







pianogirl 原创作品转载请注明出处 + 《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、进程的描述
1、struct task_struct(PCB)
task_struct内容非常庞大,大致分为:
- 进程描述信息:
PID、家族… - 进程控制、调度信息:
当前状态、调度信息、计时信息… - 资源信息:
使用的存储器空间、打开的文件… - 现场信息:
当时CPU运行现场,以便下次切换时能够精准地继续运行。
2、在processor.h中查看task_struct的具体字段
(参考同学制图:http://www.cnblogs.com/hyq20135317/p/5337216.html)





3、进程的状态
进程状态:进程描述符中state域描述了进程的当前状态。
TASK_RUNNING(可执行)
TASK_INTERRUPTIBLE(正被阻塞)
TASK_UNINTERRUPTIBLE(不可中断)
_TASK_TRACED(被其他进程跟踪)
_TASK_STOPPED(进程停止执行)
Linux进程状态之间的转换:

4、进程在内存中是怎样的
下图为个人理解,如有不当请指正!
【我画的图是一般的两个进程在内存中的情况,包括各自的堆栈空间、PCB板(保存了各个进程自己的sp、ip)、数据、以及切换时SAVE_ALL保存当时寄存器所有数值的情形。】
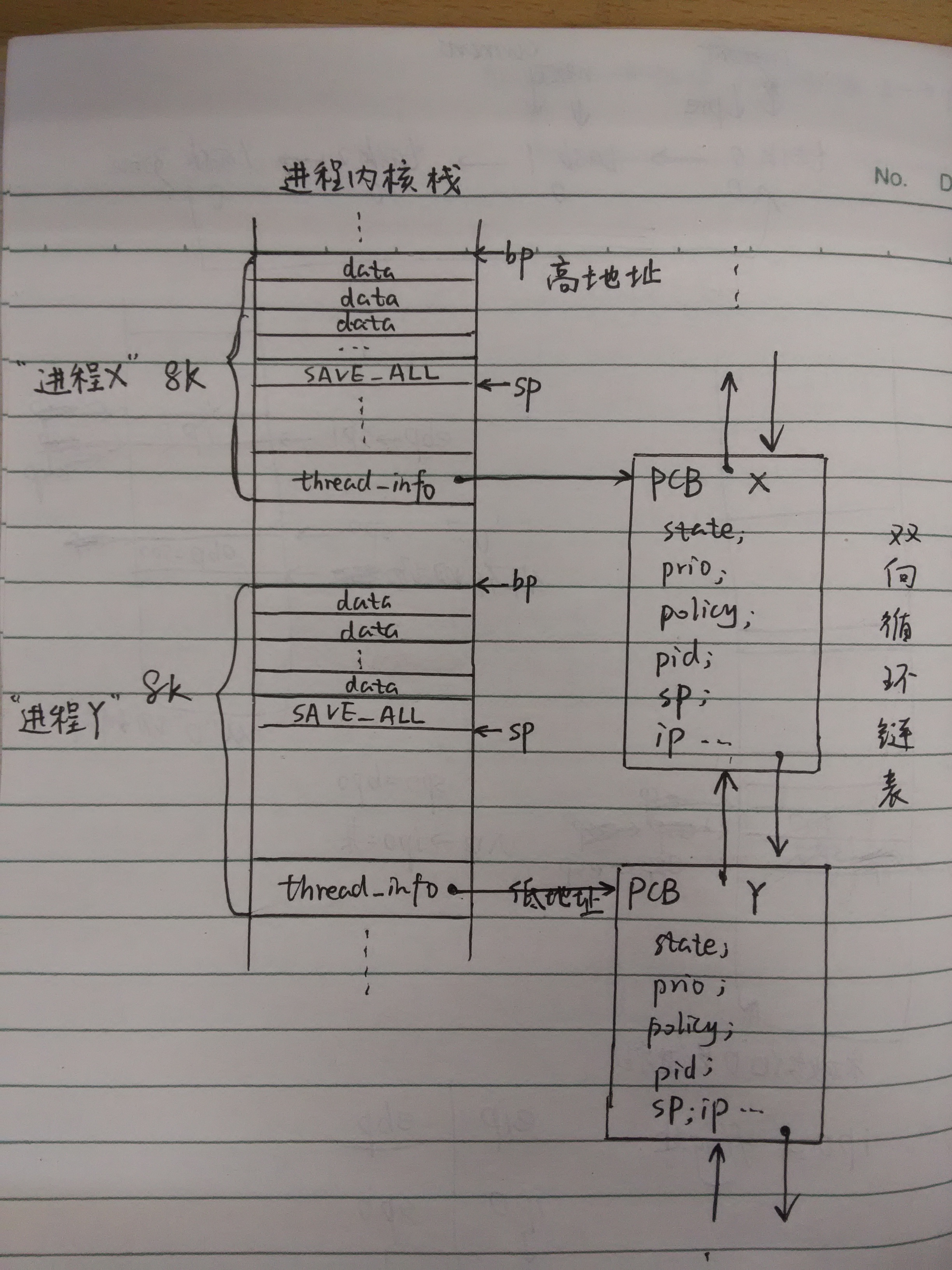
Linux分配机制:
Linux通过Slab分配器分配task_struct结构。对于向下增长的栈来说,需要在栈底创建一个新的结构struct thread_info,而struct thread_info 中有一个指向该进程PCB的指针。
对于X86这样寄存器较少的结构来说:
通常分配8k的内核堆栈。通过计算偏移,间接找到task_struct结构。
二、进程的创建
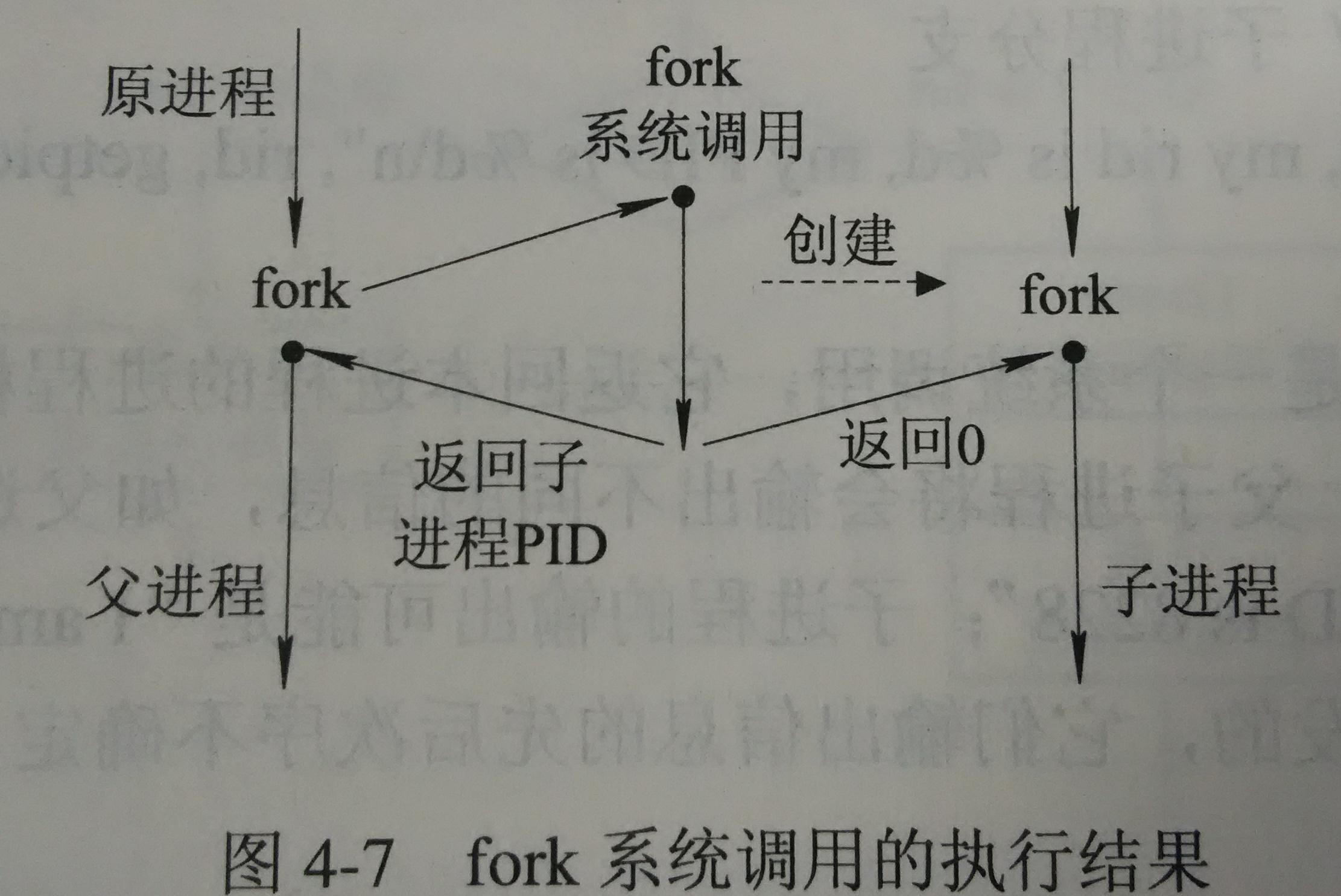
fork、vfork和clone三个系统调用都可以创建一个新进程,而且都是通过调用do_fork来实现进程的创建。
创建新进程是通过复制当前进程实现的。
do_fork主要是复制了父进程的task_struct,然后修改必要的信息,从而得到子进程的task_struct。归纳、总结后的关键过程如下(更多细节,尤其函数之间的调用层次见http://www.cnblogs.com/hyq20135317/p/5337216.html)。
1、 复制一个PCB板——task_struct:
err = arch_dup_task_struct(tsk, orig); //直接指针赋值2、给新进程分配一个新的内核堆栈:
ti = alloc_thread_info_node(tsk, node); //分配一个struct thread_info类型的空间
tsk->stack = ti; //将thread_info(同时也就是栈底)的地址赋给task的stack变量
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈3、修改复制过来的进程数据,比如pid、进程链表等。
4、子进程的启动:
*childregs = *current_pt_regs(); //复制内核堆栈
childregs->ax = 0; //子进程的fork返回0的原因
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址刚fork出来的子进程接着从ret_from_fork开始执行,然后跳转到syscall_exit,从系统调用中返回。
5、小结
上面那张我画的图是一般的两个进程在内存中的情况,但是也可以帮助我们理解系统是怎样fork一个子进程并返回到用户态的。
如果这两个进程X、Y是父子进程关系的话:
- 假设进程X通过系统调用fork()创建了Y进程。
- 结合上面的分析,我们知道有PCB的复制和修改、为子进程开辟一块8k的内核堆栈等过程。
- 不同的是,我的图上“进程Y”的栈底应该没有数据,只有从父进程那里copy过来的SAVE_ALL(这是一个宏,实际上是把所有寄存器值打包变成的一个结构体),也就是*childregs = *current_pt_regs();
- 复制完SAVE_ALL后,将sp移到子进程栈顶:p->thread.sp = (unsigned long) childregs;
- p->thread.ip = (unsigned long) ret_from_fork;
这一句的理解非常关键。刚fork出来的子进程从ret_from_fork开始执行,自动跳转到syscall_exit,从系统调用中返回。这样就指定了新进程的第一条指令地址。
【举例】上周我的blog中自选的系统调用服务恰好是fork,代码如下:
#include <unistd.h>
#include <stdio.h>
int main ()
{
pid_t fpid;
fpid = fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0) {
printf("i am the child process, my process id is %d\n",getpid());
}
else {
printf("i am the parent process, my process id is %d\n",getpid());
}
return 0;
}
- 对于父进程来说:
通过系统调用fork()陷入内核。完成系统调用2号服务例程后,从iret返回,并恢复之前SAVE_ALL的寄存器值,从内核态回到用户态,继续执行用户态代码printf("i am the parent process, my process id is %d\n",getpid()),所以打印的是子进程pid值。 对于子进程来说:
由于是父进程创建的,一出生就存在于内核中了。用户代码fork()之前的它管不了,只能管fork()之后的代码。于是ret_from_fork–>syscall_exit,恢复父进程保存在SAVE_ALL的寄存器值,从内核态回到用户态,继续执行用户态代码printf("i am the child process, my process id is %d\n",getpid())。由于ax寄存器值赋值为0,所以返回值为0,打印的是0。三、实验:gdb跟踪内核
准备工作:
rm menu -rf
git clone http://github.com/mengning/menu.git # 更新Menu
cd menu
mv test_fork.c test.c # 把test.c覆盖掉
make rootfs
执行fork,可以看到父进程子进程都输出了信息。
进行gdb调试:
qemu -kernel linux-3.18.6/arch/x86/boot/bzImage -initrd rootfs.img -s -S
gdb
file linux-3.18.6/vmlinux
target remote:1234
// 设置断点
b sys_clone # 因为fork实际上是执行的clone
b do_fork
b dup_task_struct
b copy_process
b copy_thread
b ret_from_fork
c
n
……
四、总结
这次的学习过程不是一帆风顺的。虽然上周实验机智地使用了fork并预先学习了,然而这周看视频里的源代码还是晕。后来看书,并尝试着自己画图,突然就明白了许多(或许有不对的地方,请指正!!),又参考了同学的博客,细节上把握更细致了。收获很大。
参考资料:《Linux内核设计与实现》《Linux操作系统原理》
http://www.cnblogs.com/hyq20135317/p/5337216.html















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









