







 本文档详细介绍了如何下载与使用Stanza工具包进行英文、德文等多语言的NLP处理,包括词性标注、词形还原、依赖解析和命名实体识别。同时,提供了不同版本和语言的资源包下载链接,并展示了Python代码示例,用于加载模型并处理文本。此外,还提到了词性标注的UPOS和XPOS标准,以及命名实体识别的相关信息。
本文档详细介绍了如何下载与使用Stanza工具包进行英文、德文等多语言的NLP处理,包括词性标注、词形还原、依赖解析和命名实体识别。同时,提供了不同版本和语言的资源包下载链接,并展示了Python代码示例,用于加载模型并处理文本。此外,还提到了词性标注的UPOS和XPOS标准,以及命名实体识别的相关信息。
1. 手动下载工具包:(参考https://github.com/stanfordnlp/stanza/issues/275)
默认英语工具包:https://nlp.stanford.edu/software/stanza/1.2.0/en/default.zip
默认德语工具包:https://nlp.stanford.edu/software/stanza/1.2.0/de/default.zip
版本切换为1.2.2, 1.1.0或1.0.0:https://nlp.stanford.edu/software/stanza/1.1.0/en/default.zip, https://nlp.stanford.edu/software/stanza/1.0.0/en/default.zip,
语种切换为中文,法语:https://nlp.stanford.edu/software/stanza/1.2.0/zh-hans/default.zip ,https://nlp.stanford.edu/software/stanza/1.2.0/fr/default.zip;
如想自定义下载,如1.2.2版本的德语 POS Tagging的hdt.pt:
https://nlp.stanford.edu/software/stanza/1.2.2/de/pos/hdt.pt
2. 将工具包解压后,与对应版本的resources.json放置在默认路径(可自定义)下,如图:
默认:C:\Users\pengr\stanza_resources
自定义:D:\Downloads\stanza_resources
3. 导入stanza,加载管道,NLP文本处理,详情参考官网详解:https://stanfordnlp.github.io/stanza/neural_pipeline.html:
import stanza
from stanza.models.common.doc import Document
import time
start = time.time()
# stanza.download('en') # download English model
nlp = stanza.Pipeline('en', r"D:\Downloads\stanza_resources", tokenize_pretokenized=True, verbose=False)
# 词形还原常见类型
# doc1 = nlp("my your you his he her she our we their they me i him he her she us we them they mine yours ours its theirs" +
# " myself ourselves yourself yourselves herself himself itself oneself themselves") # run annotation over a sentence
# doc2 = nlp("my your you his he her she our we their they me i him he her she us we them they mine yours ours its theirs") # run annotation over a sentence
# doc3 = nlp('something voting swimming 1990s results played does do did will do is am are doing was were doing will be doing have has done had done will have done have has been doing had been doing will have been doing would do would be doing would have done would have been doing')
# 专有名词还原
doc4 = nlp('Serbia Croatia Cambodia Romania Bulgaria Yulia Tunisia Albania Estonia Haiti Ebadi')
# for sentence in doc.sentences:
# for word in sentence.words:
# print(word.id, word.head, word.text, word.pos, word.upos, word.xpos, word.lemma, word.deprel, word.feats)
# lines = []
# with open(r'G:\NMT_Code\fairseq\data\aslg\dev.en','r',encoding='utf-8') as f:
# for line in f.readlines():
# line = line.strip().split()
# if len(line)<=22:
# lines.append(line)
# Create the document batch
# line_str = "\n\n".join([" ".join(line) for line in lines])
# docs = nlp(line_str)
for i, sent in enumerate(doc4.sentences):
print("Sentence{}:".format(i) + sent.text) # 句子本身
# print("Tokenize:" + ' '.join(token.text for token in sent.tokens)) # 标记化
# print("POS: " + ' '.join(f'{word.text}/{word.pos}' for word in sent.words)) # 词性标注(UPOS)
# print("UPOS: " + ' '.join(f'{word.text}/{word.upos}' for word in sent.words)) # 词性标注(UPOS)
# print("XPOS: " + ' '.join(f'{word.text}/{word.xpos}' for word in sent.words)) # 词性标注(XPOS)
# print("LEMMA: " + ' '.join(f'{word.text}/{word.lemma}' for word in sent.words)) # 词形还原
# print(sentence.dependencies) # 依赖解析
# print(*[f'id: {word.id}\tword: {word.text}\thead id: {word.head}\thead: {sent.words[word.head - 1].text if word.head > 0 else "root"}\tdeprel: {word.deprel}' for word in
# sent.words], sep='\n') # 依赖解析
print("NER: " + ' '.join(f'{ent.text}/{ent.type}' for ent in sent.ents)) # 命名实体识别
print(*[f'token: {token.text}\tner: {token.ner}' for token in sent.tokens], sep='\n') # 命名实体识别
# print("SENTI: " + str(sent.sentiment)) # 情感分析
# print("{} s".format(time.time() - start))4. 注意事项:
a. stanza由CoreNLP Java包的Python接口,以继承选区解析,共指消解以及语言学模式配对;

b. 词性标注:
UPOS标记的文档包含在UD指南中(在pos标记下):https://universaldependencies.org/u/pos/index.html
XPOS标签是特定于语言的,不是UD标准定义的,因此您需要查阅每个树库的文档(或联系提供的树库)。
c. 命名实体识别(参考https://zhuanlan.zhihu.com/p/75713706):
命名实体识别提升性能: 可使用CONLL03代替ONTONOTES (模型下载链接未找到)
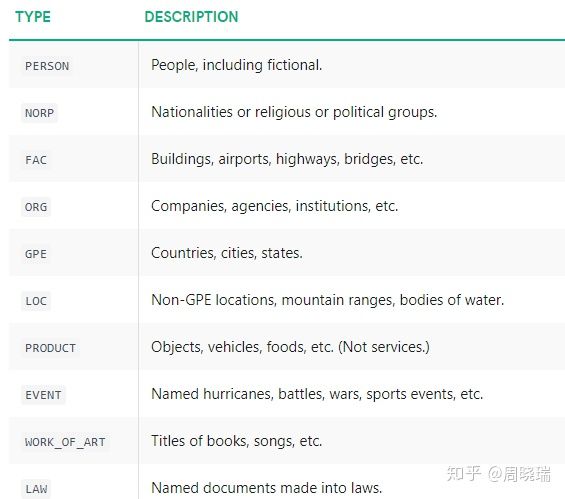
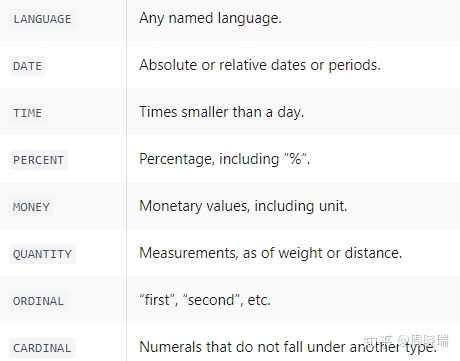

















 1216
1216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









