







文|MESeraph
10 | gdb
在不利用gdb调试之前,我们一般通过以下步骤发现bug的原因:通过错误现象,假设错误原因,再通过插入printf,执行程序并分析结果。
这样费时费力,而通过gdb可以完全复现错的现象。(当然如果是多线程的问题,可以会比较复杂一点,因为线程之间交互过多,打断点也经常会阻碍线程的正常交互)。
- 编译时加上
-g选项便可以生产可调试的可执行文件。 - 在提示符下直接按回车键表示重复上一条命令。
- 把源代码改名或移到别处再用gdb调试,这样就列不出源代码了。
| 命令 | 简写 | 含义 |
|---|---|---|
| help [指令] | h | 查看帮助 |
| list [数字|函数名] | l | 从第n行或函数头开始查看源码,每次列出10行 |
| quit | q | 退出gdb调试 |
| start | 无 | 开始执行调试 |
| next | n | 单步调试 |
| step | s | 进入函数内部跟踪调试 |
| backstrace | bt | 查看函数调用的栈帧 |
| info locals | i locals | 查看局部变量值; |
| frame | f | 切换栈帧 |
| p | 打印变量值 | |
| finish | 无 | 让程序执行完当前函数 |
| set var 变量 | 给变量赋值 | |
| dispaly/undisplay 变量 | 跟踪/取消跟踪变量 | |
| breakpoint 行数 | b | 设置断点,在某行设置断点,一般是会先使用l显示行 |
| continue | c | 继续执行 |
| i breakpoints | i b | 查看已经设置的断点 |
| delete breakpoints [数字] | 无 | 删除第n个断点或全部 |
| disable breakpoints [数字] | 无 | 暂停第n个断点或全部 |
| enable breakpoints [数字] | 无 | 启用第n个断点或全部 |
| break n if 条件 | 无 | 满足条件则执行断点 |
| run | r | 重新运行调试程序 |
| x/数字b 变量 | 打印变量位置的指定数量的单位内存信息 | |
| watch array[5] | 监视array[5]内存改变 | |
| i watchpoints | 查看监视点 |
13 | 计算机中数的表示
- 逻辑电路计算两个bit的加法:
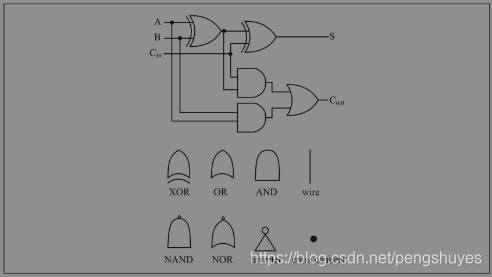
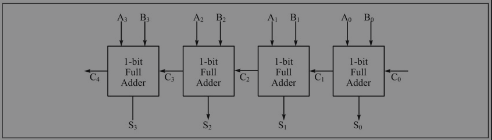
- 多位加法器
- 十进制小数换算成二进制小数:乘2取整,顺序排列。
- 数的表示法:
- Sign and Magnitude表示法:把最高位规定为符号位(Sign Bit),0表示正1表示负,剩下的7位表示绝对值的大小,8个bit表示整数的取值范围是
−
2
7
−
1
~
2
7
−
1
-2^7-1~2^7-1
−27−1~27−1。
用这种表示法进行减法的缺点:计算机做加减运算需要处理很多逻辑:比较符号位、比较绝对值、加法改减法、减法改加法、小数减大数改成大数减小数……这是非常低效率的。还有一个缺点是0的表示不唯一,既可以表示成10000000也可以表示成00000000。 - 1’s Complement表示法
十进制9补码计算理解:
167-52=167+(-52)=167+(999-52)-1000+1=167+947-1000+1=1114-1000+1=114+1=115
首先-52要用999-52表示,就是947,这称为取9的补码(9’sComplement);然后把167和947相加,得到114进1;再把高位进的1加到低位上去,得115,本来应该加1000,结果加了1,少加了999,正好把先前取9的补码多加的999抵消掉了。
二进制1补码计算理解:
00001000-00000100→00001000+(-00000100)→00001000+11111011→00000011进1→高位进的1加到低位上去,结果为00000100(正负得正的情况)
1’s Complement表示法缺点:0的表示仍然不唯一,既可以表示成11111111也可以表示成00000000。 - 2’s Complement表示法
2’s Complement表示法规定:正数不变,负数先取反码再加1。
如果8个bit采用2’s Complement表示法,负数的取值范围是从10000000到11111111(-128~-1),正数是从00000000到01111111(0~127),也可以根据最高位判断一个数是正是负,并且0的表示是唯一的,目前绝大多数计算机都采用这种表示法。
的,目前绝大多数计算机都采用这种表示法。为什么称为“2的补码”呢?因为对一位二进制数b取补码就是1-b+1=10-b,相当于从2里面减去b。
判断溢出:如果两个正数相加溢出,结果一定是负数;如果两个负数相加溢出,结果一定是正数;一正一负相加,无论结果是正是负都不可能溢出。

依据上面的情况分析得出结论:在相加过程中最高位产生的进位和次高位产生的进位如果相同则没有溢出,如果不同则表示有溢出。
逻辑电路的实现可以把这两个进位连接到一个异或门,把异或门的输出连接到溢出标志位。
- 浮点数计算
-
正规化(Normalize):规定尾数部分的最高位必须是1,也就是说尾数必须以0.1开头,对指数做相应的调整。由于尾数部分的最高位必须是1,这个1就不必保存了,可以节省出一位来用于提高精度,我们说最高位的1是隐含的(Implied)。

-
有时计算顺序不同也会导致不同的结果,因为浮点数计算时,后面的小数可能会被舍去。
14 | 数据类型详解
一、整型
- C标准的Rationale之一:优先考虑效率,而可移植性尚在其次。所以效率和可移植性需要自己作选择。
- C语言与平台和编译器是密不可分的,离开了具体的平台和编译器讨论C语言。
- C标准没有明确规定char是有符号的还是无符号的,但是要求编译器必须对此做出明确规定,并写在编译器的文档中。
- Implementation-defined表示没有明确规则,但是编译器必须明确规定。(比如char是有符号还是五符号)
Unspecified的情况,C标准没有明确规定按哪种方式处理,编译器可以自己决定,并且也不必写在编译器的文档中,这样即便用同一个编译器的不同版本来编译也可能得到不同的结果。(比如求知顺序)
Undefined的情况则是完全不确定的,C标准没规定怎么处理,编译器很可能也没规定,甚至也没做出错处理,有很多Undefined的情况编译器是检查不出来的,最终会导致运行时错误。(比如数组访问越界)
二、 浮点数
- 有的处理器有浮点运算单元(Floating Point Unit,FPU),称为硬浮点(Hard-float)实现;有的处理器没有浮点运算单元,只能做整数运算,需要用整数运算来模拟浮点运算,称为软浮点(Soft-float)实现。
三、类型转换
- 有符号或无符号的char型、short型和Bit-field在进行算术运算之前首先要做Integer Promotion,然后才能参与计算。
-
-
-
- / % > < >= <= == !=运算符都需要做UsualArithmetic Conversion。
-
-
- 单目运算符+ - ~只有一个操作数,移位运算符<< >>两边的操作数类型不要求一致,这些运算不需要做Usual Arithmetic Conversion,但需要做Integer Promotion.
- getchar的返回值是int型。
四、强制类型转换
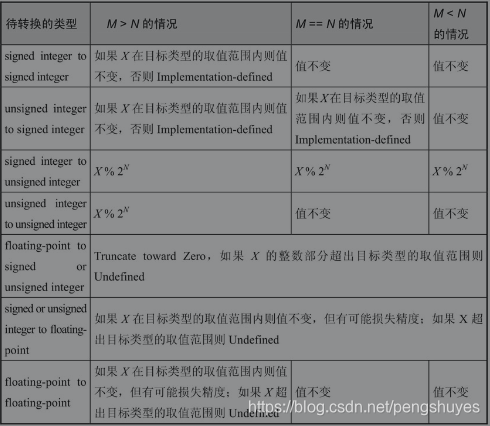
一定要注意强制类型转换,最好是不要出现数值超过转换目标类型的范围。
15 | 运算符详解
一、位运算
- C语言中其实并不存在8位整数的位运算,操作数在做位运算之前都至少被提升为int型了。
- 右移运算的规则,如果是负数,则是Implementation-defined。
- 由于类型转换和移位等问题,用有符号数做位运算是很不方便的,所以,建议只对无符号数做位运算,以减少出错的可能性。
- 一个数和自己做异或的结果是0。如果需要一个常数0,x86平台的编译器可能会生成这样的指令:xorI %eax, %eax。不管eax寄存器里的值原来是多少,做异或运算都能得到0,这条指令比同样效果的movI $0, %eax指令快,直接对寄存器做位运算比生成一个立即数再传送到寄存器要快一些。
- 从异或的真值表中可以看出,和0做异或保持原值不变,和1做异或得到原值的相反值。得到原值的相反值。可以利用这个特性配合掩码实现某些位的翻转。
- 如果a1 ^ a2 ^ a3 ^ … ^ an的结果是1,则表示a1、a2、a3…an之中1的个数为奇数个,否则为偶数个。校验码会用到这个性质。
- x ^ x ^ y == y,这个性质可以用来不借助额外的存储空间交换来两个变量的值。
a = a^b;
b = b^a;
a = a^b;
- RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)实际上就是利用了7、8。
二、其他
- size_t就代表unsigned long型。不同平台的编译器可能会根据自己平台的具体情况定义size_t所代表的类型,比如有的平台定义为unsigned long型,有的平台定义为unsigned long long型,C标准规定size_t这个名字就是为了隐藏这些细节,使代码具有可移植性。
- 类型名也遵循标识符的命名规则,并且通常加个_t后缀表示Type。
16 | 计算机体系结构基础
- 地址线、数据线和CPU寄存器的位数通常是一致的。
- 对于多字节的整数类型,低地址保存的是整数的低位,这称为小端(Little Endian)字节序(Byte Order)。x86平台是小端字节序的,而另外一些平台规定低地址保存整数的高位,称为大端(Big Endian)字节序。
- 无论是在CPU外部接总线的设备还是在CPU内部接总线的设备都有各自的地址范围,都可以像访问内存一样访问,很多体系结构(比如ARM)采用这种方式操作设备,称为内存映射I/O(Memory-mapped I/O)。但是x86比较特殊,x86对于设备有独立的端口地址空间,CPU核需要引出额外的地址线来连接片内设备(和访问内存所用的地址线不同),访问设备寄存器时用特殊的in/out指令,而不是和访问内存用同样的指令,这种方式称为端口I/O(Port I/O)。
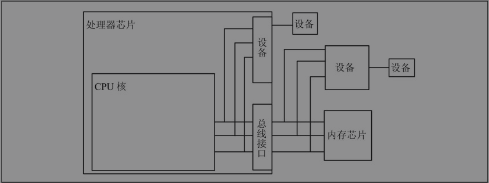
- 从CPU的角度来看,访问设备只有内存映射I/O和端口I/O两种,要么像内存一样访问,要么用一种专用的指令访问。
- 访问设备是相当复杂的,计算机的设备五花八门,各种设备的性能要求都不一样,有的要求带宽大,有的要求响应快,有的要求热插拔,于是出现了各种适应不同要求的设备总线,比如PCI、AGP、USB、1394、SATA等,这些设备总线并不直接和CPU相连,CPU通过内存映射I/O或端口I/O访问相应的总线控制器,通过总线控制器再去访问挂在总线上的设备。
- 访问设备还有一点和访问内存不同。内存只是保存数据而不会产生新的数据,如果CPU不去读它,它也不需要主动给CPU提供数据,所以内存总是被动地等待被读或者被写。而设备往往会自己产生数据,并且需要主动通知CPU来读这些数据,例如输入一个字符,用户希望计算机马上响应自己的输入,这就要求键盘设备主动通知CPU来读这个字符并做相应的处理,给用户响应。这是由中断(Interrupt)机制实现的,每个设备都有一条中断线,通过中断控制器连接到CPU,当设备需要主动通知CPU时就引发一个中断信号,CPU正在执行的指令将被打断,程序计数器会指向某个固定的地址(这个地址由体系结构定义),于是CPU从这个地址开始取指令(或者说跳转到这个地址),执行中断服务程序(Interrupt Service Routine,ISR),完成中断处理之后再返回先前被打断的地方执行后续指令。
- 由于各种设备的操作方法各不相同,每种设备都需要专门的设备驱动程序(Device Driver),一个操作系统为了支持广泛的设备就需要有大量的设备驱动程序,事实上Linux内核源代码中绝大部分是设备驱动程序。设备驱动程序通常是内核里的一组函数,通过读写设备寄存器实现对设备的初始化、读、写等操作,有些设备还要提供一个中断处理函数供ISR调用。
- MMU

如果处理器没有MMU,或者有MMU但没有启用,CPU执行单元发出的内存地址将直接传到芯片引脚上,被内存芯片(以下称为物理内存,以便与虚拟内存区分)接收,这称为物理地址(Physical Address,PA)。
如果处理器启用了MMU,CPU执行单元发出的内存地址将被MMU截获,从CPU到MMU的地址称为虚拟地址(Virtual Address,VA),而MMU将这个地址翻译成另一个地址发到CPU芯片的外部地址引脚上,也就是将VA映射成PA。 - 如果是32位处理器,则内地址总线是32位的,与CPU执行单元相连,而经过MMU转换之后的外地址总线则不一定是32位的。也就是说,虚拟地址空间和物理地址空间是独立的,32位处理器的虚拟地址空间是4GB,而物理地址空间既可以大于4GB也可以小于4GB。(注意!注意!注意!)
- 物理内存中的页称为物理页面或者页帧(Page Frame)。虚拟内存的页面映射到物理内存的页帧是通过页表(Page Table)来描述的,页表保存在物理内存中,MMU会查找页表来确定一个VA应该映射到什么PA。
- CPU每次执行访问内存的指令都会自动引发MMU做查表和地址转换操作,地址转换操作由硬件自动完成,不需要用指令控制MMU去做。
- MMU提供内存保护机制,操作系统可以在页表中设置每个内存页面的访问权限,有些页面不允许访问,有些页面只有在CPU处于特权模式时才允许访问,有些页面在用户模式和特权模式都可以访问,访问权限又分为可读、可写和可执行三种。这样设定好之后,当CPU要访问一个VA时,MMU会检查CPU当前处于用户模式还是特权模式,访问内存的目的是读数据、写数据还是取指令,如果和操作系统设定的页面权限相符,就允许访问,把它转换成PA,否则不允许访问,产生一个异常(Exception)。
- 异常的处理过程和中断类似,不同的是中断由外部设备产生而异常由CPU内部产生,中断产生的原因和CPU当前执行的指令无关,而异常的产生就是由于CPU当前执行的指令出了问题。
- 段错误的产生:
- 用户程序要访问的一个VA,经MMU检查无权访问。
- MMU产生一个异常,CPU从用户模式切换到特权模式,跳转到内核代码中执行异常服务程序。
- 内核把这个异常解释为段错误,终止引发异常的进程。
17 | x86汇编程序基础
- 链接主要有两个作用:
- 一是修改目标文件中的信息,对地址做重定位。
- 二是把多个目标文件合并成一个可执行文件
所以汇编器编译及其指令后,还需要链接。
- 汇编指令:as
- 链接指令:ld
一、汇编语法
- .开头的名称并不是指令的助记符,不会被翻译成机器指令,而是给汇编器一些特殊指示,称为汇编指示(AssemblerDirective)或伪操作(Pseudo-operation),由于它不是真正的指令所以加个“伪”字。
- .section指示把代码划分成若干个段(Section),程序被操作系统加载执行时,每个段被加载到不同的地址,操作系统对不同的页面设置不同的读、写、执行权限。
.data段保存程序的数据,是可读可写的,相当于C程序的全局变量。
.text段保存代码,是只读和可执行的 - _start是一个符号(Symbol),符号在汇编程序中代表一个地址,可以用在指令中,汇编程序经过汇编器的处理之后,所有的符号都被替换成它所代表的地址值。
- .gIobI告诉汇编器,_start这个符号要被链接器用到,所以要在目标文件的符号表中标记它是一个全局符号。
- _start就像C程序的main函数一样特殊,是整个程序的入口,链接器在链接时会查找目标文件中的_start符号代表的地址,把它设置为整个程序的入口地址,所以每个汇编程序都要提供一个_start符号并且用.gIobI声明。如果一个符号没有用.gIobI声明,就表示这个符号不会被链接器用到。
- 立即数前面要加$,寄存器名前面要加%,以便跟符号名区分开。
- int指令称为软中断指令。
- 内核提供了很多系统服务供用户程序使用,但这些系统服务不能像库函数(比如printf)那样调用,因为在执行用户程序时CPU处于用户模式,不能直接调用内核函数,所以需要通过系统调用切换CPU模式,经由异常处理程序进入内核,用户程序只能通过寄存器传几个参数,之后就要按内核设计好的代码路线走,而不能任由用户程序随心所欲地调用内核函数,这样可以保证系统服务被安全地调用。
- eax和ebx是传递给系统调用的两个参数。eax的值是系统调用号,Linux的各种系统调用都是由int $0x80指令引发的,内核需要通过eax判断用户需要哪个系统调用,_exit的系统调用号是1。ebx的值是传给_exit的参数,表示退出状态。
- x86汇编一直存在两种不同的语法,在intel的官方文档中使用intel语法, Windows也使用intel语法,而UNIX平台的汇编器一直使用AT&T语法。
- data_items类似于C语言中的数组名。
- .long指示声明占32位的数
.byte声明占8位的数
.ascii,声明取值为相应字符的ASCII码的字符。
二、x86的寄存器
- x86的通用寄存器有eax、ebx、ecx、edx、edi、esi。这些寄存器在大多数指令中是可以任意选用的,但也有一些指令规定只能用其中某个寄存器做某种用途。
- x86的特殊寄存器有ebp、esp、eip、efIags。eip是程序计数器,
efIags保存着计算过程中产生的标志位,其中包括进位标志、溢出标志、零标志和负数标志,在intel的手册中这几个标志位分别称为CF、OF、ZF、SF。ebp和esp用于维护函数调用的栈帧。
三、寻址方式
- 通用内存寻址指令格式:
ADDRESS_OR_OFFSET(%BASE_OR_OFFSET,%INDEX,MULTIPLIER) - 直接寻址、变址寻址、间接寻址、基址寻址、立即寻址、寄存器寻址。
四、ELF文件
- 各种UNIX系统的可执行文件都采用ELF格式,它有以下三种不同的类型:
- 可重定位的目标文件(Relocatable,或者Object File)
- 可执行文件(Executable)
- 共享库(Shared Object,或者Shared Library)
- 编译、链接、运行过程:
- 汇编器读取这个文本文件并将其转换成目标文件max.o,目标文件由若干个Section组成,我们在汇编程序中声明的.section会成为目标文件中的Section,此外汇编器还会自动添加一些Section(比如符号表)。
- 然后链接器把目标文件中的Section合并成几个Segment,生成可执行文件max。
- 最后加载器(Loader)根据可执行文件中的Segment信息加载运行这个程序。ELF格式提供了两种不同的视角,链接器把ELF文件看成是Section的集合,而加载器把ELF文件看成是Segment的集合。
- 有些Section只对链接器有意义,在运行时用不到,也不需要加载到内存,那么就不属于任何Segment。
- 使用readeIf工具查看目标文件内容。
- 使用hexdump工具查看目标文件字节内容。
- C语言的全局变量如果在代码中没有初始化,就会在程序加载时用0初始化。这种数据属于.bss段。
- 在ELF文件中.data段需要占用一部分空间保存初始值,而.bss段则不需要。
- .reI.text告诉链接器指令中的哪些地方需要做重定位。
- .symtab是符号表。
- 使用objdump工具反汇编。
- 两个Segment必须加载到内存中两个不同的页面,因为MMU的权限保护机制是以页为单位的,一个页面只能设置一种权限。
- strip命令去除可执行文件中的符号信息。不要对目标文件和共享库使用strip命令,因为链接器需要利用目标文件和共享库中的符号信息来做链接。
21 | Makefile编程基础
一、语法规则
- Makefile由一组规则(Rule)组成,每条规则的格式如下所示:
target ... : prerequistites ...
command1
command2
...
目标和条件之间的关系是:欲更新目标,必须先更新它的所有条件;所有条件中只要有一个条件被更新了,目标也必须随之被更新。
所谓“更新”就是执行一遍规则中的命令列表,命令列表中的每条命令必须以一个Tab开头,注意不能用空格代替这个Tab。
对于Makefile中的每个以Tab开头的命令,make会启动一个Shell进程去执行它。
如下例子:
collectsvr: collectsvr.o getconf.o httpclt.o
gcc collectsvr.o getconf.o httpclt.o -lcurl -o collectsvr
collectsvr.o: collectsvr.c include/httpclt.h include/getconf.h
gcc -c collectsvr.c
httpclt.o: httpclt.c include/httpclt.h
gcc -c httpclt.c
getconf.o: getconf.c include/getconf.h
gcc -c getconf.c
-
尝试更新Makefile中第一条规则的目标main,第一条规则的目标称为缺省目标,只要缺省目标更新了就算完成任务了,其他工作都是为这个目标而做的。
-
通常Makefile都会有一个clean规则,用于清除编译过程中产生的二进制文件,保留源文件:
clean:
@echo "cleaning project"
-rm collectsvr *.o
@echo "cleaning completed"
在make的命令行中可以指定一个或多个目标,比如指定了目标clean,则执行Makefile中更新目标clean的规则,如果在make的命令行中不指定任何目标,则更新Makefile中第一条规则的目标(缺省目标)。
我们输入make clean便可以指定clean目标。
如果make执行的命令前面加了@字符,则不显示命令本身而只显示它的输出结果;
但如果命令前面加了-字符(Hyphen),即使这条命令出错,make也会继续执行后续命令。
如果存在clean这个文件,clean目标也不依赖于任何条件,make就认为它不需要更新了。所以这个时候我们需要一条伪目标命令来告诉make指令,这条目标不是真正的目标:.PHONY: clean
- 约定俗成的目标名字有:
- all,执行主要的编译工作,通常用作缺省目标。
- install,执行编译后的安装工作,把可执行文件、配置文件、文档等分别复制到不同的安装目录。
- clean,删除编译生成的二进制文件。
- distclean,不仅删除编译生成的二进制文件,也删除其他的生成文件,比如内核源代码make menuconfig配置之后生成的.config文件,一些文档源文件(比如本书的Docbook源文件)经过make之后会转换生成HTML或PDF文件,执行make distclean应该清除所有的生成文件,只留下源文件。















 1480
1480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









