







文|Seraph
01 | Horovod介绍
Horovod是一个分布式训练框架(针对TensorFlow/Keras/PyTorch/MXNet)。Horovod目标是使分布式深度学习更快更简单地使用。
由于Tensorflow集群太不友好,业内也一直在尝试新的集群方案。 2017年Facebook发布了《Accurate, large minibatch SGD: Training ImageNet in 1 hour 》验证了大数据并行的高效性,同年百度发表了《Bringing HPC techniques to deep learning 》,验证了全新的梯度同步和权值更新算法的可行性。受这两篇论文的启发,Uber开发了Horovod集群方案。
Horovod几个亮点:不依托于某个框架,使用MPI构建一套分布式系统;Tensor Fusion可以在梯度传递过程中,将小的Tensor合并成大的Tensor,减少每一次的额外开销。
02 | Horovod安装
一、安装Python和Tensorflow、Pytorch
- 这里需要的是Python3,如仅有Python2,请使用以下命令安装。
apt-get update
apt-get install python3-pip
由于我们基本只会使用python3,我们可以通过版本切换设置将python,pip默认为python3,pip3.
- 使用版本切换命令
update-alternatives --install /usr/local/bin/python python /usr/bin/python3 150更新Python自动转Python3的优先级为150,数字越大,越优先。 update-alternatives --config python查看Python版本优先级。- 同样的方法更新pip版本切换优先级
update-alternatives --install /usr/bin/pip pip /usr/local/bin/pip3 150
- 安装TensorFlow
pip install --upgrade pip
pip install tensorflow==1.14.0
pip install tensorflow-gpu==1.14.0
pip install torch==1.2.0 torchvision==0.4.0 -f https://download.pytorch.org/whl/torch_stable.html
Pytorch版本关系详见PREVIOUS VERSIONS OF PYTORCH
如遇见pip下载慢的情况,可以使用国内镜像源。
比如pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip。
常用国内镜像源:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
note:新版ubuntu要求使用https源,要注意。
二、安装CUDA
- 卸载CUDA10.1
- 使用
apt-get remove cuda*卸载10.1 - 使用
apt-get autoremove自动卸载未卸载干净的的包 - 使用
rm -rf cuda cuda-10.1删除/usr/local目录下的cuda及cuda-10.1文件夹
-
打开链接cuda-10.0-download-archive下载相应系统版本的CUDA,我们这里使用runfile安装。
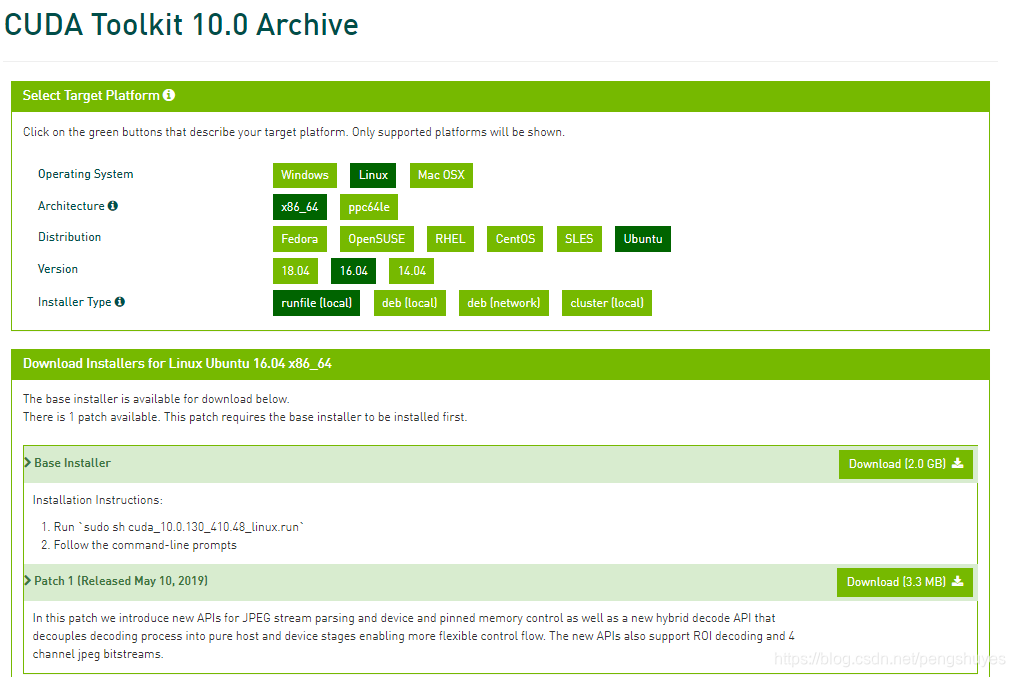
ubuntu系统可以使用wget下载,下载链接获取方式:右键Download按钮复制链接地址即可。记得补丁包也要下载。 -
下载完后,使用
sh cuda_10.0.130_410.48_linux.run执行安装包,不想看EULA,可以键盘输入Ctrl+C停止,直接进入安装选项。
Do you accept the previously read EULA?
accept/decline/quit: accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48?
(y)es/(n)o/(q)uit: n
Install the CUDA 10.0 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-10.0 ]:
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 10.0 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /root ]:
如你已经安装NVIDIA Accelerated Graphics Driver,一定要向上面一样选择no,否则半天时间就过了。。。切记。。。
- 配置CUDA环境变量,打开
~/.bashrc文件添加如下内容:
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:${CUDA_HOME}/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${CUDA_HOME}/lib64
然后保存,执行source ~/.bashrc。
- 装完成后使用
nvcc --version查询CUDA版本信息如下:

三、安装cuDNN
- 从cudnn-archive下载相应的cuDNN版本,注意我们使用的是CUDA10.0,所以也要下载对应可用的版本。我这里分别下载的是:
cuDNN Runtime Library for Ubuntu16.04 (Deb)
cuDNN Developer Library for Ubuntu16.04 (Deb) - 执行
dpkg -i libcudnn7_7.6.5.32-1+cuda10.0_amd64.deb及
dpkg -i libcudnn7-dev_7.6.5.32-1+cuda10.0_amd64.deb即可。 - 查询已安装的cuDNN版本:
cat /usr/include/cudnn.h | grep CUDNN_MAJOR -A 2
详细步骤参考cuDNN install
四、安装NCCL2
- 打开NVIDIA Collective Communications Library (NCCL) Download Page下载相应的版本文件,需要登陆,可以用社交账号(微信)扫码登陆。
- 我这里下载的
nccl-repo-ubuntu1604-2.5.6-ga-cuda10.0_1-1_amd64.deb
nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb - 分别输入如下命令
dpkg -i nccl-repo-ubuntu1604-2.5.6-ga-cuda10.0_1-1_amd64.deb
dpkg -i nvidia-machine-learning-repo-ubuntu1604_1.0.0-1_amd64.deb
apt update
apt install libnccl2=2.5.6-1+cuda10.0 libnccl-dev=2.5.6-1+cuda10.0
如提示
The public CUDA GPG key does not appear to be installed.
To install the key, run this command:
sudo apt-key add /var/nccl-repo-2.5.6-ga-cuda10.0/7fa2af80.pub
输入apt-key add /var/nccl-repo-2.5.6-ga-cuda10.0/7fa2af80.pub即可。
详细步骤参考Installing NCCL
五、OpenMPI安装
- 因为我们要演示的是TensorFlow训练,安装前,确认g++版本,必须是
g++-4.8.5或g++-4.9。否则执行如下命令apt-get install g++-4.8。(这部及其重要,否则,安装Horovod会报错,如果我们使用的是Pytorch,则安装g++-4.9) - 新建一个文件目录
openmpi,将OpenMPI 4.0.0版本下载至该目录。
wget https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.0.tar.gz - 解压文件:
tar -zxvf openmpi-4.0.0.tar.gz - 进入解压后的文件目录,配置:
./configure(必须保证以及安装了g++、gcc) ,默认配置安装路径为/usr/local/lib,也可以使用--prefix=路径参数指定安装路径 - 编译:
make - 安装:
make all install - ~/.bashrc文件末尾加上:
export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH
永久化环境变量:source ~/.bashrc - 测试,进入
example目录,然后make,最后输入mpirun --allow-run-as-root -oversubscribe -np 2 hello_c
这里需要解释一下两个参数:--allow-run-as-root和-oversubscribe,一般不需要这两个参数便能执行。
--allow-run-as-root:一般不建议root执行该命令,所以如果要在root下执行,需要加上这个参数;-oversubscirbe:执行命令前,mpi会当前的CPU资源是否适合运行,如不管这个判断,需要-oversubscirbe。
六、安装Horovod
- 执行
pip install horovod即能完成horovod安装。
执行如果没有安装任何东西,显示包都已安装,请执行pip install --upgrade horovod即可。
由于我们需要使用NCCL2中的算法库,所以我们安装horovod的时候需要添加如下参数:
HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir horovod
或
HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir --upgrade horovod - 如果要额外安装Pytorch版本,则运行下面命令:
HOROVOD_WITH_TENSORFLOW=1 HOROVOD_WITH_PYTORCH=1 HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir horovod - 测试example
- 使用git工具将horovod库clone下来。
- 进入
examples目录,输入命令horovodrun -np 1 -H localhost:1 python tensorflow_mnist.py便能运行tensorflow_mnist.py示例。
这里的localhost表示本机,输入主机名也可以,当不同的机器,以,号隔开,输入不同的主机名与GPU数量即可。
03 | Horovod使用
一、单机单卡训练脚本改为多机多卡步骤
- 初始化
hvd.init() - 每个进程分别与指定的GPU绑定
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
-
根据GPU数量放大学习率
opt = tf.train.AdagradOptimizer(learningrate * hvd.size())
因为BatchSize会根据GPU数量放大,所以学习率也应该放大。 -
封装optimizer
opt = hvd.DistributedOptimizer(opt) -
广播初始变量值给所有进程
hooks = [hvd.BroadcastGlobalVariablesHook(0)] -
设置只在worker 0上保持checkpoint
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
04 | 问题解决
-
更换Tensorflow版本后,horovodrun有问题,说没有安装MPI或Gloo。
解决:按步骤全部重新安装一遍。
理解:不知道Horovod到tensorflow有什么依赖关系。可能也和版本有关系,我尝试了多遍。目前使用tensorflow 1.14.0版本/MPI 4.0.0版本安装环境没有问题。 -
当使用两台机器进行GPU训练时,报如下错误:
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer.
解决:使用ifconfig查找通信使用的网卡,我这里是eno1
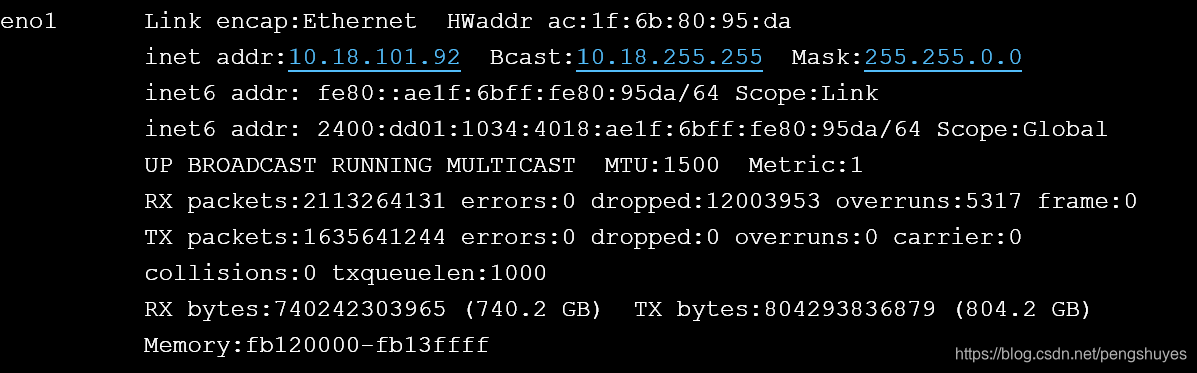
然后给mpirun命令添加-mca btl_tcp_if_include eno1参数即能正常运行。
我的执行命令如下:
mpirun --allow-run-as-root -np 2 -H ubuntu90:1,sugon92:1 -bind-to none -map-by slot -mca plm_rsh_args "-p 31028" -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include eno1 python tensorflow_mnist.py
因为我的环境是docker,监听端口不是22,所以还额外加了-mca plm_rsh_args "-p 31028"参数以表示ssh连接使用31028端口。
当然你也可以尝试下GitHub上Run Horovod with Open MPI文章Hangs due to non-routed network interfaces章节中提供方法。(虽然我没试通。。。) -
运行训练脚本时提示
Failed to find dynamic library: libnccl.so ( libnccl.so: cannot open shared object file: No such file or directory )等错误信息。
解决:NCCL2未正确安装。
我在安装NCCL2中执行apt update提示
E: The method driver /usr/lib/apt/methods/https could not be found.
N: Is the package apt-transport-https installed?
执行apt install apt-transport-https安装apt-transport-https即能正确安装。
安装过程中,一定要注意提示信息,确保每步执行正确。由于安装软件时,都有依赖包,有些执行步骤不会自动安装依赖包。
-
多机GPU训练脚本提示:
NCCL INFO NET/IB : Using interface ib0 for sideband communication
解决:这里表示的意思是使用ib0接口进行通信,这里的ib0指得是infiniband网卡,用于高性能计算的一种通信网卡。默认设置为NCCL默认设置infiniband进行通信,但如果双机的infibiband不能通信,则会导致多机并行计算失败。我们可以将NCCL使用的网卡设置为我们正常使用的以太网卡即能成功运行,给mpirun命令添加如下参数:
-x NCCL_SOCKET_IFNAME=eno1 -
多机GPU训练脚本提示:NCCL INFO NET/Plugin : No plugin found (libnccl-net.so), using internal implementation
解决:我理解是能接入外部的网络通信实现包,如果没有使用内部实现。例如外部包AWS OFI NCCL。所以这个提示是不影响正常运行的。 -
运行某些脚本时,提示:
failed to allocate 3.21G (3452305408 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY: out of memory
解决:提示明显时是显存申请失败,使用nvidia-smi命令查看N卡的信息,关注固有显存以及使用情况。
尝试使用config = tf.ConfigProto()控制GPU的显存使用。
config.gpu_options.allow_growth = True #设置成动态申请
config.gpu_options.per_process_gpu_memory_fraction = 0.3 #设置成最大使用多少比例的显存
尝试无效果的话,使用添加代码os.environ["CUDA_VISIBLE_DEVICES"] = "1"来选择哪个GPU,也许有的GPU显存被占用,亦不能释放。可以指定一个完全空闲的GPU进行训练。
或者可以在执行命令前加CUDA_VISIBLE_DEVICES=1来指定GPU。但这种对多机情况不适用,其他机器不能同步该参数。当然也可以将这个写进~/.bashrc中,便可以了。
当整个卡都无法满足显存需求时,可以修改batch_size以适当减少显存需求。
-
多机GPU训练脚本提示:
misc/ibvwrap.cc:212 NCCL WARN Call to ibv_open_device failed。
解决:IB卡的infiniband设备未找到。当我们利用MPI在IB卡做通信时,可以使用两种协议进行通信,一种是TCP,一种是infiniband协议(RDMA)。这里错误是指的是未找到infiniband协议设备,使用ibv_devices指令查看当前机器的IB卡设备。
因为我是在容器内使用的,所以在创建容器时,需要加上--cap-add=IPC_LOCK --device=/dev/infiniband参数,具体见问题19。 -
代码错误提示:
RuntimeError: Global step should be created to use StepCounterHook.
解决:使用global_step = tf.train.get_or_create_global_step()生成global_step。 -
代码错误提示:RuntimeError: Run called even after should_stop requested.
解决: -
使用docker容器,训练代码时,提示
Read -1, expected 7329, errno = 1。
解决:官方文档说明这是因为权限问题,但可以忽略,不影响训练执行。 -
使用docker容器执行多机GPU训练,提示:
A process or daemon was unable to complete a TCP connection to another process: Local host: fe31b0df9223 Remote host: 0f5f1d90a597 This is usually caused by a firewall on the remote host. Please check that any firewall (e.g., iptables) has been disabled and try again.
解决:有可能时网卡问题,新建Docker容器时,默认时以Bridge的模式。指定为Host模式即可。
在docker run运行命令后面加上--network host参数。 -
多卡训练时,出现如下错误:
tensorflow.python.framework.errors_impl.FailedPreconditionError: Mismatched ALLREDUCE CPU/GPU device selection: One rank specified device CPU, but another rank specified device GPU. [[node DistributedAdamOptimizer_Allreduce/HorovodAllreduce_gradients_dense_1_BiasAdd_grad_tuple_control_dependency_1_0 (defined at <string>:80) ]]
解决:卸载horovod,使用HOROVOD_GPU_ALLREDUCE=NCCL pip install --no-cache-dir horovod安装。 -
多卡训练时,出现如下错误:
NCCL INFO Call to connect returned Connection refused, retrying
解决:新建一个docker环境,重新搭整个环境。(我试过重新安装cuda/cuDNN/NCCL等,但是没有效果)。 -
多机训练时,出现如下错误:
hvd1:60423:60555 [1] NCCL INFO NET/IB : No device found.
hvd1:60422:60554 [0] NCCL INFO NET/Socket : Using [0]ib0:192.168.1.200<0>
hvd1:60423:60555 [1] NCCL INFO NET/Socket : Using [0]ib0:192.168.1.200<0>
hvd:27943:28074 [1] NCCL INFO Setting affinity for GPU 1 to ff00ff00
hvd1:60422:60554 [0] NCCL INFO Setting affinity for GPU 0 to ff00ff
hvd1:60423:60555 [1] NCCL INFO Setting affinity for GPU 1 to ff00ff00
hvd1:60422:60554 [0] include/socket.h:397 NCCL WARN Connect to 192.168.1.50<49823> failed : No route to host
hvd1:60422:60554 [0] NCCL INFO bootstrap.cc:95 -> 2
hvd1:60422:60554 [0] NCCL INFO bootstrap.cc:308 -> 2
hvd1:60422:60554 [0] NCCL INFO init.cc:443 -> 2
hvd1:60422:60554 [0] NCCL INFO init.cc:732 -> 2
hvd1:60422:60554 [0] NCCL INFO init.cc:771 -> 2
hvd1:60422:60554 [0] NCCL INFO init.cc:782 -> 2
解决:添加mpirun运行指令-x NCCL_SOCKET_IFNAME=eno1参数,由于我们IB卡没有通,这里告诉NCCL指定eno1进行通信。如果你的IB卡的RDMA通信正常,NCCL会默认使用infiniband协议进行通信。
-
安装CUDA时, 出错:
gpgkeys: protocol https’ not supported
解决:apt install gnupg-curl。 -
如安装CUDA后,使用nvcc命令显示:
nvcc: command not found
解决:配置CUDA环境变量。
export LD_LIBRARY_PATH=/usr/local/cuda/lib:$LD_LIBRARY_PATH
export PATH=$PATH:/usr/local/cuda/bin
-
多机训练时,出错:
Unable to load libnccl-net.so : libnccl-net.so: cannot open shared object file: No such file or directory
解决:提示其实不影响训练进行,NCCL可提供给第三方开发库,但不是必须。如没有这个库,会自动选择内部实现进行通信。详细情况见Issues 162 -
docker容器下,Pytorch多卡训练报错:
ERROR: Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm).
解决:新建容器时,添加--ipc=host参数。 -
docker容器下,欲使用IB卡的RMDA,出错:
A process failed to create a queue pair. This usually means either
the device has run out of queue pairs (too many connections) or
there are insufficient resources available to allocate a queue pair
(out of memory). The latter can happen if either 1) insufficient
memory is available, or 2) no more physical memory can be registered
with the device.
For more information on memory registration see the Open MPI FAQs at:
http://www.open-mpi.org/faq/?category=openfabrics#ib-locked-pages
Local host: laser045
Local device: qib0
Queue pair type: Reliable connected (RC)
解决:首先做分布式GPU训练,推荐使用nvidia-docker,这个命令起始就是基于英伟达的显卡配置信息上给原装的docker添加了一些配置参数。
解决本问题在于新建容器时命令如下:nvidia-docker run -it --network=host -v /mnt/share/ssh:/root/.ssh --cap-add=IPC_LOCK --device=/dev/infiniband horovod:latest。
关键参数为:--cap-add=IPC_LOCK --device=/dev/infiniband,表示关联主机上的IB卡设备。
-
RuntimeError: Global step should be created to use StepCounterHook.
解决:使用global_step = tf.train.get_or_create_global_step()生成Global_step。 -
RuntimeError: Run called even after should_stop requested.。
解决:
05 | 解决方案
-
多机GPU运行
答:将SSH连接设置成无需密码就能访问的模式即可。
同时注意可以在/ect/hosts文件中添加主机名和IP地址的映射关系。
参考 SSH login without password -
非
22端口ssh连接运行
答:不能直接使用horovodrun命令,需要使用mpirun添加相关端口参数。
参考 Run Horovod with Open MPI文章中的Custom SSH ports章节。
只能找到统一端口的配置方式,未找到不同机不同监听端口配置方式。
06 | 其他
- CUDA/MPI等环境变量参考
PATH
/usr/local/mpi/bin:/usr/local/nvidia/bin:/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/tensorrt/bin
LD_LIBRARY_PATH/usr/local/cuda/extras/CUPTI/lib64:/usr/local/cuda/compat/lib:/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/usr/local/lib/tensorflow


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









