







 本文详细介绍了PostgreSQL存储过程的各个方面,包括其优点、基本结构、PL/pgSQL语法、赋值语法、返回值类型、控制结构、调用方法、游标及事务管理。通过学习,读者将能够掌握如何创建和使用存储过程,以提高数据库操作的效率和代码的可复用性。
本文详细介绍了PostgreSQL存储过程的各个方面,包括其优点、基本结构、PL/pgSQL语法、赋值语法、返回值类型、控制结构、调用方法、游标及事务管理。通过学习,读者将能够掌握如何创建和使用存储过程,以提高数据库操作的效率和代码的可复用性。
前面介绍了 PostgreSQL 数据类型和运算符、常用函数、锁操作、执行计划、视图与触发器相关的知识点,今天我将详细的为大家介绍 PostgreSQL 存储过程相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
工作中可能会存在业务比较复杂,重复性工作比较多,需要批量处理数据的情况,此时使用存储过程会方便很多,存储过程的执行效率也会快很多,能帮助我们节省很多代码和时间。
并且,将需要的sql写成存储过程并设置成定时任务,那样在任意时刻,需要执行任意次数都可以根据你的设定执行,哪怕你不在工位上,减少你的工作量,能让你更愉快的摸鱼(不是)。
PostgreSQL 概述
在 PostgreSQL 中,除了标准 SQL 语句之外,通过创建复杂的过程和函数来满足程序需要,我们称为存储过程和自定义函数(User-Defined Function)。它有助于您执行通常在数据库中的单个函数中进行多次查询和往返操作的操作。
PL/pgSQL 简单易学,无论是否具有编程基础都能够很快学会。PL/pgSQL 存储过程,它和 Oracle PL/SQL 非常类似,是 PostgreSQL默认支持的存储过程,下面针对优缺点给大家做了简要分析。
优点
-
减少应用和数据库之间的网络传输。所有的 SQL 语句都存储在数据库服务器中,应用程序只需要发送函数调用并获取除了结果,避免了发送多个 SQL 语句并等待结果。
-
提高应用的性能。因为自定义函数和存储过程进行了预编译并存储在数据库服务器中。
-
可重用性。存储过程和函数的功能可以被多个应用同时使用。
-
作为脚本使用,如产品的 liquibase 中, 清理或修复数据将非常好用。
缺点
-
导致软件开发缓慢。因为存储过程需要单独学习,而且很多开发人员并不具备这种技能。
-
不易进行版本管理和代码调试。
-
不同数据库管理系统之间无法移植,语法存在较大的差异。
-
更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
存储过程基本结构
定义一个函数
CREATE [ OR REPLACE ] FUNCTION
name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
[ RETURNS rettype
| RETURNS TABLE ( column_name column_type [, ...] ) ]
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| WINDOW
| IMMUTABLE | STABLE | VOLATILE | [ NOT ] LEAKPROOF
| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| PARALLEL { UNSAFE | RESTRICTED | SAFE }
| COST execution_cost
| ROWS result_rows
| SUPPORT support_function
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
由官方文档得到的定义一个函数的语法,当然现实中不需要所有的要素都要定义到。现在就常用的要素做出解释。
-
CREATE FUNCTION定义一个新函数。CREATE OR REPLACE FUNCTION将创建一个新函数或者替换一个现有的函数
-
name:表示要创建的函数名
-
argmode:一个参数的模式:IN、OUT、INOUT或者VARIADIC。如果省略,默认为IN。只有OUT参数能跟在一个VARIADIC参数后面。还有,OUT和INOUT参数不能和RETURNS TABLE符号一起使用。
-
argname:一个参数的名称
-
argtype:该函数参数的数据类型
-
default_expr:如果参数没有被指定值时要用作默认值的表达式
-
rettype:返回的数据类型,如果该函数不会返回一个值,可以指定返回类型为void。(后面详细讲)
-
column_name:RETURNS TABLE语法中一个输出列的名称
-
culumn_type:RETURNS TABLE语法中的输出列的数据类型
注意:定义函数的时候,参数可以是空,但是哪怕不修改函数体只修改参数,它会得到一个新的函数。更多关于大数据 PostgreSQL 系列的学习文章,请参阅:PostgreSQL 数据库,本系列持续更新中。
PL/pgSQL 的结构
[ <<label>> ]
[ DECLARE
declarations ]
BEGIN
statements
END [ label ];
PL/pgSQL是一种块结构的语言。一个函数体的完整文本必须是一个块。存储过程的语法如上所示。
-
在一个块中的每一个声明和每一个语句都由一个分号终止。
-
所有的关键词都是大小写无关的。除非被双引号引用,标识符会被隐式地转换为小写形式,就像它们在普通 SQL 命令中。
-
PL/pgSQL代码中的注释和普通 SQL 中的一样。一个双连字符(–)开始一段注释,它延伸到该行的末尾。一个/* 开始一段块注释,它会延伸到匹配*/出现的位置。块注释可以嵌套。
赋值语法
声明变量赋值
具体可看官方文档
name [ CONSTANT ] type [ COLLATE collation_name ] [ NOT NULL ] [ { DEFAULT | := | = } expression ];
在自定义函数中声明一个变量,并给这个变量赋值的时候可以用这个方法。示例如下:
-- 1
declare a integer default 32;
-- 2
declare a integer :=32;
-- 3
declare a integer;
a :=32;
这三种方法都能将声明一个变量a,并且将32赋值给a。若不给a赋值,就是方法三中没有a:=32;也不会报错,就是变量a初始化为sql空值。
-
constant:若是增加constant,则表示该变量的值无法修改
-
collate:给该变量指定一个排序规则
-
not null:如果给改变量赋值为空值会报错
例如,以下方式就会报错。
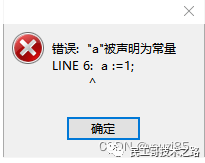
-- 报错1
-- 加了constant,已经无法修改a的值了。
declare a constant integer default 32;
a :=1;
-- 报错2
-- 在声明变量的时候选择了not null,就应该在声明时赋值,否则哪怕后面赋值还是会报错
declare a integer not null;
a :=32;

动态赋值
具体可查看官方文档
方式一:into子句
SELECT select_expressions INTO [STRICT] target FROM ...;
INSERT ... RETURNING expressions INTO [STRICT] target;
UPDATE ... RETUR 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









