







最长回文子串
题目链接:
http://hihocoder.com/problemset/problem/1032?sid=480298
解题思路:
Manacher’s Algorithm
先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组p记录以每个字符为中心的最长回文串的信息。p[id]记录的是以字符str[id]为中心的最长回文串的半径(包含str[id]本身)。
原串: abababa
新串: *#a#b#a#b#a#b#a#
辅助数组P : 1121416181614121
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。
下面是插入的代码:
for(int i = len; i >= 0; i--){
//插入'#'
str[i+i+2] = str[i];
str[i+i+1] = '#';
}//插入了len+1个'#',最终的s长度是1~len+len+1即2*len+1,首尾s[0]和s[2*len+2]要插入不同的字符
str[0]='*';//s[0]='*',s[len+len+2]='\0',防止在while时p[i]越界
对于字符串S=abcdcba而言,最长回文子串是以d为中心,半径为3的子串。当我们采用上面的做法分别求出以S[1]=a, S[2]=b, S[3]=c, S[4]=d为中心的最长回文子串后,对S[5]=c,S[6]=b...还需要一一进行扩展求吗?答案是NO。因为我们已经找到以d为中心,半径为3的回文了,S[5]与S[3],S[6]与S[2]...,以S[4]为对称中心。因此,在以S[5],S[6]为中心扩展找回文串时,可以利用已经找到的S[3],S[2]的相关信息直接进行一定步长的偏移,这样就减少了比较的次数(回想一下KMP中next数组的思想)。优化的思想找到了,我们先看下核心代码:
for(int i = 1; str[i]; i++){
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (str[i + p[i]] == str[i - p[i]])
p[i]++;
if (i + p[i] > mx){
mx = i + p[i];
id = i;
}
if(maxl < p[i])
maxl = p[i];
}这里进行简单的解释:上述代码中有三个主要变量,它们代表的意义分别是:
p:以S[i]为中心的最长回文串的半径为p[i]。
id:已经找出的最长回文子串的起始位置。
mx:已经找出的最长回文子串的结束位置。
算法的主要思想是:先找出所有的p[i],最大的p[i]即为所求。在求p[j](j>i)时,利用已经求出的p[i]减少比较次数。代码中比较关键的一句是:p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
在求p[i]时:
如果 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配;
如果 mx>i,则表明已经求出的最长回文中包含了p[i],那么与p[i]关于idx对称的p[(id<<1)-i]的最长回文子串可以提供一定的信息:
当P[id]+id=mx>i 时说明以i为中心点可能存在回文子串,这时就可以将P[i]初始化成该回文子串的值在进行扩展搜索回文子串的半径是否能够增大,省去了P[i]从0开始搜索的一些步骤。
A: mx-i > P[j]的情形。这时的字符串可以表示成下图(注意到j = 2*id-1):
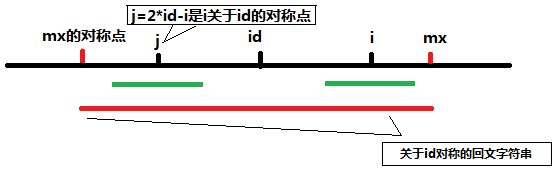
图中最下面的红色线条是之前求得的索引号i之前的那个使得回文子串最右面的字符的索引号最大的那个回文子字符串。j点是i关于id的对称点,由于红的字符串是回文字符串,所以关于j对称的回文子串和关于i对称的回文子串是完全一样的(图中两段绿色的线条),而满足mx-i>P[j]时说明此时j的回文子串半径小于j到mx关于j对称的左端点的差,此时可以初始化P[i]=P[j]。
B: mx-i <= P[j]的情形。这时的字符串可以表示成下图:

图中最下面的红色线条仍然是之前求得的索引号i之前的那个使得回文子串最右面的字符的索引号最大的那个回文子字符串。j点是i关于id的对称点,由于红的字符串是回文字符串,所以关于j对称的回文子串和关于i对称的在mx和mx的对称点之间的回文子串是完全一样的(图中两段绿色的线条),而满足mx-i<=P[j]时说明此时j的回文子串半径大于或等于j到mx关于j对称的左端点的差,此时可以先初始化P[i]=mx-i,然后再对P[i]的回文子串半径进行进一步的增大。
AC代码:
#include <iostream>
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
const int N = 1000005;
char str[N*2];
int p[N*2];
int main(){
int T;
scanf("%d",&T);
while(T--){
scanf("%s",str);
int len = strlen(str),id = 0,maxl = 0,mx = 0;
for(int i = len; i >= 0; i--){
//插入'#'
str[i+i+2] = str[i];
str[i+i+1] = '#';
}//插入了len+1个'#',最终的s长度是1~len+len+1即2*len+1,首尾s[0]和s[2*len+2]要插入不同的字符
str[0] = '*';str[len+len+2] = '\0';//防止在while时p[i]越界
for(int i = 2; str[i]; i++){
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (str[i + p[i]] == str[i - p[i]])
p[i]++;
if (i + p[i] > mx){
mx = i + p[i];
id = i;
}
if(maxl < p[i])
maxl = p[i];
}
printf("%d\n",maxl-1);
}
return 0;
}















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









