







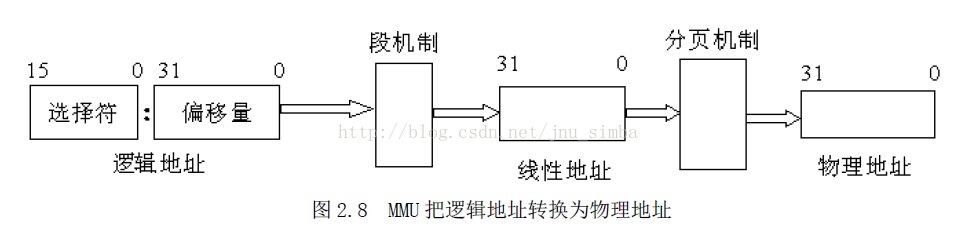
80386的分段机制、分页机制和物理地址的形成
注:本分类下文章大多整理自《深入分析linux内核源代码》一书,另有参考其他一些资料如《linux内核完全剖析》、《linux c 编程一站式学习》等,只是为了更好地理清系统编程和网络编程中的一些概念性问题,并没有深入地阅读分析源码,我也是草草翻过这本书,请有兴趣的朋友自己参考相关资料。此书出版较早,分析的版本为2.4.16,故出现的一些概念可能跟最新版本内核不同。
此书已经开源,阅读地址 http://www.kerneltravel.net
MOVE REG,ADDR ;
它把地址为ADDR(假设为10000)的内存单元的内容复制到REG 中
在8086 的实模式下,把某一段寄存器(段基址)左移4 位,然后与地址ADDR 相加后被直接送到内
存总线上,这个相加后的地址(20位)就是内存单元的物理地址,而程序中的这个地址ADDR就叫逻辑地址
(或叫虚地址)。
在80386 的段机制中,逻辑地址由两部分组成,即
段部分(选择符)
及偏移部分。
段是形成逻辑地址到线性地址转换的基础。如果我们把段看成一个对象的话,那么对它
的描述如下。
(1)段的基地址(Base Address):在线性地址空间中段的起始地址。
(2)段的界限(Limit):表示在逻辑地址中,段内可以使用的最大偏移量。
(3)段的属性(Attribute): 表示段的特性。例如,该段是否可被读出或写入,或者
该段是否作为一个程序来执行,以及段的特权级等。
1、逻辑地址、线性地址和物理地址
所谓
描述符(Descriptor)
,就是描述段的属性的一个8 字节存储单元。
2、用户段描述符(Descriptor)
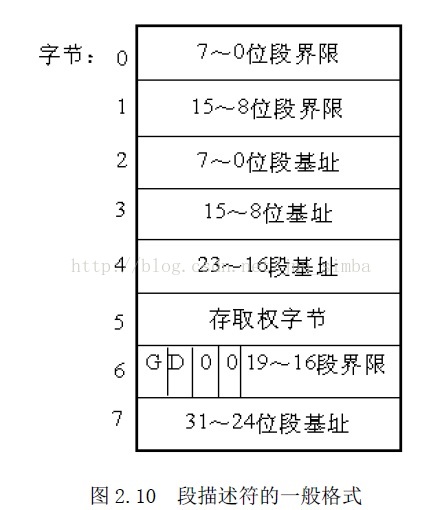

一个段描述符指出了段的32 位基地址和20 位段界限(即段大小)。
第6 个字节的G 位是粒度位,当G=0 时,段长表示段格式的字节长度,即一个段最长可
达1M 字节。当G=1 时,段长表示段的以4K 字节为一页的页的数目,即一个段最长可达
1M×4K=4G 字节。D 位表示缺省操作数的大小,如果D=0,操作数为16 位,如果D=1,操作数
为32 位。
第7 位P 位(Present) 是存在位,表示段描述符描述的这个段是否在内存中,如果在
内存中。P=1;如果不在内存中,P=0。
DPL(Descriptor Privilege Level)
,就是描述符特权级,它占两位,其值为0~3,
用来确定这个段的特权级即保护等级。0为内核级别,3为用户级别。
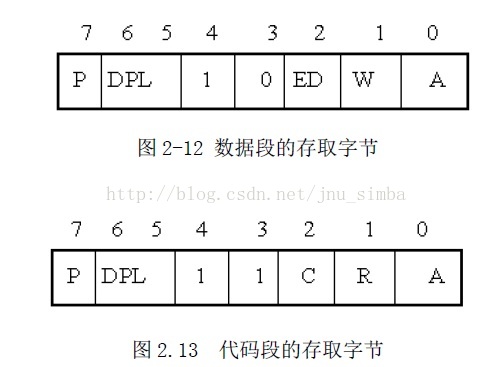
S 位(System)表示这个段是系统段还是用户段。如果S=0,则为系统段,如果S=1,则
为用户程序的代码段、数据段或堆栈段。
类型占3 位,第3 位为E 位,表示段是否可执行。当E=0 时,为数据段描述符,这时的
第2 位ED 表示地址增长方向。
第1 位(W)是可写位
。
当段为代码段时,第3 位E=1,这时第2 位为一致位(C)。当C=1 时,如果当前特权级
低于描述符特权级,并且当前特权级保持不变,那么代码段只能执行。所谓当前特权级
CPL
(Current Privilege Level)
,就是当前正在执行的任务的特权级。第1 位为可读位R
。
存取权字节的第0 位A 位是访问位,用于请求分段不分页的系统中,每当该段被访问时,
将A 置1。对于分页系统,则A 被忽略未用。
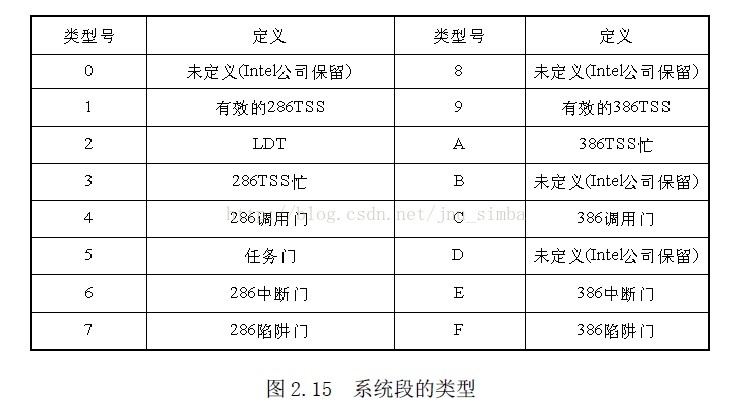
3、系统段描述符

系统段描述符的第5 个字节的第4 位为0,说明它是系统段描述符,类型占
4 位,没有A 位。第6 个字节的第6 位为0,说明系统段的长度是字节粒度,所以,一个系统
段的最大长度为1M 字节。
系统段的类型为16 种,如图2.15 所示。
在这16 种类型中,保留类型和有关286 的类型不予考虑。
门也是一种描述符,有调用门、任务门、中断门和陷阱门4 种门描述符
。
4、选择符、描述符表和描述符表寄存器
描述符表(即段表)定义了386 系统的所有段的情况。所有的描述符表本身都占据一个
字节为8 的倍数的存储器空间,空间大小在8 个字节(至少含一个描述符)到64K 字节(至
多含8K=8192)个描述符之间。
1.全局描述符表(GDT)
全局描述符表GDT(Global Descriptor Table),除了任务门,中断门和陷阱门描述符
外,包含着系统中所有任务都共用的那些段的描述符。它的第一个8 字节位置没有使用。
2.中断描述符表(IDT)
中断描述符表IDT(Interrupt Descriptor Table),包含256 个门描述符。IDT 中只
能包含任务门、中断门和陷阱门描述符,虽然IDT 表最长也可以为64K 字节,但只能存取2K
字节以内的描述符,即256 个描述符,这个数字是为了和8086 保持兼容。
3.局部描述符表(LDT)
局部描述符表LDT(Local Descriptor Table),包含了与一个给定任务有关的描述符,
每个任务各自有一个的LDT。有了LDT,就可以使给定任务的代码、数据与别的任务相隔离。
每一个任务的局部描述符表LDT 本身也用一个描述符来表示,称为LDT 描述符,它包含
了有关局部描述符表的信息,被放在全局描述符表GDT 中,使用LDTR进行索引。
在实模式下,段寄存器存储的是真实的段基址,在保护模式下,16 位的段寄存器无法放
下32 位的段基址,因此,它们被称为选择符,即段寄存器的作用是用来选择描述符。选择符
的结构如图2.16 所示。

可以看出,选择符有3 个域:第15~3 位这13 位是索引域,表示的数据为0~8129,用于
指向全局描述符表中相应的描述符。第2 位为选择域,如果TI=1,就从局部描述符表中选择
相应的描述符,如果TI=0,就从全局描述符表中选择描述符。第1、0 位是特权级,表示选
择符的特权级,被称为请求者特权级
RPL(Requestor Privilege Level
)。只有请求者特权
级RPL 高于(数字低于)或等于相应的描述符特权级DPL,描述符才能被存取,这就可以实
现一定程度的保护。
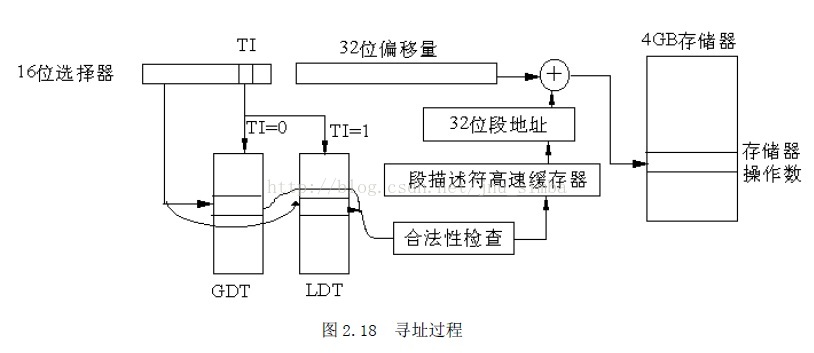
下面讲一下在没有分页操作时,寻址一个存储器操作数的步骤。
(1)在段选择符中装入16 位数,同时给出32 位地址偏移量(比如在ESI、EDI 中等)。
(2)先根据相应描述符表寄存器中的段地址(
确定描述符表的地址
)和
段界限
(确定描述符表的大小)
,根据段选择符的TI决定从哪种描述符表中取,再根据段选择符的索引找到相应段描述符的位置
,比较RPL与DPL,若该段无问题,就取出相应的段
描述符放入段描述符高速缓冲寄存器中。
(3)将段描述符中的32 位段基地址和放在ESI、EDI 等中的32 位有效地址相加,就形成
了32 位物理地址。
5、linux中的段机制
从2.2 版开始,Linux 让所有的进程(或叫任务)都使用相同的逻辑地址空间,因此就
没有必要使用局部描述符表LDT。
Linux 在启动的过程中设置了段寄存器的值和全局描述符表GDT 的内容,段寄存器的定义在
include/asm-i386/segment.h 中:
C++ Code
|
1
2 3 4 5 |
#define __KERNEL_CS 0x10
//内核代码段,index=2,TI=0,RPL=0 #define __KERNEL_DS 0x18 //内核数据段, index=3,TI=0,RPL=0 #define __USER_CS 0x23 //用户代码段, index=4,TI=0,RPL=3 #define __USER_DS 0x2B //用户数据段, index=5,TI=0,RPL=3 |
从定义看出,没有定义堆栈段,实际上,Linux 内核不区分数据段和堆栈段,这也体现
了Linux 内核尽量减少段的使用。因为没有使用LDT,因此,TI=0,并把这4 个段描述符都放在GDT
中, index 就是某个段描述符在GDT 表中的下标。内核代码段和数据段具有最高特权,因此其RPL
为0,而用户代码段和数据段具有最低特权,因此其RPL 为3。
全局描述符表的定义在arch/i386/kernel/head.S 中:
C++ Code
|
1
2 3 4 5 6 7 8 9 10 |
ENTRY(gdt_table)
.quad 0x0000000000000000 /* NULL descriptor */ .quad 0x0000000000000000 /* not used */ .quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */ .quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at 0x00000000 */ .quad 0x00cffa000000ffff /* 0x23 user 4GB code at 0x00000000 */ .quad 0x00cff2000000ffff /* 0x2b user 4GB data at 0x00000000 */ .quad 0x0000000000000000 /* not used */ .quad 0x0000000000000000 /* not used */ |
从代码可以看出,GDT 放在数组变量gdt_table 中。按Intel 规定,GDT 中的第一项为
空,这是为了防止加电后段寄存器未经初始化就进入保护模式而使用GDT 的。第二项也没用。
从下标2~5 共4 项对应于前面的4 种段描述符值。对照图2.10,从描述符的数值可以得出:
• 段的基地址全部为0x00000000;
• 段的上限全部为0xffff;
• 段的粒度G 为1,即段长单位为4KB;
• 段的D 位为1,即对这4 个段的访问都为32 位指令;
• 段的P 位为1,即4 个段都在内存。
由此可以得出,每个段的逻辑地址空间范围为0~4GB。
每个段的基地址为0,因此,逻辑地
址到线性地址映射保持不变,也就是说,
偏移量就是线性地址
,我们以后所提到的逻辑地址
(或虚拟地址)和线性地址指的也就是同一地址。看来,Linux 巧妙地把段机制给绕过去了,
它只把段分为两种:用户态(RPL
=3)的段和内核态(RPL=0)的段,
而完全利用了分页机制。
按Intel 的规定,每个进程有一个任务状态段(TSS)和局部描述符表LDT,但Linux 也
没有完全遵循Intel 的设计思路。如前所述,Linux 的进程没有使用LDT,而对TSS 的使用也
非常有限,每个CPU 仅使用一个TSS。
TSS 有它自己 8 字节的任务段描述符(Task State Segment Descriptor ,简称
TSSD)。这个描述符包括指向TSS 起始地址的32 位基地址域,20 位界限域,界限域值不能小
于十进制104(由TSS 段的最小长度决定)。TSS 描述符存放在GDT 中,它是GDT 中的一个表
项,由中断描述符表(IDT)中的任务门(存放TSS段的选择符)装入TR来进行索引。
7、页目录项、页表项、页面项
80386 使用4K 字节大小的页。每一页都有4K 字节长,并在4K 字节的边界上对齐,即每
一页的起始地址都能被4K 整除。因此,80386 把4G 字节的线性地址空间,划分为1G 个页面,
每页有4K 字节大小。分页机制通过把线性地址空间中的页,重新定位到物理地址空间来进行
管理,因为每个页面的整个4K 字节作为一个单位进行映射,并且每个页面都对齐4K 字节的
边界,因此,线性地址的低12 位经过分页机制直接地作为物理地址的低12 位使用。
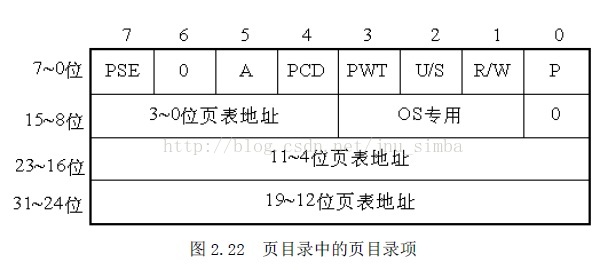
页目录表
,
存储在一个4K 字节的页面中,
最多可包含1024 个
页目录项
,每个页目录项为4 个字节,结
构如图2.22 所示。
•
第31~12 位是20 位页表地址,由于页表地址的低12 位总为0,所以用高20 位指出
32 位页表地址就可以了。
•
第0 位是存在位,如果P=1,表示页表地址指向的该页在内存中,如果P=0,表示不
在内存中。
•
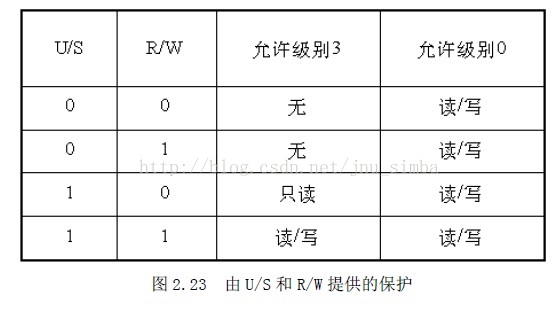
第1 位是读/写位,第2 位是用户/管理员位,这两位为页目录项提供硬件保护。当特
权级为3 的进程要想访问页面时,需要通过页保护检查,而特权级为0 的进程就可以绕过页
保护,如图2.23 所示。
•
第3 位是PWT(Page Write-Through)位,表示是否采用写透方式,写透方式就是既
写内存(RAM)也写高速缓存,该位为1 表示采用写透方式。
第4 位是PCD(Page Cache Disable)位,表示是否启用高速缓存,该位为1 表示启
用高速缓存。
•
第5 位是访问位,当对页目录项进行访问时,A 位=1。
•
第7 位是Page Size 标志,只适用于页目录项。如果置为1,页目录项指的是4MB 的
页面,即扩展分页。
80386 的每个页目录项指向一个
页表
,
存储在一个4K 字节的页面中,
页表最多含有1024 个
页面项
,每项4 个字节,包
含页面的起始地址和有关该页面的信息。页面的起始地址也是4K 的整数倍,所以页面的低
12 位也留作它用,如图2.24 所示。

第31~12 位是
20 位物理页面地址
,除第6 位外第0~5 位及9~11 位的用途和页目录
项一样,第6 位是页面项独有的,当对涉及的页面进行写操作时,D 位被置1。
4GB 的存储器只有一个页目录,它最多有1024 个页目录项,每个页目录项又含有1024
个页面项,因此,存储器一共可以分成1024×1024=1M 个页面。由于每个页面为4K 个字节,
所以,存储器的大小正好最多为4GB。
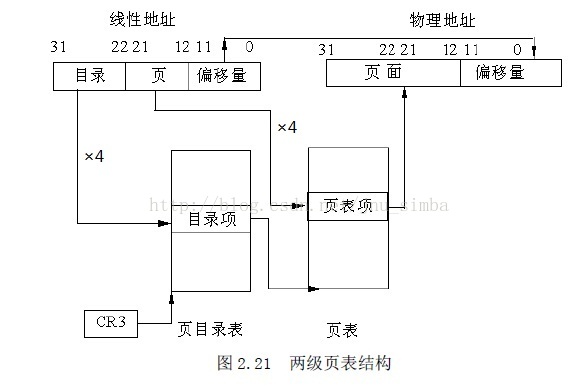
当访问一个操作单元时,如何由分段结构确定的32 位线性地址通过分页操作转化成32
位物理地址呢?
第一步,CR3 包含着页目录的起始地址,用32 位线性地址的最高10 位A31~A22 作为页
目录表的页目录项的索引,将它乘以4,与CR3 中的页目录表的起始地址相加,形成相应页目录项的
地址。
第二步,从指定的地址中取出32 位页目录项,它的低12 位为0,这32 位是页表的起始
地址。用32 位线性地址中的A21~A12 位作为页表中的页表项的索引,将它乘以4,与页表的起
始地址相加,形成相应页表项的地址。
第三步,从指定地址中取出32位页表项,它的低12位为0,这32位是页面地址,将A11~A0 作为相对于页面地址的偏移量,与32 位页面地址相加,形成32 位
物理地址。
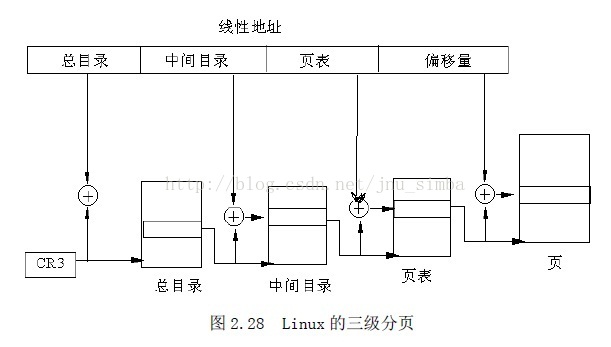
8、linux 中的分页机制
Linux 的分段机制使得所有的进程都使用相同的段寄存器值,这就使得内存管理变得
简单,也就是说,所有的进程都使用同样的线性地址空间(0~4GB)。
Linux 采用三级分页模式而不是两级
。如图2.28 所示为三级分页模式,为此,Linux
定义了3 种类型的表。
• 总目录PGD(Page Global Directory)
• 中间目录PMD(Page Middle Derectory)
• 页表PT(Page Table)
注:本分类下文章大多整理自《深入分析linux内核源代码》一书,另有参考其他一些资料如《linux内核完全剖析》、《linux c 编程一站式学习》等,只是为了更好地理清系统编程和网络编程中的一些概念性问题,并没有深入地阅读分析源码,我也是草草翻过这本书,请有兴趣的朋友自己参考相关资料。此书出版较早,分析的版本为2.4.16,故出现的一些概念可能跟最新版本内核不同。
此书已经开源,阅读地址 http://www.kerneltravel.net
1.进程状态(State)
进程执行时,它会根据具体情况改变状态。进程状态是调度和对换的依据。Linux 中的
进程主要有如下状态,如表4.1 所示。

(1)可运行状态
处于这种状态的进程,要么正在运行、要么正准备运行。正在运行的进程就是当前进程
(由
current 宏
所指向的进程),而准备运行的进程只要得到CPU 就可以立即投入运行,CPU 是
这些进程唯一等待的系统资源。系统中有一个运行队列(run_queue),用来容纳所有处于可
运行状态的进程,调度程序执行时,从中选择一个进程投入运行。
当前运行进程一直处于该队列中,也就是说,current
总是指向运行队列中的某个元素,只是具体指向谁由调度程序决定。
(2)等待状态
处于该状态的进程正在等待某个事件(Event)或某个资源,它肯定位于系统中的某个
等待队列(wait_queue)中。Linux 中处于等待状态的进程分为两种:可中断的等待状态和
不可中断的等待状态。处于可中断等待态的进程可以被信号唤醒,如果收到信号,该进程就
从等待状态进入可运行状态,并且加入到运行队列中,等待被调度;而处于不可中断等待态
的进程是因为硬件环境不能满足而等待,例如等待特定的系统资源,它任何情况下都不能被
打断,只能用特定的方式来唤醒它,例如唤醒函数wake_up()等。
(3)暂停状态
此时的进程暂时停止运行来接受某种特殊处理。通常当进程接收到SIGSTOP、SIGTSTP、
SIGTTIN 或 SIGTTOU 信号后就处于这种状态。例如,正接受调试的进程就处于这种状态。
(4)僵死状态
进程虽然已经终止,但由于某种原因,父进程还没有执行wait()系统调用,终止进程的
信息也还没有回收。顾名思义,处于该状态的进程就是死进程,这种进程实际上是系统中的
垃圾,必须进行相应处理以释放其占用的资源。
A child that terminates, but has
not
been waited
for
becomes a
"zombie"
. The kernel maintains a
minimal set of information about the zombie process (PID, termination status, resource usage
information) in order to allow the parent to later perform a wait to obtain information about the
child. As
long
as a zombie is
not
removed from the system via a wait, it will consume a slot in
the kernel process table,
and
if
this
table fills, it will
not
be possible to create further
processes. If a parent process terminates, then its
"zombie"
children (
if
any) are adopted by
init(
8
), which automatically performs a wait to remove the zombies.
2.进程调度信息
调度程序利用这部分信息决定系统中哪个进程最应该运行,并结合进程的状态信息保证
系统运转的公平和高效。这一部分信息通常包括进程的类别(普通进程还是实时进程)、进
程的优先级等,如表4.2 所示。

当need_resched 被设置时,在“下一次的调度机
会”就调用调度程序schedule();counter 代表进程剩余的时间片,是进程调度的主要依据,
也可以说是进程的动态优先级,因为这个值在不断地减少;nice 是进程的静态优先级,同时
也代表进程的时间片,用于对counter 赋值,可以用nice()系统调用改变这个值;policy
是适用于该进程的调度策略,实时进程和普通进程的调度策略是不同的;rt_priority 只对
实时进程有意义,它是实时进程调度的依据。
进
程的调度策略有3 种,如表4.3 所示。

只有root 用户能通过sched_setscheduler()系统调用来改变调度策略。
3.标识符(Identifiers)
每个进程有进程标识符、用户标识符、组标识符,如表4.4 所示。
不管对内核还是普通用户来说,怎么用一种简单的方式识别不同的进程呢?这就引入了
进程标识符(
PID,process identifier
),每个进程都有一个唯一的标识符,内核通过这个
标识符来识别不同的进程,同时,进程标识符PID 也是内核提供给用户程序的接口,用户程
序通过PID 对进程发号施令。PID 是32 位的无符号整数,它被顺序编号:新创建进程的PID
通常是前一个进程的PID 加1。然而,为了与16 位硬件平台的传统Linux 系统保持兼容,在
Linux 上允许的最大PID 号是32767,当内核在系统中创建第32768 个进程时,就必须重新开
始使用已闲置的PID 号。

4.进程通信有关信息(IPC,Inter_Process Communication)
为了使进程能在同一项任务上协调工作,进程之间必须能进行通信即交流数据。
Linux 支持多种不同形式的通信机制。它支持典型的UNIX 通信机制(IPC Mechanisms):
信号(Signals)、管道(Pipes),也支持System V / Posix 通信机制:共享内存(Shared Memory)、
信号量和消息队列(Message Queues),如表4.5 所示。

5.进程链接信息(Links)
程序创建的进程具有父/子关系。因为一个进程能创建几个子进程,而子进程之间有兄
弟关系,在task_struct 结构中有几个域来表示这种关系。
在Linux 系统中,除了初始化进程init,其他进程都有一个父进程(Parent Process)
。可以通过fork()或clone()系统调用来创建子进程,除了进程标识符(PID)
等必要的信息外,子进程的task_struct 结构中的绝大部分的信息都是从父进程中拷贝
。系统有必要记录这种“亲属”关系,使进程之间的协作更加方便,例如
父进程给子进程发送杀死(kill)信号、父子进程通信等。
每个进程的task_struct 结构有许多指针,通过这些指针,系统中所有进程的
task_struct结构就构成了一棵进程树,这棵进程树的根就是初始化进程init的task_struct
结构(init 进程是Linux 内核建立起来后人为创建的一个进程,是所有进程的祖先进程)。
表4.6 是进程所有的链接信息。

6.时间和定时器信息(Times and Timers)
一个进程从创建到终止叫做该进程的生存期(lifetime)。进程在其生存期内使用CPU
的时间,内核都要进行记录,以便进行统计、计费等有关操作。进程耗费CPU 的时间由两部
分组成:一是在用户模式(或称为用户态)下耗费的时间、一是在系统模式(或称为系统态)
下耗费的时间。每个时钟滴答,也就是每个时钟中断,内核都要更新当前进程耗费CPU 的时
间信息。

7.文件系统信息(File System)
进程可以打开或关闭文件,文件属于系统资源,Linux 内核要对进程使用文件的情况进
行记录。task_struct 结构中有两个数据结构用于描述进程与文件相关的信息。其中,
fs_struct 中描述了两个VFS 索引节点(VFS inode),这两个索引节点叫做root 和pwd,分
别指向进程的可执行映像所对应的根目录(Home Directory)和当前目录或工作目录。
file_struct 结构用来记录了进程打开的文件的描述符(Descriptor)。如表4.9 所示。

在文件系统中,每个VFS 索引节点唯一描述一个文件或目录,同时该节点也是向更低层
的文件系统提供的统一的接口。
8.虚拟内存信息(Virtual Memory)
除了内核线程(Kernel Thread),每个进程都拥有自己的地址空间(也叫虚拟空间),
用
mm_struct
来描述。另外Linux 2.4 还引入了另外一个域active_mm,这是为内核线程而
引入的。因为内核线程没有自己的地址空间,为了让内核线程与普通进程具有统一的上下文
切换方式,当内核线程进行上下文切换时,让切换进来的线程的active_mm 指向刚被调度出
去的进程的mm_struct。内存
信息如表4.10 所示。

9.页面管理信息
当物理内存不足时,Linux 内存管理子系统需要把内存中的部分页面交换到外存,其交
换是以页为单位的。有关页面的描述信息如表4.11。

10.对称多处理机(SMP)信息
Linux 2.4 对SMP 进行了全面的支持,表4.12 是与多处理机相关的几个域。

11.和处理器相关的环境(上下文)信息(Processor Specific Context)
这里要特别注意标题:和“处理器”相关的环境信息。进程作为一个执行环境的综合,
当系统调度某个进程执行,即为该进程建立完整的环境时,处理器(Processor)的寄存器、
堆栈等是必不可少的。因为不同的处理器对内部寄存器和堆栈的定义不尽相同,所以叫做“和
处理器相关的环境”,也叫做“处理机状态”。当进程暂时停止运行时,处理机状态必须保
存在进程的
thread_struct
结构(多线程的话每个线程都有一份)中,当进程被调度重新运行时再从中恢复这些环境,也就是恢
复这些寄存器和堆栈的值。处理机信息如表4.13 所示。

12.其他
(1)struct wait_queue *wait_chldexit
在进程结束时,或发出系统调用wait 时,为了等待子进程的结束,而将自己(父进程)
睡眠在该等待队列上,设置状态标志为TASK_INTERRUPTIBLE,并且把控制权转给调度程序。
(2)Struct rlimit rlim[RLIM_NLIMITS]
每一个进程可以通过系统调用setrlimit 和getrlimit 来限制它资源的使用。
(3)Int exit_code exit_signal
程序的返回代码以及程序异常终止产生的信号,这些数据由父进程(子进程完成后)轮
流查询。
(4)Char comm[16]
这个域存储进程执行的程序的名字,这个名字用在调试中。
(5)Unsigned long personality
Linux 可以运行X86 平台上其他UNIX 操作系统生成的符合iBCS2 标准的程序,
personality 进一步描述进程执行的程序属于何种UNIX 平台的“个性”信息。通常有
PER_Linux,PER_Linux_32BIT,PER_Linux_EM86,PER_SVR4,PER_SVR3,PER_SCOSVR3,
PER_WYSEV
386,PER_ISCR4,PER_BSD,PER_XENIX 和PER_MASK 等,参见include/Linux/personality.h>。
(6) int did_exec:1
按POSIX 要求设计的布尔量,区分进程正在执行老程序代码,还是用系统调用execve()
装入一个新的程序。
(7)struct linux_binfmt *binfmt
指向进程所属的全局执行文件格式结构,共有a.out、script、elf、java 等4 种。
二、进程组织方式
1、内核栈
每个进程都有自己的内核栈,
当进程从用户态进入内核态时,CPU 就自动地设置该进程
的内核栈,
也就是说,CPU 从任务状态段TSS 中装入内核栈指针esp,
在/include/linux/sched.h 中定义了如下一个联合结构:
C++ Code
|
1
2 3 4 5 6 |
union task_union
{ struct task_struct task; unsigned long stack[ 2408]; }; |

从这个结构可以看出,内核栈占8KB 的内存区。实际上,进程的task_struct 结构所占
的内存是由内核动态分配的,更确切地说,内核根本不给task_struct 分配内存,而仅仅给
内核栈分配8KB 的内存,并把其中的一部分给task_struct 使用。
task_struct 结构大约占1K 字节左右,其具体数字与内核版本有关,因为不同的版本其
域稍有不同。因此,内核栈的大小不能超过7KB,否则,内核栈会覆盖task_struct 结构,
从而导致内核崩溃。不过,7KB 大小对内核栈已足够。
2、current 宏
当一个进程在某个CPU 上正在执行时,内核如何获得指向它的task_struct 的指针?
在linux/include/i386/current.h 中
定义了current 宏,这是一段与体系结构相关的代码:
C++ Code
|
1
2 3 4 5 6 7 8 |
static
inline
struct task_struct *get_current(void)
{ struct task_struct *current; __asm__( "andl %%esp,%0; ": "=r" (current) : "0" (~8191UL)); return current; } |
3、哈希表
Linux 在进程中引入的哈希表叫做
pidhash,在include/linux/sched.h 中定义如下:
C++ Code
|
1
2 3 4 |
#define PIDHASH_SZ (4096 >> 2)
extern struct task_struct *pidhash[PIDHASH_SZ]; #define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1)) |
其中,PIDHASH_SZ 为表中元素的个数,表中的元素是指向task_struct 结构的指针。
pid_hashfn 为哈希函数,把进程的PID 转换为表的索引。通过这个函数,可以把进程的PID
均匀地散列在它们的域(0 到 PID_MAX-1)中。
Linux 利用链地址法来处理冲突的PID:也就是说,每一表项是由冲突的PID 组成的双
向链表,这种链表是由task_struct 结构中的pidhash_next 和 pidhash_pprev 域实现的,
同一链表中pid 的大小由小到大排列。
4、双向循环链表
哈希表的主要作用是根据进程的pid 可以快速地找到对应的进程,但它没有反映进程创
建的顺序,也无法反映进程之间的亲属关系,因此引入双向循环链表。每个进程task_struct
结构中的prev_task 和next_task 域用来实现这种链表。
链表的头和尾都为init_task,它对应的是进程0(pid 为0),
也就是所谓的空进程,它是所有进程的祖先。
5、运行队列
当内核要寻找一个新的进程在CPU 上运行时,必须只考虑处于可运行状态的进程(即在
TASK_RUNNING 状态的进程),因为扫描整个进程链表是相当低效的,所以引入了可运行状态
进程的双向循环链表,也叫运行队列(run queue)。
该队列通过task_struct 结构中的两个指针run_list 链表来维持。队列的标志有两个:
一个是“空进程”idle_task;一个是队列的长度,
,也就是系统中处于可运行状态(TASK_RUNNING)的进程数
目,用全局整型变量nr_running 表示。
6、等待队列
进程必须经常等待某些事件的发生,例如,
等待一个磁盘操作的终止,等待释放系统资源或等待时间走过固定的间隔。等待队列实现在
事件上的条件等待,也就是说,希望等待特定事件的进程把自己放进合适的等待队列,并放
弃控制权。因此,等待队列表示一组睡眠的进程,当某一条件变为真时,由内核唤醒它们。
等待队列由循环链表实现。
7、内核线程
内核线程(thread)(也称为daemon)
•
内核线程执行的是内核中的函数,而普通进程只有通过系统调用才能执行内核中的函
数。
•
内核线程只运行在内核态,而普通进程既可以运行在用户态,也可以运行在内核
态。
•
因为内核线程指只运行在内核态,因此,它只能使用大于PAGE_OFFSET(3G)的地址
空间。另一方面,不管在用户态还是内核态,普通进程可以使用4GB 的地址空间。

















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









