







论文标题:Pretrained Transformer As Universal Computation Engines - CoRR 2021
原文传送门:https://arxiv.org/abs/2103.05247 https://arxiv.org/abs/2103.05247
https://arxiv.org/abs/2103.05247
1. Abstarct
作者研究了在语言上预训练的Transformer以最少的微调泛化到其他模态的能力——特别是在没有微调residual blocks (Self-Attn和FFN Layers)的情况下。
他们称该预训练模型为 Frozen Pretrained Transformer (FPT),在涵盖数值计算、视觉和蛋白质折叠预测的各种序列分类任务上对其进行微调。
与在相同模态数据集下预训练+微调的模型比较,基于自然语言的预训练可提高非语言下游任务的性能和计算效率。此外,还与随机初始化Transformer、LSTM 进行了比较。
总体性能图:
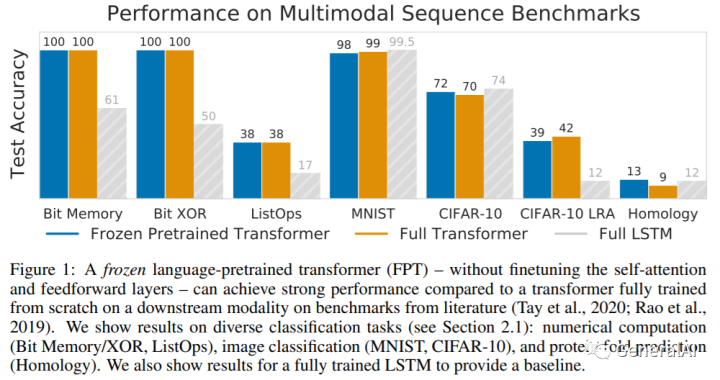
2. Introduction & Methodology
Introduction:简而言之,在大型语料库训练GPT,在不同任务的小数据集上做微调。注:仅针对线性输入和输出层,以及位置嵌入和层范数参数。
Methodology:
I. Bit memory, Bit XOR, ListOps. (数值计算任务) / MNIST, CIFAR-10, CIFAR-10 LRA (图像分类任务) / Remote homology detection (蛋白质折叠预测) II. Transformer模型就不做赘述;
3. Empirical Evaluations
3.1 Can pretrained language models transfer to different modalities?
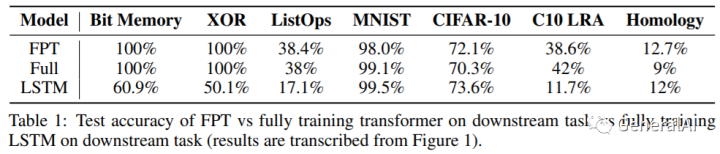
结论:7个任务下,FPT基本和随机初始化Transformer持平,比随机初始化LSTM好。
3.2 What is the importance of the pretraining modality?
Random initialization (Random): 随机初始化的GPT-2;
Bit memory pretraining (Bit): 在Bit Memory数据集上预训练;
Image pretraining (ViT): 在ImageNet-21K上预训练;
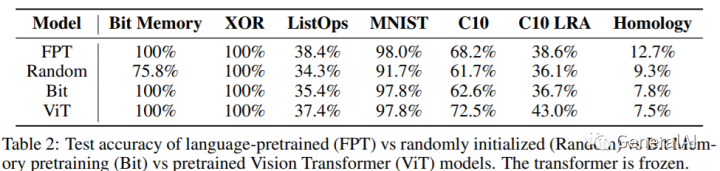
结论:7个任务下,FPT最好;而其他预训练模型,在各自模态数据下会较优。
3.3 How important is the transformer architecture compared to LSTM architecture?
Trans.: 随机初始化Transformer
LSTM: 随机初始化LSTM
LSTM*: +12-Layer + Residual Connections + Positional Embeddings

结论:Transformer较之LSTM,存在明显模型优势。
3.4 Does language pretraining improve compute efficiency over random initialization?

结论:FPT模型收敛速度 faster >> Random Transformer
3.5 Do the frozen attention layers attend to modality-specific tokens?

结论: FPT 关注到数据中语义有效的模式,仅限Bit XOR任务
3.6 Does freezing the transformer prevent overfitting or underfitting?
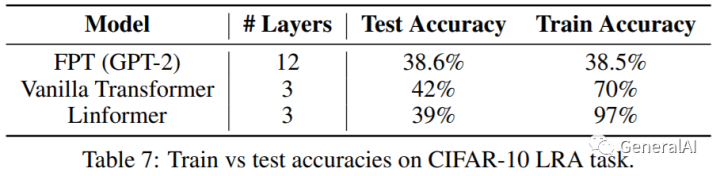
结论: FPT 会欠拟合,可在增大模型容量来改进;Linformer反映Transformer会在低资源数据下过拟合。
3.7 Does performance scale with model size?
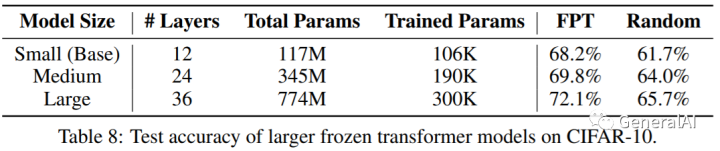
结论:较之从头训练的Transformer,FPT增大模型容量不会出现过拟合和模型不收敛。
3.8 Can performance be attributed simply to better statistics for initialization?
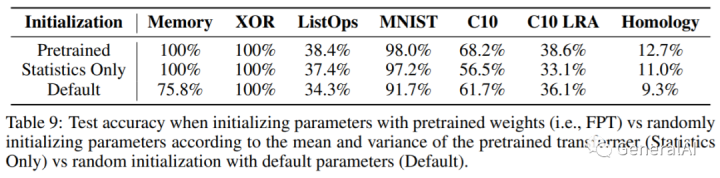
结论:移除FPT中的逐层均值和标准差,该Statistics Only模型介于FPT和 Random Transformer之间。
3.9 Can we train a transformer by only finetuning the output layer?

结论:FPT仅用于线性分类(Table. 10两项任务)的特征提取,1) 收敛加速;2)性能下降,模型过拟合(缺少对特征的正则化操作)
3.10 What is the role of model depth in token mixing?

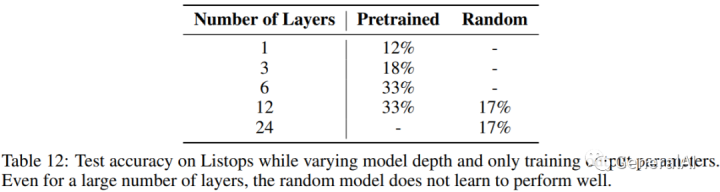
With finetuning layernorm.:层少时,使用Pretrained Layer时对Token Mixing有效,层多到6层就没区别了。 Without finetuning layernorm.:Random模型一直不行,而Pretrained会ok,但是需要足够多的层才能恢复原始性能。
3.11 Can training more parameters improve performance?


结论:微调FFN Layer可提升性能,CIFAR-10只微调最后一个注意力层最佳;
3.12 Which parameters of the model are important to finetune?
消融仅微调选择参数,以查看哪些参数最敏感。
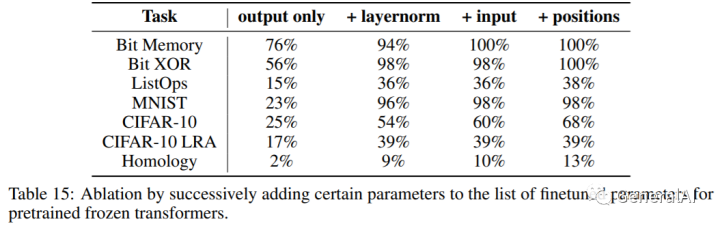
结论:+ layernorm, + input, + positions 都有用,其中+ layernorm最好
3.13 Is finetuning layer norm necessary for FPT to perform well?
只考虑微调输入和输出层,将整个FPT作为黑盒。

结论:仿射层范数参数的内部调制有所帮助,类似加入更精细的位置信息。
3.14 How well do the trends hold across other transformer models?
使用其他Transformer变种,如BERT,T5,Longformer;

结论:基于自然语言的预训练可提高非语言下游任务的性能和计算效率,该结论同样成立















 309
309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









