






目录
二、代码解释(好像也没啥好解释的,反正都是套文法规则来写就是了)
text:这个窗口最简单,直接在getToken()函数里面把需要的文本保存起来就好了
folder:直接调用qt的QTreeView控件就好了,先看代码:
tree:找了很多资料也没找着画树的案例,干脆直接手动画一个,这里面涉及到了QGraphics的许多知识,我解释不清,就讲讲画树的思路吧。总之先看代码:
题目
实验3 TINY扩充语言的语法树生成
一、实验内容:
(一)为Tiny语言扩充的语法有
1.实现改写书写格式的新if语句;
2.扩充算术表达式的运算符号:++(前置自增1)、 --(前置自减1)运算符号(类似于C语言的++和--运算符号,但不需要完成后置的自增1和自减1)、求余%、乘方^;
3.扩充扩充比较运算符号:<(小于)、>(大于)、<=(小于等于)、>=(大于等于)、<>(不等于)等运算符号;
4增加正则表达式,其支持的运算符号有: 或(|) 、连接(&)、闭包(#)、括号( ) 、可选运算符号(?)和基本正则表达式。
5.for语句的语法规则(类似于C语言的for语言格式):
书写格式:for(循环变量赋初值;条件;循环变量自增或自减1) 语句序列
6.while语句的语法规则(类似于C语言的while语言格式):
书写格式:while(条件) 语句序列 endwhile
(二)对应的语法规则分别为:
1. 把TINY语言原有的if语句书写格式
if_stmt-->if exp then stmt-sequence end | | if exp then stmt-sequence else stmt-sequence end
改写为:
if_stmt-->if(exp) stmt-sequence else stmt-sequence | if(exp) stmt-sequence
2. ++(前置自增1)、 --(前置自减1)运算符号、求余%、乘方^等运算符号的文法规则请自行组织。
3.<(小于),>(大于)、<=(小于等于)、>=(大于等于)、<>(不等于)等运算符号的文法规则请自行组织。
4.为tiny语言增加一种新的表达式——正则表达式,其支持的运算符号有: 或(|) 、连接(&)、闭包(#)、括号( ) 、可选运算符号(?)和基本正则表达式,对应的文法规则请自行组织。
5.为tiny语言增加一种新的语句,ID==正则表达式 (同时增加正则表达式的赋值运算符号==)
6.为tiny语言增加一个符合上述for循环的书写格式的文法规则,
7.为tiny语言增加一个符合上述while循环的书写格式的文法规则,
8.为了实现以上的扩充或改写功能,还需要注意对原tiny语言的文法规则做一些相应的改造处理。
Tiny语言原来的文法规则,可参考:云盘中参考书P97及P136的文法规则。
二、实验要求:
(1)要提供一个源程序编辑的界面,以让用户输入源程序(可输入,可保存、可打开源程序)
(2)可由用户选择是否生成语法树,并可查看所生成的语法树。
(3)实验3的实现只能选用的程序设计语言为:C++
(4)要求应用程序的操作界面应为Windows界面。
(5)应该书写完善的软件文档
三、测试数据(语法正确和错误的源程序均要有测试文件)
测试文件1:(该程序中的if语句还是采用原Tiny语言中if语句的书写格式进行书写,作为实验3的测试源程序,你需要根据实验3实际要求的改写方式进行改写)
{ Sample program
in TINY language -
computes factorial
}
read x; { input an integer }
if 0<x then { don't compute if x <= 0 }
for( fact := 1; x>0;--x)
fact := fact * x
write fact { output factorial of x }
end
测试文件2:(该程序中的if语句还是采用原Tiny语言中if语句的书写格式进行书写,作为实验3的测试源程序,你需要根据实验3实际要求的改写方式进行改写)
{ Sample program
in TINY language -
computes factorial
}
read x; { input an integer }
if 0<x then { don't compute if x <= 0 }
fact := 1;
while( x>0 )
fact := fact * x;
--x
endwhile
write fact { output factorial of x }
end
测试文件3:(该程序中的if语句还是采用原Tiny语言中if语句的书写格式进行书写,作为实验3的测试源程序,你需要根据实验3实际要求的改写方式进行改写)
{ Sample program
in TINY language -
computes factorial
}
read x; { input an integer }
if x>0 then { don't compute if x <= 0 }
fact := 1;
repeat
fact := fact * x;
--x
until x = 0;
write fact { output factorial of x }
end部分代码解释
(首先我还是希望你先把yl给的tiny编译器代码搞懂先)
代码是直接在yl给的代码上来修改的,所以大部分代码逻辑我这里就不解释了;
提醒一下,我把分文件的模式改成一个文件了,主要是方便我写成一个类。
一、改动部分(这是在我的作业文档上摘下来的)
本次实验增加了不少新的tiny文法,因此在原有的tiny语言编译器的基础上,要对一些枚举作增删;
首先是TokenType,由于if语句改成风格,不在具备THEN和END,因此要删去这两项。增加了for、while语句,因此要增加FOR、WHILE、ENDWHILE ,显然StmtKind也要增加ForK、WhileK。在操作符上又增加了:大于、不等于、取余、乘方、自增、自减、大于等于、小于等于、正则表达式赋值号、或、连接、闭包、可选,因此增加
* MOD: %
* POW: ^
* PP: ++自增
* MM: --自减
* RE: ==正则表达式
* GT: >大于
* LE: <=小于等于
* GE: >=大于等于
* NE: <>不等于
* ROR/RAND/RC/RS:或(|),连接(&),闭包(#),可选(?)
其次是StateType,要增加五个状态:
* INASSIGNOREQ ==, =
* INLE <=, <, <>
* INGE >, >=
* INPE +, ++
* INME --
最后是reservedWords,由于增加了for、while、更改了if,要删去{"then",THEN},{"end",END}
增加 {"for",FOR}, {"while",WHILE}, {"endwhile",ENDWHILE}
考虑到增加了for语句,因此tiny树的结构体也要改变,主要体现在孩子数从3增加到4,因为for语句最多可以有4个孩子。
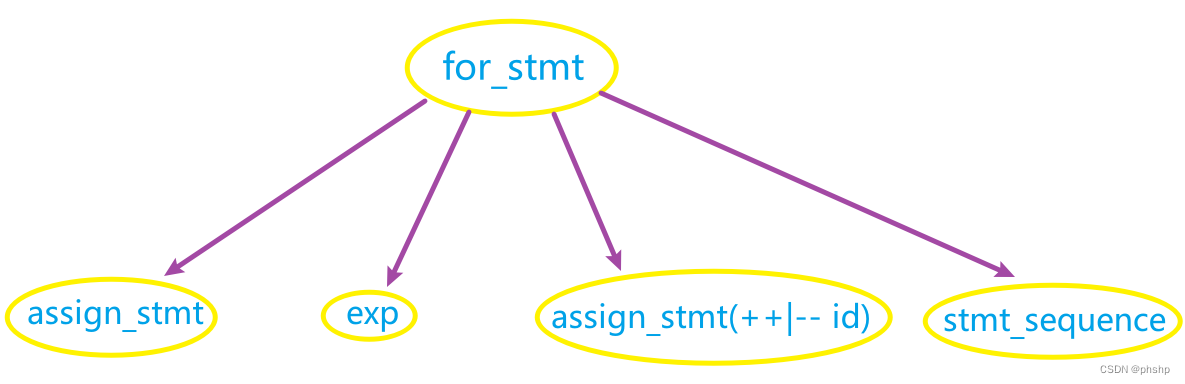
在做好上面的改变之后,就可以写出新的tiny语言的文法规则了,具体如下:
stmt_sequence -> statement { ; statement }
statement -> if_stmt | repeat_stmt | while_stmt | assign_stmt | read_stmt | write_stmt | for_stmt
if_stmt -> if (exp) stmt_sequence [ else stmt_sequence]
repeat_stmt -> repeat stmt_sequence until exp
while_stmt -> while (exp) stmt_sequence endwhile
assign_stmt -> id ( := simple_exp | == regExp1 ) | (++ | --) id
read_stmt -> read id
write_stmt -> write simple_exp
for_stmt -> for (assign_stmt ; exp ; assign_stmt) stmt_sequence
exp -> simple_exp [ ( < | = | > | <= | >= | <> ) simple_exp ]
simple_exp -> term { ( + | - ) term }
term -> power { ( * | / | % ) power }
power -> factor{ ^ factor }
factor -> number| id | ( simple_exp )
regExp1 -> regExp2{ \| regExp2 } 这里有个转义字符,说明 ‘|’是属于正则表达式的
regExp2 -> regExp3{& regExp3}
regExp3 -> regExp4[#|?]
regExp4 -> ID | (regExp1)
二、代码解释(好像也没啥好解释的,反正都是套文法规则来写就是了)
这里我只解释最最折腾我的函数:Stmt_squence(),当然还有被他牵扯到的其他函数
为什么呢,往下看就知道了。
先看下源码
TreeNode* SyntaxTree::stmt_sequence(void)
{
TokenType tk = token;
TreeNode* t = statement();
TreeNode* p = t;
//增加了缩进(split)和ENDWHILE作为stmt_sequence的分割符
while((token != ENDFILE) && (token != ELSE) && (token != UNTIL) && (token != ENDWHILE)){
int f=-1;
if(!QSet{WHILE,IF,FOR}.contains(tk)){
if(split>0){
if(lineno<=textLines)syntaxError("you lose a \";\"",lineno-1);
break;
}
f=lineno;
match(SEMI);
}
if(split>0){
if(f>=textLines)syntaxError("unexpected token:\";\",it should be deleted",f);
break;
}
TreeNode* q;
tk=token;
q = statement();
if (q != NULL) {
if (t == NULL) t = p = q;
else{
p->sibling = q;
p = q;
}
}
}
if(split>0)split--;
return t;
}这里面出现了几个变量:tk、f、还有最核心的split,先简单讲一下它们的作用
- tk:记录一条语句的第一个token
- f:记录未匹配分号前的行号
- split:记录需要结束几条if/for语句(重点)
之所以说这个函数不好写,就是因为文法中的if语句和for语句没有结束符,以及yl给的测试用例中,while语句的结束符endwhile后面没有分号(不知道yl是故意的还是不小心的,所以这个规则不符合文法规则,因为每条非结束语句后面都要跟一个分号,不过个人感觉有endwhile了再加个分号就有点不礼貌了)
所以就诞生了 split 变量,他的功能就是根据缩进来判断if语句和for语句是否结束。
但是什么时候知道split要增加呢,答案是在getNextChar()函数里面,先看源码:
int SyntaxTree::getNextChar()
{
if(linepos>=bufsize){
if(lineno>=textLines){
EOF_flag = TRUE;
return EOF;
}
// QStringList TextRows = 源程序.split('\n');
buff = TextRows[lineno++].append("\n");
int i=0;
for(auto c:qAsConst(buff)){
if(c=='\t')i+=4;
else if(c==' ')i++;
else break;
}
if(i<buff.size()&&buff[i]=='{')inComment=TRUE;
if(!inComment){
// QStack<int> retract;
while(!retract.empty()&&i<=retract.top()&&!buff.contains("else")){
retract.pop();
split++;
}
if(buff.contains("if")||buff.contains("for")){
retract.push(i);
}
}
if(buff.isEmpty()){
EOF_flag = TRUE;
return EOF;
}
bufsize=buff.size();
linepos = 0;
}
return buff[linepos++].unicode();
}
这里又出现了几个变量:i、inComment、retract。
- i:记录新的一行的缩进值,空格计为1,制表符计为4
- inComment:判断当前getToken()函数是不是在扫描注释
- retract:缩进值栈
i和inComment就不解释了,不过inComment在getToken()函数中也有赋值的地方,具体看我在GitHub上发布的源码。
重点讲一下retract,首先只有在非注释扫描时我们才对它进行操作。
既然是针对if和for的,那么我就让它每次遇到if/for时,就把这一行的缩进值存到栈里,不过在判断这一条件时有些草率了,只是简单的使用contains函数作判断条件,当然应该没人会故意在if/for语句之前写一些其他乱七八糟的东西吧(应该没有才对)。那么有了这些缩进值的时候,也就是栈非空的时候,对于接下来的每一行,我们都要检查一下这一行的缩进值有没有小于或者等于栈顶元素,如果小于或者等于栈顶元素,说明这一行已经不属于离他最近的if/for语句的语句了,那么我们的split就要自增一次了,但是为什么我不直接把split设置成bool值呢?其实我一开始也是直接设置成bool的,但是我后来发现,如果有一条语句,它连续脱离了多条if/for语句呢,就像这样:
if(x>0) // ①
if(y>0) // ②
if(z>0) // ③
x:=0;
m:=0 // 一次性脱离了三条if语句!!!那么这个m产生的价值就有三个结束标志而不是一个了,因此split要安排成int而不是bool。但是注意一个细节,就是这条语句:
while(!retract.empty()&&i<=retract.top()&&!buff.contains("else")){里面还有一个不包含‘else’的条件,主要是因为else语句确实可以在缩进值与if相等时也属于if语句的范围,于是方便起见,我直接忽略包含‘else’行的缩进值了,但是就会出现一个奇怪的现象,举个例子:
if(x>0)
x:=0
else
y:=0;// 在if范围
z:=0 // 不在if范围明明z:=0语句在else范围内,却不属于if范围,所以这里应该要一个改进,就是把这个if的缩进值用它的else的缩进值来更新一下,但是这样做貌似非常麻烦,至少我已近懒得想了。
ok,我们再次回到Stmt_squence()函数
TreeNode* SyntaxTree::stmt_sequence(void)
{
TokenType tk = token;
TreeNode* t = statement();
TreeNode* p = t;
//增加了缩进(split)和ENDWHILE作为stmt_sequence的分割符
while((token != ENDFILE) && (token != ELSE) && (token != UNTIL) && (token != ENDWHILE)){
int f=-1;
if(!QSet{WHILE,IF,FOR}.contains(tk)){
if(split>0){
if(lineno<=textLines)syntaxError("you lose a \";\"",lineno-1);
break;
}
f=lineno;
match(SEMI);
}
if(split>0){
if(f>=textLines)syntaxError("unexpected token:\";\",it should be deleted",f);
break;
}
TreeNode* q;
tk=token;
q = statement();
if (q != NULL) {
if (t == NULL) t = p = q;
else{
p->sibling = q;
p = q;
}
}
}
if(split>0)split--;
return t;
}讲完了split,再来讲讲tk,可以发现,tk的作用是决定要不要匹配分号(match(SEMI);),
if(!QSet{WHILE,IF,FOR}.contains(tk)){如果这条语句是while语句,那么不匹配,很好理解,因为while语句是以endwhile结尾的,之前讲过endwhile后面不跟分号,或者把endwhile看作一个while语句的专属分号。重点是为什么if和for也要跳过分号匹配?原因还是在缩进。
if/for语句是否结束取决于下一条语句的缩进值,是的,也就是说要扫描到最后一条语句的后一条语句,才知道刚刚已经扫过了最后一条语句。那么这个时候,本不应该扫描的分号却已经被扫描了,那么我们就不应该再扫描一遍,这里依旧拿个例子来讲:
write x;
if(x>0)
x:=0;
y:=0;
z:=0; // 这个分号匹配之后,split才会自增
x:=1
// 上面的写法仿佛在说z:=0;中的‘;'属于if语句的,但其实不然,我们看看下面这个
write x;
if(x>0)
x:=0;
y:=0;
z:=0
;
x:=1
// 这样写可能还不明显,再简化一下
write x;
if_stmt;
x:=1
// 现在应该够清楚了所以我们可以理解为if语句中的语句块预消耗了if_stmt的分号,所以读到if语句时才应该跳过最后的分号匹配,for语句同理。
最后f参数就是一个简单的行号判断,逻辑比较简单,我就不解释了。
UI设计
首先看看我的界面吧:(温馨提示:如果下载了安装包,打开之后界面可能会有点乱,因为主窗口大小被我固定住了,根据每台电脑的屏幕参数不同,界面就有可能发生混乱,但功能不受影响)
首先声明一下,这个界面是仿照哔哩哔哩某up主的视频来做的:
设置里面有一个github链接,但是不知道为什么,github莫名其妙把我的账号的停用了,真是无语,所以链接可能不生效了,因此我又把链接转到gitee上面了,下面的gif是没修改之前的设置
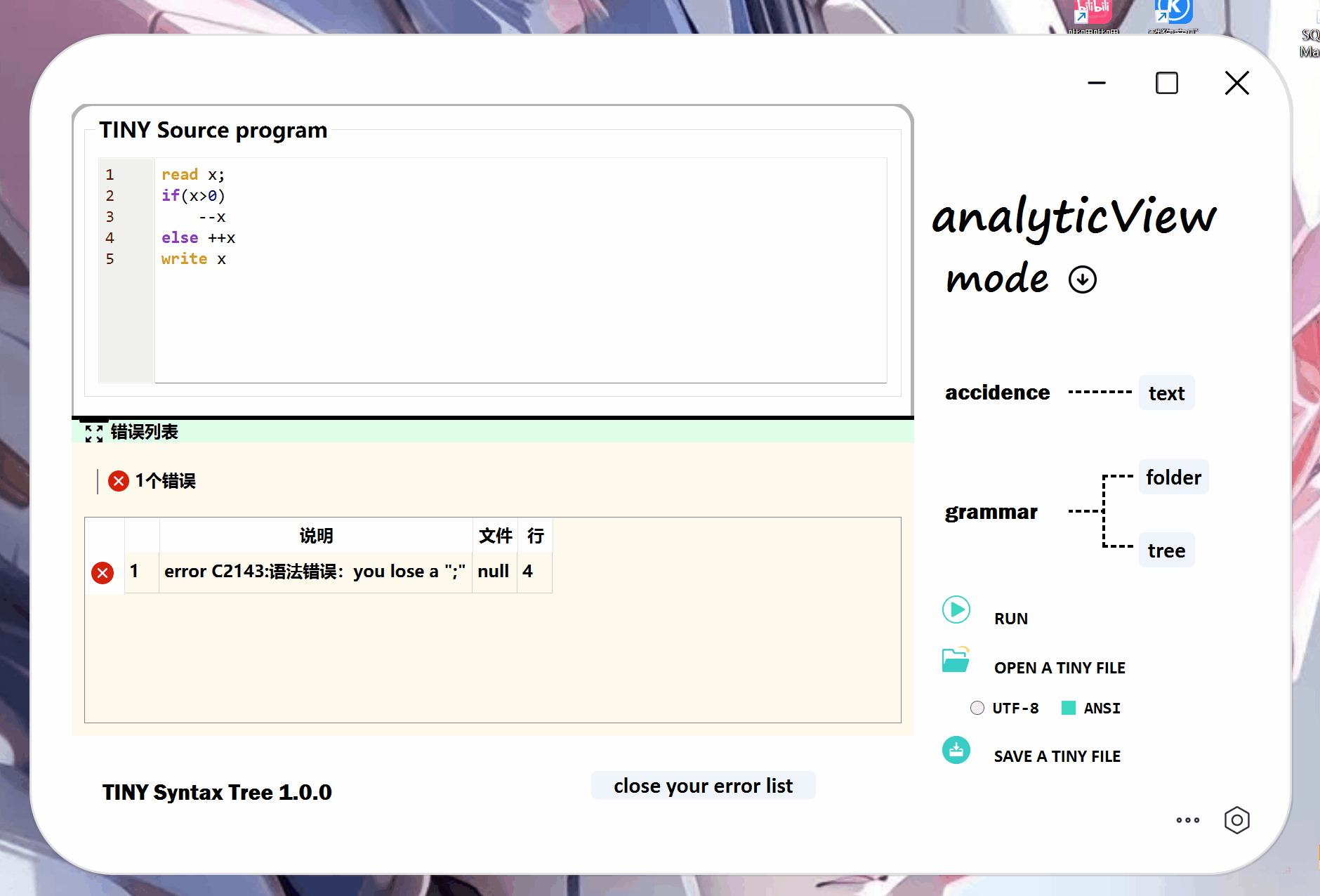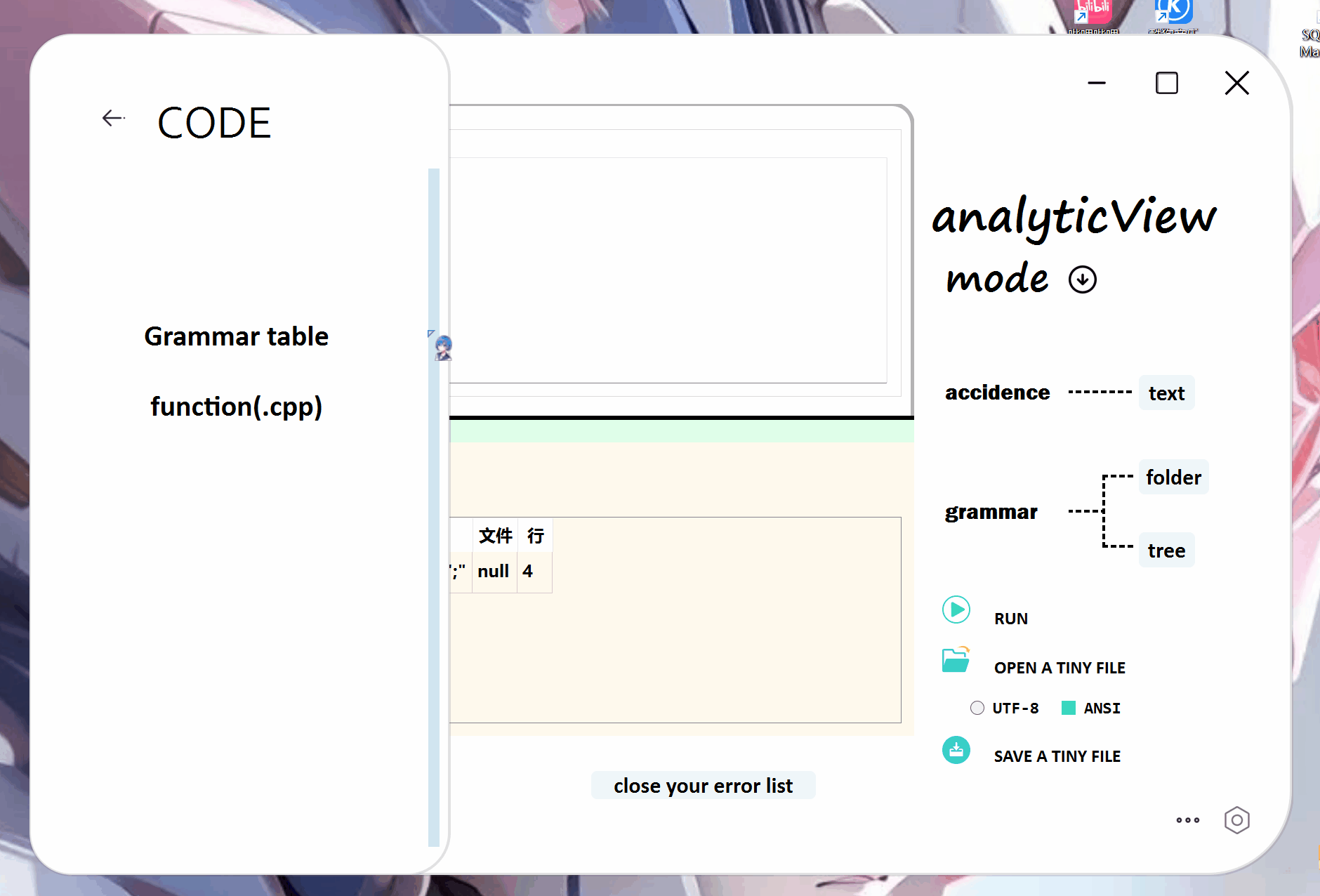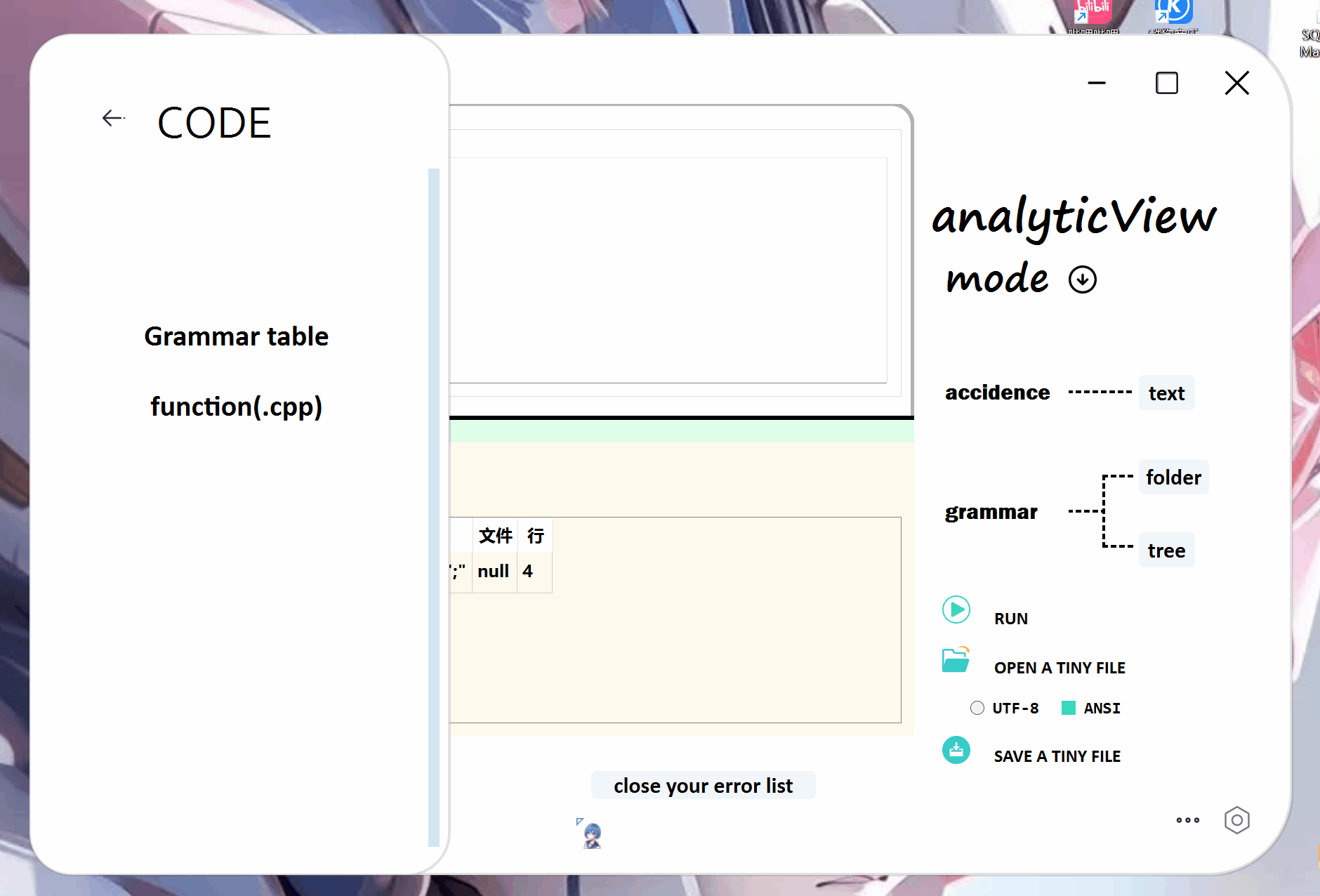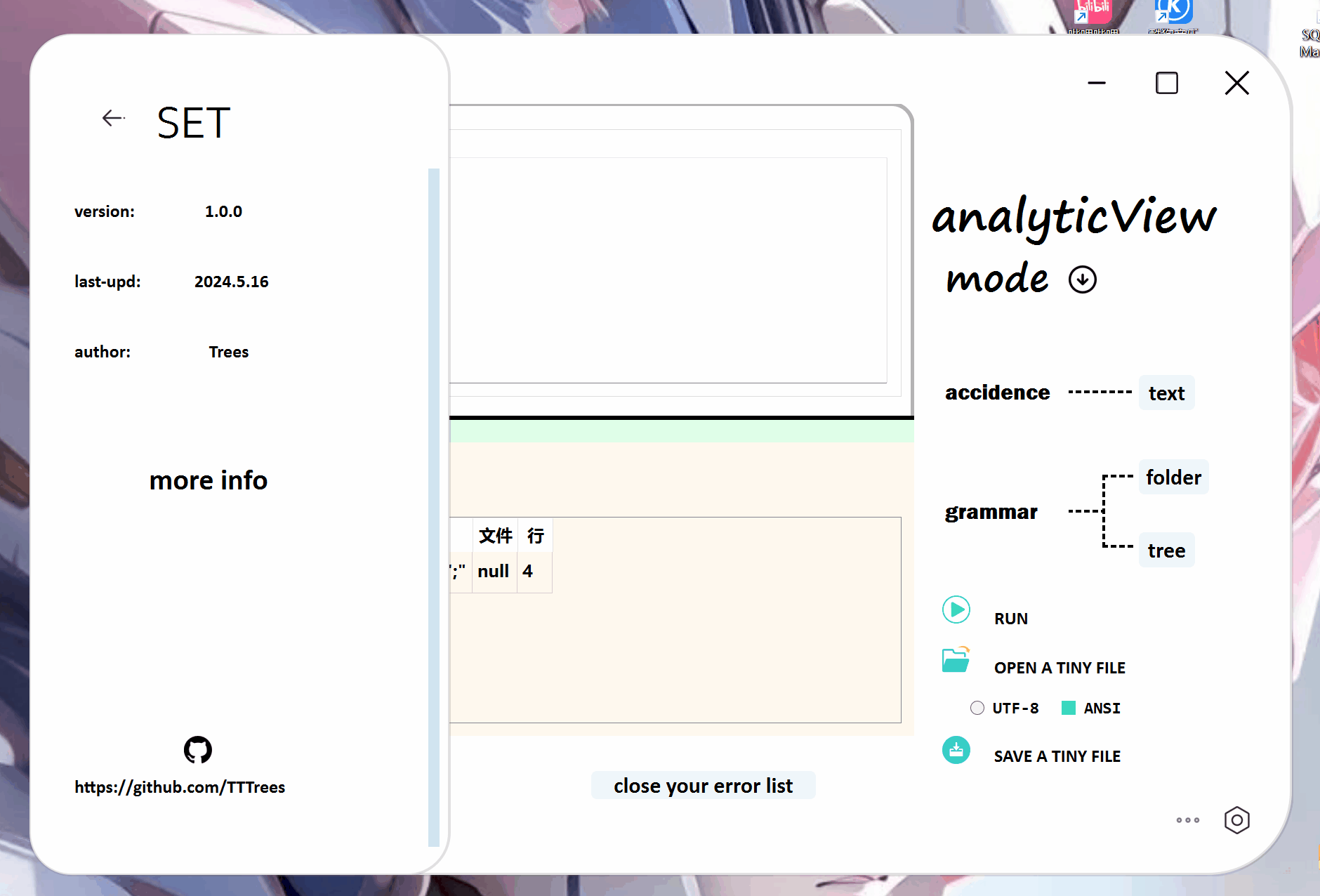
我这里只讲三个分析窗口的制作(第一张gif)
-
text:这个窗口最简单,直接在getToken()函数里面把需要的文本保存起来就好了
switch (currentToken) { case NUM://数字 Text.append(tokenString).append("\t\t数字\n\n"); break; case ASSIGN://赋值运算符 case PP: case MM: Text.append(tokenString).append("\t\t赋值运算符\n\n"); break; case EQ://比较运算符 case LT: case RE: case GT: case LE: case GE: case NE: Text.append(tokenString).append("\t\t比较运算符\n\n"); break; case PLUS://运算运算符 case MINUS: case TIMES: case OVER: case MOD: case POW: Text.append(tokenString).append("\t\t运算运算符\n\n"); break; case LPAREN:// 分隔符 case RPAREN: case SEMI: Text.append(tokenString).append("\t\t分隔符\n\n"); break; case ROR://正则表达式运算符 case RAND: case RC: case RS: Text.append(tokenString).append("\t\t正则表达式运算符\n\n"); break; default: break; }这段代码是追加在getToken末尾的,注释、标识符和保留字的判断也在getToken里面,这里没展示出来。
-
folder:直接调用qt的QTreeView控件就好了,先看代码:
QStandardItemModel *MainWindow::createTreeViewModel(TreeNode *syntaxTree) { // 创建根节点 QStandardItemModel *model = new QStandardItemModel(); QStandardItem *rootItem = model->invisibleRootItem(); QStandardItem* root = new QStandardItem("START"); rootItem->appendRow(root); model->setHorizontalHeaderLabels({""}); // 递归地填充树 populateTree(root, syntaxTree); return model; } void MainWindow::populateTree(QStandardItem *parentItem, TreeNode *node) { while(node!=NULL){ QString content=getContent(node); // 添加当前节点到树中 QStandardItem *item = new QStandardItem(content); item->setEditable(false); parentItem->appendRow(item); // 处理孩子节点 for (int i = 0; i < 4; ++i) { if(node->child[i]){ populateTree(item, node->child[i]); } } node=node->sibling; } }可以先了解一下QTreeView的用法,然后就是一个简单的递归函数就可以遍历完整棵树了,getContent()函数是用来解析当前节点的字串值的。
这里把返回值写成QStandardItemModel *也是根据QTreeView控件的设置设计的,因为它只要有QStandardItemModel * model ,就可以直接产生一棵树了,因此我选择把生成好的model保留下来,每次打开窗口时只要把model丢给QTreeView就好了,不用再生成一遍。 -
tree:找了很多资料也没找着画树的案例,干脆直接手动画一个,这里面涉及到了QGraphics的许多知识,我解释不清,就讲讲画树的思路吧。总之先看代码:
void MainWindow::populate(QStandardItemModel *model)
{
// QList<QPair<QPointF,QString>>allNodes;
allNodes.clear();
index=0;
m_left=0;
// QHash<int,QList<int>>m_hash;
m_hash.clear();
QStandardItem* root = model->item(0);
dfs(root,0);
}
int MainWindow::dfs(QStandardItem *item,qreal dep)
{
qreal l=m_left+1;
QList<int>ll;
for(int i=0;i<item->rowCount();++i){
if(item->child(i)->hasChildren())ll.append(dfs(item->child(i),dep+1));
else{
allNodes.append({{++m_left*100,150+dep*120},item->child(i)->text()});
ll.append(index++);
}
}
l=(l+m_left)*50;
allNodes.append({{l,30+dep*120},item->text()});
m_hash[index]=ll;
return index++;
}逻辑部分的代码并不多,先来解释一下一些参数:
- allNodes:一个存储节点字串和位置的列表
- index:节点编号
- m_left:节点距离左侧的单位数
- m_hash:父节点编号为key,直接子节点编号集合为value
- l:记录子树的第一个叶子节点距离左侧的单位数+1(组合方式:① l=m_left+1,++m_left
② l=m_left-1,m_left++) - dep:树深
所以到底怎么正确的获取每个节点的位置信息呢?答案是采用后序遍历树的方法。
首先我使用的树不是我们自己创建的语法树,而是folder里面的QTreeView,因为它的结构中没有sibling,只有child,而且之前每个节点的字串也都加载好了,直接拿它来遍历最好不过了。
采用后序遍历应该很好理解,毕竟想要确定一个节点的位置,当然要先知道它所有孩子的位置,然后根据孩子位置的中间值来确定自己的位置就好了,我这里写的逻辑是:子树根的横坐标位置=这棵子树所有叶子节点横坐标的平均值。纵坐标就简单了,直接每递归深入一次,dep加一就好了。
那么为什么要记录节点编号?m_hash又是干什么的?这和我画树的函数有关,我们一起来看看:
QRect MyGraphicsView::sketchTree(QList<QPair<QPointF, QString> > allNodes, QHash<int,QList<int>>m_hash)
{
// ---------------------------------------------------------- //
delete scene_list[0];scene_list.clear();
QGraphicsScene* myGraphicsScene= new QGraphicsScene();
myGraphicsScene->setBackgroundBrush(QBrush(QColor(0,0,0,0)));
scene_list.append(myGraphicsScene);
myGraphicsScene->setBackgroundBrush(Qt::transparent);
this->setScene(myGraphicsScene);
// ---------------------------------------------------------- //
foreach(int key,m_hash.keys()){
MyGraphicsVexItem* start = addVex(allNodes[key].first,allNodes[key].second,myGraphicsScene);
for(int i:qAsConst(m_hash[key])){
MyGraphicsVexItem* end = addVex(allNodes[i].first,allNodes[i].second,myGraphicsScene);
addLine(start,end,myGraphicsScene);
}
}
return myGraphicsScene->sceneRect().toRect();
}这里没有把画布场景(myGraphicsScene)设置成类成员是因为我不知道怎么重置那个场景大小,找了一些办法也没成功,导致如果先生成了一棵大树,场景就被扩大了,再画小树的时候那个场景就很难看,所以干脆每次都new一个,不过记得要delete。
重点看分界线下面那个循环代码,这里又两个函数:
addVex(节点坐标,节点字串,场景)、addLine(开始节点,结束节点,场景);
这两个函数怎么实现的我就不讲了,不是重点;有了这两个函数之后,答案就很明朗了,前面的allNodes和m_hash就派上用场了,简单看一下addVex和addLine的参数,应该很容易看懂了吧。
所以只要把allNodes和m_hash都正确生成好,几乎就大功告成了。
最后再讲一个细节,也是我找了许多资料都没能解决的问题,那就是把树给保存成图片时,图片展示不全的问题。
QPushButton* btn_tree = createPushButton("tree",this,QRectF(790,355,40,25),main_btn_style);
connect(btn_tree,&QPushButton::clicked,this,[=](){
QRect r = cGvTree->sketchTree(allNodes,m_hash);
QSize s = QSize(r.width()+300,r.height()+300);
m_cTree->resize(s);
pix = cGvTree->grab({{r.x()-100,r.y()-100},s});
m_cTree->setGeometry(650,100,600,500);
m_cTree->setVisible(true);
m_cTree->raise();
});这个是tree按钮的槽函数,可以看到,我直接在调用grab()函数之前,把我的m_cTree窗口给扩大到比画布大一点的大小,这样再来调用grab()函数就不用担心画面缺失了,是不是很简单?
ok,以上就是本次实验的全部解释内容,想看源码的点击下方链接哦:















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









