






Java后端面试
经历了两个月的面试和准备,下面对常见的八股文进行总结。有些问题是网上看到的面经里提到的,有些是我真实面试过程遇到的。
异常
1、异常分为哪几种?他们的父类是什么?
注意:所有异常对象的父类为Throwable
- Error及其子类:
- 一般指的是虚拟机的错误,是由java虚拟机生成并抛出,程序不能进行处理,所以也不加处理,例如OutOfMemoryError内存溢出。
- RuntimeException及其子类(运行时异常):
- 是由编程bug所致。如NullPointerException、ClassCastException、ArrayIndexOutOfBoundsException、ArithmeticException
- Exception及其子类中除了RuntimeException及其子类之外的其它异常(受检型异常):
- 编译器就能检测的异常,JAVA 编译器强制要求我们必需对出现的这些异常进行 try-catch或者throws,否则编译不会通过。如IOException、ClassNotFoundException
2、受检异常与非受检异常的区别?
同上。
3、Error可以捕获吗?
可以。Throwable 的子类,都可以被 try-catch 语句捕获,分为 Error 和 Exception。
4、栈溢出和堆溢出是什么?OOM可以捕获吗?什么情况可以捕获?
栈溢出:栈帧堆积,超过设置的栈的大小。
OOM 作为一个 Error,在某些条件下是可以被 catch 的。仅针对我们可控的代码,并且在 try 块中,由于申请大段连续内存的情况下,触发的 OOM,才是可以被 catch 的。当 catch 住 OOM 时,应该主动释放一些可控的内存,做好内存管理,避免在后续的操作中,在其他操作中又触发 OOM,导致崩溃。

集合
1、说说你对Java集合的理解
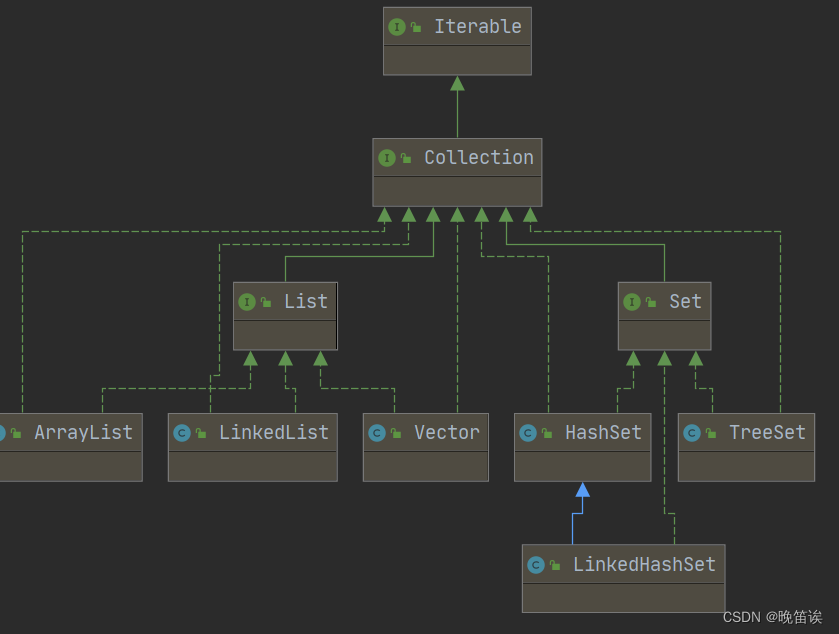

2、ArrayList和LinkedList的区别
底层实现不同,长度一个有限一个理论无限
ArrayList延迟初始化,第一次添加元素时才初始化容量,每次扩容1.5倍
3、它们都线程安全吗?如何得到线程安全的List?
No。
- Vector
- Collections.synchronizedList()方法对非线程安全集合进行装饰
- CopyOnWriteArrayList。读写分离,读取时不加锁,只是写入、删除、修改时加锁。不能保证完全线程安全,适用于读多写少的场景。
4、CopyOnWriteArrayList用过吗?优缺点?
能保证写入线程安全,提高读线程并发量。
缺点:读写线程数据一致性无法保证、写时内存占用问题
5、Set是有序还是无序的?一定无序吗?
Set接口有三个实现类:HashSet(无序)、LinkedHashSet(有 序)、TreeSet(有序)
6、TreeSet的底层实现
红黑树。
7、把你所知道的HashMap的所有知识都说一下?(包括底层实现、扩容机制、1.7与1.8的区别、长度为什么是2的n次幂)
1.7:数组 + 链表,元素大于 容量 * 0.75 时进行扩容
1.8:数组 + 链表 + 红黑树
8、保证线程安全的Map是什么?ConcurrentHashMap聊一下?(和HashMap答题类似,不过重点要回答的是为什么线程安全)
HashTable、ConcurrentHashMap
HashTable 加的锁锁住整张表、ConcurrentHashMap1.8后锁住一个节点再CAS自旋
ConcurrentHashMap:
1.7:分段锁segment
1.8:CAS、synchronized、volatile
9、ConcurrentHashMap每个Node节点中变量使用final和volatile修饰有什么用呢?
final:保证不可修改,读取该变量不用考虑线程安全问题。
volatile:volatile来保证某个变量内存的改变对其他线程即时可见,在配合CAS可以实现不加锁对并发操作的支持。get操作可以无锁是由于Node的元素val和指针next是用volatile修饰的,在多线程环境下线程A修改结点的val或者新增节点的时候是对线程B可见的。
10、ConcurrentHashMap中synchronize和CAS是如何使用的
深入浅出ConcurrentHashMap详解-CSDN博客
CAS:当hash定位的节点为空,则用CAS自旋写入。
synchronize:当hash定位的节点非空,则用synchronize锁住节点进行修改。
至于为什么修改不用CAS,我的理解是由于无法解决ABA问题。
反射
1、反射是什么?举几个例子?
2、通过反射可以拿到类中的变量信息吗?
设计模式(一般与SpringAOP一同问)
多线程
1、线程实现的方式及其优缺点?
线程是调度的基本单位。
2、如何死锁?(考察死锁的条件)
3、如何加锁?(Synchronize关键字和Reentrantlock)
Reentrantlock实现了Lock接口规范:
| 接口 | 作用 |
|---|---|
| void lock() | 获取锁,调用该方法当前线程会获取锁,当锁获得后,该方法返回。 |
| void lockInterruptibly() throws InterruptedException | 可中断的获取锁,和lock()方法不同之处在于该方法会响应中断,即在锁的获取中可以中断当前线程 |
| boolean tryLock() | 尝试非阻塞的获取锁,调用该方法后立即返回。如果能够获取到返回true,否则返回false。 |
| boolean tryLock(long time, TimeUnit unit) throws InterruptedException | 超时获取锁,当前线程在以下三种情况下会被返回: 当前线程在超时时间内获取了锁 当前线程在超时时间内被中断 超时时间结束,返回false。 |
| Condition newCondition() | 获取等待通知组件,该组件和当前的锁绑定,当前线程只有获取了锁,才能调用该组件的await()方法,而调用后,当前线程将释放锁。 |
可重入锁:
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,再进入该线程的内层方法会自动获取锁(前提锁对象得是同一个对象),不会因为之前已经获取过还没释放而阻塞。Java中ReentrantLock和synchronized都是可重入锁,可重入锁的一个优点是可一定程度避免死锁。在实际开发中,可重入锁常常应用于递归操作、调用同一个类中的其他方法、锁嵌套等场景中。
3.1、同步方法块和同步方法的区别?(monitorenter、exit和ACC_SYNCHRONIZED)
同步方法块:monitorenter 和 monitorexit两个指令进行同步
同步方法:ACC_SYNCHRONIZED标志位进行同步
3.2、锁升级过程?
关于 锁的四种状态与锁升级过程 图文详解 - 牧小农 - 博客园 (cnblogs.com)
锁有四种状态:无锁、偏向锁、轻量锁、重量锁。
三种锁的优缺点对比:
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法相比仅存在纳秒级的差距 | 如果线程质检存在锁竞争,会带来额外锁撤销的消耗 | 适用于只有一个线程访问同步块的场景 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度 | 如果始终得不到锁竞争的线程,使用自旋会消耗CPU资源 | 追求响应时间,同步块执行速度非常快 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗CPU资源 | 线程阻塞,响应时间缓慢 | 追求吞吐量,同步块执行速度较长 |
锁升级过程:
- 初次执行到synchronized代码块的时候,锁对象变成偏向锁(通过CAS修改对象头里的锁标志位),字面意思是“偏向于第一个获得它的线程”的锁。
- 轻量级锁是指当锁是偏向锁的时候,却被另外的线程所访问,此时偏向锁就会升级为轻量级锁,其他线程会通过自旋(关于自旋的介绍见文末)的形式尝试获取锁,线程不会阻塞,从而提高性能。
- 轻量级锁在长时间获取不到锁时会忙等,自旋超过10次(可修改)时,升级为重量级锁。
3.3、ReentrantLock优缺点?
3.4、底层实现?(AQS、CAS)
3.5、CAS会存在什么问题?如何避免?
ABA问题。版本号
3.6、公平锁和非公平锁在AQS上是如何实现的?Synchronized是公平锁还是非公平锁?
3.7、synchronized原理
synchronized原理_synchronized可重入锁原理-CSDN博客
原理:JVM提供的监视器monitor,synchronized对代码块加锁需要依靠两个指令 monitorenter 和 monitorexit,对方法加锁依赖方法ACC_SYNCHRONIZED标志区。
synchronized锁升级原理:
JDK1.6之前synchronize是标准的重量级锁(悲观锁),JDK1.6之后进行了大幅度优化,支持锁升级制度缓解加锁和解锁造成的性能浪费,锁的状态总共有四种,无锁、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级到重量级锁,并且锁只能升级不能降级。
4、线程池的理解
4.1、线程池工厂创建的4中方法?
阿里巴巴开发手册上明确写了不要这样做,因为通过这种方式创建的线程池阻塞队列太长,容易造成OOM
- newCachedThreadPool 创建可缓存的线程池
- newFixedThreadPool 创建定长的线程池
- newSingledThreadPool 创建单一线程池执行
- newScheduedThreadPool 创建一个定长的周期执行的线程池
4.2、任务加入的线程池的流程?

4.3、线程池的7个参数?拒绝策略?
// 本质ThreadPoolExecutor()
// 线程池的七大参数
public ThreadPoolExecutor(int corePoolSize, // 核心线程池大小
int maximumPoolSize, // 最大核心线程池大小
long keepAliveTime, // 非核心线程超时了没有被使用就会释放
TimeUnit unit, // 超时单位
BlockingQueue<Runnable> workQueue, // 阻塞队列
ThreadFactory threadFactory, // 线程工程创建线程,一般不用动
RejectedExecutionHandler handler // 拒绝策略
) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
拒绝策略:
new ThreadPoolExecutor.AbortPolicy() // 默认的拒绝策略,不处理,抛出异常
new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略,哪来的去哪里
new ThreadPoolExecutor.DiscardPolicy() // 拒绝策略, 队列满了不会抛出异常
new ThreadPoolExecutor.DiscardOldestPolicy() // 拒绝策略,队列满了,尝试去和最早的竞争,不会抛出异常
4.4、线程池中如何拿到线程的执行结果?
Callable类型的线程。
直接用Future接收线程返回值,或者提交Futuretask类型的线程任务。
// Future
Callable<String> callable = () -> {
Thread.sleep(2000);
return Thread.currentThread().getName();
};
Future<String> future = executor.submit(callable);
System.out.println("-------------task1返回结果 : " + future.get());
//FutureTask
FutureTask<String> futureTask = new FutureTask<String>(callable);
executor.submit(futureTask);
Future<String> future1 = executor.submit(callable);
System.out.println("-------------futureTask返回结果 : " + futureTask.get());
4.6、线程池的大小该如何去设置?
IO密集型:2 * CPU核心数
CPU密集型:CPU核心数 + 1
4.5、核心工作线程是否会被回收?
线程池中有个allowCoreThreadTimeOut字段能够描述是否回收核心工作线程,线程池默认是false表示不回收核心线程,我们可以使用allowCoreThreadTimeOut(true)方法来设置线程池回收核心线程。
4.6、线程池创建参数中keepAliveTime的作用
当线程池中的线程数量⼤于 corePoolSize 的时候,如果这时没有新的任务 提交,核⼼线程外的线程不会⽴即销毁,⽽是会等待,直到等待的时间超过了 keepAliveTime 才会被回收销毁。
非核心线程空闲状态下的存活时间。
5、你对ThreadLocal了解多少?
每个线程维持一份副本。增删查改都是对副本操作。
关键就是Thread里的这俩变量
【高并发】一文带你彻底搞懂ThreadLocal-云社区-华为云 (huaweicloud.com)
/* ThreadLocal values pertaining to this thread. This map is maintained
* by the ThreadLocal class. */
ThreadLocal.ThreadLocalMap threadLocals = null;
/*
* InheritableThreadLocal values pertaining to this thread. This map is
* maintained by the InheritableThreadLocal class.
*/
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
注意:线程池创建的 ThreadLocal要在finally中⼿动remove,不然会有内存泄漏的风险。
6、为什么我们调⽤ start() ⽅法时会执⾏ run() ⽅法,为什么我们不能直接调⽤ run() ⽅法。
new ⼀个 Thread,线程进⼊了新建状态。调⽤ start() ⽅法,会启动⼀个线程并使线程进⼊了就绪状态,当分配到时间⽚后就可以开始运⾏了。 start() 会执⾏线程的相应准备⼯作,然后⾃动 执⾏ run() ⽅法的内容,这是真正的多线程⼯作。 但是,直接执⾏ run() ⽅法,会把 run() ⽅法当成⼀个 main 线程下的普通⽅法去执⾏,并不会在某个线程中执⾏它,所以这并不是多线程⼯作。
7、Semophore介绍一下
synchronized 和 ReentrantLock 都是⼀次只允许⼀个线程访问某个资源, Semaphore (信号量)可以指定多个线程同时访问某个资源。
Semaphore semaphore = new Semaphore(3);
@Override
public void run() {
try {
// 获取许可证,如果没有许可证了,线程会阻塞
semaphore.acquire();
System.out.println("Thread " + id + " is accessing the shared resource.");
Thread.sleep(1000); // 模拟访问共享资源的时间
System.out.println("Thread " + id + " has finished accessing the shared resource.");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
// 释放许可证
semaphore.release();
}
}
8、synchronized 和 ReentrantLock 的区别
相似点:
- 都是互斥锁
不同点:
- 原理上:synchronized 是jdk提供的关键字,加锁解锁由JVM实现,内部使用监视器实现同步;ReentrantLock 是jdk提供的api,内部使用AQS实现,加锁解锁需要自己调用方法,更灵活。
- 公平性:synchronized 是非公平锁;ReentrantLock 可以通过传参创建公平锁。
- 响应中断:synchronized是不可中断类型的锁,除非加锁的代码中出现异常或正常执行完成;ReentrantLock 可以设置超时方法或者将lockInterruptibly()放到代码块中,调用interrupt方法进行中断。
- 多条件唤醒:synchronized不能绑定; ReentrantLock通过绑定Condition结合await()/singal()方法实现线程的精确唤醒,而不是像synchronized通过Object类的wait()/notify()/notifyAll()方法要么随机唤醒一个线程要么唤醒全部线程。
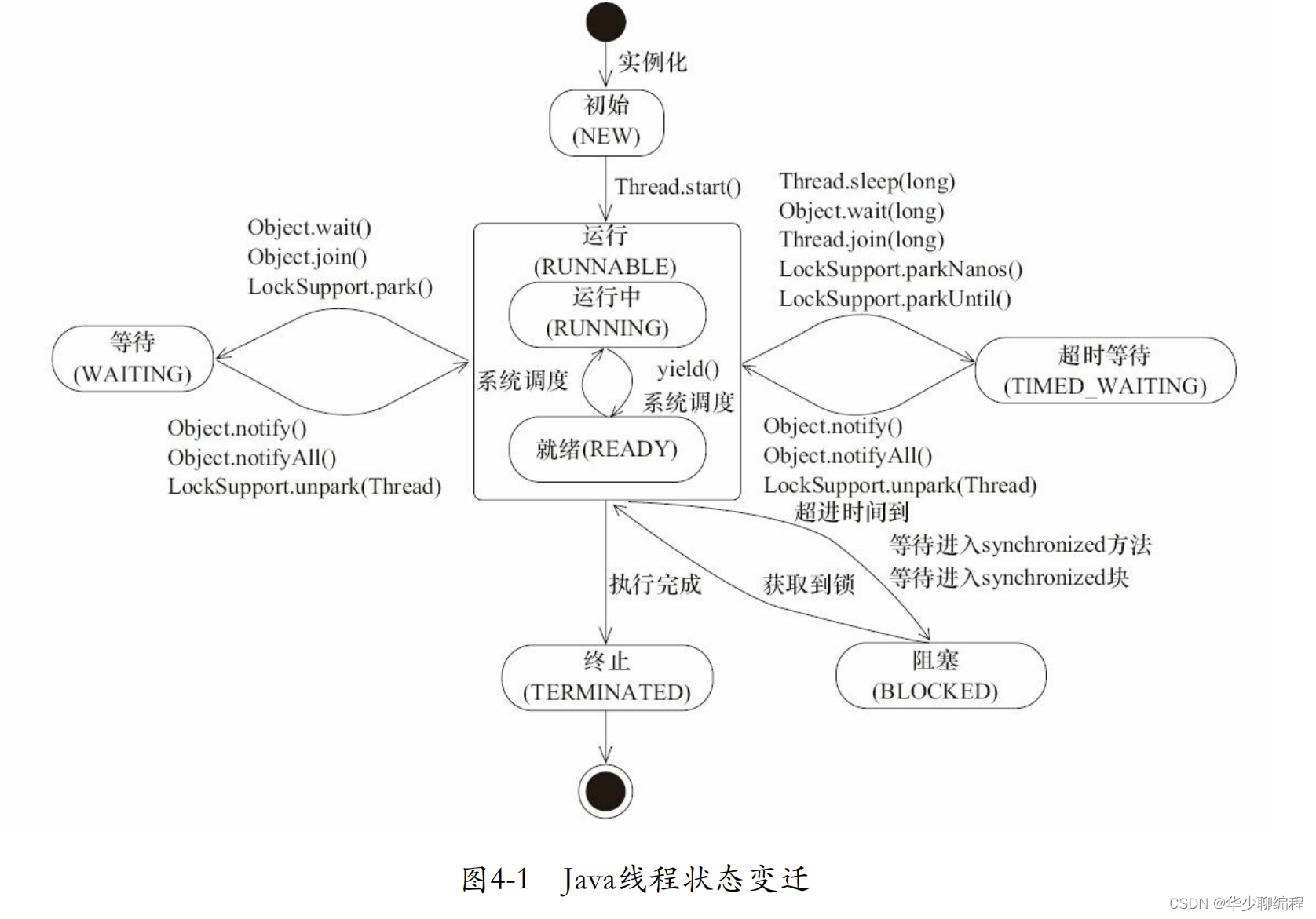
9、线程状态转换
线程状态:
可以使用 jstack 命令查看,上面就有线程的状态。
Java8新特性
1、Java8新特性你都用过哪些?
2、如何使用stream找出某一个字段值最大的数据?
int max = list.stream().max(Comparator.comparingInt(i -> i)).get();
JVM
1、JVM都分为哪些模块?都有什么作用?
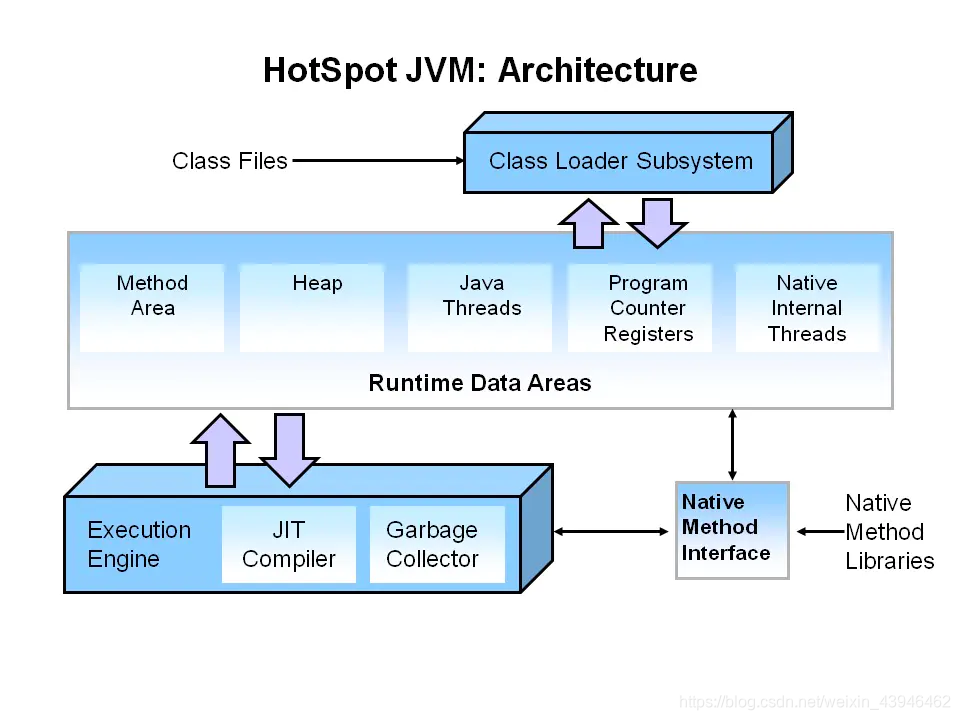
- Class loader(类加载器):根据给定的全限定名类名(如:java.lang.Object)来装载class文件 到运行时数据区中的方法区。
- Execution engine(执行引擎):执行引擎也叫解释器,负责解释命令,交由操作系统执行;JIT编译器。
- Native Interface(本地接口):与native libraries交互,是其它编程语言交互的接口。
- Runtime data area(运行时数据区域):这就是我们常说的JVM的内存,我们所有所写的程序都被加载到这里,之后才开始运行。
2、类的加载过程是什么样的?都涉及到哪些模块?
- 加载
- 将字节码文件加载到内存中
- 链接
- 验证:保证加载的字节码是合法、合理并符合规范的。
- 准备:为类的静态变量分配内存,并将其初始化为默认值。
- 解析:将类、接口、字段和方法的符号引用转为直接引用。
- 初始化
- 将静态变量的赋值和静态方法封装为==()方法==,执行。
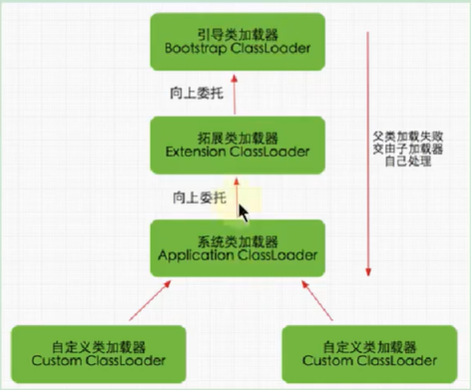
3、双亲委派与沙箱安全机制(这个我没有被问到,但是我在回答过程中有提到,面试官没有顺着我的意思问…)
如果一个类加载器在接到加载类的请求时,它首先不会自己尝试去加载这个类,而是把这个请求任务委托给父类加载器去完成,依次递归,如果父类加载器可以完成类加载任务,就成功返回。只有父类加载器无法完成此加载任务时,才自己去加载。
好处:(安全)
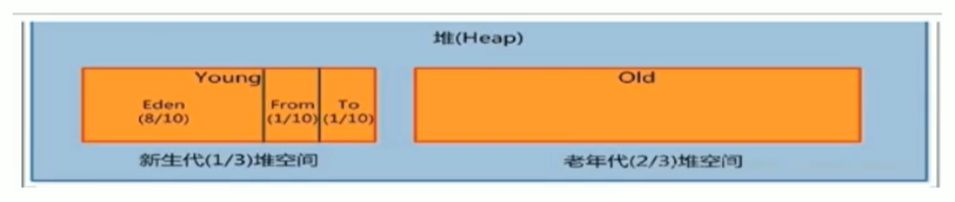
4、详细说一下堆?(此处发现面试官想要问垃圾回收机制,可以有意提到一些自己熟悉的知识点)
所有的对象实例以及数组都应当在运行时分配在堆上。
垃圾回收,分代回收。
新生代、老年代
5、垃圾回收算法(不要遗漏分代回收)
-
标记:引用计数、可达性分析
-
清除:复制算法、标记-清除算法、标记-压缩算法
-
分代:分代收集算法
6、为什么新生代用标记复制?老年代用标记删除、压缩?(考察是否理解缘由,而非死记硬背)
根据新生代和老年代的特点来回答。
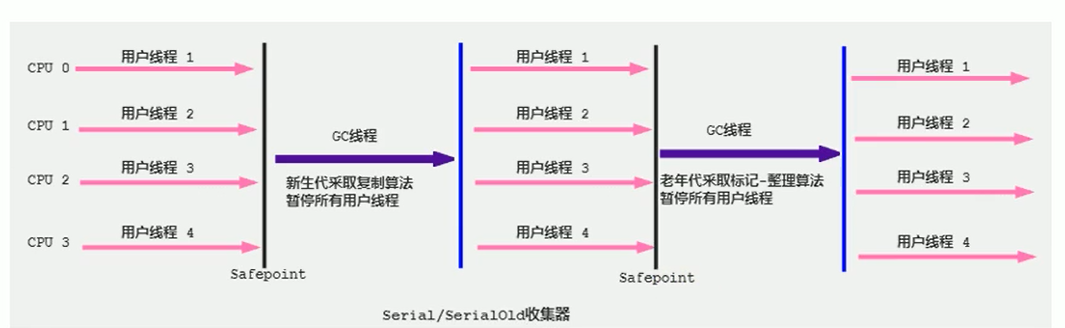
7、垃圾回收器你知道哪些?
-
Serial 收集器(串行收集器):回收时STW,简单高效。一般单核CPU才使用。
-
ParNew 回收器(并行回收):复制算法、STW

-
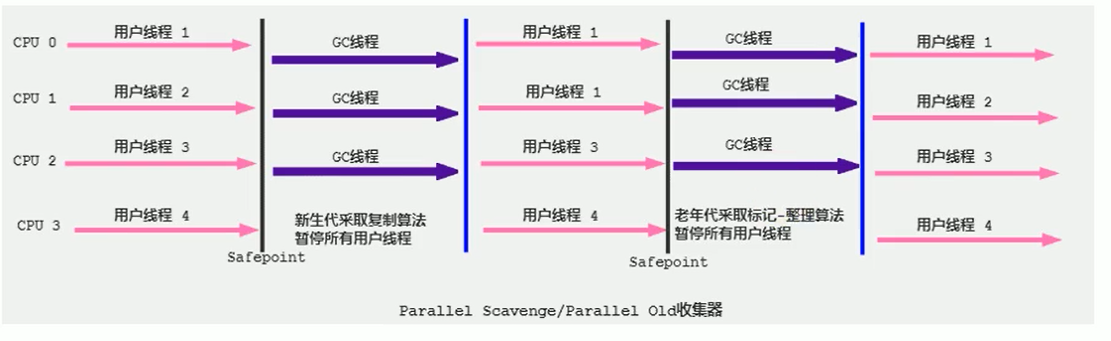
Parallel 回收器:复制算法、并行回收和STW,新生代采用Parallel Scavenge收集器(复制算法)、老年代采用Parallel Old收集器(标记-压缩)
-
CMS:老年代,标记 - 清除
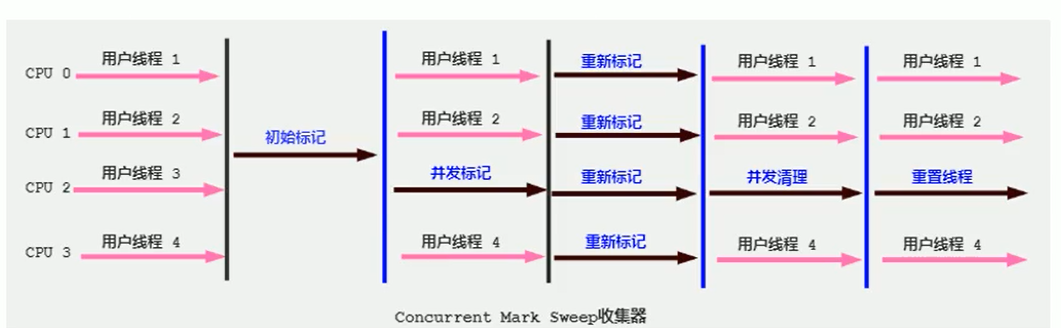
分为四个阶段:初始标记、并发标记、重新标记和并发清除。初始标记和重新标记会STW,不过这两段耗时是最短的。整体上低停顿。
缺点:
- 会产生内存碎片,FullGc时才会整理内存碎片。
- CMS 收集器会消耗CPU,程序吞吐量会下降。
- CMS 收集器无法处理浮动垃圾。在并发标记阶段产生的垃圾只能在下一次CMS或FullGc时才能回收
8、如何进行JVM调优?
内存溢出问题:
-
通过gc日志和程序日志分析,OOM是什么原因引起的。
-
观察参数是否有不合理的地方。
-
调整参数、增大内存再观察。
-
导出内存快照分析是否有内存泄漏问题(要改代码了)。
对于线上应用如果出现OOM,首先观察JVM参数设置是否合理。比如堆内存一般设置为容器内存的80%,要给容器预留一些内存,元空间最好加上限制。然后继续观察GC日志,观察老年代的大小变化。
9、触发Full Gc的情况?
- 调用 System.gc()时,系统建议执行 Full GC,但是不必然执行
- 老年代空间不足
- 方法区空间不足(元空间)
- 通过 Minor GC 后进入老年代的平均大小大于老年代的可用内存
- 由 Eden 区、survivor space0(From Space)区向 survivor space1(To Space)区复制时,对象大小大于 To Space 可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
10、方法区存储什么信息?
存储已被虚拟机加载的类型信息、常量、静态变量、即时编译器编译后的代码缓存等。
框架 SSM
1、Spring的IOC和AOP说说你的理解?
2、AOP实现的两种方式?
3、使用jdk代理和cglib的区别?
4、SpringBean的生命周期
实例化 -> 属性赋值 -> 初始化 -> 销毁
5、默认是单例模式,那原因知道吗?
可以从单例的好处出发回答。
为了提高性能,少创建实例,垃圾回收,缓存快速获取。
缺点:
所有的请求都共享一个bean实例,不能做到线程安全!
6、单例模式是线程安全的吗?如果需要保证线程安全该如何做?
饿汉式:由JVM保证线程安全
懒汉式:双重检测,单例变量用volatile修饰、静态内部类、枚举实现。懒汉式有这三种方式线程安全。
7、Spring如何解决循环依赖?(三级缓存)
spring 循环依赖以及解决方案(吊打面试官)_循环依赖解决方案-CSDN博客
三级缓存。
核心:bean在没有完全完成创建过程时,会在初始化阶段提前把自己暴露到三级缓存中,虽然此时创建流程并未完成,但是其引用不会改变,可以优先满足其他bean对其产生的依赖。
8、Spring中用到了什么设计模式?(接Java基础,单例,工厂,原型,模版 jdbcTemplate,策略<多线程拒绝策略>)
9、SpringBoot的作用是什么?
10、SpringBoot如何做到自动配置?
三个注解:
@SpringBootApplication
@EnableAutoConfiguration
@Import(AutoConfigurationImportSelector.class)
// AutoConfigurationImportSelector 类实现了 ImportSelector接口,也就实现了这个接口中的 selectImports方法,该方法主要用于获取所有符合条件的类的全限定类名,这些类需要被加载到 IoC 容器中。
==核心:==自动读取 META-INF/spring.factories 文件所有配置的类进行注入。
11、@Component、@Service、@Controller有什么区别?如果在Controller上使用@Service会怎么样?
没啥区别。
如果不使用springMVC时,三者使用其实是没有什么差别的,但如果使用了springMVC,@Controller就被赋予了特殊的含义。
spring会遍历上面扫描出来的所有bean,过滤出那些添加了注解@Controller的bean,将Controller中所有添加了注解@RequestMapping的方法解析出来封装成RequestMappingInfo存储到RequestMappingHandlerMapping中的mappingRegistry。后续请求到达时,会从mappingRegistry中查找能够处理该请求的方法。
没用SpringMVC,如果在Controller上使用@Service也是可以的。
12、Restful风格是什么?如何把@RestController换成@Controller会怎么样?
单独使⽤ @Controller 不加 @ResponseBody 的话⼀般使⽤在要返回⼀个视图的情况,这种情况 属于⽐传统的Spring MVC 的应⽤,对应于前后端不分离的情况。
前后端分离项目中:@RestController = @Controller +@ResponseBody
13、Mybatis中#和$的区别是什么?
14、Mybatis中解析sql是在那一层面完成的?
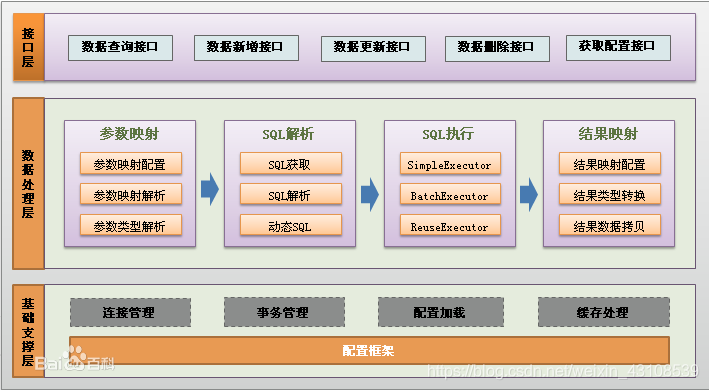
15、分页是怎么实现,除了使用语句的方式?
16、spring事务的实现原理
在使用Spring框架的时候,可以有两种实现方式,一种是编程式事务,另一种是声明式事务。编程式事务需要用户自定义代码来控制事务的处理逻辑,类似于分布式事务中的TCC,声明式事务通过@Transactional注解来实现。
声明式事务@Transactional是AOP的一个核心体现,当一个方法添加@Transactional后,Spring会基于这个类生成一个代理对象,会将这个代理对象作为Bean,当使用这个代理对象的方法的时候,如果有事务处理,就会先把事务的自动提交给关闭,然后去执行具体的业务逻辑,如果业务逻辑执行没问题,代理逻就会提交,如果出现任何异常就会回滚。当然,用户也可以控制对哪些异常情况进行回滚。
注意事项:
- 不要在接口上声明 @Transactional ,而要在具体类的方法上使用 @Transactional 注解,否则注解可能无效。
- 将 @Transactional 放置在类级的声明中会使得所有方法都有事务。影响性能,推荐加在方法实现上。
- 使用了 @Transactional的方法,对同一个类里面的方法调用, @Transactional无效。比如有一个类Test,它的一个方法A,A再调用Test本类的方法B(不管B是否public还是private),但A没有声明注解事务,而B有。则外部调用A之后,B的事务是不会起作用的。(经常在这里出错)
- 使用了 @Transactional 的方法, 只能是public, @Transactional注解的方法都是被外部其他类调用才有效,故只能是public。道理和上面的有关联。故在 protected、private 或者 package-visible 的方法上使用 @Transactional 注解,它也不会报错,但事务无效。
数据库
1、MyIsam和Innodb的区别?
2、Innodb的事务隔离级别
可重复读
3、如何实现事务?(MVCC)
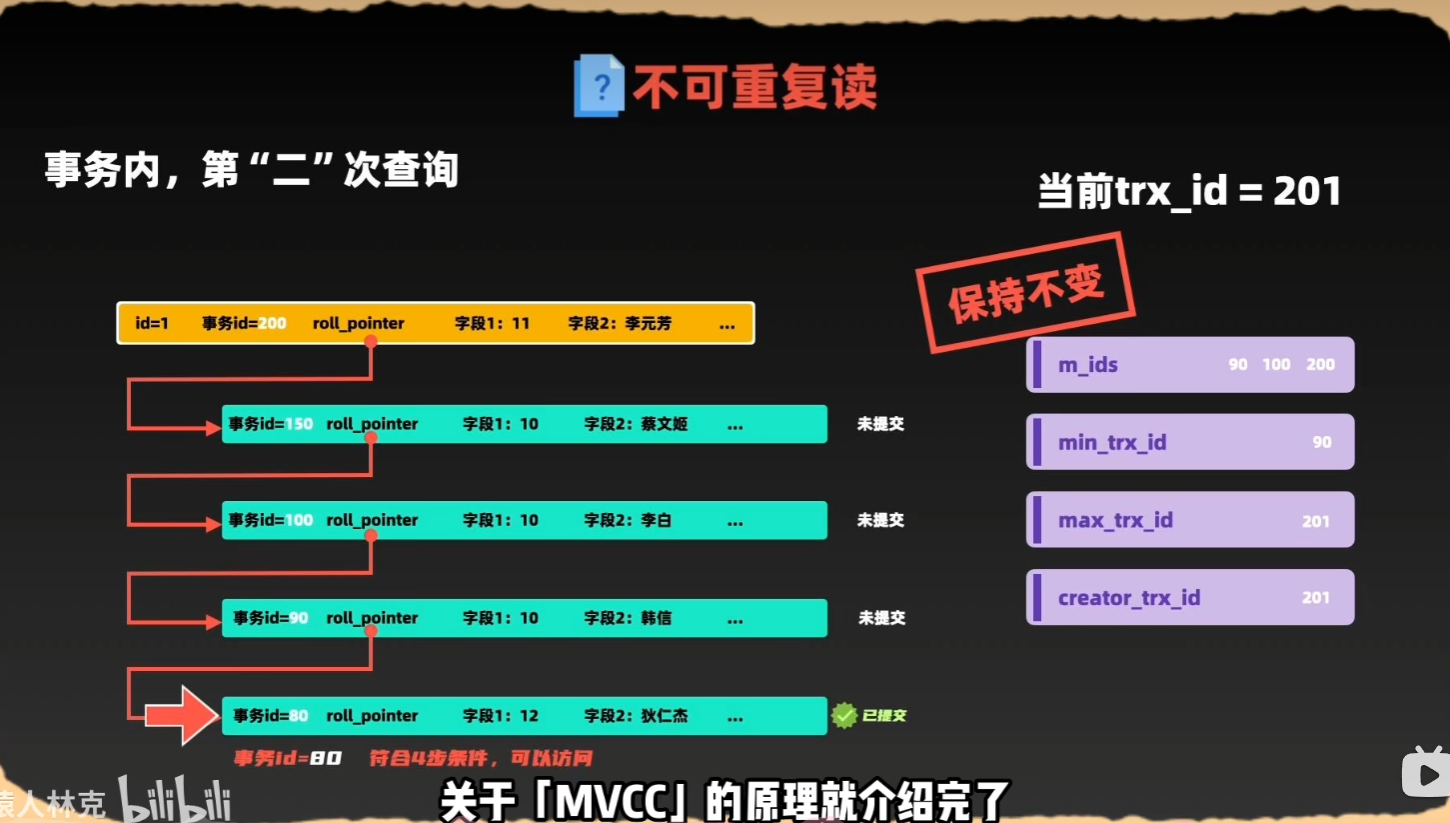
undo_log + read view
4、索引是越多越好吗?为什么?
5、Innodb的索引和MyIsam的索引有什么区别?
6、索引是如何实现的?
7、为什么不用BTree而用B+Tree?
8、那使用索引中,索引失效、索引覆盖都是什么意思?
索引失效:(无法依据索引使用二分查找)
- 在索引列上进行运算操作,索引将失效。
- 字符串类型字段使用时,不加引号,索引将失效。
- 头部模糊匹配,索引失效。
- 用 or 分割开的条件,如果 or 其中一个条件的列没有索引,那么涉及的索引都不会被用到。
- MySQL 评估使用索引比全表更慢,则不使用索引。
9、联合索引该如何使用?ABC的联合索引,查询BC会走索引吗?
10、Mysql查询时如何根据索引查找?(考察页、槽)
按页读取,进行查询,再读入另一页
11、执行计划有用过吗?其中哪些字段需要注意?
12、优化sql的流程
- 观察联表数量是否太多。太多可以考虑数据冗余或者拆分为多次查询。
- 分析是否用到索引。查看其执行计划。
- 减少查询的字段
13、刚才提到创建索引,你是如何考虑索引的创建的?
查询、GROUP BY 、ORDER BY
14、分库分表你们项目中有涉及到吗?
有的。shardingJDBC
15、分表如何判断所需要查询的数据在哪一张表中?
通过分库路由和分表路由决定
16、项目中有跨表执行数据操作吗?具体怎么做的?
没有。单表查的。没有创建绑定表,不涉及联表查询。
如果要跨表查,可以通过绑定表减少联表的组合数量。
17、优化limit
当limit偏移量非常大时,会很慢。慢的原因:在系统中需要进行分页操作的时候,我们通常会使用LIMIT加上偏移量 的办法实现,同时加上合适的ORDER BY子句。如果有对应的索引,通 常效率会不错,否则,MySQL需要做大量的文件排序操作。
# 方案一 :返回上次查询的最大记录(偏移量)
SELECT id, name FROM employee WHERE id > 10000 LIMIT 10;
# 方案二:orderby + 索引
SELECT id, name FROM employee ORDER BY id LIMIT 10000, 10;
# 方案三:在业务允许的情况下限制页数,太靠后的页不查了,因为绝大多数用户都不会往后翻太多页。
# 方案四:延迟联接,通过覆盖索引优化查询
# 比如:
SELECT * FROM student WHERE age > 10 LIMIT 10000,10;
# 此时会把所有满足数据加载进内存,然后抛弃前面10000条。
# 延迟联接优化,此时子查询会走覆盖索引查询需要记录id,再通过id集合查询需要的数据
SELECT * FROM student INNER JOIN
(SELECT id FROM student WHERE age > 10 LIMIT 10000,10) AS s;
Redis
1、项目主要用Redis做什么?
2、项目中用到最多的数据类型?
3、在使用hash的时候,对于大Key值是如何操作的?
4、如果我要删除一个hash的value,但是其中的键值对很多,如何删除?
5、那如果值删除一部分,而不是全部删除,怎么做?
6、redis缓存机制你了解吗?
7、RDB和AOF你们公司如何使用的?二者都用吗还是选择其一?
8、缓存雪崩、缓存击穿和缓存穿透你知道吗?都是什么意思?
缓存雪崩:
现象:缓存在同⼀时间⼤⾯积的失效,或者redis服务宕机,后⾯的请求都直接落到了数据库上,造成数据库短时间内承受⼤量请求。
解决办法:
- 采⽤ Redis 集群,避免单机出现问题整个缓存服务都没办法使⽤。
- 限流,避免同时处理⼤量的请求。
缓存穿透:
现象:缓存穿透说简单点就是⼤量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这⼀层。举个例⼦:某个⿊客故意制造我们缓存中不存在的 key 发起⼤量请求,导 致⼤量请求落到数据库。
解决办法:
-
做好参数校验。
-
布隆过滤器。(维持一个请求参数的Map)

9、刚刚提到布隆过滤器,你知道布隆过滤器是如何实现的吗?
10、布隆过滤器的结果一定是准确无误的吗?
11、还有其他方式防止缓存穿透吗?二者区别?
12、缓存雪崩如何解决,或者避免?
13、Redis的过期策略都有哪些?
14、你们有用过集群,主从吗?
15、哨兵模式是什么,具体说说?
16、那如果哨兵挂了怎么办?
17、使用集群或者主从是如何保证数据一致性的?
18、缓存一致性问题如何解决?
延迟双删:先删缓存、更新数据库,延迟T时间后再删缓存。
不能完全解决。真要一致性,就别查缓存,直接从数据库查。
19、redis的优缺点
优点:基于内存,操作非常快,而且提供了丰富的数据结构,能帮助我们解决不同的问题。
缺点:水能载舟亦能覆舟。基于内存,意味着断电数据就没了,需要一定的持久化策略或者集群部署。另一方面redis单机的性能瓶颈受限于内存大小。
分布式
1、你怎么理解分布式和微服务?
2、你们用的是SpringCloud是吧,那介绍一下SpringCloud都有哪些组件?
注册中心、Feign、熔断、网关
3、熔断是怎么做的?
4、dubbo有用过吗?(自己没用过,老实说没用过就好)
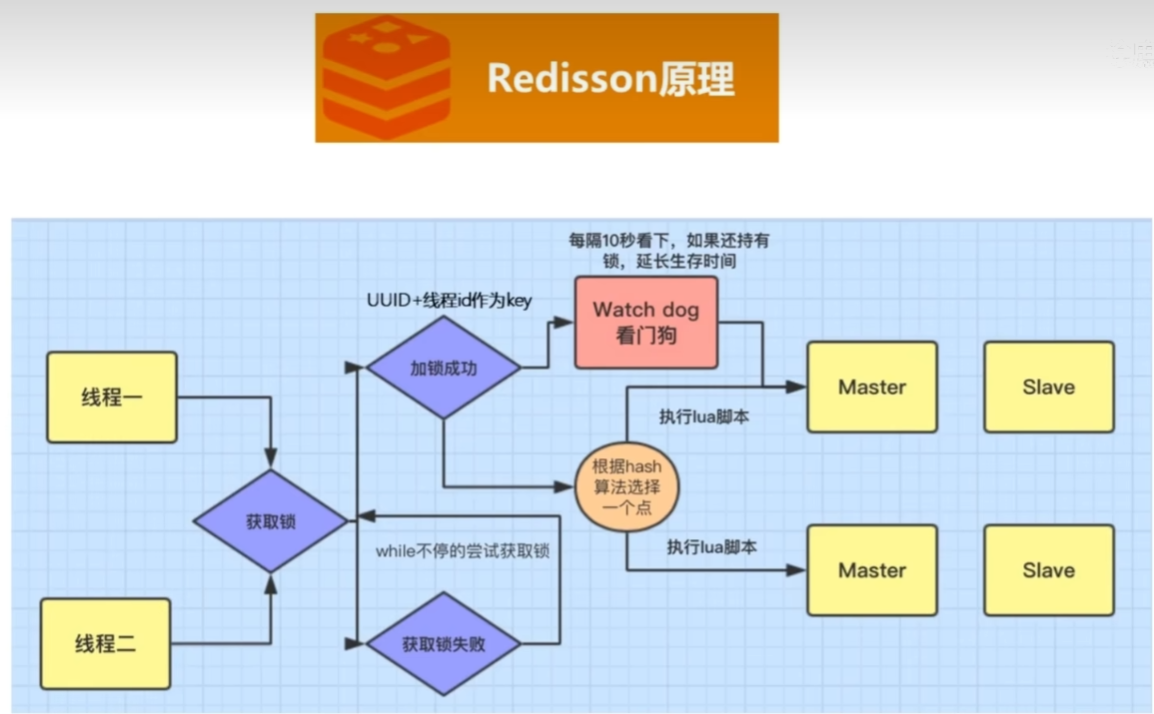
5、分布式中的锁你知道怎么实现吗?
6、用Redis实现需要注意什么?(这里较深,需要注意的地方也多,各种原子性,过期时间延长等等)
7、分布式事务是什么?如何实现?
分布式事务有这一篇就够了! - 知乎 (zhihu.com)
2PC:两阶段提交,有两种实现基于数据库 XA 协议和Seata 实现(推荐)。由于 Seata 的 0 侵入性并且解决了传统 2PC 长期锁资源的问题,推荐采用 Seata 实现 2PC。
TCC:分为三个阶段,业务检查、确认提交、业务取消,三个阶段需要用户编程实现。这种方式优势在于,可以让应用自己定义数据操作的粒度,使得降低锁冲突、提高吞吐量成为可能
try:
// 业务检查
confirm:
// 确认提交
cancel:
// 业务取消

8、2PC和TCC可以详细说一下吗?
9、最大努力通知这种实现有了解吗?
10、分布式锁
其他
1、打包时使用package和install的区别?
2、项目启动时如何跳过单元测试?
3、单元测试作用是什么?
4、Nexus你了解吗?
私服。
5、服务部署平时有做吗?
6、Linux使用多吗?
消息队列
1、项目组当中用到消息队列的场景是什么?
2、 那消息丢失和重复你们有遇到过吗?是如何解决的?
3、Kafka消息是全局有序的吗?
不是。
4、Kafka如何保证消息有序消费
分区内消费是有序的。
-
1 个 Topic 只对应⼀个 Partition。
-
(推荐)发送消息的时候指定 key/Partition。
RocketMq顺序消息实现方式:
发送端单线程串行发送,接收端每个消费组单线程串行消费,每个消费组的消息发送到同一个队列中。
5、RocketMQ如何保证消息的可用性/可靠性/不丢失呢?
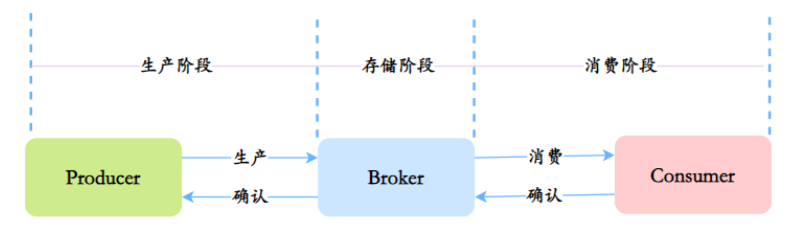
从这三个过程考虑:
生产阶段:
通过请求确认机制,来保证消息的可靠传递。
- 同步发送的时候,要注意处理响应结果和异常。如果返回响应OK,表示消息成功发送到了Broker,如果响应失败,或者发生其它异常,都应该重试。
- 异步发送的时候,应该在回调方法里检查,如果发送失败或者异常,都应该进行重试。
- 如果发生超时的情况,也可以通过查询日志的API,来检查是否在Broker存储成功。
存储阶段:
存储阶段,可以通过配置可靠性优先的 Broker 参数来避免因为宕机丢消息,简单说就是可靠性优先的场景都应该使用同步。
- 消息只要持久化到CommitLog(日志文件)中,即使Broker宕机,未消费的消息也能重新恢复再消费。
- Broker的刷盘机制:同步刷盘和异步刷盘,不管哪种刷盘都可以保证消息一定存储在pagecache中(内存中),但是同步刷盘更可靠,它是Producer发送消息后等数据持久化到磁盘之后再返回响应给Producer。
- Broker通过主从模式来保证高可用,Broker支持Master和Slave同步复制、Master和Slave异步复制模式,生产者的消息都是发送给Master,但是消费既可以从Master消费,也可以从Slave消费。同步复制模式可以保证即使Master宕机,消息肯定在Slave中有备份,保证了消息不会丢失。
消费阶段:
逻辑执行完再发送消费进行确认
- Consumer保证消息成功消费的关键在于确认的时机,不要在收到消息后就立即发送消费确认,而是应该在执行完所有消费业务逻辑之后,再发送消费确认。因为消息队列维护了消费的位置,逻辑执行失败了,没有确认,再去队列拉取消息,就还是之前的一条。
6、如何处理消息重复的问题呢?
处理消息重复问题,主要有业务端自己保证,主要的方式有两种:业务幂等和消息去重。
业务幂等:第一种是保证消费逻辑的幂等性,也就是多次调用和一次调用的效果是一样的。这样一来,不管消息消费多少次,对业务都没有影响。
消息去重:第二种是业务端,对重复的消息就不再消费了。这种方法,需要保证每条消息都有一个唯一的编号,通常是业务相关的,比如订单号,消费的记录需要落库,而且需要保证和消息确认这一步的原子性。可以建立一个消费记录表,拿到这个消息做数据库的insert操作。给这个消息做一个唯一主键(primary key)或者唯一约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。
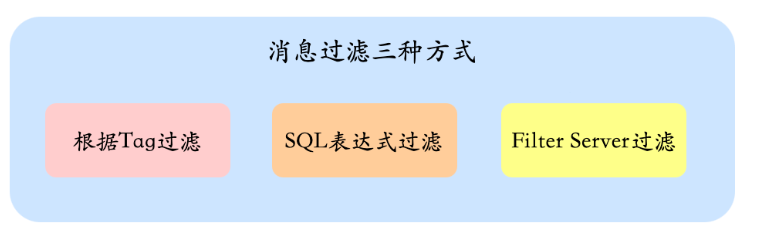
7、如何实现消息过滤?
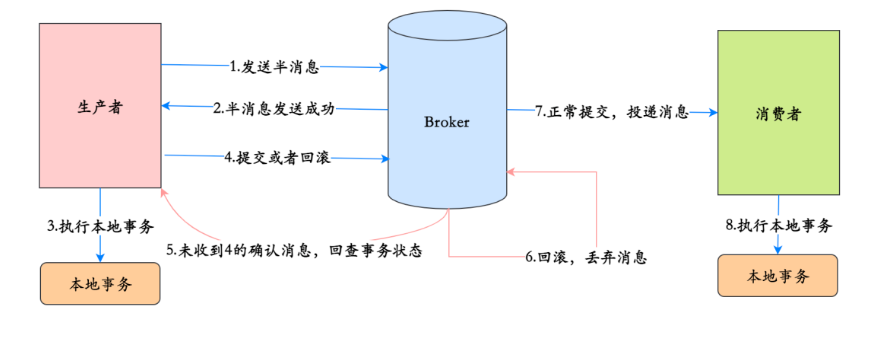
8、事务消息的实现
9、死信队列知道吗?
死信队列用于处理无法被正常消费的消息,即死信消息。
一条消息初次消费失败,消息队列 RocketMQ 会自动进行消息重试;达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息,此时,消息队列 RocketMQ 不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中,该特殊队列称为死信队列。
死信消息的特点:
- 不会再被消费者正常消费。
- 有效期与正常消息相同,均为 3 天,3 天后会被自动删除。因此,需要在死信消息产生后的 3 天内及时处理。
死信队列的特点:
- 一个死信队列对应一个 Group ID, 而不是对应单个消费者实例。
- 如果一个 Group ID 未产生死信消息,消息队列 RocketMQ 不会为其创建相应的死信队列。
- 一个死信队列包含了对应 Group ID 产生的所有死信消息,不论该消息属于哪个 Topic。
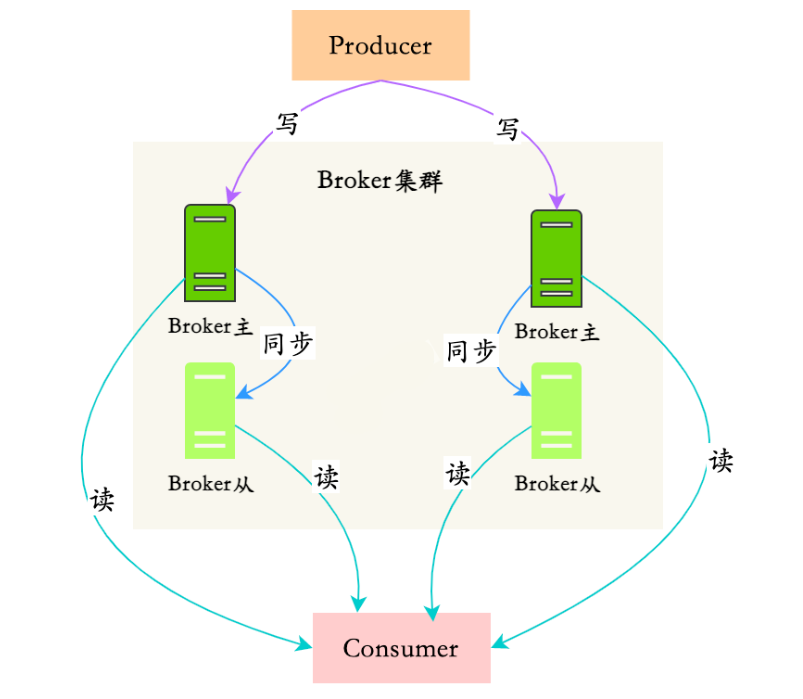
10.如何保证RocketMQ的高可用?
NameServer因为是无状态,且不相互通信的,所以只要集群部署就可以保证高可用。
RocketMQ的高可用主要是在体现在Broker的读和写的高可用,Broker的高可用是通过集群和主从实现的。
11、消息刷盘怎么实现的呢?
RocketMQ提供了两种刷盘策略:同步刷盘和异步刷盘
- 同步刷盘:在消息达到Broker的内存之后,必须刷到commitLog日志文件中才算成功,然后返回Producer数据已经发送成功。
- 异步刷盘:异步刷盘是指消息达到Broker内存后就返回Producer数据已经发送成功,会唤醒一个线程去将数据持久化到CommitLog日志文件中。
计算机网络
1、 TCP粘包和拆包问题有了解吗?
面试题:聊聊TCP的粘包、拆包以及解决方案 - 知乎 (zhihu.com)
TCP是面向字节流的。
由于缓冲区的存在,两个TCP报文被同一个缓冲区接收,就是粘包。一个TCP报文被多个缓冲区接收就是拆包。
对于粘包和拆包问题,常见的解决方案有四种:
- 发送端将每个包都封装成固定的长度,比如100字节大小。如果不足100字节可通过补0或空等进行填充到指定长度;
- 发送端在每个包的末尾使用固定的分隔符,例如\r\n。如果发生拆包需等待多个包发送过来之后再找到其中的\r\n进行合并;例如,FTP协议;
- 将消息分为头部和消息体,头部中保存整个消息的长度,只有读取到足够长度的消息之后才算是读到了一个完整的消息;
- 通过自定义协议进行粘包和拆包的处理。
Netty对粘包和拆包问题的处理:
- LineBasedFrameDecoder:以行为单位进行数据包的解码;
- DelimiterBasedFrameDecoder:以特殊的符号作为分隔来进行数据包的解码;
- FixedLengthFrameDecoder:以固定长度进行数据包的解码;
- LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议(最常用);















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









