






在今年 2 月 27 日的发布会上,除了万众瞩目的小米SU7 Ultra 与小米15 Ultra 外,还推出了一系列夺人眼球、科技感满满的产品。其中,小米技术团队历经两年打磨的 TWS 耳机 ——XIAOMI Buds 5 Pro,以小米史上最强音质震撼登场,在降噪领域更是实现了惊人突破,成为小米超宽频深度降噪的扛鼎之作。
想象一下,在春运火车站的站台、在轰鸣的生产车间、在音乐狂欢的酒吧中,无论外界环境如何喧嚣,它都能能精准抓取人声,确保通话如在静谧空间般清晰。而这背后,自研 3 麦克风环境噪声消除技术功不可没。接下来,让我们一同深入探索,看小米如何凭借前沿科技,为用户打造极致通话体验,同时解开小米自研 3 麦克风环境噪声消除技术的神秘面纱。

XIAOMI Buds 5 Pro 除了硬件与音质的大幅度提升之外,在降噪上也有了极大的技术突破,是目前小米最强的超宽频深度降噪耳机,另外,XIAOMI Buds 5 Pro 的一大亮点就是可在 100dB 的嘈杂环境中,仍能精准识别人声,实现清晰通话。
实现这一极端环境下清晰的通话降噪效果,背后的技术支撑是自研 3 麦克风阵列的环境噪声消除技术(以下简称 3mic ENC 技术),我们将从技术原理、效果对比、技术升级展望等方向,为大家带来极端环境下实现超清通话的技术介绍。

01
自研环境噪声消除原理
TWS耳机里一般有三个麦克风,一个是通话麦克,一个是前馈麦克,一个是反馈麦克,简称为 3mic 。3mic ENC通话降噪,首先会进行 3 路的自动回声消除(Automatic Echo Cancellation,AEC)+线性回声抑制+非线性回声抑制,能有效消除回声和各种因素导致的非线性回声,保证 3 颗麦克风能将回声信号滤除干净;利用波束形成技术(图中的beamform),将拾音方向聚焦到嘴巴方向,能有效拾取说话者声音。
结合双通路自适应滤波,能将目标人声和环境噪声初步分离,此时可以分离出一路语音通路和一路噪声通路,其中语音通路目标语音信号占主导并有少量噪声信号,噪声通路中噪声占主导并有少量目标语音信号;将两路信号送入自研AI降噪模块和双通道后处理,利用AI算法强大的降低非平稳噪声能力,和双通道后处理降低平稳噪声的强大能力,使得自研 3mic ENC 能轻松应对各种环境噪声,提取出干净的目标人声。
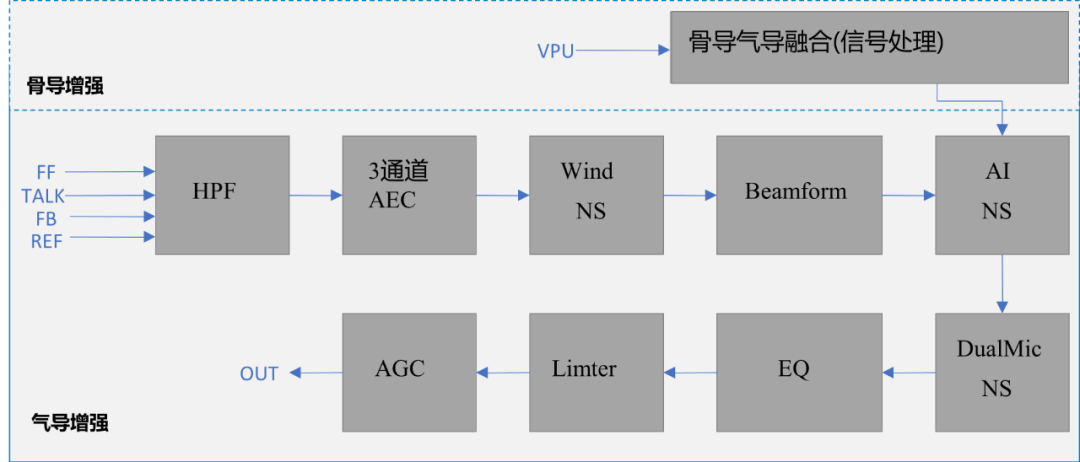
AI降噪模块是自研技术核心之一,其是根据人耳听觉对声音不同频率敏感度不同的特性,将神经网络与计算听觉场景分析深度结合,对不同噪声环境下的人声进行精准提取和增强;同时结合了多种优化方法降低模型的计算复杂度,在较低功耗下达到极致的降噪性能。考虑到TWS耳机使用场景,自研AI降噪模块进行了充足数据训练,覆盖各种场景,其中包括:数千小时+的噪声数据,餐厅、马路、音乐、地铁、公交车、火车、风噪、家居生活、自然环境、车内噪声、车行驶的噪声、鸟叫、敲门等等;仅风噪数据一项,便收集训练了各种类型的风噪,使最终降噪效果得以平稳呈现;同时,AI降噪模块还收集了一万小时以上的干净语音数据,包括男声、女声、老人、小孩、各地方言等等,保证人声效果的干净、清澈。
TWS耳机用户经常会遇到户外刮风或者冬天骑车的场景,此时相对风速常常达到5级风,很容易造成通话信号嘈杂,更常见的场景是在嘈杂市场、公交车、地铁等较大噪声场景临时通话,在这些场景实测中,自研3mic ENC均能获得较好的降噪体验,这依赖于其中四项主要的技术:内麦增强、自适应内外麦映射、风噪检测、风噪抑制。
内麦增强:利用反馈麦克风(feedback mic)低通特性和拾取到较高信噪比的特性,对其拾取的信号进行内麦增强,该算法对反馈麦克风信号整体信噪比提升有较大作用;同时增强的信号在大噪声和风噪场景下对保证清晰的语音通话起到重要作用。
自适应内外麦映射:在入耳式耳机中,内麦拾取到的信号也有一定低通特性,听感往往会比较沉闷,且不同人佩戴其低通特性表现不一样,这就导致用以往固定频率的高架滤波方式不可行,因此小米自研团队创新性提出利用内麦频谱映射到外麦频谱的方式,且设计了一套自适应映射方法,使得内麦映射到外麦后听感和外麦非常相似;该算法在大噪声和风噪场景下对保证清晰的语音通话起到重要作用。
风噪检测:利用拾取风噪信号的不相关性检出风噪起始时间和受风噪污染的频段,自研enc的风噪检测速度可以做到15m/s内准确检测到受影响的频带。
风噪抑制:对检出风噪的信号进行风噪抑制,自研方案创新性利用反馈麦克风映射信号替换受风噪污染的频段,该算法能最大限度去除风噪干扰。
在风噪场景下,通过风噪检测检测出风噪起始时间,及风噪污染频段,利用内麦增强和自适应内外麦映射得到未受到风噪污染的干净语音信号(反馈麦克风映射信号),利用其映射信号来替换受风噪污染的频段,从而实现风噪抑制,实测状态下,即使在15m/s风速,即7级强风的情况下,也能够稳定通话。
在较大噪声场景,如嘈杂市场、公交车、地铁、机场等,噪声声压级有时会大于100dB,用户说话声音较小意味着麦克风采集到信号的信噪比较低,在这种场景下,环境噪声的能量强度已经明显大于人声强度,此时双通路自适应滤波、自研AI降噪模块和双通道后处理等算法面临较大挑战,常规的降噪处理手段已难以施展。
在这种极端场景下,自研ENC采用策略类似风噪场景,利用内麦增强和自适应内外麦映射得到未受到噪声干扰的干净语音信号,根据背景噪声量估计方法得到的环境噪声量级,动态融合反馈麦克风的映射信号,从而达到提高信噪比作用,以便后续模块工作在最佳状态。
通过以上技术的组合使用,自研ENC算法能轻松应对各种生活场景噪声,保证清晰的语音通话,带给用户最佳体验。
02
效果评价
▍整体评价
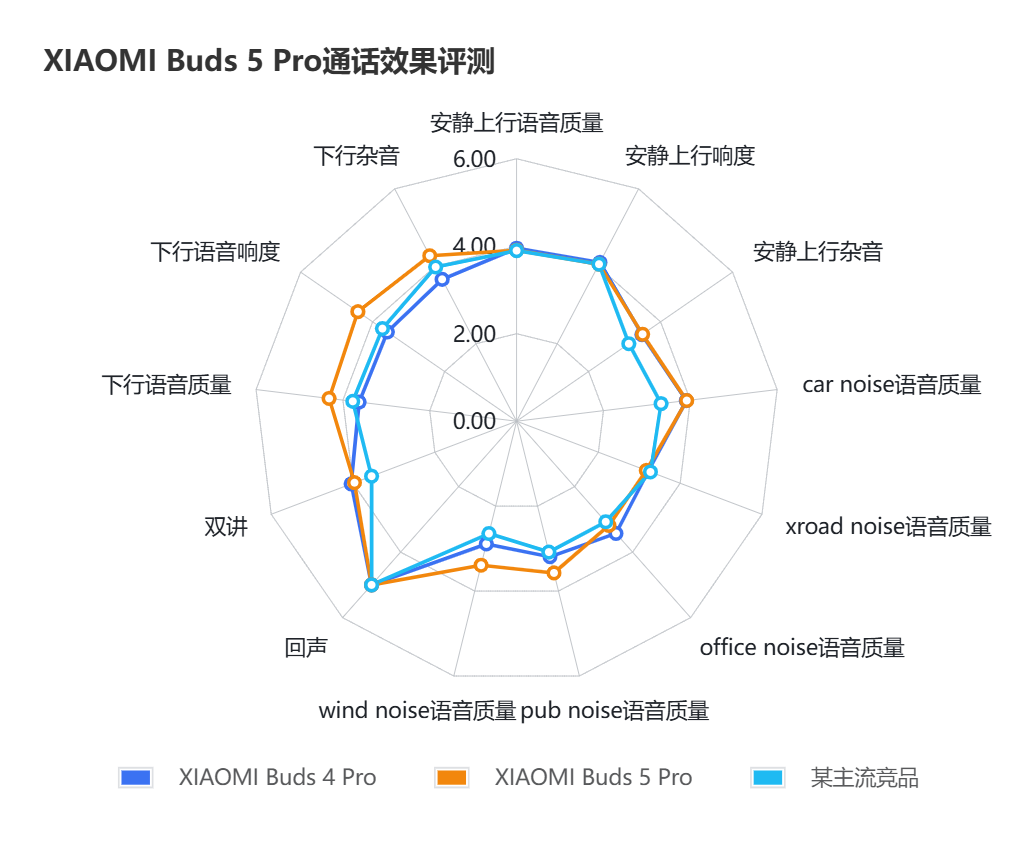
为了验证自研 3mic ENC 降噪效果,我们在大批量人群上进行了十三个维度的效果比较,比较对象包括了 XIAOMI Buds 5 Pro 、上一代 XIAOMI 降噪耳机以及市场某主流竞品,获得了整体评价:
可以看出,引入自研 3mic ENC 降噪后,XIAOMI Buds 5 Pro 在语音响度、语音质量多个维度都明显优于了竞品及上一代的同类产品。
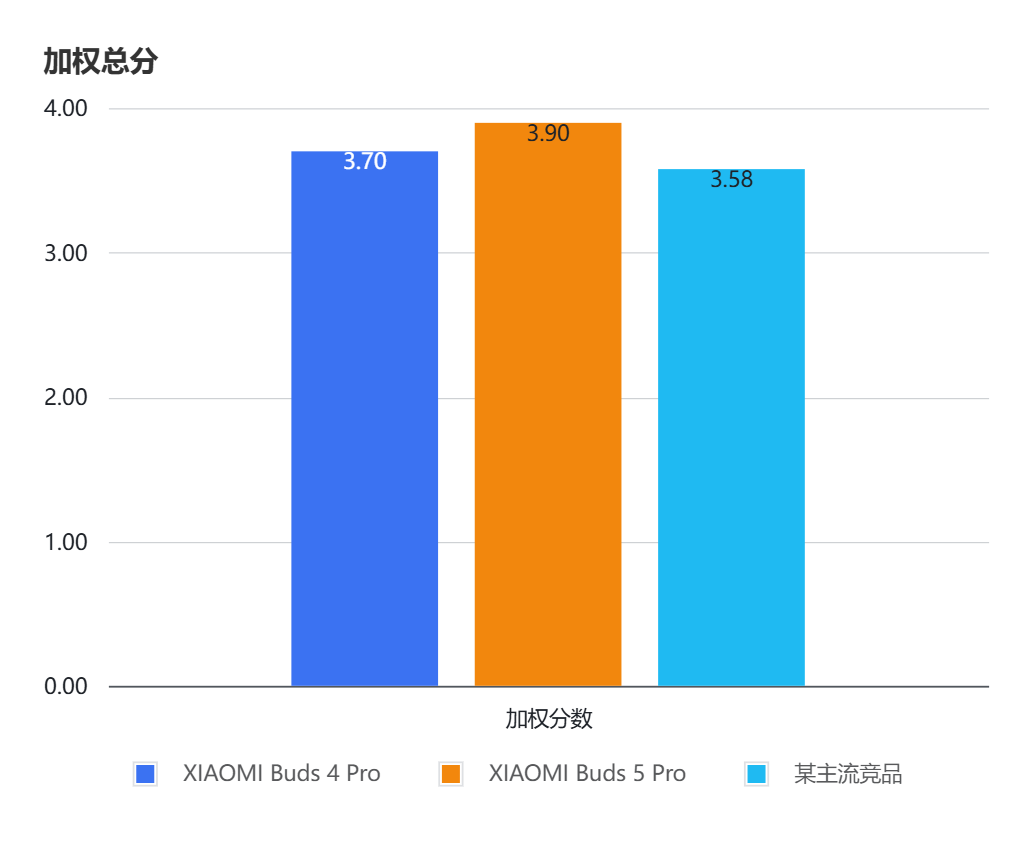
在大样本人群的盲测主观打分中,XIAOMI Buds 5 Pro 也获得了明显更高的加权满意度,相比上一代产品有明显的进步:
▍环境噪声降噪评价
我们在 XIAOMI Buds 5 Pro 上采用创新通话降噪方案,利用AI降噪算法,融合 3 麦克风阵列技术,充分保障了语音可懂度、清晰度,且优化了之前主流竞品存在的声音发闷等问题;最终实现了 100dB 噪声环境下的信息清晰传达。
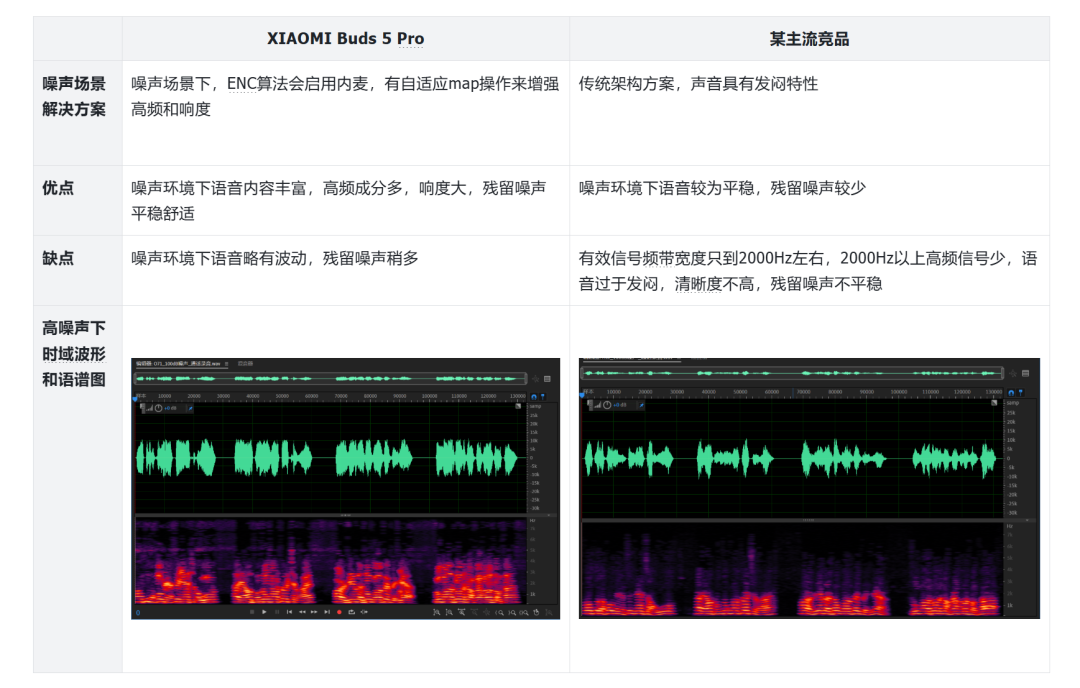
以下录音展示了在 100dB 高嘈杂环境下,某竞品耳机与 XIAOMI Buds 5 Pro 试听效果的对比,可带上耳机试听:
▍通话抗风噪性能评价
通过在 5m/s 到 11m/s 的风速环境下测试,可以明显感受到 XIAOMI Buds 5 Pro 优秀的抗风噪能力,通过自研 ENC 降噪,语音输出响度大、信号平稳、内容丰富。
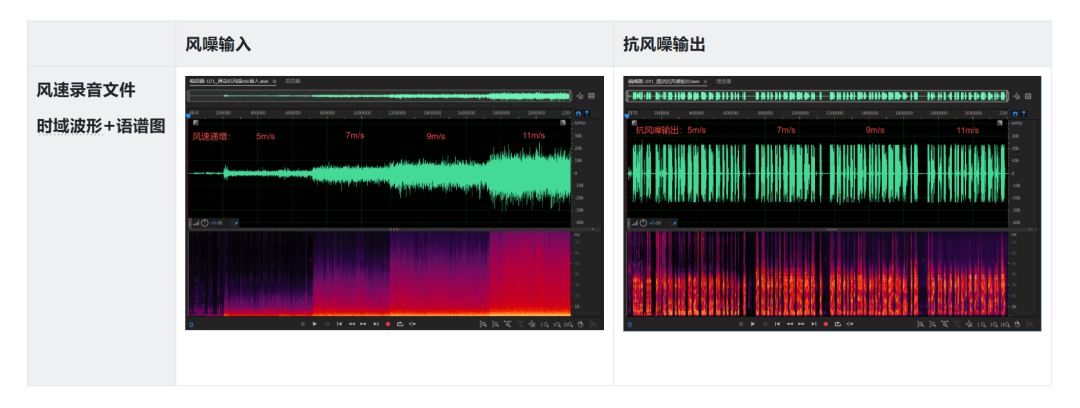
以下录音展示了在从低到高的风噪环境下,某竞品耳机与XIAOMI Buds 5 Pro 试听效果的对比,可带上耳机试听:
▍行业技术认证
除了大规模的人群效果评价外,XIAOMI Buds 5 Pro 引用的自研降噪算法还通过了中国计量院抗风噪 15m/s 认证(证书编号202400120030),符合行业要求的降风噪技术标准。


03
技术升级展望
在大模型浪潮之下,音频通信技术也迎来了技术范式的革新,当前音频通信技术正沿着「无损传输、零感延迟、智能交互」三大轴线加速演进。以 Dante 协议为代表的IP化音频传输网络,已实现多通道音频的微秒级同步传输(典型延迟<2ms),为沉浸式会议系统与智能家居生态奠定基础。AI 技术的深度渗透推动通信链路智能化跃迁——如基于神经网络的动态降噪算法可实时分离人声与超高分贝的噪声,说话人识别系统能在 0.3 秒内完成声纹特征提取与身份验证。在 TWS 耳机上应用的自研 ENC 降噪算法,也将沿着生成式大模型的技术路径,探索音频修复技术的效果突破。
采用生成式音频修复技术,通过扩散概率模型+对比学习框架,可以实现在 IoT 设备端实现实时声学环境重构。基于扩散模型,可实现任意长度音频间隙的修复。该技术突破传统监督学习的数据依赖限制,在突发性噪声消除场景(如爆炸声、玻璃碎裂声)中展现出独特价值。例如,Stable Audio 采用的扩散架构可在 10ms 内生成与原始声场物理特性匹配的修复结果。生成式音频修复技术,必将带来信息通话、IOT 设备行业新的革命,在小米应用体系内,我们新的技术升级将应用在以下方面:
▍智能家居场景
复杂声场解耦:智能音箱通过 Ambisonics 阵列采集 4 通道空间音频,结合 GAN 模型分离重叠声源。在家庭聚会场景中,可精准提取特定人声指令可实现信噪比提升 25dB 以上,即便在吸尘器附近的高噪音干扰下仍可保持极高的识别准确率。
声纹欺骗防御:门禁系统搭载声纹反生成模型,可识别AI语音合成攻击(如生成的高仿语音),防御成功率较传统方案明显提升,有效提高了声纹使用的安全性。
▍工业物联网场景
设备异常诊断:工业传感器通过 AudioLM 模型分析机械振动音频,实现轴承磨损、齿轮缺齿等故障的声纹特征提取,诊断效率较频谱分析法提升明显。
危险声波预警:建筑工地的边缘计算节点实时检测超声波频段(如玻璃幕墙应力释放声),可实现极高的预警准确率,响应时间也可缩短至 200ms 。
▍车载系统升级
座舱声场重构:采用神经辐射场(NeRF-Audio)技术,通过 4 个麦克风实现全车舱 3D 声场建模。在高速公路场景下,可动态增强驾驶员侧语音清晰度,同时抑制风噪与胎噪,降噪量达 30dB 以上。
事故音频重建:车载黑匣子利用变分自编码器(VAE)修复碰撞瞬间的破损音频,可实现关键信息复原,为事故责任判定提供关键证据链。
▍技术挑战与演进路径
尽管当前技术突破显著,在实际应用上,仍需突破三大瓶颈:
边缘端算力约束:现有 RNN-T 模型在 ARM Cortex-M7 芯片的推理时延较高,需开发专用 NPU 加速架构(如特斯拉 Dojo D1 芯片的音频处理单元)
跨场景泛化能力:当前模型在极端场景(如暴雨中的户外监控)的噪声抑制性能会产生下降,需引入元学习框架提升适应能力
隐私安全风险:数据收集过程中,在联邦学习框架下的分布式声纹数据库建设,需满足 GDPR 声纹数据匿名化标准
-
综合来看,通过小米自研的通话降噪技术,现有推出的TWS耳机已可实现比较优秀的环境声和风噪的消除效果,已明显优于行业竞品,可以为用户带来十分优秀的通话降噪体验。而随着技术的升级,采用生成式音频修复技术,耳机降噪效果将会迎来新一轮的巨大提升,为用户带来更清晰、更具质感的音频体验。
END



















 7632
7632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









