




创建数据库
在创建数据库之前,应该有充分的规划
- 规划数据库的表、索引结构
- 规划构成数据库的文件的组织方式
- 选取全局数据库名
创建数据库需要下面的步骤
- 创建数据库实例的控制文件
- 创建数据文件与日志文件
- 创建神通数据库的系统表和数据字典
- 创建神通数据库的系统视图,并执行部分初始化命令
- 为数据库实例创建一个控制文件 为数据库实例创建一个或多个数据文件
- 为数据库实例创建两个或更多的重做日志组,并创建日志文件
- 设置数据库实例的归档模式 创建 SYSTEM 表空间 创建系统表和数据字典
- 创建系统视图,并执行初始化脚本
创建数据库的命令:
CREATE DATABASE fenix
CONTROLFILE '/home/OSCAR/admin/fenix.ctrl'
DATAFILE '/home/OSCAR/odbs/fenix/fenix.dbf' SIZE 100M
AUTOEXTEND ON NEXT 100M MAXSIZE UNLIMITED
LOGFILE GROUP ('/home/OSCAR/odbs/fenix/REDO01.log') SIZE 100M
LOGFILE GROUP ('/home/OSCAR/odbs/fenix/REDO02.log') SIZE 50M
LOGFILE GROUP ('/home/OSCAR/odbs/fenix/REDO03.log') SIZE 100M
ARCHIVELOG '/home/OSCAR/arch/'
注意事项:
- 创建数据库完成后,用户应当对数据库做一次完整地备份,以保证数据库能够从介质故障完全恢复;
- 创建的在线重做日志数量至少应有 1 个;
- 为保证在断电情况下数据库的一致性,务必禁用磁盘缓存;
- 创建数据库只能在数据库非启动状态下运行,即在命令行中输入神通数据库进入交互界面,也可使用交 互式的数据库配置程序。
启动数据库
- 交互式启动
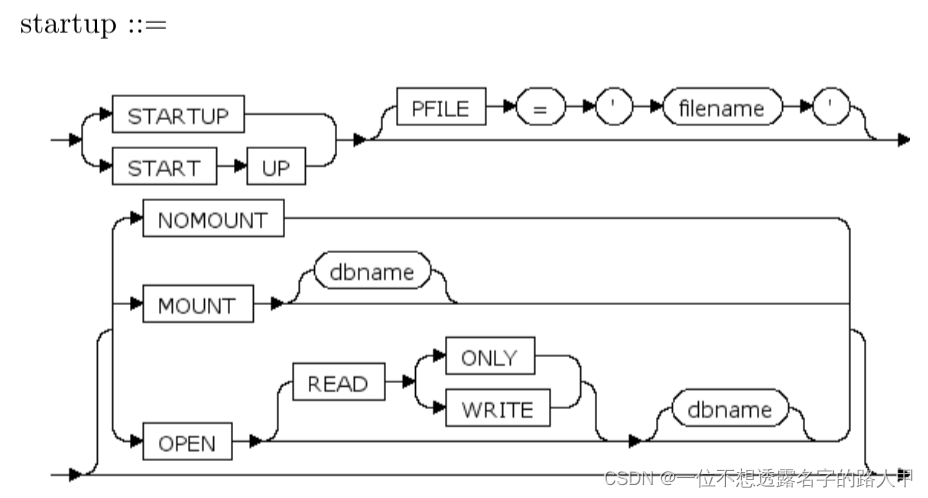
其中,
- NOMOUNT:启动一个实例,启动一实例的处理包含分配一个数据库信息使用的内存共享区和后台线程的建立。实例 起动的执行先于该实例装载一数据库。如果仅启动实例,则没有数据库与内存储结构和线程相联系。
- MOUNT:装载指定的数据库。装配数据库是将一数据库与已启动的实例相联。如果不指定 dbname,则使用默认 的数据库。
- OPEN:打开一数据库,打开一数据库是使数据库可以进行正常数据库操作的处理。当一数据库打开,所有用户 可连接到该数据库来存取其信息
- READ ONLY:表示以只读方式启动数据库
- READ WRITE:表示以读写方式启动数据库
- 命令行启动
- -o normal 表示正常模式启动
- -r 表示 READ ONLY
- -d dbname 表示启动 dbname 数据库
- -p file 表示 PFILE = ‘file’
- -o ni 表示非交互模式启动 (NonInteractive),用于启动服务
- DBA管理工具启动
- 服务方式启动
神通数据库启动过程
- 启动一个实例:
启动一个实例的处理包含分配一个数据库信息使用的内存共享区和后台线程的建立。实例启动的执行先 于该实例装载一个数据库。如果仅启动实例,则没有数据库与存储结构和进程相联系。
在这个状态下,可以创建数据库。 - 装载一个数据库
装配数据库是将一个数据库与已启动的实例相联。当实例安装一个数据库之后,该数据库保持关闭,仅 DBA 可存取。 在这个状态下,允许 DBA 做一些专门的维护操作,比如,增加日志文件组等任务只能当数据库在
mount 状态时执行。 - 打开一个数据库
打开一个数据库是使数据库可以进行正常数据库操作的处理。当一个数据库打开所有用户可连接到该数 据库用存取其信息。在数据库打开时,数据文件和日志文件也被打开
数据库可访问性控制
- 装载数据库:ALTER DATABASE MOUNT;
- 打开一个关闭的数据库:ALTER DATABASE OPEN;
- 指定只读/读写方式打开数据库;
ALTER DATABASE OPEN READ ONLY;
ALTER DATABASE OPEN READ WRITE;
关闭数据库
- normal选项:
SHUTDOWN NORMAL; - immediate选项:
SHUTDOWN IMMEDIATE; - transactional选项:
SHUTDOWN TRANSACTIONAL; - abort选项:
SHUTDOWN ABORT
挂起/恢复数据库
挂起:alter system suspend;
恢复:alter system resume;

















 1028
1028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









