







文章目录
数位dp
应用场景
枚举某个区间中满足某些条件的数字、字符串或组合。
算法原理
原理
数位dp其实就是对一棵n叉树进行dfs剪枝搜索。
n就是数字的进制:一个数位的情况数树的孩子就是数位的种类剪枝的依据就是题目的筛选条件
假如我们需要求解一个区间
[
l
,
r
]
[l, r]
[l,r] 中满足条件check的所有数字,并且告诉你这是一个十进制区间(一般都是10进制),那么我们有一个最简单的做法,那就是O(n)遍历区间
int cnt = 0;
for(int num = l; num <= r; ++num){
if(check(num))cnt++;
}
这个算法非常头铁,它一点剪枝都不做(其实是这样压根剪不了),导致复杂度太高。
数位dp则很好的解决了这个问题,它不会向上述做法一样,直接拿到整个数字来做判断,而是一位一位地拼凑出数字,拼数字的过程中,如果已经得知它继续拼下去也无法满足check时,就可以pass掉,完成了剪枝。
剪枝
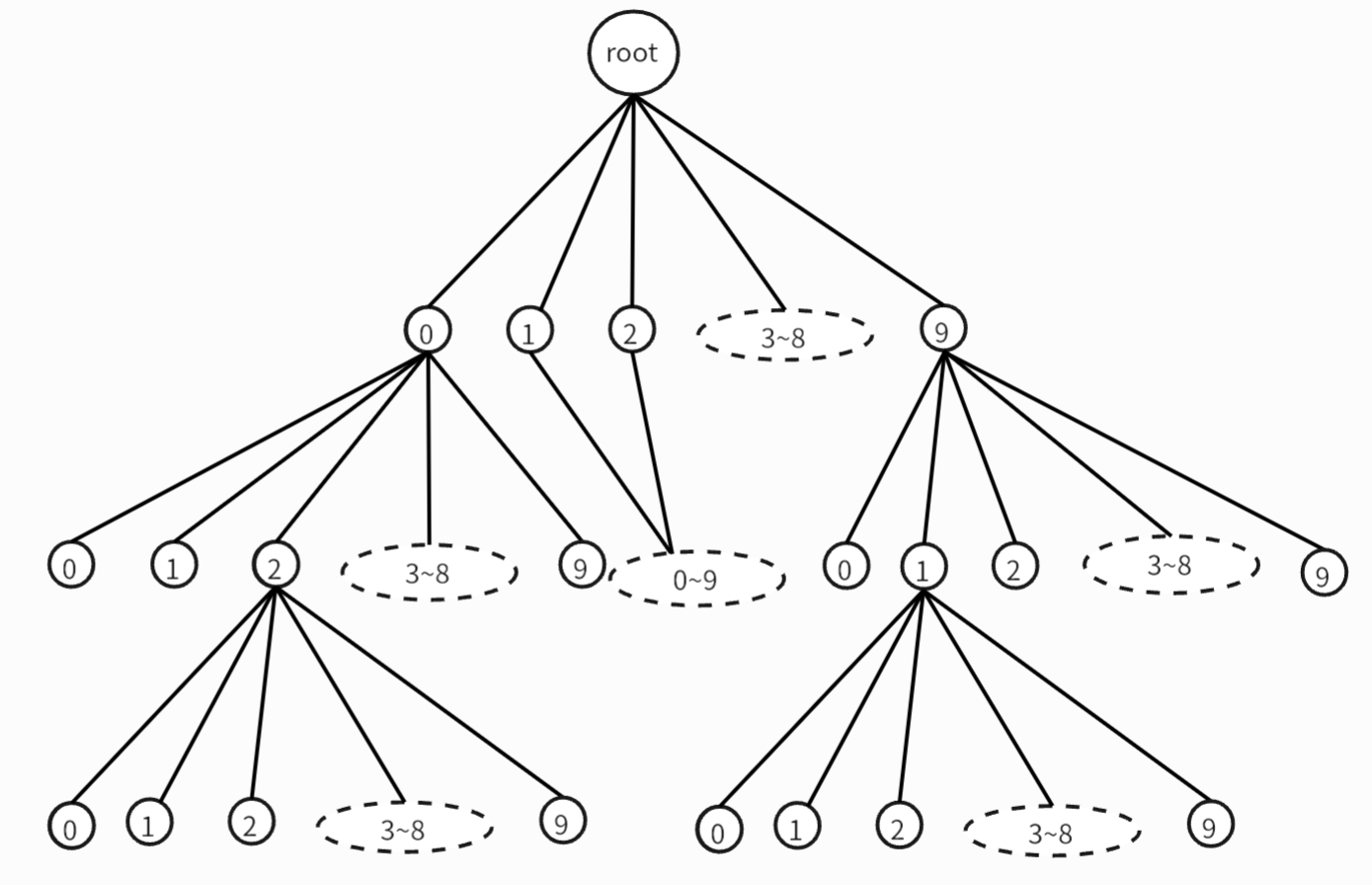
这是一棵10叉树的一部分,假如它是一棵深度为9的满10叉树,那么我们去前序遍历它的时候,就可以得到
[
0
,
1
0
9
−
1
]
[0, 10^9-1]
[0,109−1]的所有数字,并且是按照升序的顺序得到它们,但这比for(int i=l;i<=r;++i)还要差劲地多,因为为了得到一个数字,需要做9次拼接。
但是如果我告诉你,在第一层中,你只能选择数字1,在第二层中,你只能选择数字 { 0 , 1 , 2 } \{0,1,2\} {0,1,2},那么第一层你就剪掉了整棵树的 9 10 \frac9 {10} 109,第二层就可以剪掉剩余的 7 10 \frac7{10} 107,后面的还可以继续剪,看来dp已经赢麻了。
因此,数位dp的难点就在于如何剪枝,剪枝的条件怎么写。
dp模板
关键点
记忆dp模板,有三个关键点:
bound数组- bound ,界限。它是我们控制数字拼接时不超过范围的关键。
- 一般我们只使用上界,下界默认是0,也就是lower_bound={0,0,0,…0}
dfs函数参数:i、flag、argsi:当前是哪一位?它是bound数组的下标索引。flag:目前为止,前面选择的所有数字拼起来是否是上界的前缀?它也是剪枝条件之一。args:它可以没有,也可以有多个,作用是辅助剪枝条件判断。
初始参数传递(假设没有args)dfs(n-1, true)n-1:表示bound的最后一个元素,也就是最高位(因为我们是倒着装数字的)。true:你可以理解成在还没有选择任何数字之前,拼接的数字就是全0,那么确实是上界的前缀,设置成true没毛病。
步骤
数位dp算法步骤
- 求
bound数组(要求两个,一个是l的,一个是r的)
#define ll long long
int boundL[20], boundR[20];
pair<int, int> getBound(ll l ,ll r){
// 因为每次调用dfs,都是求[0, num]之间的情况数
// 所以 ans([l, r]) = ans([0, r] - [0, l-1]),因此 l--
l--;
int idx_l = 0;
while(l > 0){
boundL[idx_l++] = l % 10;
l /= 10;
}
int idx_r = 0;
while(r > 0){
boundR[idx_r++] = r % 10;
r /= 10;
}
return make_pair(idx_l, idx_r);// 我们需要知道数字有多少位
}
这一步几乎是通解,没什么变化。
- 设计dfs函数参数(主要针对
args)
// 返回值往往是int,因为大部分题目都是计数,少部分是void,这种题目往往要求求出具体是那些数字
int dfs(int i, bool flag, T args){// i 和 flag 也是固定参数
// i < 0 表示已经把数字拼接好了
// 这里往往返回1,因为可以走到这一步说明没有被剪掉,这是一个合法数字
if(i < 0)return 1;
// upper 表示可以选择的最大数字,如果前面所有数字都使用了最大值(都使用了bound中的值),
// 那么这里的最大值就需要有bound[i]决定,否则就是9(因为是10进制)
int upper = flag ? bound[i] : 9;
int res = 0;
// 现在开始前序遍历,枚举所有孩子(0~upper)
for(int k = 0; k <= upper; ++k){
// 在这里进行剪枝,判断哪些孩子是要剪掉的
// 你可能需要根据 k 的值来判断,也可能需要结合args来判断
if(check(k, args)){
// 如果合法,进入下一位i-1,flag = 之前已经是前缀并且第i位选择的也是bound[i]
// 由于又选了一位,所以args会根据k做出相应的改变
res += dfs(i - 1, flag && k == upper, newArgs);
}
}
return res; // 返回所有情况
}
- 初始化参数设置
// idx是bound数组的有效长度
int res = dfs(idx_r-1, true, ?) - dfs(idx_l-1, true, ?);
进阶(记忆化搜索)
虽然剪枝可以有效提高搜索效率,但大部分时候还是太慢了,这个时候就需要记忆化搜索。
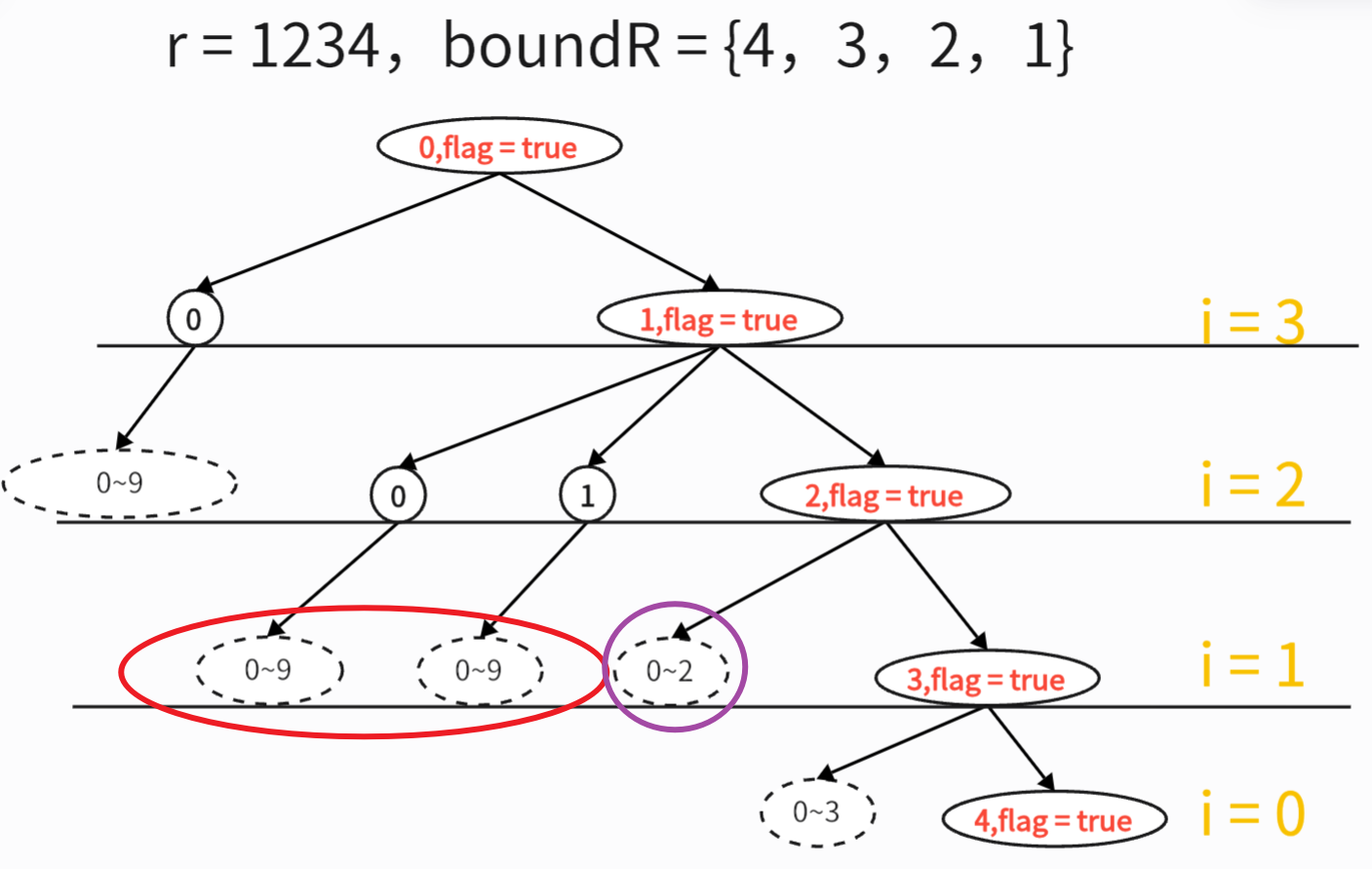
这里有一个技巧,就是只有flag = false的项才可以记忆化搜索。
可以发现图中被红圈圈住的20个节点,它们的父节点都是flag=false,所以它们才长得一样。
而被紫色圈住的3个节点,因为它们的父节点是flag=true,所以它们不是0~9。
只要父节点是flag=false,你就完全可以复用前面已经算过的值,它们都是一样的。这就是记忆化搜索。
int memo[20];// 初始化要全部设置为-1,不能设置成0,因为有些情况memo[i] 就是等于0
int dfs(int i, bool flag, T args){
if(i < 0)return 1;
// 父节点flag=false,并且之前算过这一层,可以直接返回
if(!flag && memo[i] != -1)return memo[i];
int upper = flag ? bound[i] : 9;
int res = 0;
for(int k=0;k<=upper;++k){
if(check(k, args)){
res += dfs(i-1, flag && k == upper, newArgs);
}
}
// 只记录父节点flag = false的,记录flag=true的没有意义,还会导致出错
if(!flag)memo[i] = res;
return res;
}
上述代码只是最简单的记忆化搜索,实际上memo往往是一个二维数组,只有当仅需i和flag就可以确定唯一状态时,memo只需要开一维。
其实只要会影响dfs最终返回值的参数,都需要纳入memo中,原本flag也是memo的一部分,但是flag只有两种状态,就省略了。
for(int k=0;k<=upper;++k){
// 在这里,如果flag=false,就可以保证upper=9,k就可以有0~9十种选择
// 如果args不需要,那你memo妥妥的一维就够了
// 但是如果有args,那么你大概率需要开二维,即便args不会影响check函数
if(check(k, args)){
res += dfs(i-1, flag && k == upper, newArgs);
}
}
完整模板
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int mod = 1e9 + 7;
ll bound[20], memo[20][?];
ll dfs(int i, bool flag, T args){
if(i < 0)return result(args);
if(!flag && isOk(args) && memo[i][args] != -1)return memo[i][args];
int upper = flag ? bound[i] : 9;
ll res = 0;
for(int k=0;k<=upper;++k){
if(check(k, args))res += dfs(i-1, flag && k == upper, newArgs), res %= mod;
}
if(!flag && isOk(args))memo[i][args] = res;
return res;
}
ll solve(ll upper){
int n=0;
while(upper > 0){
bound[n++] = upper % 10;
upper /= 10;
}
return dfs(n-1, true, args);
}
int main(){
int l, int r;
cin >> l >> r;
memset(memo, -1, sizeof(memo));
cout << (solve(r) - solve(l-1) + mod) % mod << endl;
return 0;
}
实例讲解
统计各位数字都不同的数字个数
给你一个整数 n ,统计并返回各位数字都不同的数字
x
x
x 的个数,其中
0
<
=
x
<
1
0
n
0 <= x < 10^n
0<=x<10n 。
比如
n
=
0
n = 0
n=0, 则
0
<
=
x
<
1
0
0
0<=x<10^0
0<=x<100,只有
0
0
0是合法数字,输出1
n
=
2
n = 2
n=2, 则
0
<
=
x
<
1
0
2
0<=x<10^2
0<=x<102,除了
11
,
22
,
.
.
.
,
99
11,22,...,99
11,22,...,99,其他数字都合法,输出91
数据范围:0 <= n <= 8
无需输入输出, 解题模板如下
class Solution {
public:
int countNumbersWithUniqueDigits(int n) {
}
};
答案
class Solution {
public:
int bound[9];
int memo[9][1024];
int dfs(int i, bool lead, int mask){
if(i < 0)return 1;
if(!lead && memo[i][mask] != -1)return memo[i][mask];
int res = 0;
for(int k=0;k<=9;++k){
if(mask & (1 << k))continue;
res += dfs(i-1, lead && k == 0, mask | (lead && k == 0 ? 0 : 1 << k));
}
if(!lead)memo[i][mask] = res;
return res;
}
int countNumbersWithUniqueDigits(int n) {
fill(bound, bound + 9, 9);
memset(memo, -1, sizeof(memo));
return dfs(n-1, true, 0);
}
};
解析
首先找出 [ l , r ] = [ 0 , 1 0 n − 1 ] [l, r] = [0, 10^n-1] [l,r]=[0,10n−1]。
由于需要确认搜索路径上是否出现重复数字,我们可以使用一个mask掩码来体现之前已经选择了哪些数字,比如选择了数字
3
3
3,那么mask |= 1 << 3,标记3已经使用,下次使用
(mask & (1 << k)) == 0来判断数字k还没有使用。注意前导零的
0
0
0不能加入mask。
最后设计memo[i][mask]来记忆化搜索即可。
由于上界总是类似
999...
999...
999...这样的数字,所以flag就没有意义了,有他没他都一样。
统计各位数字之和为偶数的整数个数
给你一个正整数 num ,请你统计并返回 小于或等于 num 且各位数字之和为 偶数 的正整数的数目。
正整数的 各位数字之和 是其所有位上的对应数字相加的结果。
比如数字:123,他的各位数字之和 = 1 + 2 + 3 = 6。
数据范围:1 <= num <= 1000
无需输入输出, 解题模板如下
class Solution {
public:
int countEven(int num) {
}
};
答案
class Solution {
public:
int bound[4];
int memo[4];
int dfs(int i, bool flag, int sum) {
if (i < 0) {
return sum % 2 == 0;
}
if(!flag && memo[i] != -1)return memo[i];
int upper = flag ? bound[i] : 9;
int res = 0;
for (int k = 0; k <= upper; ++k) {
res += dfs(i - 1, flag && k == upper, sum + k);
}
if(!flag)memo[i] = res;
return res;
}
int countEven(int num) {
int idx = 0;
while (num > 0) {
bound[idx++] = num % 10;
num /= 10;
}
fill(memo, memo+4, -1);
return dfs(idx - 1, true, 0) - 1;// l = 1 时只有0满足 dfs = 1,所以减一即可
}
};
解析
这道题目没有直接给出
[
l
,
r
]
[l, r]
[l,r] ,但是根据题意可以知道是
[
1
,
n
u
m
]
[1, num]
[1,num] 。
题目的限制条件:各位数字之和为 偶数 。
这道题目没有check函数,或者说是在叶子节点进行check的,你必须把整个数字拼完才可以知道和,所以这题没法剪枝,但是可以记忆化搜索。那memo为什么一维就够了?他不是有sum参数吗?
其实本题正常思路应该是需要
m
e
m
o
[
i
]
[
s
u
m
]
memo[i][sum]
memo[i][sum],但是由于条件太特殊了:奇偶性。
一个正整数非奇即偶,假如你第一次计算到m层时,sum = 10,假设还剩2位没算,也就是100种组合,比如:1 2 3 4 [0 ~ 2] {0 ~ 9} {0 ~ 9},那么后面的100种组合算出来的
s
u
m
∈
[
0
,
18
]
sum\in [0,18]
sum∈[0,18]并且一定有50个sum是奇数,50个sum是偶数。
那么无论你当前sum是奇数还是偶数,最后凑出的合法数字都是一样的。
- 你当前sum是奇数,就会有50个奇数和你相凑,最终得到50个合法数字。
- 你当前sum是偶数,就会有50个偶数和你相凑,最终得到50个合法数字。
所以当前sum并不影响dfs最终的返回值。
如果我们把条件改成 各位数字之和可以被3整除,就必须使用 m e m o [ i ] [ s u m ] memo[i][sum] memo[i][sum] 了。
如果使用
m
e
m
o
[
i
]
[
s
u
m
]
memo[i][sum]
memo[i][sum] ,你需要估算最大的sum,这个简单,把所有位全部置为9,数数最多可以有多少个9就好了。
比如num=1000,sum_max = 9 +9 +9 = 27,那你开
m
e
m
o
[
10
]
[
30
]
memo[10][30]
memo[10][30] 就ok了。
你可以简单测试一下,把条件改成sum%3==0,然后用一维记忆化搜索,以及不使用记忆化搜索,看看结果是否一致。
类似题目:P4999 烦人的数学作业
答案
数字 1 的个数
给定一个整数 n,计算所有小于等于 n 的 非负整数 中数字 1 出现的个数。
比如 n =12,那么0~9中有1个1,10和12有1个1,11有2个1,总共有5个1
数据范围:
0
<
=
n
<
=
1
0
9
0 <= n <= 10^9
0<=n<=109
无需输入输出, 解题模板如下
class Solution {
public:
int countDigitOne(int n) {
}
};
答案
class Solution {
int bound[10];
int memo[10][10];
int dfs(int i, bool flag, int cnt){
if(i < 0)return cnt;
if(!flag && memo[i][cnt] != -1)return memo[i][cnt];
int upper = flag ? bound[i] : 9;
int res = 0;
for(int k = 0; k <= upper; ++k){
res += dfs(i-1, flag && k == upper, cnt + (k == 1));
}
if(!flag)memo[i][cnt] = res;
return res;
}
public:
int countDigitOne(int n) {
int idx = 0;
while(n > 0){
bound[idx++] = n % 10;
n /= 10;
}
memset(memo, -1, sizeof(memo));
return dfs(idx-1, true, 0);
}
};
解析
这题的区间是
[
0
,
n
]
[0, n]
[0,n],为了计算1的个数,需要增加一个cnt参数来计算当前状态已经有 多少个1了。本题同样没有check函数,因为所有数字都合法,即使这个数字1个0都没有,那他的贡献就是0呗。
为什么开
m
e
m
o
[
10
]
[
10
]
memo[10][10]
memo[10][10] 就够了?结合题目数据范围
n
<
=
1
0
9
n <= 10^9
n<=109,而我们的cnt记录的是某个数字1的个数,撑死就是10个数位有9个都是1,所以cnt <= 9。
统计圆数
如果一个正整数的二进制表示中,0 的数目不小于 1 的数目,那么它就被称为「圆数」。
例如,9 的二进制表示为 1001,其中有 2 个 0 与 2 个 1。因此,9 是一个「圆数」。
请你计算,区间 [ l , r ] [l,r] [l,r] 中有多少个「圆数」。
输入格式: 只有一行,分别输入两个整数 :
l
l
l
r
r
r
输出格式: 输出一个整数表示答案个数
数据范围: 1 ≤ l , r ≤ 2 × 1 0 9 1 ≤ l, r ≤ 2\times10^9 1≤l,r≤2×109
示例输入1:
2 12
示例输出1:
6
答案
#include<bits/stdc++.h>
#define ll long long
using namespace std;
int bound[32], memo[32][64];
int dfs(int i, bool flag, bool lead, int blanced){
if(i < 0)return blanced >= 32;
if(!flag && !lead && memo[i][blanced] != -1)return memo[i][blanced];
int upper = flag ? bound[i] : 1;
int res = 0;
for(int k=0;k<=upper;++k){
res += dfs(i-1,flag && k == upper, lead && k == 0, blanced + (k == 0 ? (lead ? 0 : 1) : -1));
}
if(!flag && !lead)memo[i][blanced] = res;
return res;
}
int solve(int upper){
int n = 0;
while(upper > 0){
bound[n++] = upper % 2;
upper /= 2;
}
return dfs(n-1, true, true, 32);
}
int main(){
int l, r;
cin >> l >> r;
memset(memo, -1, sizeof(memo));
cout << solve(r) - solve(l-1) << endl;
return 0;
}
解析
本题 [ l , r ] [l, r] [l,r] 是一个二进制区间,需要修改的地方有两个:
- bound的获取: %10 ⇒ % 2, /= 10 ⇒ /=2
- upper的获取:flag ? bound[i] : 9 ⇒ flag ? bound[i] : 1
会影响dfs结果的参数多了2个
lead:这个是判断前面是否全是0,即前导零。
因为前导零不能贡献0的个数,所以要跳过它们。又因为他是个bool值,所以就没有写入memo中,和flag一样做个判断就行了。blanced:遇到非前导零就+1,遇到1就-1,最终看谁的影响更大。
初始时设置成32,这样就不会出现负数索引了。
类似题目:P4317 花神的数论题
答案
【提示】:本题你可能需要使用到快速幂算法,他可以高效计算
p
o
w
(
a
,
b
)
pow(a,b)
pow(a,b)
ll qpow(ll a, ll b){
ll res = 1;
while(b){
if(b & 1)res = res * a % mod;
a = a * a % mod;
b >>= 1;
}
return res;
}
被n整除的n位数
被
n
n
n 整除的
n
n
n 位数”是这样定义的:记这个
n
n
n 位数为
a
n
⋯
a
2
a
1
a_n ⋯ a _2a_1
an⋯a2a1 。首先
a
n
a_n
an
不为 0。从
a
n
a_n
an开始从左到右扫描每一位数字,前 1 位数(即
a
n
a_n
an)能被 1 整除,前 2 位数
a
n
−
1
a_{n−1}
an−1能被 2 整除,以此类推…… 即前
i
i
i 位数能被
i
i
i 整除(
i
=
1
,
⋯
,
n
i=1,⋯,n
i=1,⋯,n)。
例如 34285 这个 5 位数,其前 1 位数 3 能被 1 整除;前 2 位数 34 能被 2 整除;前 3 位数 342 能被 3 整除;前 4 位数 3428 能被 4 整除;前 5 位数 34285 能被 5 整除。所以 34285 是能被 5 整除的 5 位数。
本题就请你对任一给定的 n n n,求出给定区间 [ a , b ] [a,b] [a,b]内被 n n n 整除的 n n n 位数。
输入:只有一行,分别输入
n
n
n
a
a
a
b
b
b
输出:按照升序结果输出所有答案,每个答案独占一行,如果一个都没有则输出No Solution。
数据范围:
1
<
n
<
=
15
,
1
<
=
a
<
=
b
<
1
0
15
1 < n <=15, 1 <= a <= b < 10^{15}
1<n<=15,1<=a<=b<1015
示例输入1:
5 34200 34500
示例输出1:
34200
34205
34240
34245
34280
34285
示例输入2:
4 1040 1050
示例输出2:
No Solution
答案
#include<bits/stdc++.h>
#define vvi vector<vector<int>>
#define vi vector<int>
#define ll long long
#define pii pair<int, int>
using namespace std;
inline ll read() {
ll x = 0;
bool p = false;
char ch = getchar();
while(ch<'0'||ch>'9')p |= ch=='-',ch = getchar();
while(ch>='0'&&ch<='9')x = (x << 3) + (x << 1) + (ch ^ '0'), ch = getchar();
return p?-x:x;
}
int upperBound[16], lowerBound[16];
void dfs(ostringstream& out, int i, ll num, bool isLower, bool isUpper, int p){
if(i < 0){// 能够抵达叶子节点,说明这个num是合法的
out << num << "\n";
return;
}
int lower = isLower ? lowerBound[i] : 0;
int upper = isUpper ? upperBound[i] : 9;
num = (num << 3) + (num << 1);// num = num * 8 + num * 2;
for(int k = lower; k <= upper; ++k){
if((num + k) % p == 0){// 只有合法的num才可以继续dfs
dfs(out, i-1, num + k, isLower && k == lower, isUpper && k == upper, p + 1);
}
}
}
void solve(ostringstream& out){
ll n = read(), lower = read(), upper = read(), i = 0;
while(upper > 0){
upperBound[i++] = upper % 10;
upper /= 10;
}
if(i < n)return;// 没有达到n位,直接排除
// if(i > n)fill(upperBound, upperBound+n, 9);// 超过n位,把最低的n位全部设成最大值
i = 0;
while(lower > 0){
lowerBound[i++] = lower % 10;
lower /= 10;
}
if(i < n){// 没有超过n位,设置成最小的n位数,因为不能有前导零
memset(lowerBound, 0, sizeof(lowerBound));
lowerBound[n-1] = 1;
}
dfs(out, n-1, 0, true, true, 1);
}
int main(){
ostringstream out;
int T = 1;
// T = read();
while(T--){
solve(out);
}
if(out.str() == "")cout << "No Solution";
else cout << out.str();
return 0;
}
解析
本题不需要使用记忆化搜索,因为题目要求的是具体哪些数字,而不是有多少个。
既然是要输出所有数字的,那数字的数量肯定不会多到哪去,而且这次我们不采取前缀和的思想,即solve(r) - solve(l-1),这明显不合理。我们没必要也不可以去输出solve(l-1)的答案。既然我们的模板一直是使用了上界,那完全可以再添加一个下界。
int upperBound[16], lowerBound[16];
之前的for(int k=0;k<=upper;++k)就可以改成for(k=lower;k<=upper;++k)。
题目的要求十分明显,所以我们需要一边拼数字,一边判断这个数字书否可以被整除即可
dfs(ostringstream& out, int i, ll num, bool isLower, bool isUpper, int p)
out是缓冲输出流,可以有效提高输出效率(只要cout一次)num就是遍历路径拼接的数字,用来check判断剪枝isUpper相当于前面的flagisLower和isUpper作用相似p是这一层需要的mod,同时也表示树深
【注意】 :题目并没有说
a
a
a 和
b
b
b 都是
n
n
n 位数,只告诉你
a
<
=
b
a <= b
a<=b
所以你需要先判断
[
a
,
b
]
[a, b]
[a,b]内有没有
n
n
n位的数字,没有就直接pass,有的话再求出准确的上下界。
比如
n
=
4
,
a
=
1
,
b
=
1000000
n = 4, a = 1, b =1000000
n=4,a=1,b=1000000,那么真正的
[
l
,
r
]
=
[
1000
,
9999
]
[l, r] = [1000,9999]
[l,r]=[1000,9999]
只要多注意一些细节,这道题目就是简单题。
答案
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int mod = 1e9+7;
ll bound[20], memo[20][200];
ll dfs(int i, bool flag, int sum){
if(i < 0)return sum;
if(!flag && memo[i][sum] != -1)return memo[i][sum];
int upper = flag ? bound[i] : 9;
ll res = 0;
for(int k=0;k<=upper;++k){
// 只要你知道传sum+k,那么这题你就做完了
res += dfs(i-1, flag && upper == k, sum + k);
res %= mod;
}
if(!flag)memo[i][sum] = res;
return res;
}
ll solve(ll upper){
int n = 0;
while(upper > 0){
bound[n++] = upper % 10;
upper /= 10;
}
return dfs(n-1, true, 0);
}
int main(){
int t;
cin >> t;
memset(memo, -1, sizeof(memo));
while(t--){
ll l, r;
cin >> l >> r;
cout << (solve(r) - solve(l-1) + mod) % mod << endl;
}
return 0;
}
方法一(直接dp求解,推荐)
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int mod = 1e7+7;
ll bound[32], memo[64][64];
ll dfs(int i, bool flag, int sum){
// 注意题目是从1开始的,所以你不应该考虑0的情况,否则答案永远是0
if(i < 0)return max(1, sum);
if(!flag && memo[i][sum] != -1)return memo[i][sum];
int upper = flag ? bound[i] : 1;
ll res = 1;
for(int k=0;k<=upper;++k){
res *= dfs(i-1, flag && upper == k, sum + k);
res %= mod;
}
if(!flag)memo[i][sum] = res;
return res;
}
ll solve(ll upper){
int n = 0;
while(upper > 0){
bound[n++] = upper & 1;
upper >>= 1;
}
return dfs(n-1, true, 0);
}
int main(){
ll n;
cin >> n;
memset(memo, -1, sizeof(memo));
cout << solve(n) << endl;
return 0;
}
为什么可以这样写呢?看看这幅图你就懂了:
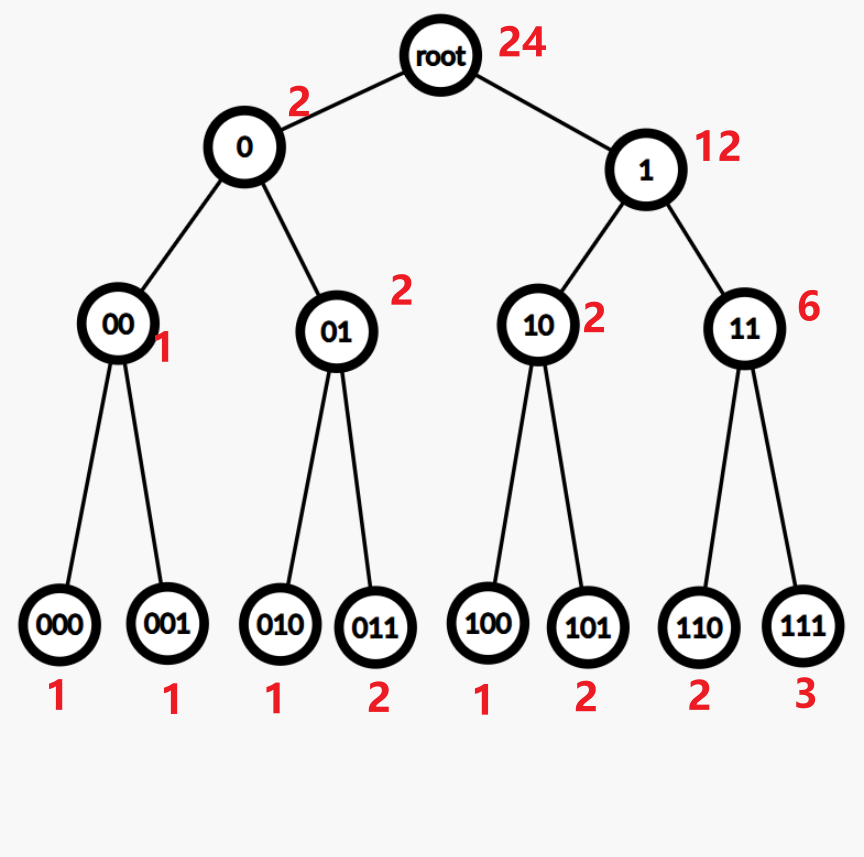
这是n=7的情况,000要特殊处理成1,因为题目是从1开始计算的。
方法二(先用dp计数,再求解)
#include<bits/stdc++.h>
#define ll long long
using namespace std;
const int mod = 1e7+7;
ll qpow(ll x, ll y){
ll res = 1;
while(y){
if(y & 1)res = res * x % mod;
x = x * x % mod;
y >>= 1;
}
return res;
}
ll bound[32], memo[64][64][64];
ll dfs(int i, bool flag, int sum, int target){
if(i < 0)return sum == target;
if(!flag && memo[i][sum][target] != -1)return memo[i][sum][target];
int upper = flag ? bound[i] : 1;
ll res = 0;
for(int k=0;k<=upper;++k){
// 这里可以剪枝,如果sum+k已经超过target,那可以跳过了。
// 当然你还可以再剪枝,如果后面即使全部选择1也达不到target,也可以pass
if(sum + k <= target){
res += dfs(i-1, flag && upper == k, sum + k, target);
// 注意这里res一定不可以取余,因为res是幂运算的指数部分
}
}
if(!flag)memo[i][sum][target] = res;
return res;
}
ll solve(ll upper){
int n = 0;
while(upper > 0){
bound[n++] = upper & 1;
upper >>= 1;
}
ll res = 1;
// 枚举所有可能的sum,最多就n个1,再统计cnt[sum]
for(ll sum = 1; sum <= n; ++sum){
ll cnt = dfs(n-1, true, 0, sum);
res *= qpow(sum, cnt);
res %= mod;
}
return res;
}
int main(){
ll n;
cin >> n;
memset(memo, -1, sizeof(memo));
cout << solve(n) << endl;
return 0;
}
总结
数位dp主要靠剪枝+记忆化搜索,写法比较固定,所以比较好记忆。
上述题目中,我们遇到了10进制和2进制的题目,如果你遇到了字符串类型的数位dp,那么大概率是使用字母,并且告诉你按照字典序升序来搜索。如果全是小写字母或者全是大写字母,那你就把字符串看作是一个26进制的数字就ok了,其他都一样的,只不过这类题目大概率还需要结合字符串匹配(KMP)算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









