






若要理解数据库如何处理 SQL 语句,有必要了解一下数据库中被称为优化器的部件(也称为查询优化器或基于成本的优化器)。所有 SQL 语句都使用优化器来确定访问指定的数据的最有效手段。
使用优化器
要执行一个 DML 语句,数据库可能需要执行许多步骤。每一步或者是从数据库中物理地检索数据行,或者是在为发出语句的用户准备数据,等等。
许多不同的处理 DML 语句的方式通常都是可能的。例如,访问表或索引的顺序可能会不同。数据库用来执行一条语句的步骤,很大程度上会影响该语句的运行速度有多快。优化器生成执行计划来描述可能的执行方法。
优化器通过考虑几个信息来源来确定哪种执行计划是最有效的,包括查询条件、可用的访问路径、为系统收集的统计信息、以及提示等。对于由 Oracle 处理的任何语句,优化器将执行以下操作:
表达式和条件评估
检查完整性约束, 以了解数据和基于此元数据的优化的更多信息
语句转换
优化器目标选择
访问路径选择
连接顺序选择
优化器生成处理一个查询的几乎所有可能的方法,并给生成的执行计划中的每个步骤分配一个成本。具有最低成本的计划被选择为要执行的查询计划。
注意:
您可以获得一个 SQL 语句的执行计划,而不一定需要执行它。只有数据库实际上用于执行一个查询的执行计划,才称为查询计划。
你可以通过设置优化器目标,并为优化程序收集有代表性的统计数据,来影响优化器的选择。例如,您可以设置优化器目标为以下之一:
总吞吐量
ALL_ROWS 提示指示优化器尽可能快地将所有结果数据返回给客户端应用程序。
初始响应时间
典型的交互式终端用户应用程序将受益于初始响应时间优化,而非交互式批处理模式应用程序将受益于总吞吐量的优化。
优化器组件
优化器包含三个主要组件,如图 7-2所示。
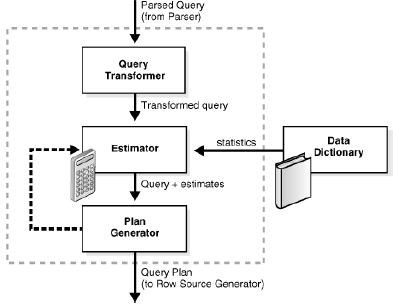
优化器的输入是一个已解析的查询。优化器将执行以下操作:
1 优化器接收已解析的查询,并基于可用的访问路径和提示,为SQL 语句生成一组潜在的计划。
2 优化器基于数据字典中的统计信息,估计每个计划的成本。成本是一个与特定用于执行该语句的计划所需的预期资源使用成正比的估计值。
3 优化器比较各个计划的成本,并选择具有最低成本的计划(也叫查询计划),然后传递给行源生成器
查询转换器
查询转换器确定更改查询的形式是否有助于优化器生成一个更好的执行计划。查询转换器的输入是一个由一组查询块表示的已分析的查询。
估算器
估算器确定一个给定的执行计划的总体成本。估算器生成三种不同类型的测量值,以实现这一目标:
选择性
这项测量表示一个行集中的一小部分。受如 last_name 的选择性依赖于查询谓词(或谓词的组合),比如last_name=’Smith’。
基数
这项测量表示行集中的行数。
成本
这项测量表示工作量或使用的资源。查询优化器使用磁盘 I/O、 CPU 使用率、和内存使用情况作为工作量。
如果统计数据可用,则估算器使用它们来计算这些测量值。统计信息可以提高测量的精确程度。
计划生成器
计划生成器对提交的查询尝试不同的计划,并选出具有最低成本的计划。优化器为每个由单独查询块表示的嵌套子查询和未合并试图生成子计划。计划生成器通过尝试不同的访问路径、 联接方法、和联接顺序,来为查询块探究各种计划。
优化程序自动管理计划,并确保只使用经过验证的计划。SQL 计划管理 (SPM) 通过仅当一个新的计划已经过验证比当前的计划更好时才使用它, 来控制计划演进。
像EXPLAIN PLAN这样的诊断工具使您能够查看优化器所选择的执行计划。EXPLAIN PLAN会显示指定的 SQL 查询的查询计划,就好像它已经在当前会话中执行过一样。其他的诊断工具还有Oracle 企业管理器和 SQL * Plus AUTOTRACE 命令。示例 7-6 显示一个查询当AUTOTRACE 处于启用状态时的执行计划。
访问路径
访问路径是从数据库检索数据的方式。例如,使用索引的查询与不使用索引的查询具有不同的访问路径。通常,索引访问路径对于只检索表行中的一个小的子集是最佳的。而完全扫描则对访问表中的一大部分更有效。
数据库可以使用几个不同的访问路径从表中检索数据。以下是一个有代表性的列表:
全表扫描
这种类型的扫描从一个表读取所有行,并滤掉那些不符合选择条件的行。数据库顺序扫描段中的所有数据块,包括那些高水位标记以下的块,高水位标记用来分隔已使用和未使用的空间。
Rowid扫描
行的 rowid 指定包含行的数据文件和数据块,以及行在该块中的位置。数据库通过语句的 WHERE 子句或一个索引扫描,首先获取所选的行的 rowids,然后基于这些 rowid查找每个选定的行。
索引扫描
此扫描搜索被SQL 语句访问的索引列的值。如果该语句仅访问已被索引的列,则数据库直接从索引读取索引的列值。
簇扫描
簇扫描用来检索存储在一个索引化的表簇中的一个表中的数据,具有相同的簇键的所有行都存储在同一个数据块中 。Oracle数据库首先通过扫描簇索引来获取所选行的 rowid。然后基于此 rowid查找相应行。
哈希扫描
哈希扫描用于查找哈希群集中的行,其中具有相同哈希值的所有行都存储在同一个数据块中 。Oracle数据库首先通过将哈希函数应用于由该语句指定的簇键值,以获得哈希值。然后扫描包含具有此哈希值的行的数据块。
优化器对访问路径的选择,基于语句的所有可用的访问路径,和使用每个访问路径或其组合的估算成本。
优化器统计
优化器统计信息是描述有关数据库和数据库中的对象的详细信息的数据集合。统计信息提供数据存储和分布的正确描述,以被优化器用来评估访问路径。
优化器统计信息包括:
表统计
这包括行数、 块数、和平均行长等。
列统计
这包括非重复值数目、空值数目、和数据的分布。
索引统计
这包括叶块数目和索引级别。
系统统计
这包括 CPU 和 I/O 的性能及利用率。
Oracle 数据库自动收集所有数据库对象的优化器统计信息,并作为一项自动维护任务来维护这些统计信息。您还可以使用DBMS_STATS 包手动收集统计信息。该PL/SQL包可以修改、 查看、 导出、 导入、和删除统计信息。
优化器统计信息被创建来用于查询优化的目的,并存储在数据字典中。这些统计数字不应与通过动态性能视图看到的性能统计信息相混淆。
优化器提示
提示是SQL 语句中的注释,作为优化程序的一个指示。有时应用程序的设计者比优化器更了解一个特定的应用程序的数据的详细信息,他可以选择一个运行 SQL 语句的更有效方法。应用程序设计者可以在 SQL 语句中使用提示,来指定该语句应该如何运行。
例如,假设你的交互式应用程序运行一个查询,返回 50 行。此应用程序最初只读取查询的前 25 行来呈现给终端用户。你想使优化器生成一个计划,尽可能快地获取首批 25 条记录,以使用户不必被迫等待。您可以使用一个提示来将此指令传递给优化器,参阅示例 7-4中的 SELECT 语句和 AUTOTRACE 输出,如下所示。
示例 7-4带有FIRST_ROWS提示的SELECT语句的执行计划
SELECT /*+ FIRST_ROWS(25) */ employee_id, department_id
FROM hr.employees
3 WHERE department_id > 50;
Execution Plan
----------------------------------------------------------
Plan hash value: 2056577954
--------------------------------------------------------------------------------
-----------------
| Id | Operation | Name | Rows | Bytes | Cost (
%CPU)| Time |
--------------------------------------------------------------------------------
-----------------
| 0 | SELECT STATEMENT | | 26 | 182 | 3
(0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 26 | 182 | 3
(0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | | | 1
(0)| 00:00:01 |示例 7-4 中的执行计划显示,优化器选择employees.department_id 列上的一个索引,来查找其部门 ID 超过 50的雇员中的前 25 行。优化器使用从索引中检索到的 rowid, 从雇员表中检索相应记录,并将其返回给客户端。第一条记录的检索通常几乎是在瞬间即可完成的。
示例 7-5 显示了相同的语句,但未使用优化器提示。
SELECT employee_id, department_id
FROM hr.employees
3 WHERE department_id > 50;
Execution Plan
----------------------------------------------------------
Plan hash value: 4141486281
--------------------------------------------------------------------------------
------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)
| Time |
--------------------------------------------------------------------------------
------------
| 0 | SELECT STATEMENT | | 50 | 350 | 3 (34)
| 00:00:01 |
|* 1 | VIEW | index$_join$_001 | 50 | 350 | 3 (34)
| 00:00:01 |
|* 2 | HASH JOIN | | | |
| |
|* 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 50 | 350 | 2 (50)
| 00:00:01 |例 7-5中的执行计划,将两个索引联接以尽可能快的返回请求的记录。优化器并不像示例 7-4那样多次在表和索引间倒腾,而是在EMP_DEPARTMENT_IX索引上使用范围扫描,找出所有部门 ID 超过50的行,并将这些行放在一个哈希表中。然后优化器读取 EMP_EMP_ID_PK 索引。对该索引中的每一行,它探测一次该哈希表,以查找相应的部门 id。
在这种情况下,数据库不能在完成对EMP_DEPARTMENT_IX 索引的范围扫描之前向客户端返回第一行。因此,此生成的计划将需要更长的时间返回第一条记录。与示例7-4中按索引 rowid访问表的计划不同,示例 7-5 的计划使用多数据块 I/O,导致大量读取操作。这种读取使得整个结果集的最后一行会更快地返回。















 274
274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









