







 这篇博客深入探讨了C++11中的并发编程,重点介绍了std::thread的使用,包括构造函数、赋值操作、线程管理函数等。此外,还详细讲解了std::mutex、std::recursive_mutex、std::timed_mutex等互斥量,以及std::lock_guard和std::unique_lock的区别和用法。文章还提到了std::promise和std::packaged_task在异步编程中的作用,并简要讨论了C++11的内存模型和不同的内存序。最后,通过四个生产者消费者模型的实例展示了并发编程的应用。
这篇博客深入探讨了C++11中的并发编程,重点介绍了std::thread的使用,包括构造函数、赋值操作、线程管理函数等。此外,还详细讲解了std::mutex、std::recursive_mutex、std::timed_mutex等互斥量,以及std::lock_guard和std::unique_lock的区别和用法。文章还提到了std::promise和std::packaged_task在异步编程中的作用,并简要讨论了C++11的内存模型和不同的内存序。最后,通过四个生产者消费者模型的实例展示了并发编程的应用。
前言
首先需要说明,本博客的主要内容参考自Forhappy && Haippy博主的分享,本人主要是参照博主的资料进行了学习和总结,并适当的衍生或补充了相关的其他知识内容。
C++11有了std::thread 以后,可以在语言层面编写多线程程序了,直接的好处就是多线程程序的可移植性得到了很大的提高。
C++11 新标准中引入了四个头文件来支持多线程编程,他们分别是,,,和。
:该头文主要声明了两个类, std::atomic 和 std::atomic_flag,另外还声明了一套 C 风格的原子类型和与 C 兼容的原子操作的函数。
:该头文件主要声明了 std::thread 类,另外 std::this_thread 命名空间也在该头文件中。
:该头文件主要声明了与互斥量(mutex)相关的类,包括 std::mutex 系列类,std::lock_guard, std::unique_lock, 以及其他的类型和函数。
:该头文件主要声明了与条件变量相关的类,包括 std::condition_variable 和 std::condition_variable_any。
:该头文件主要声明了 std::promise, std::package_task 两个 Provider 类,以及 std::future 和 std::shared_future 两个 Future 类,另外还有一些与之相关的类型和函数,std::async() 函数就声明在此头文件中。
1. HelloWorld
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <thread>
using namespace std;
void thread_task()
{
cout << "Hello World!" << std::endl;
}
int main(int argc, const char *argv[])
{
thread t(thread_task);
t.join();
system("pause");
return 0;
}
2. Thread Constructor
1)默认构造函数:thread() noexcept,创建一个空的 thread 执行对象。
2)初始化构造函数: template
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
#include <functional>
#include <atomic>
using namespace std;
void exec_proc1(int n)
{
for (int i = 0; i < 5; ++i) {
cout << "pass value, executing thread " << n << endl;
//阻止线程运行到10毫秒
this_thread::sleep_for(chrono::milliseconds(10));
}
}
void exec_proc2(int& n)
{
for (int i = 0; i < 5; ++i) {
cout << "pass reference, executing thread " << n << endl;
++n;
//阻止线程运行到10毫秒
this_thread::sleep_for(chrono::milliseconds(10));
}
}
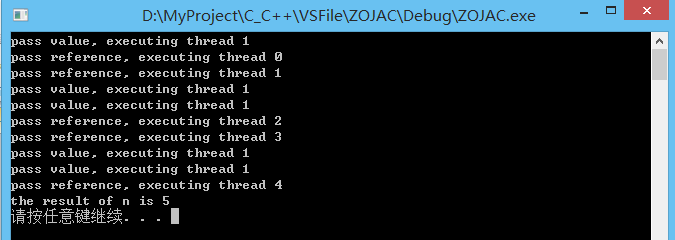
int main()
{
int n = 0;
// t1,使用默认构造函数,什么都没做
thread t1;
// t2,使用有参构造函数,传入函数名称(地址)exec_pro1,并以传值的方式传入args
// 将会执行exec_proc1中的代码
thread t2(exec_proc1, n + 1);
// t3,使用有参构造函数,传入函数名称(地址)exec_pro1,并以传引用的方式传入args
// 将会执行exec_proc1中的代码
thread t3(exec_proc2, ref(n));
// t4,使用移动构造函数,由t4接管t3的任务,t3不再是线程了
thread t4(move(t3));
// 可被 joinable 的 thread 对象必须在他们销毁之前被主线程 join 或者将其设置为 detached.
t2.join();
t4.join();
cout << "the result of n is " << n << endl;
system("pause");
return 0;
}
3. 赋值操作
1)move 赋值操作:thread& operator= (thread&& rhs) noexcept,如果当前对象不可 joinable,需要传递一个右值引用(rhs)给 move 赋值操作;如果当前对象可被 joinable,则 terminate() 报错。
2)拷贝赋值操作被禁用:thread& operator= (const thread&) = delete,thread 对象不可被拷贝。
#include <stdio.h>
#include <stdlib.h>
#include <chrono>
#include <iostream>
#include <thread>
using namespace std;
void exec_produce(int duration) {
//阻止线程运行到duration秒
this_thread::sleep_for(chrono::seconds(duration));
//this_thread::get_id()获取当前线程id
cout << "exec_produce thread " << this_thread::get_id()
<< " has sleeped " << duration << " seconds" << endl;
}
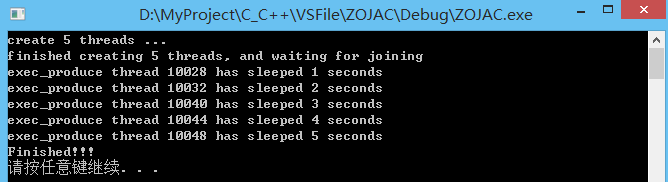
int main(int argc, const char *argv[])
{
thread threads[5];
cout << "create 5 threads ..." << endl;
for (int i = 0; i < 5; i++) {
threads[i] = thread(exec_produce, i + 1);
}
cout << "finished creating 5 threads, and waiting for joining" << endl;
//下面代码会报错,原因就是copy操作不可用,相当于是delete操作,所以报错
/*for(auto it : threads) {
it.join();
}*/
for (auto& it: threads) {
it.join();
}
cout << "Finished!!!" << endl;
system("pause");
return 0;
}
其他相关函数作用说明
1)get_id() 获取线程 ID。
2)joinable() 检查线程是否可被 join
3)join() Join 线程。
4)detach() Detach 线程
5)swap() Swap 线程
6)native_handle() 返回 native handle。
7)hardware_concurrency() 检测硬件并发特性
4. std::mutex
mutex 又称互斥量,C++ 11中与 mutex 相关的类(包括锁类型)和函数都声明在 头文件中,所以如果需要使用 std::mutex,就必须包含 头文件,mutex中包含以下:
mutex系列类
std::mutex,最基本的 mutex类
std::recursive_mutex,递归 mutex类
std::time_mutex,定时 mutex类。
std::recursive_timed_mutex,定时递归 mutex类
lock 类
std::lock_guard,与 mutex RAII 相关,方便线程对互斥量上锁
std::unique_lock,与 mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制
其他类型
std::once_flag
std::adopt_lock_t
std::defer_lock_t
std::try_to_lock_t
函数
std::try_lock(),尝试同时对多个互斥量上锁。
std::lock(),可以同时对多个互斥量上锁。
std::call_once(),如果多个线程需要同时调用某个函数,call_once 可以保证多个线程对该函数只调用一次。
(1)std::mutex
std::mutex 是C++11 中最基本的互斥量,std::mutex 对象提供了独占所有权的特性——即不支持递归地对 std::mutex 对象上锁,而 std::recursive_lock 则可以递归地对互斥量对象上锁。
std::mutex 的成员函数
1)构造函数,std::mutex不允许拷贝构造,也不允许 move 拷贝,最初产生的 mutex 对象是处于 unlocked 状态的。
2)lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
3)unlock(), 解锁,释放对互斥量的所有权。
4)try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
/**
就像大家更熟悉的const一样,volatile是一个类型修饰符(type specifier)。
它是被设计用来修饰被不同线程访问和修改的变量。如果不加入volatile,
基本上会导致这样的结果:要么无法编写多线程程序,要么编译器失去大量优化的机会。
**/
volatile int counter = 0;
const int MAX_TIMES_VALUE = 10000;
mutex my_mutex;
void my_task() {
for (int i = 0; i < MAX_TIMES_VALUE; ++ i) {
//尝试获取锁,try_lock()失败时返回false
if (my_mutex.try_lock()) {
++counter;
my_mutex.unlock();
}
}
}
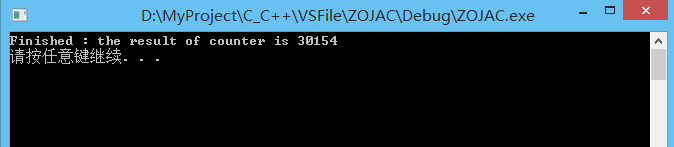
int main() {
thread threads[10];
for (int i = 0; i < 10; ++ i) {
threads[i] = thread(my_task);
}
for (auto& it : threads) {
it.join();
}
cout << "Finished : the result of counter is " << counter << endl;
system("pause");
return 0;
}
(2)std::recursive_mutex
std::recursive_mutex 与 std::mutex 一样,也是一种可以被上锁的对象,但是和 std::mutex 不同的是,std::recursive_mutex 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
(3)std::time_mutex
std::time_mutex 比 std::mutex 多了两个成员函数,try_lock_for(),try_lock_until()
try_lock_for() 函数接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex 的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until() 函数则接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
#include <iostream>
#include <chrono>
#include <thread>
#include <mutex>
using namespace std;
timed_mutex my_mutex;
void my_task(int val, char tag) {
//每200ms尝试获取锁,如果获取到跳出while循环,否则输出一次线程编号
//比如0-200ms,在200ms之前如果获取不到锁,则线程阻塞,时间到了200ms如果取得了锁,
//则加锁,否则返回false
while (!my_mutex.try_lock_for(chrono::milliseconds(200))) {
//int pid = this_thread::get_id().hash();
cout << val;
}
//成功取得锁,然后将线程sleep到1000ms
this_thread::sleep_for(chrono::milliseconds(1000));
cout << tag << endl;
my_mutex.unlock();
}
int main ()
{
thread threads[10];
char end_tag[] = {
'!', '@', '#', '$', '%', '^', '&', '*', '(', ')'};
//创建10个线程,分别执行my_task()中的代码
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task, i, end_tag[i]);
}
for (auto& it : threads) {
it.join();
}
system("pause");
return 0;
}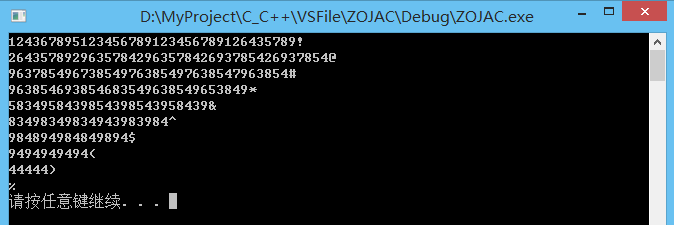
结果分析:
0-9号线程从0ms时刻开始运行,由于线程调度的随机性,假使最开始运行的是0号线程,则0号线程可以在0ms时刻便取得锁,这时候0号线程持锁sleep,这时线程调度会去执行1-9号线程,显然这时是无法取得锁的,所以什么调用try_lock_for()在0-200ms内去尝试取锁,在200ms之前由于取不到锁会分别阻塞,到了200ms这个时刻由于取锁失败,try_lock_for()返回false,所以在200ms这个时刻会在控制台中输出1-9这九个字符,之后类似的,直到到了1000ms这个时刻,0号线程释放了锁,并输出与其对应的tag。
之后的过程便成了9个线程的调度执行的过程了,和上面描述基本类似的过程。
(4)std::recursive_timed_mutex
和 std:recursive_mutex 与 std::mutex 的关系一样,std::recursive_timed_mutex 的特性也可以从 std::timed_mutex 推导出来
(5)std::lock_guard
与 mutex RAII 相关,方便线程对互斥量上锁,是一种自解锁。std::lock_guard是一个局部变量,创建时,对mutex 上锁,析构时对mutex解锁。这个功能在函数体比较长,尤其是存在多个分支的时候很有用
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex my_mutex;
void print (int x) {
cout << "value is " << x;
cout << endl;
this_thread::sleep_for(chrono::milliseconds(200));
}
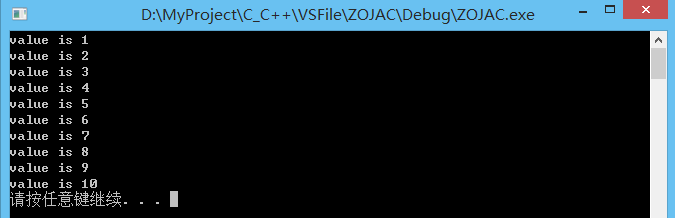
void my_task (int id) {
// lock_guard创建局部变量my_lock,会在lock_guard的构造方法中对my_mutex加锁
lock_guard<mutex> my_lock (my_mutex);
//由于自解锁的作用,下面的代码相当于临界区,执行过程不会被打断
print(id);
//运行结束时会析构my_lock,然后在析构函数中对my_mutex解锁
}
int main ()
{
thread threads[10];
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task,i+1);
}
for (auto& th : threads) {
th.join();
}
system("pause");
return 0;
}
(6)std::unique_lock
与 mutex RAII 相关,方便线程对互斥量上锁,但提供了更好的上锁和解锁控制,相对于std::lock_guard来说,std::unique_lock更加灵活,std::unique_lock不拥有与其关联的mutex。构造函数的第二个参数可以指定为std::defer_lock,这样表示在构造unique_lock时,传入的mutex保持unlock状态。然后通过调用std::unique_lock对象的lock()方法或者将将std::unique_lock对象传入std::lock()方法来锁定mutex。
std::unique_lock比std::lock_guard需要更大的空间,因为它需要存储它所关联的mutex是否被锁定,如果被锁定,在析构该std::unique_lock时,就需要unlock它所关联的mutex。std::unique_lock的性能也比std::lock_guard稍差,因为在lock或unlock mutex时,还需要更新mutex是否锁定的标志。大多数情况下,推荐使用std::lock_guard但是如果需要更多的灵活性,比如上面这个例子,或者需要在代码之间传递lock的所有权,这可以使用std::unique_lock,std::unique_lock的灵活性还在于我们可以主动的调用unlock()方法来释放mutex,因为锁的时间越长,越会影响程序的性能,在一些特殊情况下,提前释放mutex可以提高程序执行的效率。
使用std::unique_lock默认构造方法和std::lock_guard类似,多了可以主动unlock,其他相当于一个自解锁,所以类似于unique_lock my_lock(my_mutex)的用法就不再举例。
下面举例使用两个参数构造使用,和锁的所有权传递问题
#include <iostream>
#include <thread>
#include <mutex>
using namespace std;
mutex my_mutex;
mutex some_mutex;
//使用含两个参数的构造函数
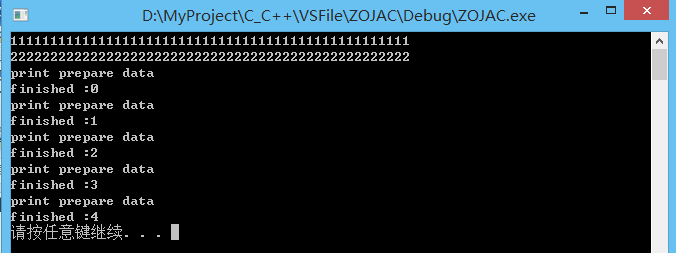
void my_task (int n, char c) {
unique_lock<mutex> my_lock (my_mutex, defer_lock);
my_lock.lock();
for (int i=0; i<n; ++i) {
cout << c;
}
cout << endl;
//会自动unlock
}
unique_lock<mutex> prepare_task()
{
unique_lock<mutex> lock(some_mutex);
cout << "print prepare data" << endl;
//返回对some_mutex的所有权,尚未解锁
return lock;
}
void finish_task(int v)
{
//取得prepare_task创建的锁所有权
unique_lock<mutex> lk(prepare_task());
cout << "finished :" << v << endl;
//析构,解锁
}
int main ()
{
thread t1 (my_task, 50, '1');
thread t2 (my_task, 50, '2');
t1.join();
t2.join();
thread threads[5];
for(int i = 0; i < 5; ++ i)
{
threads[i] = thread(finish_task, i);
}
for(auto& it : threads) {
it.join();
}
system("pause");
return 0;
}
其他不同构造函数使用方法简介
1)try-locking :unique_lock(mutex_type& m, try_to_lock_t tag)
新创建的 unique_lock 对象管理 mutex 对象 m,并尝试调用 m.try_lock() 对 mutex 对象进行上锁,但如果上锁不成功,并不会阻塞当前线程。
2)deferred :unique_lock(mutex_type& m, defer_lock_t tag) noexcept
新创建的 unique_lock 对象管理 mutex 对象 m,但是在初始化的时候并不锁住 mutex 对象。m 应该是一个没有当前线程锁住的 mutex 对象。
3)adopting :unique_lock(mutex_type& m, adopt_lock_t tag)
新创建的 unique_lock 对象管理 mutex 对象 m, m 应该是一个已经被当前线程锁住的 mutex 对象。(并且当前新创建的 unique_lock 对象拥有对锁(Lock)的所有权)。
4)locking for:template
#include <iostream>
#include <thread>
#include <chrono>
#include <mutex>
using namespace std;
int value;
once_flag value_flag;
void setValue (int x) {
value = x;
}
void my_task (int id) {
this_thread::sleep_for(chrono::milliseconds(1000));
//使setValue函数只被第一次执行的线程执行
call_once (value_flag, setValue, id);
}
int main ()
{
thread threads[10];
for (int i=0; i<10; ++i) {
threads[i] = thread(my_task,i+1);
}
for (auto& it : threads){
it.join();
}
cout << "Finished!! the result of value is : " << value << endl;
system("pause");
return 0;
}
5. std::promise
promise 对象可以保存某一类型 T 的值,该值可被 future 对象读取(可能在另外一个线程中),因此 promise 也提供了一种线程同步的手段。在 promise 对象构造时可以和一个共享状态(通常是std::future)相关联,并可以在相关联的共享状态(std::future)上保存一个类型为 T 的值。
可以通过 get_future 来获取与该 promise 对象相关联的 future 对象,调用该函数之后,两个对象共享相同的共享状态(shared state)
1)promise 对象是异步 Provider,它可以在某一时刻设置共享状态的值。
2)future 对象可以异步返回共享状态的值,或者在必要的情况下阻塞调用者并等待共享状态标志变为 ready,然后才能获取共享状态的值。
入门示例
#include <iostream>
#include <functional>
#include <thread>
#include <future>
using namespace std;
//通过std::future获取共享状态的值
void printShareState(future<int>& state) {
// 获取共享状态的值.
int x = state.get();
cout << "share state value : " << x << endl;
}
int main ()
{
// 创建一个 promise<int> 对象,状态值为int类型
promise<int> prom;
// 和 future 关联
future<int> fut = prom.get_future();
// 将 future 交给另外一个线程t.
thread t(printShareState, ref(fut));
// 设置共享状态的值, 此处和线程t保持同步.
prom.set_value(10);
t.join();
system("pause");
return 0;
}
(1)构造函数
1)默认构造函数promise(),初始化一个空的共享状态。
2)带自定义内存分配器的构造函数template promise (allocator_arg_t aa, const Alloc& alloc),与默认构造函数类似,但是使用自定义分配器来分配共享状态。
3)拷贝构造函数promise (const promise&) = delete,被禁用。
4)移动构造函数promise (promise&& x) noexcept。
另外,std::promise 的 operator= 没有拷贝语义,即 std::promise 普通的赋值操作被禁用,operator= 只有 move 语义,所以 std::promise 对象是禁止拷贝的
#include <iostream>
#include <thread>
#include <future>
using namespace std;
//使用默认构造函数构造一个空共享状态的promise对象
promise<int> prom;
void printShareStateValue () {
future<int> fut = prom.get_future();
int x = fut.get();
cout << "share state value is " << x << endl;
}
int main ()
{
thread t1(printShareStateValue);
prom.set_value(10);
t1.join();
//promise<int>()创建一个匿名空的promise对象,使用移动拷贝构造函数给prom
prom = promise<int>();
thread t2 (printShareStateValue);
prom.set_value (20);
t2.join();
system("pause");
return 0;
}
(2)其他成员函数
1)std::promise::get_future()
该函数返回一个与 promise 共享状态相关联的 future 。返回的 future 对象可以访问由 promise 对象设置在共享状态上的值或者某个异常对象。只能从 promise 共享状态获取一个 future 对象。在调用该函数之后,promise 对象通常会在某个时间点准备好(设置一个值或者一个异常对象),如果不设置值或者异常,promise 对象在析构时会自动地设置一个 future_error 异常(broken_promise)来设置其自身的准备状态
2)std::promise::set_value()
void set_value (const T& val);
void set_value (T&& val);
void promise
#include <iostream>
#include <functional>
#include <thread>
#include <future>
#include <exception>
using namespace std;
void getAnInteger(promise<int>& prom) {
int x;
cout << "input an integer : ";
//设置如试图从不能解析为整数的字符串里想要读一个整数等,顺便说下eof也会造成f 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1709
1709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









