




前言
在现代数据技术栈中,元数据管理已从一个可有可无的选项演变为支撑数据发现、治理和互操作性的核心基础。随着数据生态系统的日益复杂和分散,企业迫切需要一个统一的控制平面来管理其宝贵的数据和 AI 资产。本次分析报告旨在对三个领先的开源元数据平台进行深入、详尽的技术评估:Apache Gravitino、DataHub 和 Unity Catalog 开源版(OSS)。这三个平台代表了解决现代元数据挑战的三种截然不同的哲学理念和架构范式。
-
Apache Gravitino 将自身定位为一个“联邦元数据湖”,其核心理念是直接管理。它并非被动地收集元数据,而是通过连接器主动地、双向地管理底层数据源,确保元数据在 Gravitino 与源系统之间实时同步。这种架构提供了强大的跨源一致性控制,并支持地理分布式部署,使其成为寻求对异构、多区域数据环境进行集中化、强力管控的组织的理想选择。
-
DataHub 是一个成熟的、功能丰富的事件驱动型元数据图谱。它采用“模式优先”(schema-first)和流式处理架构,将元数据变更视为事件流,通过 Apache Kafka 进行实时传播。这使其不仅是一个被动的目录,更是一个支持数据运营(DataOps)自动化的主动平台。凭借其广泛的连接器生态系统、成熟的用户界面和强大的数据发现能力,DataHub 成为寻求开箱即用的企业级数据目录和治理解决方案的首选。
-
Unity Catalog OSS 的目标并非成为一个大而全的应用,而是致力于建立一个数据与 AI 互操作性的通用开放标准。其核心是基于 OpenAPI 规范的开放 API,旨在消除供应商锁定,通过与 Apache Hive Metastore 和 Iceberg REST Catalog API 的兼容性,促进一个由众多引擎、工具和平台组成的广泛生态系统。选择 Unity Catalog OSS,意味着投资于一个新兴的、由行业巨头推动的 foundational protocol,而非一个单一的产品。
本报告将从基础架构、元数据模型、数据治理能力、部署运维以及社区生态等多个维度,对这三个平台进行全面解构和比较。报告特别强调了 Unity Catalog OSS 版本与其在 Databricks 平台内的商业版本之间的关键功能差距,尤其是在数据治理和数据血缘方面。最终,报告将提供一个战略性的用例适用性矩阵,旨在为数据架构师、平台负责人和首席工程师等技术决策者提供清晰、有力的依据,以帮助他们根据自身的组织需求、技术栈和战略目标,做出最明智的平台选型决策。
第一部分:基础架构与核心哲学
每个元数据平台的设计都根植于一种核心哲学,其架构选择直接决定了其能力、局限性和最佳应用场景。理解这些基础架构是评估其适用性的第一步。本节将解构这三个平台的核心设计原则。
1.1 Apache Gravitino:作为直接管理层的联邦元数据湖

Apache Gravitino 的核心哲学是成为一个主动的、联邦式的管理层,而非一个被动的元数据收集器。它将自己定义为一个“元数据湖”(Metadata Lake),旨在为跨越不同系统、区域和云的元数据提供单一事实来源(Single Source of Truth, SSOT)。
其最显著的特征是直接元数据管理(Direct Metadata Management)。与传统系统需要定期拉取或被动接收元数据不同,Gravitino 通过其连接器直接与底层数据源交互。当用户通过 Gravitino 的 API 执行操作时——例如创建一个新的 Hive 表或修改一个 PostgreSQL 的 schema——这些变更会实时地在底层源系统中生效。反之,源系统的某些变更也能反映到 Gravitino 中,从而保证了元数据视图的实时一致性。
这种设计理念体现在其分层架构中:
- 功能层(Functionality Layer):暴露了用于元数据 CRUD(创建、读取、更新、删除)和治理(如访问控制、数据发现)的 API。
- 接口层(Interface Layer):目前主要提供标准的 REST API 作为与用户和应用交互的接口,并计划在未来支持 Thrift 和 JDBC 接口。
- 核心对象模型(Core Object Model):定义了一套通用的、统一的元数据模型,用以抽象和表示来自不同来源和类型的元数据,实现了对异构元数据的统一管理。
- 连接层(Connection Layer):这是一个可插拔的连接器系统,是实现直接管理逻辑的核心。它包含了一系列用于连接不同元数据源(如 Apache Hive、MySQL、PostgreSQL 等)的连接器。
基于这种架构,Gravitino 衍生出几个关键特性:
- 地理分布支持(Geo-Distribution Support):Gravitino 的架构原生支持跨区域或跨云部署。不同的 Gravitino 实例可以相互连接并共享元数据,为全球化的组织提供一个统一的、跨地域的元数据视图。
- 多引擎支持(Multi-Engine Support):通过为 Trino、Spark 和 Flink 等查询引擎提供连接器,Gravitino 使这些引擎能够通过其统一的命名空间访问数据,而无需修改现有的 SQL 方言。
1.2 DataHub:事件驱动的实时元数据图谱
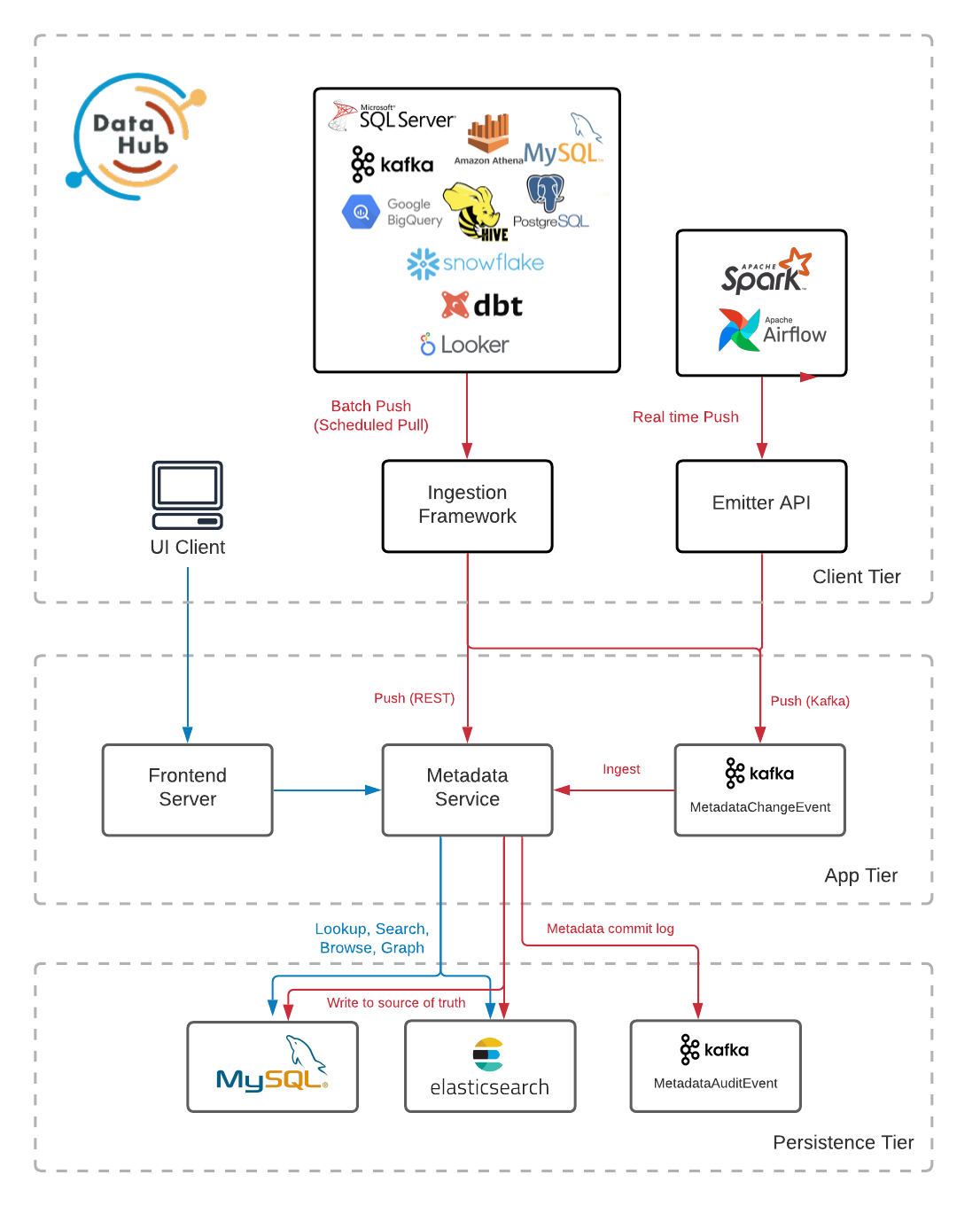
DataHub 的架构设计围绕一个核心理念:构建一个集中式的、基于流的元数据平台。其哲学是“模式优先”(schema-first)和事件驱动。在 DataHub 的世界里,每一次元数据的变更都被视为一个事件,在一个事件流中传播。这种设计使其能够实现近乎实时的元数据更新,并支持构建对元数据变化做出反应的自动化系统(例如,一个访问控制系统可以实时监测到某个数据集被添加了 PII 标签,并立即触发访问权限审查)。它扮演着一个中心枢纽的角色,通过推(push)和拉(pull)两种机制,从庞大的数据生态系统中聚合元数据。
DataHub 的架构由以下关键组件构成:
- 采集框架(Ingestion Framework):一个高度灵活的框架,支持基于拉取的爬虫(用于从 Snowflake、BigQuery 等数据源定期抓取元数据)和基于推送的发射器(用于从 Airflow、Spark 等工具在元数据生成时主动推送)。所有元数据变更都被封装为元数据变更提案(Metadata Change Proposals, MCPs)。
- 元数据变更日志(Metadata Change Log, MCL):这是一个以 Apache Kafka 为核心的事件流,是所有已提交元数据变更的中央日志。它是 DataHub 实时特性的基石。
- 服务层(Serving Tier, GMS - General Metadata Service):这是 DataHub 的核心服务,负责将元数据持久化到主存储(如 MySQL 或 PostgreSQL),暴露 REST 和 GraphQL API,并向 MCL 生成事件。
- 索引与图层(Index and Graph Tier):异步的消费者作业(
mae-consumer-job)从 MCL 读取事件,并相应地更新 Elasticsearch 中的搜索索引和图数据库(如 Neo4j)中的血缘关系图。
这种架构赋予了 DataHub 几个核心优势:
- 实时更新:基于流的架构确保了元数据变更能在数秒内反映到整个平台。
- 联邦所有权(企业级特性):尽管开源版的 DataHub 通常部署一个中央 GMS,但其架构支持由不同团队拥有和运营的联邦式元数据服务。这些服务通过 Kafka 与中央索引和图数据库通信,在支持全局搜索和发现的同时,实现了元数据的解耦所有权。这使得 DataHub 的架构非常适合实施数据网格(Data Mesh)的组织。
- 高度可扩展性:采用“模式优先”的方法(使用 Pegasus 定义语言 - PDL)和事件驱动的特性,使得添加新的实体类型或元数据切面(Aspect)变得非常容易,具有极高的可扩展性。
1.3 Unity Catalog OSS:数据与 AI 互操作性的通用标准

Unity Catalog (UC) OSS 的核心哲学并非成为一个像 DataHub 那样功能齐全的一站式应用,而是旨在建立数据与 AI 领域的通用目录标准。其首要目标是通过提供一个开放的、基于 OpenAPI 规范的接口,来消除供应商锁定,并促进一个任何引擎、工具和平台都可以集成的广泛生态系统。
UC OSS 的架构围绕以下几个核心组件构建:
- OpenAPI 规范:UC 的基石是其 REST API,该 API 在一个 OpenAPI 规范文件(
api/all.yaml)中被严格定义。这种 API 优先的方法鼓励了广泛的第三方集成。 - 服务器实现:该开源项目提供了一个遵循 OpenAPI 规范的服务器实现(主要由 Java 和 Scala 编写)。它需要一个后端数据库(如 MySQL 或 PostgreSQL)来进行元数据持久化。
- 客户端兼容性:UC OSS 在设计上有意兼容现有的行业标准,特别是 Apache Hive Metastore (HMS) API 和 Apache Iceberg REST Catalog API。这是一个战略性的选择,旨在降低现有工具的集成和采用门槛。
- UniForm:这是一项关键的使能技术,它允许单个表副本能够同时被视为 Delta Lake、Iceberg 或 Hudi 格式,从而在数据格式层面极大地促进了互操作性。
1.4 架构综合分析:设计权衡的深层解读
对这三个平台架构的深入分析揭示了它们在设计上的根本性权衡,这些权衡直接影响着它们的适用场景和战略价值。
首先,核心的架构张力体现在 Gravitino 的“就地管理”联邦模式与 DataHub 的“拉取/推送并集中”模式之间。Gravitino 的直接管理方法意味着它成为了在源系统中创建和修改元数据对象的权威控制平面。这为跨异构系统的联邦环境提供了强大的一致性保证和集中化控制。然而,这也要求 Gravitino 必须拥有对所有数据源的高权限访问,这在操作上和安全上都可能构成挑战。相比之下,DataHub 的模型侵入性较小,它主要需要对数据源的读取权限,以便将元数据拉取到其中心化的图谱中。这种方式简化了集成过程,但引入了潜在的数据延迟(取决于采集任务的运行频率),并使 DataHub 成为一个被动的观察者而非主动的管理者。对于正在实施数据网格(Data Mesh)且希望领域团队保留对其数据产品完全控制权的组织来说,Gravitino 的模型可能显得过于中心化。反之,对于一个旨在跨异构环境强制推行统一标准的中央数据平台团队而言,Gravitino 的直接控制能力则是一个强大的特性。DataHub 的模型更像是一个发现和治理的覆盖层,能够很好地适应中心化和去中心化的组织结构。
其次,DataHub 的定位是一个完整的应用,而 Unity Catalog OSS 的定
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











