







参考
中华石杉
DT大数据梦工厂系列
场景
什么是并行度、如何调节并行度、并行度对性能有怎样的影响以及并行度调节成多大合适?
分析
- 并行度
Snail理解的并行度是指spark集群能同时并发处理的task数量,在数值上等于集群的总core的数量,其值可以在编写应用程序的时候指定:
val conf = new SparkConf()
conf.setAppName("my first spark app ").set("spark.default.parallelism", "1") //指定并行度为1- 对性能的影响
[3.0.0]详细说明了最大化资源的重要性。好的,现在假设集群资源为:
12个executors, 每个executor分配 4 cores 8G,并且已通过spark-submit将资源设置为最大了。处理相同复杂度的spark任务,考虑如下三种并行度设置方式:
spark.default.parallelism = 24
spark.default.parallelism = 12*4
spark.default.parallelism = 12*4*5先比较第1、2种情况:集群能并行处理 48个task,而第1中情况并行度只设置成24 - 这意味着平均分给每个executor的task 为两个(24/12),意味着每个executor都浪费了2个core,意味着对处理相同复杂度的spark任务而言,每个task要处理的数据量比第二种情况要多一倍:比如总共有2400G的数据要处理,第一种情况下每个task要处理的数据量是 2400G/24 等于100G,而第二种情况是 50G 。处理的数据量越大,出现磁盘I/O、GC的可能性就增加了!
- 并行度调节成多大合适
经验证明(snail也只是听王教主说的):每个 core分配5个task最佳
官方是推荐将task数量设置成spark application总cpu core数量的2~3倍,比如150个cpu core,基本要设置task数量为300~500,原因如下:
有些task会运行的快一点,比如50s就完了,有些task可能会慢一点,要1分半才运行完。所以如果你的task数量,刚好设置的跟cpu core数量相同,还是会导致资源的浪费-因为,比如150个task,10个先运行完了,剩余140个还在运行,但是这个时候,有10个cpu core就空闲出来了,就导致了浪费。那如果task数量设置成cpu core总数的2~3倍,那么一个task运行完了以后,另一个task马上可以补上来,就尽量让cpu core不要空闲,同时也是尽量提升spark作业运行的效率和速度,提升性能。
实验
这里限于资源问题只能在本地验证一点:通过set(“spark.default.parallelism”, “1”)设置的并行度与实际并行运行的task数量一至。
1、代码 set(“spark.default.parallelism”, “1”)
package com.dt.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object WordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("my first spark app ").set("spark.default.parallelism", "1") // 本地模式不设置的话,spark会自行将并行度设置
//成本地最大的cores
val sc = new SparkContext(conf)
val lines2 = sc.textFile("file:///home/pengyucheng/resource/hellospark.txt")
lines2.flatMap(line => line.split(" ") ).map( word => (word,1) ).reduceByKey(_+_).
map(wordNumberPair=>(wordNumberPair._2,wordNumberPair._1)).sortByKey(false).
collect.foreach(wordNumberPair => println(wordNumberPair._1 +":" + wordNumberPair._2))
sc.stop
}
}执行脚本
--class com.dt.spark.WordCount \
--num-executors 1 \
--driver-memory 1000m \
--executor-memory 1000m \
--executor-cores 1 \
/home/pengyucheng/resource/wordcount.jar \
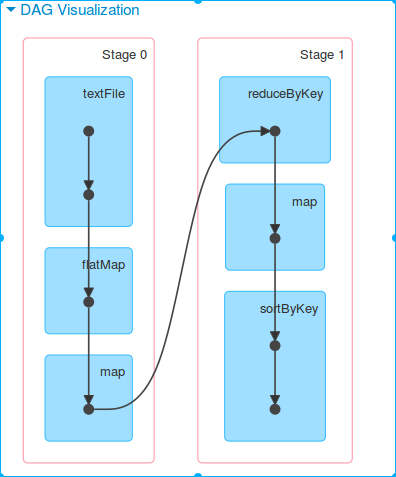
结果 web UI

共一个job,分为3个stage,每个stage一个task
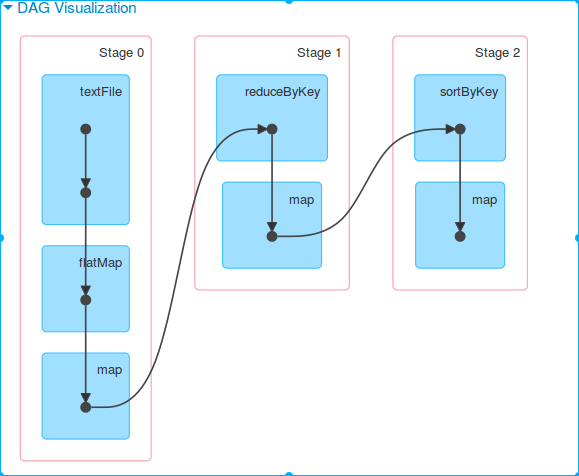
2、代码(略)set(“spark.default.parallelism”, “2”)
web UI

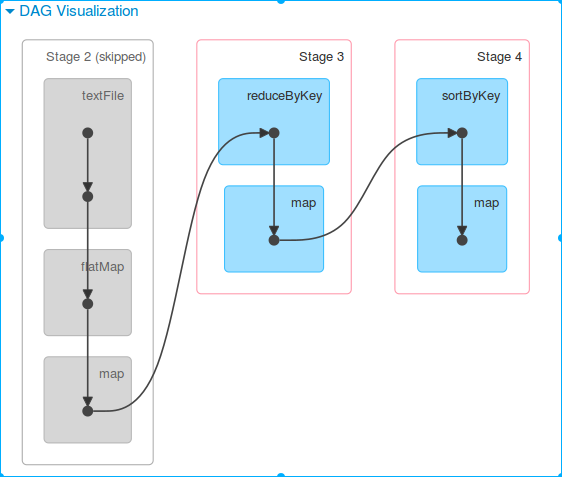
划分成2个job,每个job分为2个stage,每个stage2个任务
总结
- 并行度的设置需要与资源相匹配,才能最大化利用集群资源
- 并行度设置方式set(“spark.default.parallelism”, “parallelismNum”)
疑问:并行度设置的不同,怎么会导致同一任务划分的job数量不同呢?















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









