






文章是关于何凯明的residual network 第三部分,Deep Residual Learning 部分的一些个人解读。
写在前面:
看到这篇博客的你可能是一名正在入门的苦逼学生或者工作党,如果您是业界大牛,首先我感谢您能抽空来浏览我的帖子,我下面说的这些话你就可以直接跳过了。
像 residual network 这种划时代的论文,我建议你从读原文下手,不要害怕是英文看不懂,可以多看几遍,花时间在这上面是值得的。不要在网上随便看两篇博客就以为自己懂了,这样是对自己的不负责任。我认为博客里写的都是在很大程度上加入了作者的个人理解,是别人嚼过的,你很难真正的理解原文的全部核心以及作者的思维。自己先看,有问题了再来网上看一些别人的理解,看看能不能帮助到自己。
-
3.1 residual learning
首先我们假设H(x)使我们使用这些网络想要得到的一个潜在的映射,并且将x 看作为这部分网络的输入。
(也就是说我们想通过一些非线性网络的叠加,将输入的x 经过学习(或者说是运算、处理)得到理想的输出H(x) )
这样一来,我们就可以理所应当的做出这样的一个假设,即假设这些非线性网络层的堆叠可以近似的看作是一个函数,
即 给定输入x 得到 输出H(x) 的这样一个函数。(这里可能需要思考一下,理解理解)
这样的假设其实是等价于 这些非线性网络的堆叠可以近似的看做是残差函数的作用(residual function),
例如我们此篇文章中的 H(x)- x (ps:需要两者有着相同的dimensions,因为这样才能做减法)
所以,接下来我们的目的就不是以 将堆叠的网络层 所输出的结果拟合成H(x) 了, 我们有了更加明确的结果,即将网络层的输出向F(x) = H(x) - x 的方向来拟合。
(这里可以看到,一个使用残差学习(residual learni)所定义的网络模块(few stacked layer) , 其目的是将输出与输入之间的差值作为整个部分所要拟合的结果)
有了上面F(x) 的式子,就可以用 H(x) = F(x) + x 的方式来表示Hx。
作者之所以有这样的想法是源于一个反直觉的问题,也就是出现退化现象的问题。
if the added layers can be constructed as identity mapping ,
如果添加的网络层可以被构建成为恒等映射的形式 , 那么使用一个更深层网络的效果是一定要比使用 派生出这个深层网络的浅层网络的效果要好。 (当然这是被证伪的)
退化现象的出现正是说明了 我们的这个solver maybe 很难去通过 一些非线性层的叠加来 逼近一个恒等映射(approximate identity mapping)。
不能进行恒等映射,所以输入与输出的值就不会相同, 可能是将输入的结果做出了一定量的优化,但是也有可能是出现退化的情况。
在residual learning 当中,如果出现了退化的现象,也就是说Hx-x 的值为负,那么就放弃这个部分的作用,直接改用恒等映射,这样一来这部分的负优化便被遗弃了。
放弃的方法是将这部分的w全部置0。
什么是恒等映射( identity mapping ) ?
在我的印象里恒等映射就是y = x 这样集合上的映射,用在这里应当指的是 x = H(x)吧。
在实际情况下,恒等映射不太可能是最优的,但是我们的重构可能有助于对问题进行预处理。
如果最优函数比零映射更接近于恒等映射,则求解器应该更容易找到关于恒等映射的抖动,(抖动应当就是残差吧)
而不是将该函数作为新函数来学习。我们通过实验(图7)显示学习的残差函数通常有更小的响应,表明恒等映射提供了合理的预处理。
图7如下:

magnitude 量级,梯度
或者可以这样说: 对于一个深层网络,如果它具有退化成Identity Mapping的能力,那么它一定是容易优化、并且具有很好性能的。
-
3.2 identity mapping by shortcuts
ok , 前面的意思说的很清楚了,在使用了 residual learning 之后,我们few stacked layers 要么就是学习正向激励的HX - X,
要么就是 identity mapping, 这样一来,即使出现退化的情况,也可以避免,不会再出现degradation了。
这部分主要讲的就是 如何实现 identity mapping的, 通过章节的名字你也应该能够猜出来,是通过一种叫做 shortcuts 的方法。

我们在 every few stacked layers 上应用residual learning, 构建的模块如上图所示。
我们将上图的这种模块定义为:
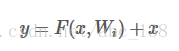
x 和y 分别是输入和输出向量, 这其中的F(x,wi)表示的所是要学习的残差映射(residual mapping),
(例如 F = w2 α(w1 x)表示的就是两层网络组成的一个小模块,其中α表示ReLU,这里为了表达方便我们省去了bias )
而我们之前所表示的 Hx = F(x) + x 的表达式, 就可以用一个shortcut connection 和 element-wise 的相加来表达。
(我认为 shortcut connection 指的是右面的 identity mapping的部分, 而element-wise当然指的是左侧的部分)
shortcut connection 部分既没有增加额外的参数,也没有增加额外的复杂度,这就给了我们公平比较 残差连接的网络与之前网络性能的机会。
然后文章又说了一些在维度上的问题,以用来在pooling或者大stride的卷积后来继续使用 residual learning .
3.3 & 3.4 略














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









