






Apache Spark
适用场景
以批处理闻名,有专门用于机器学习的相关类库进行复杂的计算,有SparkSQL可以进行简单的交互式查询,也可以使用DataSet,RDD,DataFrame进行复杂的ETL操作。
关键词
- 处理数据量大
- 批计算
- 微批计算(可以理解成支持流计算)
- 机器学习(丰富的类库)
- SQL查询(操作简单)
- 内存计算(计算效率高,相对MapReduce而言)
- 内存开销大(通过SparkConf配置driver/executor参数,详见Spark内存管理模型,主要依赖于JVM进行内存回收)
- 抽象出了RDD进行操作,开发相对简单,又可以写比SQL复杂的ETL操作
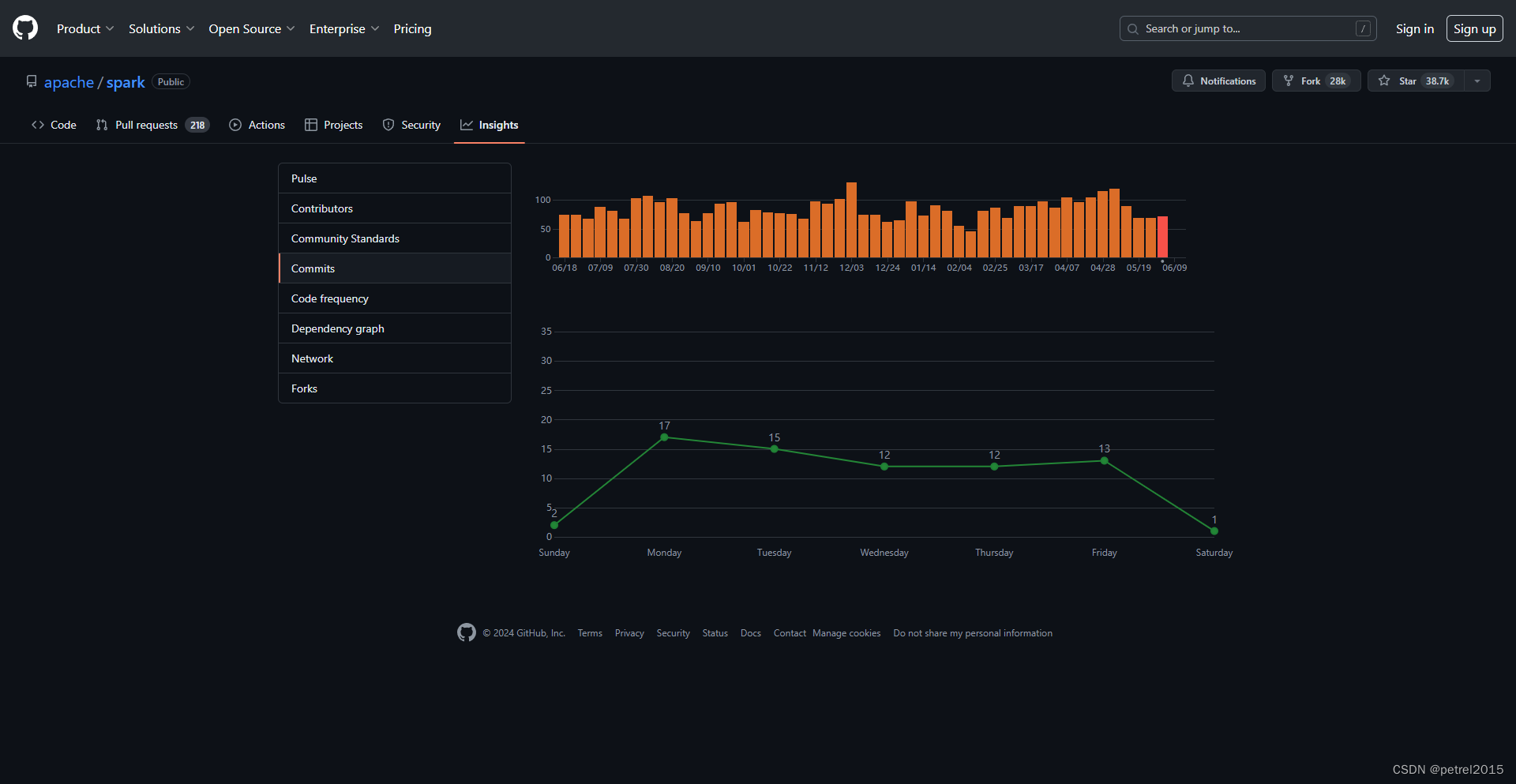
社区活跃程度:非常活跃
近一年,2023.6至2024.6,大约每周70个commit左右
Apache Flink
适用场景
具有高吞吐量、低延迟、容错性强等特点。比如实时告警系统,日志实时分析,金融交易异常检测。
关键词
- 流计算(天生设计是为了进行流计算,不像Spark通过微批来实现流计算)
- 事件驱动,响应快
- 流批一体,通过统一的编程模型,可以实现开发一套代码,同时进行流处理、批处理
- 数据集成,Flink支持多种数据源,如Kafka,HDFS,Cassandra,ElasticSearch
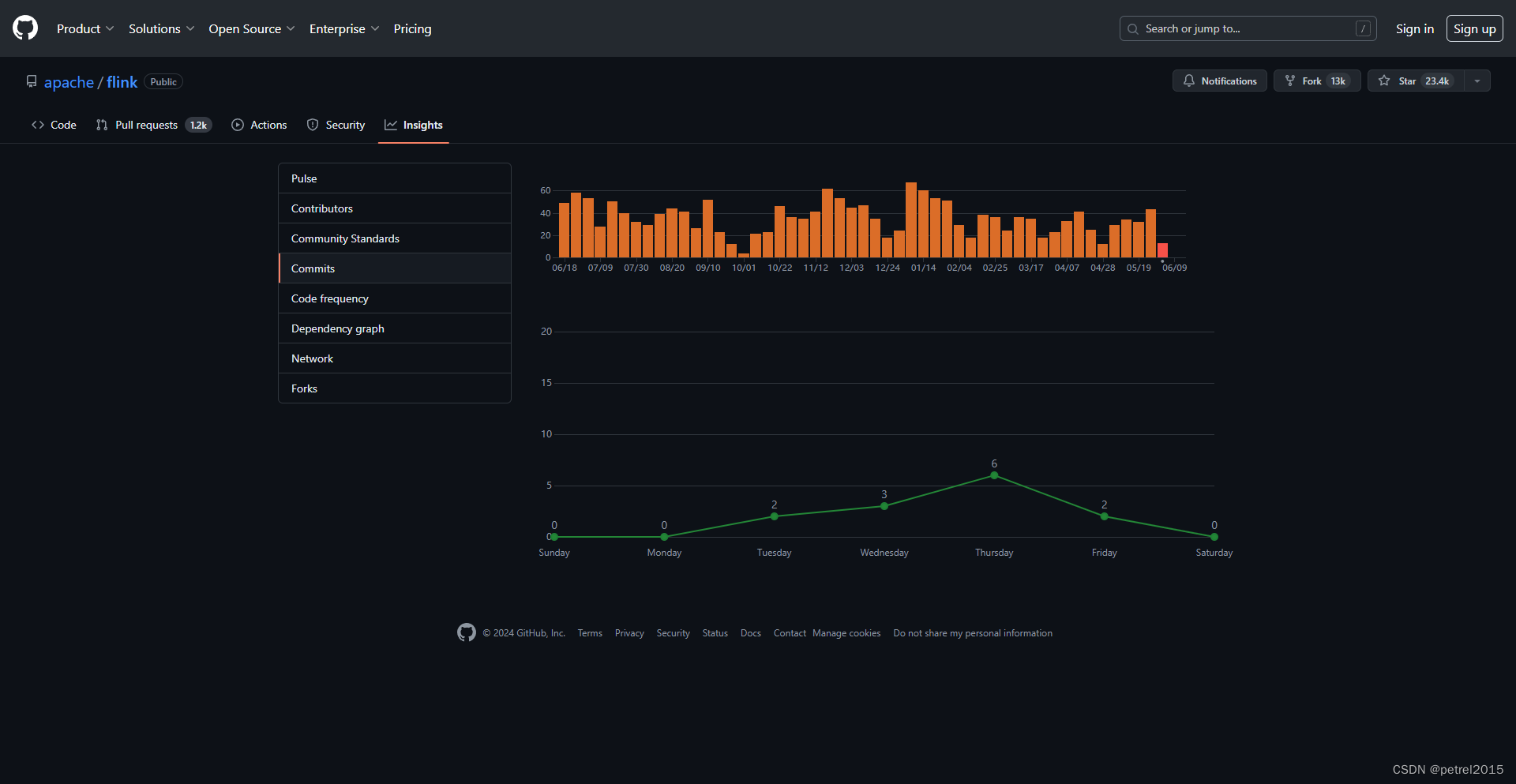
社区活跃程度:活跃
近一年,2023.6至2024.6,大约每周30个commit左右
Apache Storm
适用场景
具有高吞吐量、低延迟、容错性强等特点。比如实时告警系统,日志实时分析,金融交易异常检测。
关键词
- 流计算,实时处理
- 可靠性和容错性,节点故障自动重启和恢复任务
- 水平扩展
- 数据集成,支持多种数据源,如Kafka,HDFS,Cassandra
社区活跃程度:不活跃
近一年,2023.6至2024.6,大约每周不到10个commit

Apache Beam
适用场景
beam侧重点是一种编程模型,编写一次,可以运行在不同的流批引擎,有点像Flink提供的流批一体能力。减轻了开发人员学习各个引擎的特点,调优方法,让开发人员聚焦于业务逻辑。如果更侧重于性能,那毫不犹豫地应该选择具体的引擎比如Spark,Flink。但如果是为了更加通用的实现业务逻辑,可以使用Beam,避免将大量时间花费对各个引擎的学习。
关键词
- 统一的编程模型:用于定义和执行大规模的数据处理任务。它旨在提供一种通用的编程接口,可以在不同的执行引擎上运行
- 批处理和流处理:提供统一的编程模型来处理有界和无界的数据集。
- 跨平台执行:Beam 的跨平台执行能力使得用户可以选择最适合其需求的执行引擎,并在不同执行引擎之间轻松迁移。
- 窗口化和触发器:Beam 的窗口化和触发器机制使得处理无界数据流更加灵活和高效,适用于实时数据处理和分析。
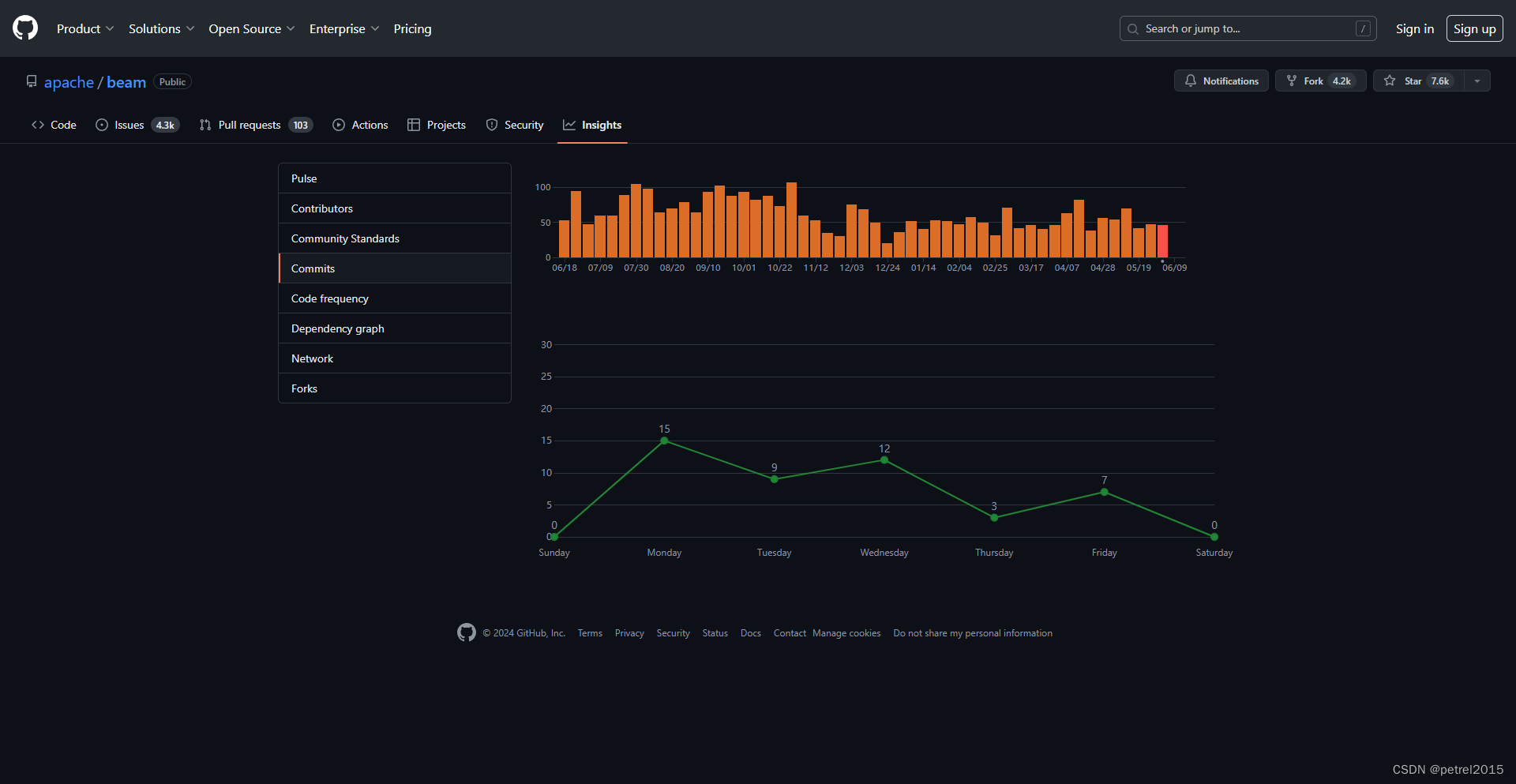
社区活跃程度:活跃
近一年,2023.6至2024.6,大约每周50个commit
总结
就以上介绍的4个框架来说。
如果要进行机器学习,毫不犹豫地选择Spark。
如果不需要流计算,或者流计算要求不高,可以使用Spark,比Flink发展更成熟。
如果业务场景明确需要流计算(实时,低延迟,高吞吐量),毫不犹豫地选择Flink。
如果想聚焦业务逻辑,对性能要求不高,可以使用Beam。
Storm几乎可以说完全被Flink超越了,社区活跃程度Flink远超过Storm。从性能上来看,可以见美团技术写的这篇博客(https://tech.meituan.com/2017/11/17/flink-benchmark.html)该篇文章对Flink和Storm进行了性能测试,从不同场景,数据量进行了测试。如果没有历史包袱,从头选择流处理框架,可以毫不犹豫地选择Flink。

















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









