






一、朴素贝叶斯分类器原理回顾
朴素贝叶斯分类器基于贝叶斯定理,其核心公式为:
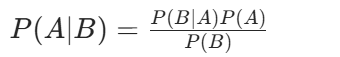
其中,P(A∣B)是在事件B发生的条件下事件A发生的后验概率;P(B∣A)是似然概率,即事件A发生时事件B发生的概率;P(A)是事件A发生的先验概率;P(B)是事件B发生的概率。
在朴素贝叶斯分类器中,有一个关键的假设 —— 特征条件独立假设,即假设各个特征之间相互独立。在西瓜好坏判断这个场景下,就是假设西瓜的色泽、根蒂、敲声等特征之间互不影响。基于这个假设,对于一个样本x=(x1,x2,⋯,xn),其属于类别y的后验概率可表示为:
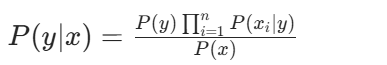
实际应用中,因为P(x)对于所有类别相同,所以我们只需比较分子![]() 的大小,就能确定样本所属类别。
的大小,就能确定样本所属类别。
二、数据集介绍
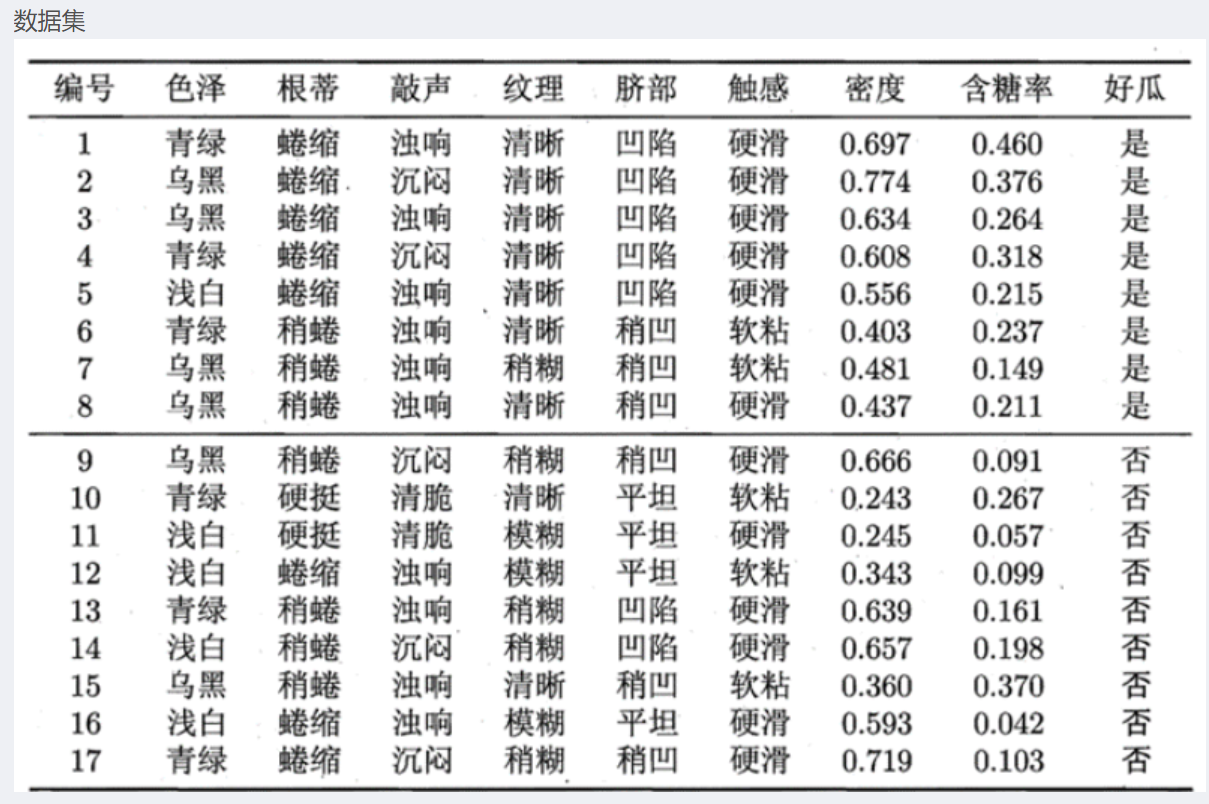
我们手头有一份西瓜数据集(参考第一张图片内容),它包含了西瓜的多个特征信息,如色泽、根蒂、敲声、纹理、脐部、触感、密度、含糖率,以及最重要的标签 —— 是否为好瓜。同时,还有一个测试样本,我们的任务就是利用朴素贝叶斯分类器,根据已有数据集来判断这个测试样本是好瓜还是坏瓜。

3.1 数据预处理
首先,我们需要将数据集整理成 Python 能够处理的格式。为了方便,我们可以使用pandas库来读取和处理数
import pandas as pd
# 读取数据集,假设数据集保存为csv格式,若不是需调整读取方式
data = pd.read_csv('watermelon_data.csv') # 这里需根据实际数据集文件路径调整
# 提取特征和标签
features = data[['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']]
labels = data['好瓜']
# 测试样本
test_sample = pd.DataFrame([['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', 0.697, 0.460]],
columns=['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率'])3.2 计算先验概率
计算好瓜和坏瓜的先验概率,也就是在数据集中好瓜和坏瓜各自出现的频率。
# 计算好瓜和坏瓜的数量
num_good_watermelon = len(labels[labels == '是'])
num_bad_watermelon = len(labels[labels == '否'])
total_num = len(labels)
# 计算先验概率
prior_good = num_good_watermelon / total_num
prior_bad = num_bad_watermelon / total_num3.3 计算条件概率
对于离散型特征(色泽、根蒂等),计算在好瓜和坏瓜条件下各个特征取值出现的概率;对于连续型特征(密度、含糖率),这里简单假设服从均匀分布来计算概率(实际中常假设高斯分布,此处简化处理)
# 计算离散特征的条件概率
def calculate_discrete_prob(feature_name, feature_value, label):
subset = features[labels == label]
num = len(subset[subset[feature_name] == feature_value])
return num / len(subset)
# 计算连续特征的条件概率(简化均匀分布假设)
def calculate_continuous_prob(feature_name, feature_value, label):
subset = features[labels == label][feature_name]
min_val = subset.min()
max_val = subset.max()
if max_val - min_val == 0:
return 1 if min_val == feature_value else 0
return 1 / (max_val - min_val) if min_val <= feature_value <= max_val else 03.4 计算后验概率并分类及结果
根据朴素贝叶斯公式计算测试样本属于好瓜和坏瓜的后验概率,比较大小进行分类。
# 计算测试样本属于好瓜的后验概率
posterior_good = prior_good
for feature_name in features.columns:
if feature_name in ['密度', '含糖率']:
feature_value = test_sample[feature_name].values[0]
posterior_good *= calculate_continuous_prob(feature_name, feature_value, '是')
else:
feature_value = test_sample[feature_name].values[0]
posterior_good *= calculate_discrete_prob(feature_name, feature_value, '是')
# 计算测试样本属于坏瓜的后验概率
posterior_bad = prior_bad
for feature_name in features.columns:
if feature_name in ['密度', '含糖率']:
feature_value = test_sample[feature_name].values[0]
posterior_bad *= calculate_continuous_prob(feature_name, feature_value, '否')
else:
feature_value = test_sample[feature_name].values[0]
posterior_bad *= calculate_discrete_prob(feature_name, feature_value, '否')
# 比较后验概率并分类
if posterior_good > posterior_bad:
result = '是(好瓜)'
else:
result = '否(坏瓜)'
print(f"测试样本是好瓜的概率: {posterior_good}")
print(f"测试样本是坏瓜的概率: {posterior_bad}")
print(f"分类结果: {result}")
四、总结与拓展
通过上述代码,我们成功地利用朴素贝叶斯分类器对测试西瓜样本进行了好坏判断。在实际应用中,朴素贝叶斯分类器在文本分类、垃圾邮件过滤、情感分析等众多领域都有着广泛的应用。
当然,本文的实现过程中对于连续型特征的处理进行了简化。在更严谨的实现中,对于密度、含糖率这样的连续型特征,通常会假设其服从高斯分布,通过计算均值和方差来准确计算概率密度函数值。同时,还可以进一步优化代码,比如使用更高效的数据结构,或者结合scikit - learn库中已经封装好的朴素贝叶斯模型来提升效率和准确性。
希望通过这篇博客,大家能对朴素贝叶斯分类器的原理和应用有更深入的理解,也欢迎大家在评论区交流探讨,分享自己的学习心得和疑问。
请注意,在实际运行代码时,需要确保数据集文件路径正确,并且根据实际情况合理调整代码中的假设和处理方式。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









