







参考
场景
- RDD的基本操作
1、计算并在控制台输出某文件中 相同行的个数.
例如,文件内容如下:
hello world
hello world
hadoop
spark
flink
spark
spark
则输出结果:
flink:1
hello world:2
spark:3
hadoop:12、WordCount程序的编写并画出相关RDD执行流程图
分析
一、代码
package main.scala
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
/**
* RDD基本操作
*/
object RDDOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDBaseOnCollection")
val sc = new SparkContext(conf)
/*
* 计算并输出文件中 相同行的个数
*/
val rows = sc.textFile("file:///home/pengyucheng/java/rdd2.txt")
val rowCount = rows.map(row=>(row,1))
val sameRowCounts = rowCount.reduceByKey(_+_)
sameRowCounts.collect().foreach(pair => println(pair._1+":"+pair._2))
/*
* 单词计数
*/
rows.flatMap(_.split(" ")).map(word=>(word,1)).reduceByKey(_+_).collect.foreach(println)
}
}二、执行结果
scala> val rows = sc.textFile("file:///home/pengyucheng/java/rdd2.txt")
16/05/26 15:42:49 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
rows: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[1] at textFile at <console>:27
scala> val rowCount = rows.map(row=>(row,1))
rowCount: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[2] at map at <console>:29
scala> val sameRowCounts = rowCount.reduceByKey(_+_)
sameRowCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:31
scala> sameRowCounts.collect().foreach(pair => println(pair._1+":"+pair._2))
flink:1
hello world:2
spark:3
hadoop:1三、wordcount RDD流程图
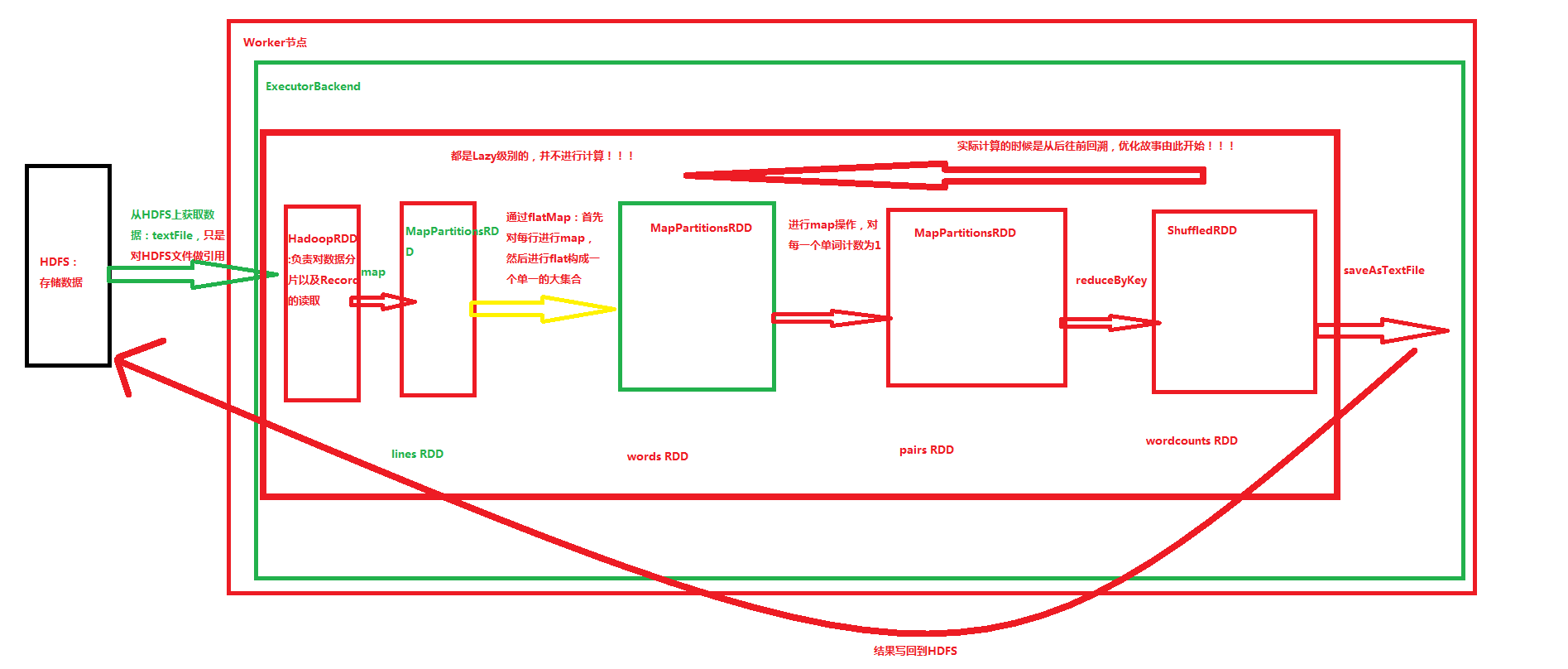
总结
1、RDD的操作分成三大类:transformation(eg、flatMap,reduceByKey)、action(eg、collect,foreach,saveAsTextFile) 与 controller(eg、persist,cache)
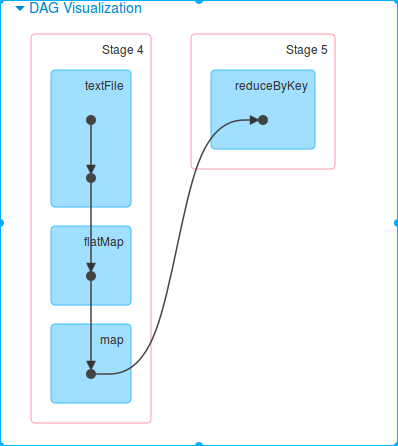
2、action触发job,shuffle触发stage















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









