




编译器:R-studio|系统:macOS
ps:学习笔记,欢迎评论区交流~
pps:内容真的比较多hhh,建议阅过留痕慢慢看🌝
目录
【最后】局限在哪儿?还有没有可以优化的地方?
【说说】分布,简直是统计人“吸烟刻肺”的东西。
说起可视化的第一步,如果没有系统学习过统计学的人,可能第一时间想到的是柱状图、饼状图、折线图(对,高中内容)我该套哪一个?而学习过统计学的人大概率首先就会想——这堆东西的分布是个啥样?是钟形不?离散程度、集中程度如何?然后再根据数据类型选择对应的图。
我们不希望一个总体太过集中(比如,研究100个身高全是164cm的人),因为这样根本不需要找数据中的规律,换言之信息太少;相反的,我们也不希望一个总体太过分散,以至于毫无规律。
“天才总是少数的。”“大家都是人,怎么差别怎么这么大?”
这些都是集中或者离中趋势的主观感受,平均数、位置平均数、方差、标准差、偏度、峰度虽精准(并且需要计算),但对于我们来说总不太直观。对于总是喜欢偷懒的我们来说(有这么一种说法“懒惰是人类进步的动力。”),看分布图便成了优先的选择。
【分类型数据】柱状图、饼图
对于分类型数据来说,我们希望直观的知道哪一类最多、最多和最少的类差得多不多。这个时候柱状图和饼状图就来发挥作用了,R本身的基础画图包{graphics}自带的函数barplot( )、pie( )就可以帮助我们实现,首先,我们要选择一个合适的数据集(R有哪些自带的数据集参考这篇R语言中自带的一些数据集_疯狂地球人的博客-CSDN博客_r语言自带数据集),紧接着我们可能需要对数据做一些处理(过滤、制作列联表等),而后,我们将从最快(相对粗糙)的过渡到更加个性化(相对精细)的场景。

【柱状图】bar plot
如图1所示,我们选择的是592人头发颜色、眼睛颜色、性别的频数统计,显而易见如果想要但考虑某种因素,需要进行基于分类的合并求和处理。
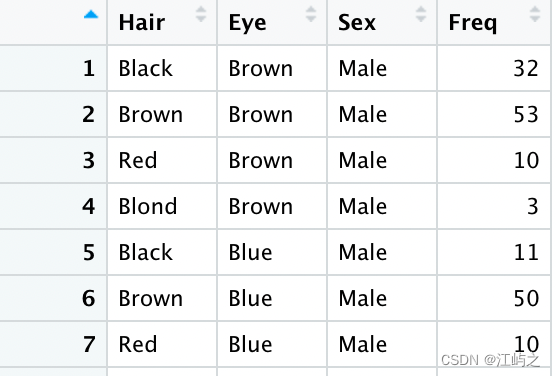
图1-转化为数据框后的数据预览
1、最朴素的柱状图⬇️
#数据获取、处理
hair<-data.frame(HairEyeColor)#592人头发颜色、眼睛颜色和性别的频数
#场景假设:想看592个人头发颜色的分布情况(换言之不考虑眼睛颜色、性别因素)
class_sum=aggregate(hair$Freq,by=list(hair$Hair),sum)#数据处理——分类求和
class_sum #展示结果
#版本一:仅输入数据
barplot(class_sum$x)#最简单的输出
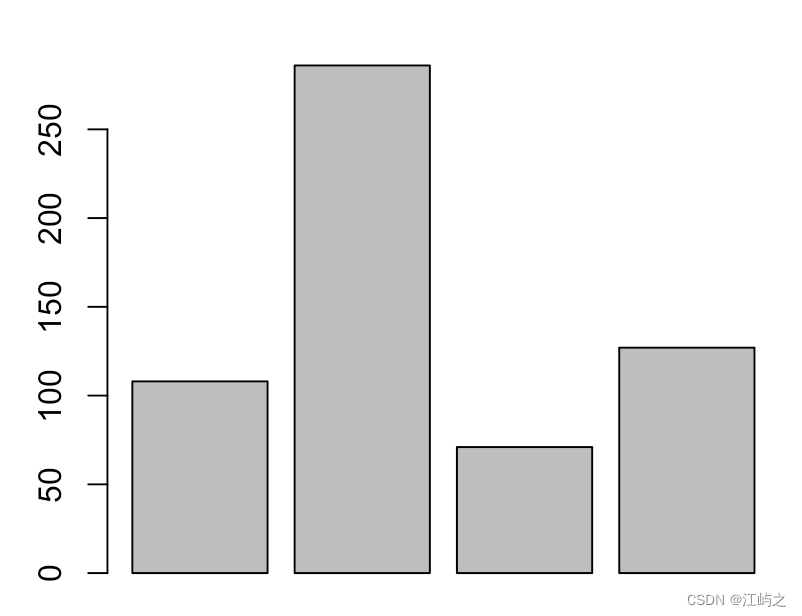
结果1-aggregate函数、barplot函数后的结果
如结果1显示,数据显示头发为棕色的人最多,红色最少,最朴素的柱状图显示出四个高低不同的柱子。虽然它没有标题、柱子颜色等等,但其致命问题在于,没有显示柱子的归属——我怎么知道最高的柱子是哪种发色的人呢??另外,如果每次都需要aggregate(尽管这个函数很好用),是不是有点太麻烦了。于是我们将进行一次全面的优化。
2、个性化的柱状图⬇️
#版本二:颜色、大小图标题、柱子的名字、保存png、循环
#先准备一个取色盘,可diy
cb_palette <- c("#ed1299", "#09f9f5", "#246b93", "#cc8e12", "#d561dd", "#c93f00", "#ddd53e",
"#4aef7b", "#e86502", "#9ed84e", "#39ba30", "#6ad157", "#8249aa", "#99db27", "#e07233", "#ff523f",
"#ce2523", "#f7aa5d", "#cebb10", "#03827f", "#931635", "#373bbf", "#a1ce4c", "#ef3bb6", "#d66551",
"#1a918f", "#ff66fc", "#2927c4", "#7149af" ,"#57e559" ,"#8e3af4" ,"#f9a270" ,"#22547f", "#db5e92",
"#edd05e", "#6f25e8", "#0dbc21", "#280f7a", "#6373ed", "#5b910f" ,"#7b34c1" ,"#0cf29a" ,"#d80fc1",
"#dd27ce", "#07a301", "#167275", "#391c82", "#2baeb5","#925bea", "#63ff4f")
png(filename = "hair_bar1_r.png",width = 1200,height = 400,units = "px",
bg = "transparent",res = 70)#创建画布,因为有三个变量所以要宽点
par(mfrow=c(1,3), #mfrow设置一个一行三列的划分,
oma = c(0, 0, 4, 0))#oma第三个参数为4,意思是在顶部还留出4行字
#利用for循环开始逐一画图
for (i in c(2:length(hair)-1)){#保证序列是从1开始,且不包括最后一行
class_sum=aggregate(hair$Freq,by=list(hair[,i]),sum)#利用aggregate函数得到汇总
class_sum<-class_sum[order(-class_sum[,-1]),]#降序排列
#class_sum<-class_sum[order(class_sum[,-1]),]#升序排列仅仅稍作调整
print(class_sum)#在console里显示出具体汇总数据
#barplot参数设定
barplot(class_sum$x,
names.arg = class_sum$Group.1,#根据第一列的内容显示
ylab = 'numbers of students',#命名y轴
col=cb_palette[1:length(class_sum$Group.1)],#调色盘取对应柱子个数的颜色
main=paste0('group of ',colnames(hair)[i]),#利用字符串黏贴作为主标题
col.main='red',#可以给这个小图的主标题设置颜色
border='transparent',#可以让柱子的边框变为透明
cex.names = 1.5,#横坐标的大小可以调整
cex.axis=1.7,cex.main=2,cex.lab=1.5#依次是坐标轴(数)、主标题(小图)、坐标名
)
}
mtext('Distribution of hair and eye color and sex in 592 statistics students.',
side = 3, line = 0, outer = T,col='purple',cex=2.1)#把大图标题放在顶部,和oma呼应
dev.off()#关闭png画布*关于全局par()参数oma
oma,A vector of the formc(bottom, left, top, right)giving the size of the outer margins in lines of text.
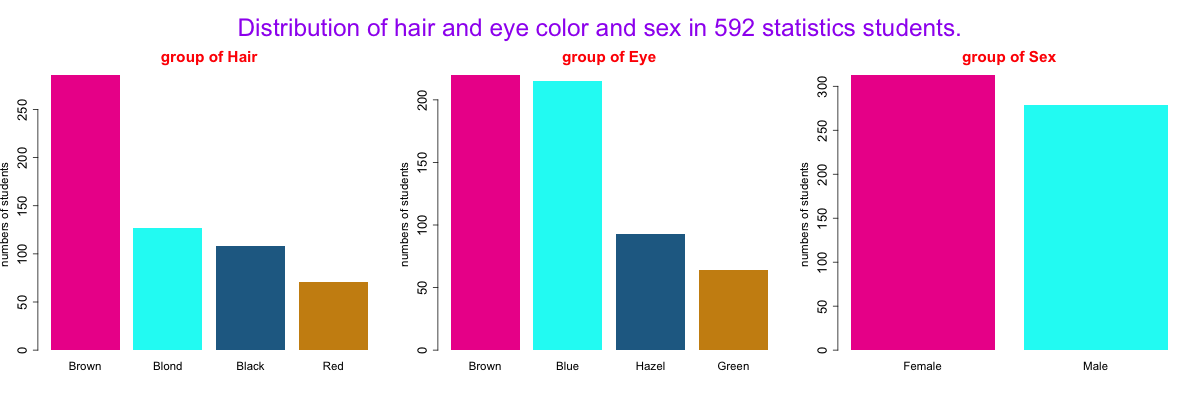 结果2-批量显示不同分类变量的频数统计
结果2-批量显示不同分类变量的频数统计
3、堆叠柱状图、组合柱状图⬇️
让我们考虑一个新场景:我们想进一步知道,男女在不同发色绝对值、比例上是否存在显著差异?这时候我们就需要对柱状图(stackted bar chart)来帮助我们了(通常我们在绝对值、百分比值想同时看),参考以下代码。
#堆叠柱状图,让我们考虑一个新场景:我们想知道,男女在不同发色比例上是否存在显著差异?
#首先已知频数分布表,需要生成新的二维列联表
xtabs(hair$Freq~hair$Hair+hair$Sex,data=hair)#生成列联表函数xtabs展示
x=xtabs(hair$Freq~hair$Hair+hair$Sex,data=hair)#赋值
png(filename = "hair_bar2_r.png",width = 1000,height = 480,units = "px",
bg = "transparent",res = 70)#创建画布
par(mfrow=c(1,2),oma=c(0,0,4,0))#我们画一个绝对值的、一个百分比的
#绝对值的
barplot(x,main="Frequency",
ylab="Frequency",
col=cb_palette[5:9],
legend=rownames(x),#图例的依据
border='transparent',
args.legend = list(x=1.8,y=300),#对于堆叠柱状图来说图例就十分重要了
width=c(0.5,0.5),
space = 1.5,#horiz = TRUE,
#axes = FALSE
cex.names = 1.3
)
#百分比的
x=prop.table(x,margin = 2)*100#先将上面的列联表转化为百分比,margin=2是把一列看作一个分割个体
x#展示百分比
barplot(x,main="Propotion",#重复一遍
ylab="Frequency",
col=cb_palette[5:9],
legend=rownames(x),
border='transparent',
args.legend = list(x=1.8,y=100),#图例的相对位置要调一下~
width=c(0.5,0.5),
space = 1.5,#horiz = TRUE,
#axes = FALSE
cex.names = 1.3
)
mtext('SEX-HAIR COLOR Stacked Bar Chart', side = 3, line = 0, outer = T,col='purple',cex=2.1)#把大图标题放在顶部,和oma呼应
dev.off()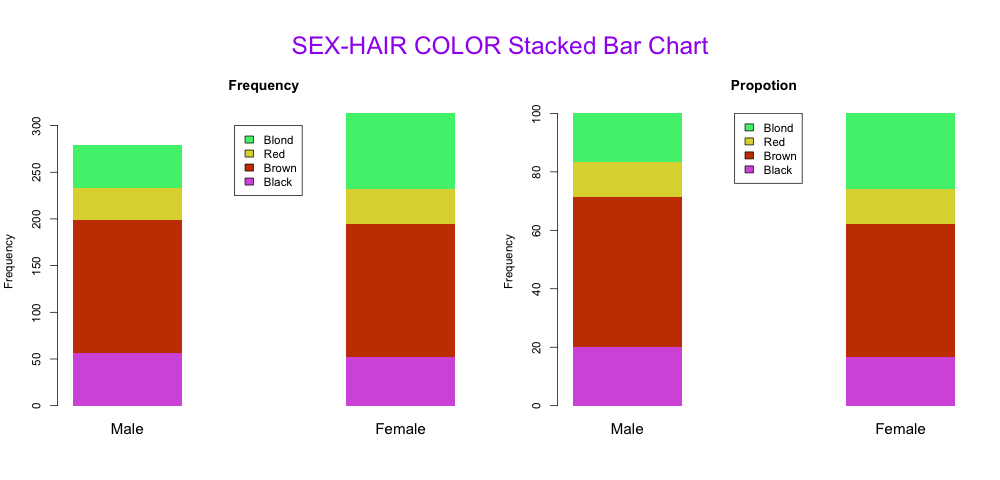 结果3-性别/发色的频率、百分比堆叠柱状图
结果3-性别/发色的频率、百分比堆叠柱状图
上端代码的画图如结果3所示,观察左图我们发现由于女性总数多于男性,所以乍一看金发女性的数量要多于金发男性,黑发则差不多。而右图百分比图则消除了总数的影响,可以看出女性群体中的金发比例确实多于男性,而男性中的黑发占比是高于女性的,图2是数据支持。


图2-xtabs后及转化为百分比后的频数统计结果(堆叠柱状图的依据)
画出堆叠柱状图后,其实组合柱状图很快就出来了,仅仅需要调节“beside”参数为“T”,如果希望把柱状图变成横向的,“horiz”参数调为“T”即可,不过记住调整下坐标轴的名称、图例位置等参数。
#组合柱状图
y=xtabs(hair$Freq~hair$Sex+hair$Hair,data=hair)#性别发色交换了位置
y#展示
#画图开始!
png(filename = "hair_bar3_r.png",width = 1000,height = 1000,units = "px",
bg = "transparent",res = 70)#创建画布
par(mfrow=c(2,1),oma=c(0,0,4,0))#我们画一个竖着的,一个横着的,上下放置
barplot(y,main="vertical",
ylab="Frequency",
beside=T,#这个是从堆叠转化为分组柱状图的关键参数!
col=cb_palette[21:22],
legend=rownames(y),#图例的依据
border='transparent',
args.legend = list(x=12,y=140),#调一下图例位置,是根据坐标轴刻度来的
#horiz = TRUE,
#axes = FALSE,
cex.names = 1.3
)
#画横着的
barplot(y,main="horizontal",
xlab="Frequency",
horiz = TRUE,#变横的关键参数
beside=T,
col=cb_palette[21:22],
legend=rownames(y),#图例的依据
border='transparent',
args.legend = list(x=140,y=13.5,horiz=T),#图例也可以变成横的
#axes = FALSE,
cex.names = 1#注意这个变量名的大小要调小点
)
mtext('HAIR COLOR-SEX Grouped Bar Chart', side = 3, line = 0, outer = T,col='purple',cex=2.1)#把大图标题放在顶部,和oma呼应
dev.off()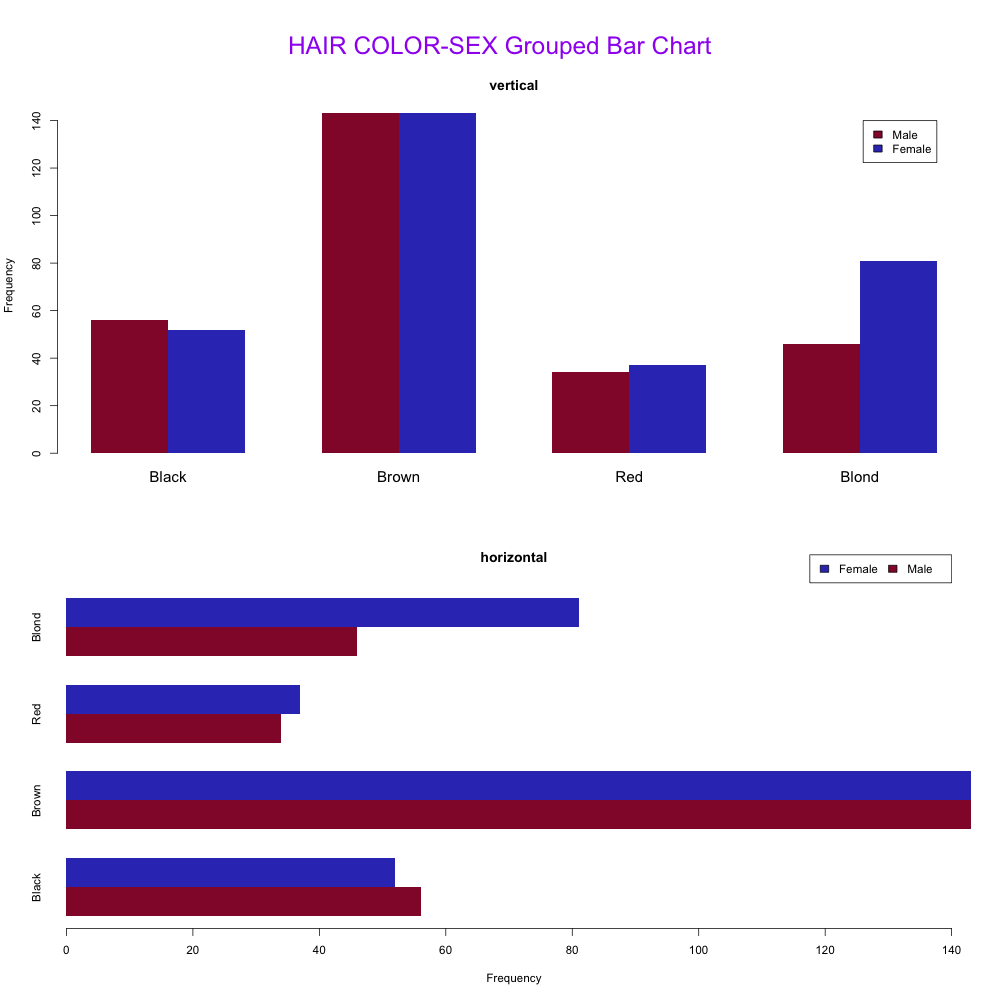
结果4-发色性别的纵型、横形组合柱状图
【饼图】pie chart
相比于柱状图的barplot(),饼图的可调节参数少了很多,比如:因为没有图例参数,所以得单独调用legend函数(先不急,这些等会儿在代码部分会加注释)。我们先换一个数据集、对其做数据处理,并不加个性化调整地得到最朴素的饼图。
#饼图
#数据获取及处理
ad<-as.data.frame(UCBAdmissions)#伯克利分校1973年院系、录取和性别的频数
clu_sum=aggregate(ad$Freq,by=list(ad$Gender),FUN=sum)#性别比例
pie(clu_sum$x)#最朴素的饼图,还是大问题:不知所属、不知所云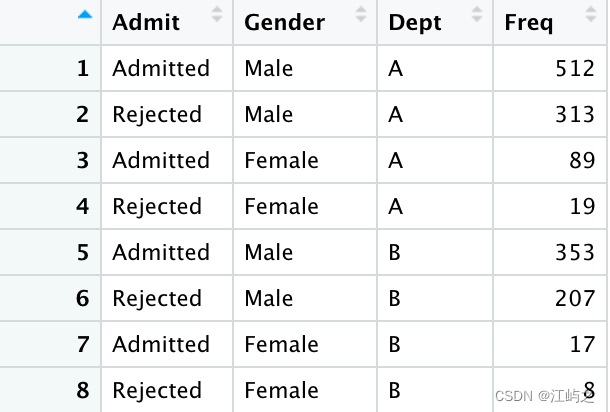
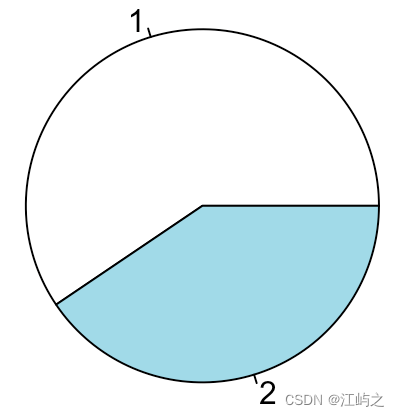
图3-录取情况数据集概览及“最朴素的”性别饼状图
UCBAdmissions数据集和我们在柱状图用的发色数据集相似,最朴素的饼状图非常简陋。迁移柱状图的for循环,我们将其循环过程编辑成一个函数pie.piliang,以至于在画图时可以直接调用。
pie.piliang<-function(dataframe,vars,colorlist){#数据框、变量个数、取色集
for (i in seq(1:vars)){
clu_sum=aggregate(dataframe$Freq,by=list(dataframe[,i]),FUN=sum)#aggregate处理
pie(clu_sum$x,col = colorlist[i:(i+length(clu_sum$Group.1))],
labels = clu_sum$x,#标签显示数
#labels=clu_sum$Group.1,
border='transparent',
radius = 1,#0-1,超过1就溢出屏了
#还有一些参数是旋转角度,比较鸡肋。。自行help
main=paste0('propostion of ',colnames(dataframe)[i])
)
legend("bottomright",#还有topleft、topright
legend=clu_sum$Group.1,
fill=colorlist[i:(i+length(clu_sum$Group.1))]#填充颜色 和pie颜色要一致
)#饼状图加图例需要单独用legend函数
}
}
cb_palette <- c("#ed1299", "#09f9f5", "#246b93", "#cc8e12", "#d561dd", "#c93f00", "#ddd53e",
"#4aef7b", "#e86502", "#9ed84e", "#39ba30", "#6ad157", "#8249aa", "#99db27", "#e07233", "#ff523f",
"#ce2523", "#f7aa5d", "#cebb10", "#03827f", "#931635", "#373bbf", "#a1ce4c", "#ef3bb6", "#d66551",
"#1a918f", "#ff66fc", "#2927c4", "#7149af" ,"#57e559" ,"#8e3af4" ,"#f9a270" ,"#22547f", "#db5e92",
"#edd05e", "#6f25e8", "#0dbc21", "#280f7a", "#6373ed", "#5b910f" ,"#7b34c1" ,"#0cf29a" ,"#d80fc1",
"#dd27ce", "#07a301", "#167275", "#391c82", "#2baeb5","#925bea", "#63ff4f")
png(filename = "ucb_pie1_r.png",width = 1000,height = 1000,units = "px",
bg = "transparent",res = 70)#创建画布,res为分辨率
par(mfrow=c(2,2),oma=c(0,0,3,0))
pie(clu_sum$x)
pie.piliang(ad,3,cb_palette)#调用函数即可
mtext('batches of pie charts',
side = 3, line = 0, outer = T,col='purple',cex=2.1)#把大图标题放在顶部,和oma呼应
dev.off()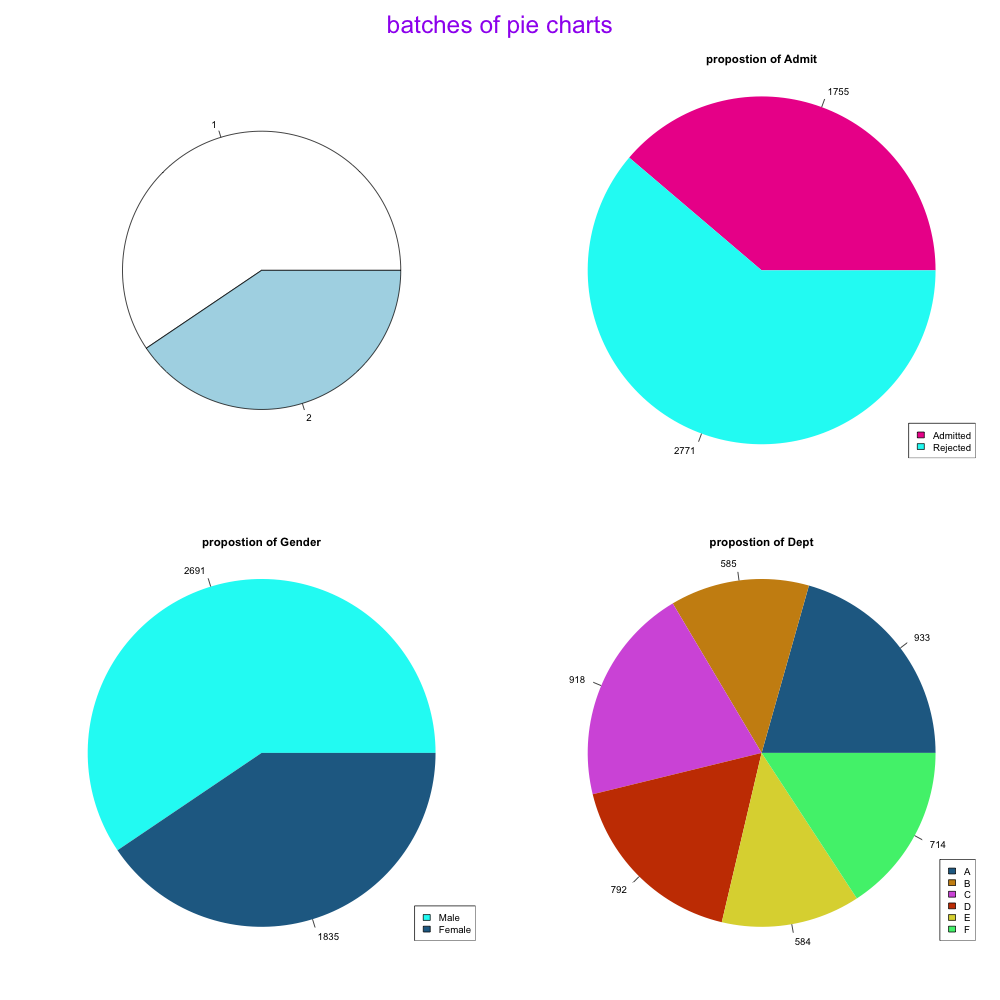
结果5-录取情况的各变量饼图
hair<-as.data.frame(HairEyeColor)#换个数据集
clu_sum=aggregate(hair$Freq,by=list(hair$Hair),FUN=sum)#性别比例
pie(clu_sum$x)#套路,最朴素的饼图
png(filename = "ucb_pie2_r.png",width = 1000,height = 1000,units = "px",
bg = "transparent",res = 70)
par(mfrow=c(2,2),oma=c(0,0,3,0))
pie(clu_sum$x)
pie.piliang(hair,3,cb_palette)#调用函数
mtext('batches of pie charts from 592HAIR',
side = 3, line = 0, outer = T,col='purple',cex=2.1)#把大图标题放在顶部,和oma呼应
dev.off()因为设置了函数,所以换一个数据集便可快速地输出结果(如结果6所示),效率🆙
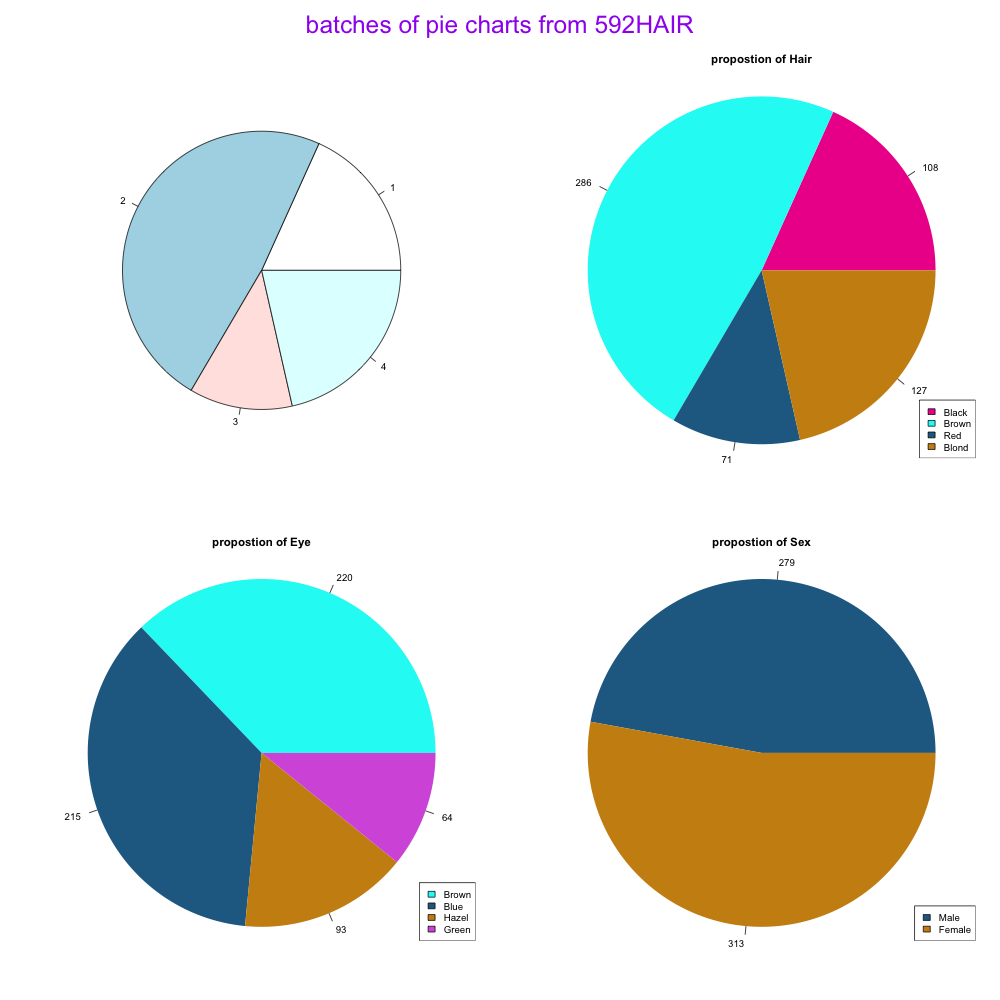
结果6-发色性别颜色的各变量饼图
【数值型数据】直方图、核密度图、箱线图
对于数值型数据我们将介绍:直方图、和密度图以及箱线图,和分类型的分布描述相同的是,直观来说我们也希望得知:哪一个区间范围内的数据“最多”,和分类型数据不同的是,因为“区间”本身可以比较大小,所以就出现了偏态、双峰、厚尾,这样的描述。
【直方图】histogram
我们采用数据框形式的airquality(反映纽约1973年5-9月每日的空气质量),其中风速的单位为mph(mile per hour,英里/小时),如果我们直接用下面那行代码可以得出如图4右边的结果,总共11个bin,效果似乎还不错——因为一定程度上能够反映风速的集中程度。
#直方图
#最朴素的方法
hist(airquality$Wind)#纽约1973年5-9月每日空气质量
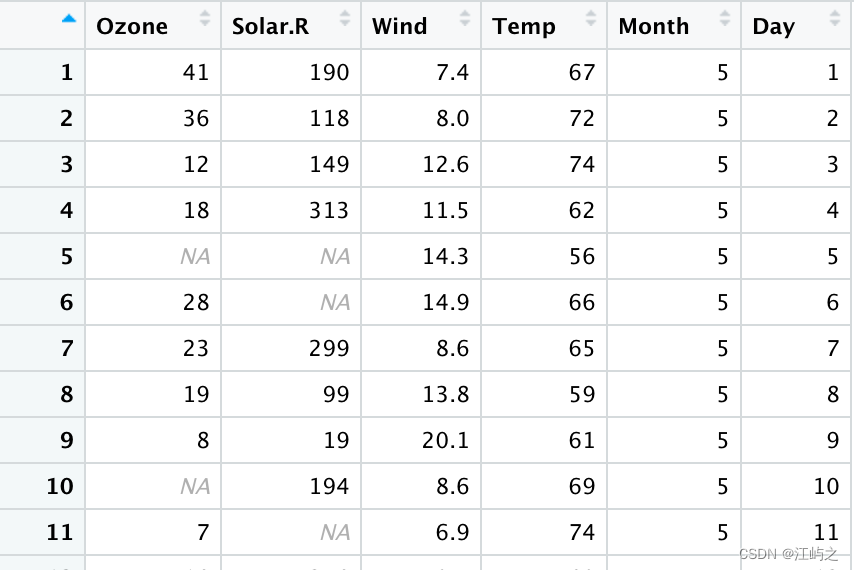
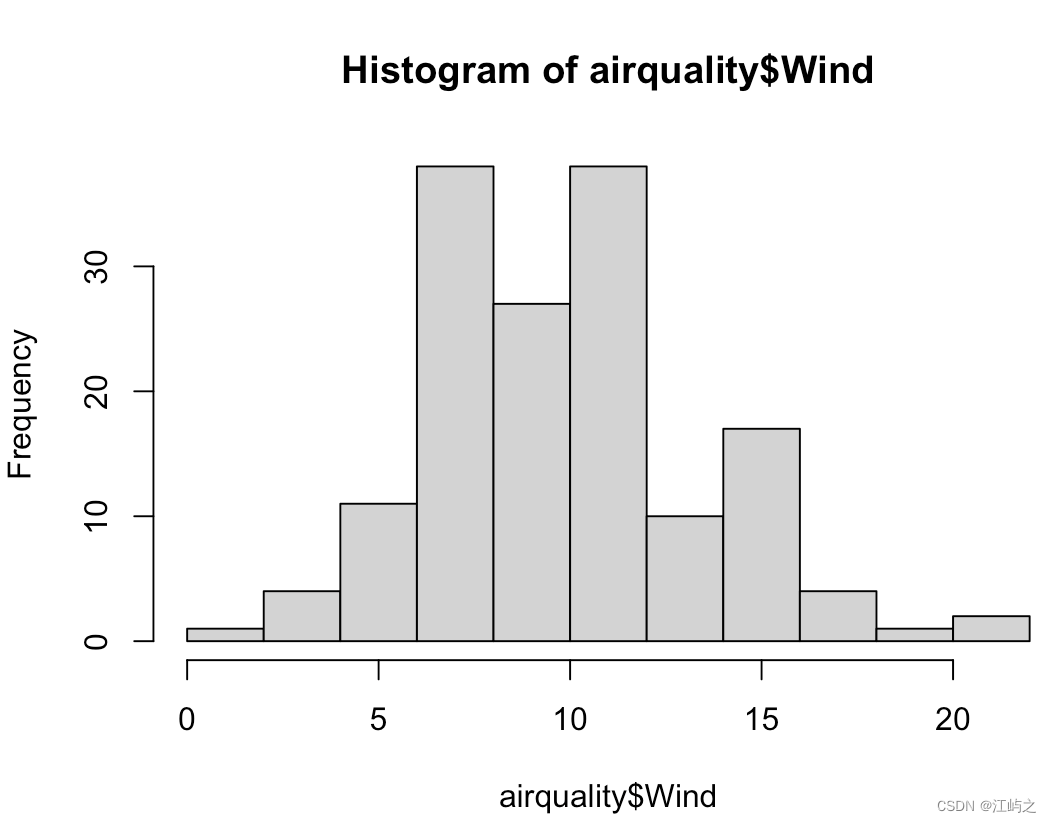
图4-直方图数据概览和朴素直方图
但,如若我们想改变箱子的个数,划分(甚至让他不均等),又或是显示频数(率),当然还包括修改坐标轴、颜色填充、自定义标题...如何实现其精细化呢? 我们接着往下看。
png(filename = "airwind_hist1_r.png",width = 1200,height = 480,units = "px",
bg = "transparent",res = 70)#创建画布,res为分辨率
par(mfrow=c(1,3),oma=c(0,0,4,0))
#hist()自定义标题、箱(break)
r<-range(airquality$Wind)#确定极值
break0=5#直接一个数字,5,默认分为5等份
break1=c(0,10,30)#一个向量,人为设定bin的划分:可(不)均分
break2=seq((r[1]-0.01),(r[2]+1))#利用seq函数by意味着每个bin的宽度,注意,最头尾要小/大于最小/大值
for (i in list(break0,break1,break2)){
hist(airquality$Wind,
breaks <- i,
main = paste0("splited by ",list(i))
)#优化细节-显示break
}
dev.off()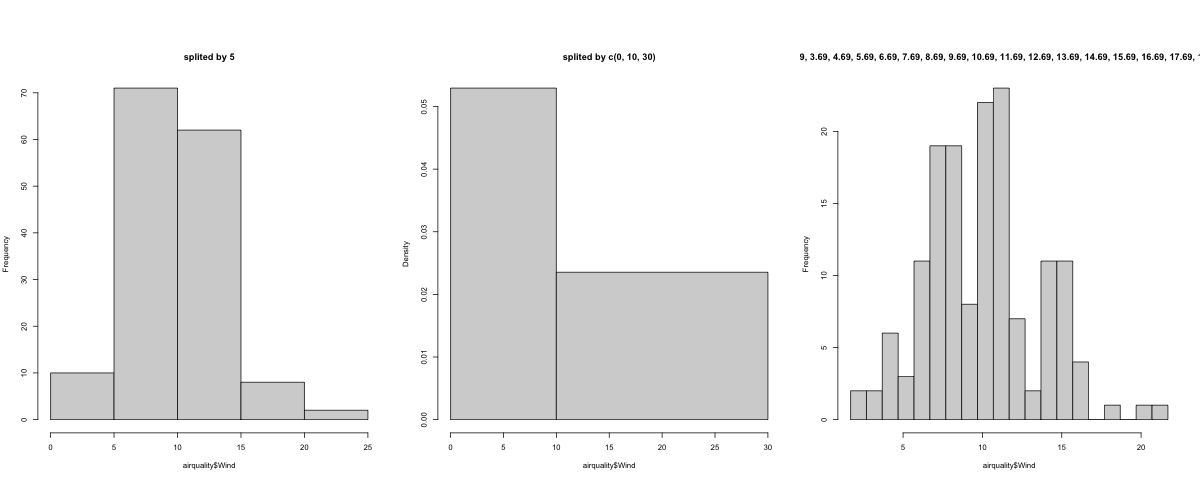
结果7-不同breaks参数设置下的结果
hist()参数中,breaks的设置非常有用,可以通过单独一个数字,一组向量(可以是不等的),一个函数(break2即为seq生成的结果)。但需要注意的是,向量里的元素(数)需要完全覆盖数据的值,所以建议用range函数看一下这组数的极值。
细心的话你会发现,结果7图中,即在不均等分的情况下,纵坐标名自动变成了‘Density’而不是默认的‘frequency’,由于在箱宽(bin)不均等的情况下显示频数无意义(或者说容易引起视觉误差),所以根据直方图的定义,每一个箱子的面积(即密度*宽度)就是数据落在该“箱”里的频率。
#hist()自定义箱(nclass)、显示频数/密度(freq/density)
png(filename = "airwind_hist2_r.png",width = 1000,height = 480,units = "px",
bg = "transparent",res = 70)#创建画布,res为分辨率
par(mfrow=c(1,2))
hist(airquality$Wind,nclass = 3,freq=TRUE,#nclass为更便捷控制箱子个数的调节方式
main='bin=3')#3个箱,频数
hist(airquality$Wind,nclass = 7,freq = FALSE,#不现实频率而显示密度的参数调节
main = 'bin=7')#7个箱,频率
dev.off()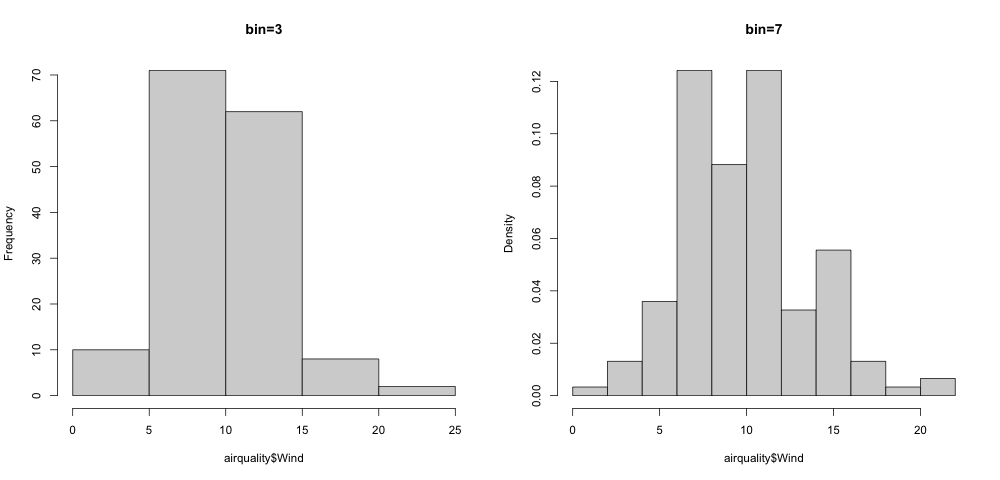
结果8-频率直方图、密度直方图
最后是关于颜色、标签有无的设置,结果如图9
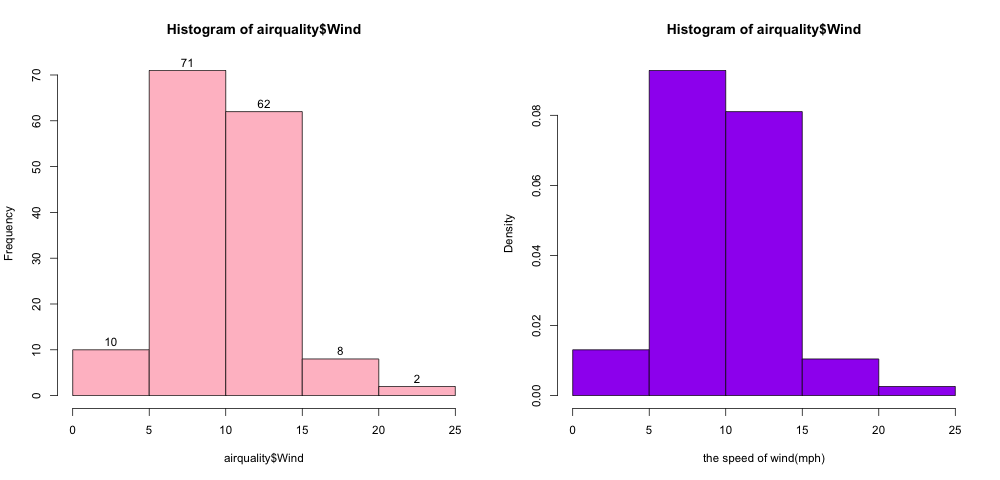
结果9-给直方图加颜色、标签、修改坐标名
【核密度图】kernal density plot
有关核密度估计的数理知识改天我再出一篇,这部分咱们先跳过,总之通过恰当的核函数选择、带宽,我们可以形象地、光滑地(相比于直方图)描绘出一组数值型数据的分布。得到核密度估计和画出曲线其实并不难density、plot两个函数就可以搞定。
#density曲线
d<-density(airquality$Wind)#获取核密度估计
plot(d)#plot画出密度曲线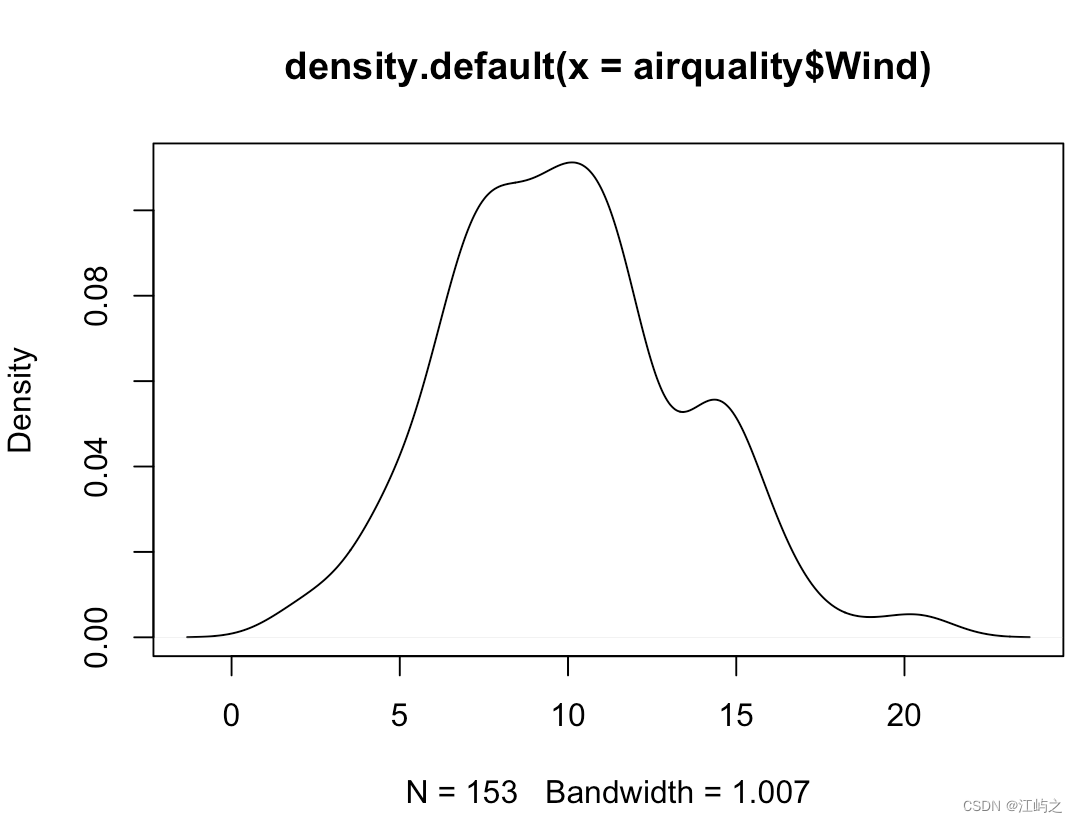
图5-朴素的核密度曲线
如果我们将其和直方图一起看呢?以下操作比较细节,是图片设计、叠加的综合运用。
png(filename = "airwind_hist+d_r.png",width = 600,height = 480,units = "px",
bg = "transparent",res = 70)#创建画布
par(oma=c(0,0,0,3))
hist(airquality$Wind,breaks = seq(0,30,by=5),#bins的设置
border = 'purple',col = rainbow(n=1,start = 8/10,end = 9/10,alpha = 0.3),#玩玩rainbow函数
labels=T,main = 'histogram with kernel density estimatation',
ylim = c(0,100),xlab='the speed of wind(mph)',ylab = 'Days')#显示标签的频数直方图
d<-density(airquality$Wind)
par(new=T)#这样才可以叠加图片
plot(d,xlim=c(0,30),lty=4,lwd=2,col='blue',
main = '',xlab='',ylab='',xaxt='n',yaxt='n')#一些坐标轴、名可以不显示了
axis(side=4)#再把坐标轴安排在右边
legend('topright',legend='kernel density',col='blue',lty = 4)#加图例
mtext('Density',side=4,line=3)#添加那个删掉的“density”
dev.off()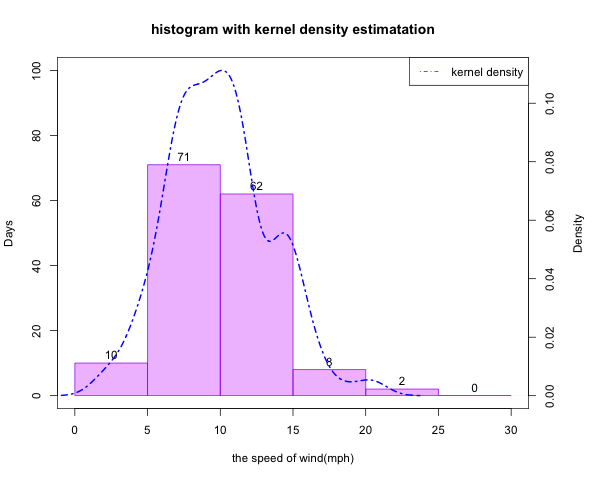
结果10-直方图叠加核密度曲线
本次叠加实现了双坐标轴,所以y轴的范围不需要统一,但x轴的尺度一定要统一!这次设置的都是(0,30)的范围。
【箱线图(盒图)】box plot
最后一个是盒图,也叫箱线图。
我们选择的数据集是LifeCycleSavings,就是#50个国家的存款率
#箱线图
data=LifeCycleSavings #50个国家的存款率
png(filename = "LCS_box1_r.png",width = 1000,height = 480,units = "px",
bg = "transparent",res = 64)#创建画布,res为分辨率
par(mfrow=c(1,length(data)),oma=c(0,0,3,0))
for(i in seq(1:length(data))){
boxplot(data[,i],col=cb_palette[4+i],#调色盘在之前的代码中都有就不贴啦
xlab=variable.names(data[i]),#y是单位需要手动打上去,再利用循环
horizontal = F,cex.axis=2,cex.lab=2,
boxwex = 0.8,
staplewex = 0.5,
outwex = 0.5)
}
mtext('batches of boxplots',side=3,line=0,cex=1.5,col='purple',outer = T)
dev.off()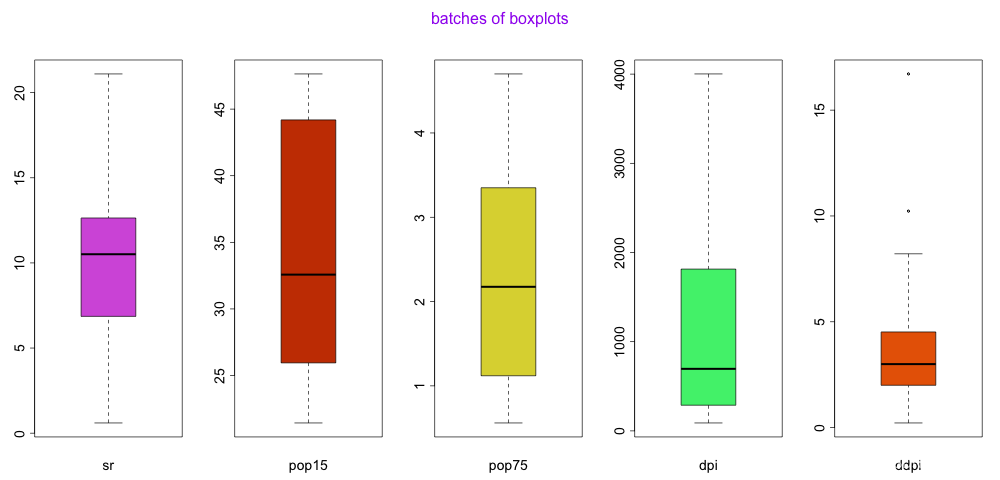
结果11-存款率数据集各变量的盒图
观察结果11,我们发现右二绿色的dpi(人均可支配收入)相比于其他参数、位置参数存在明显的偏态(右偏),何出此结论?我们等会儿会说。其实箱形图在软件实现上很简单,但解读总是一个容易令人混淆的点,哪怕是统计专业的同学也常有不清楚。
以最后结果11的右一为例(因其包含异常值点,也就是outlier)由上至下的上短线、上盒线、粗盒中线、下盒线、下短线分别代表——极大值(不包含异常值点的集合中最大的)、上四分位数()、中位数(median)、下四分位数(
)、极小值(不包含异常值点的集合中最小的)。
一段伪代码——如何得出五个关键指标及盒图?
1、根据样本个数n计算位置平均数——中位数、上下四分位数;
2、根据位置平均数计算两个notches,Box Plot Statistics表示的是
1.58倍的IQR(IQR:上下四分位数之差)还要除以一个(很多网上传传传把这个传漏了!某度百科也是)
;
3、根据notches,在中位数的基础上得到边界boundaries;
4、如果所有数据点中有超出边界的点就判定为outier,也就是异常点,若没有则无异常点;
5、排除异常点之后的新集合(也有可能同原数据集一样)中将最大、最小值的作为极值点;
6、最后将五个数据指标以及异常值点(如有)映射到图片中,结束。


 图7-wikipedia上关于盒图的解释(本来想去查原文但是要💰...)
图7-wikipedia上关于盒图的解释(本来想去查原文但是要💰...)

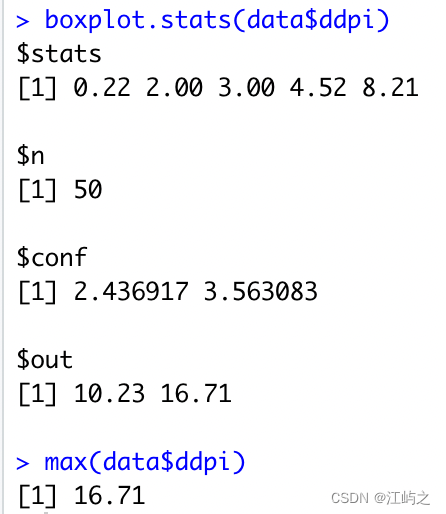
图8-boxplot.stats函数细节以及ddpi的结果
由于抛开了异常值点,所以就会出现boxplot.stats的“最大值”结果(8.21)和max函数结果(16.71)不同的情况。因此,R中boxplot做出的盒图上那两根短线,在没有异常值点的情况下,就是该数据的极值,并不是M1.58倍IQR/
,更不是其他分位数点(90%、75%统统不是)。但是details中也提到了,这个未显示出边界近似于95%的置信区间,推导来源还要参考相关文献。
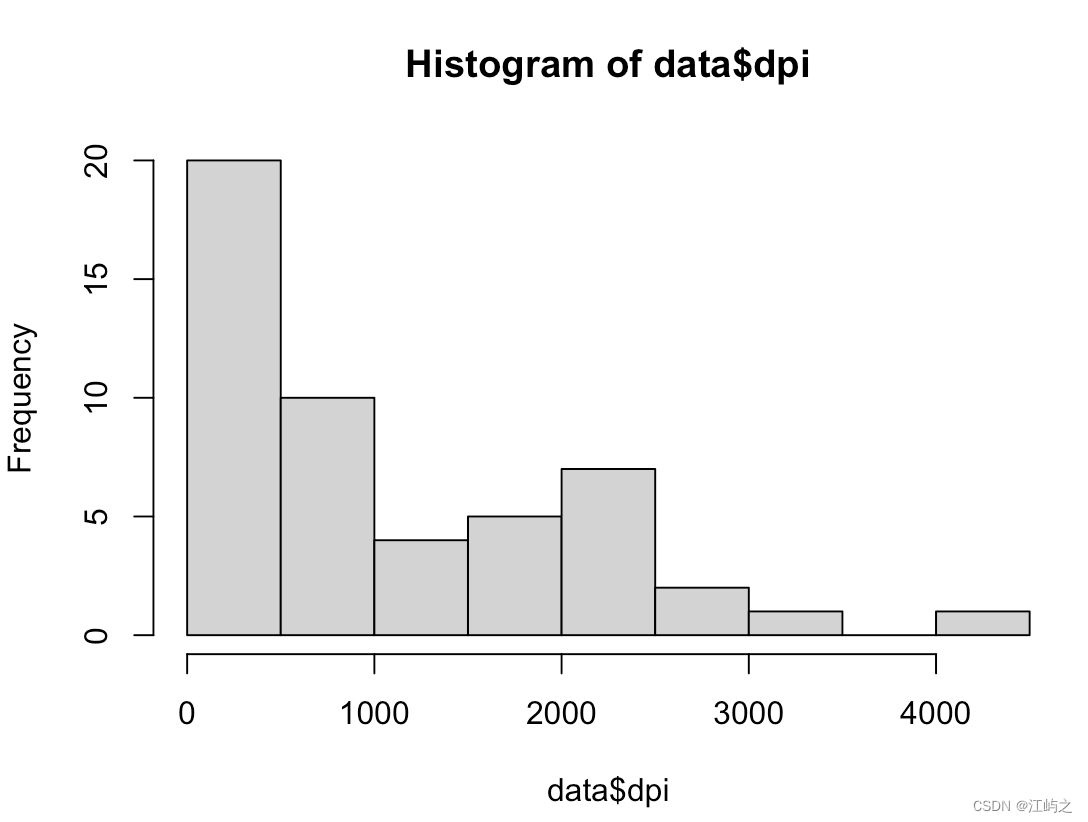
最后,我们回到之前提及的“观察结果11,我们发现右二绿色的dpi(人均可支配收入)相比于其他参数、位置参数存在明显的偏态(右偏),何出此结论?” 因为下盒线到盒中短线的距离要小于,中短线到上盒线的距离,可以这么想,25%的国家集中在如此短小的一块(下四分位数到中位数),越往dpi高的国家看同样25%的国家却跨越了这么宽的距离,说明什么,dpi低的国家密集、dpi高的国家稀疏呀!再简单绘制一个朴素的直方图,20世纪60年代2/5的国家dpi都是低于500(单位不详,应该是美元?)
【最后】局限在哪儿?还有没有可以优化的地方?
综合来看,在对数据探索阶段,R{graphics}的在实现“观察数据分布”的可视化功能还是非常够用的,不用ggplot2也能满足基本的统计、挖掘甚至报告的需求。但是如果想做三维直方图、柱状图、饼图,graphics包是不能满足的,另外无论是柱形图、直方图,在涉及填充的时候似乎只能通过颜色来区分,目前没发现能够改变填充底纹的参数(也可能是我没发现)如果在黑白期刊上,就需要用其他package了。
通过此次的学习梳理,让我收获了不少,逐渐找到了“创造”的感觉(想着能如何优化、做得更好),下一期还是graphics,内容比这个少太多了,主要是散点图~
☝️所以:下期是探究变量间关系!
附录:graphics包的介绍——graphics-package: The R Graphics Package
Information on package ‘graphics’
Description:
Package: graphics
Version: 4.1.1
Priority: base
Title: The R Graphics Package
Author: R Core Team and contributors worldwide
Maintainer: R Core Team <do-use-Contact-address@r-project.org>
Contact: R-help mailing list <r-help@r-project.org>
Description: R functions for base graphics.
Imports: grDevices
License: Part of R 4.1.1
NeedsCompilation: yes
Built: R 4.1.1; aarch64-apple-darwin20; 2021-08-10 22:23:18 UTC; unix
Index:
Axis Generic Function to Add an Axis to a Plot
abline Add Straight Lines to a Plot
arrows Add Arrows to a Plot
assocplot Association Plots
axTicks Compute Axis Tickmark Locations
axis Add an Axis to a Plot
axis.POSIXct Date and Date-time Plotting Functions
barplot Bar Plots
box Draw a Box around a Plot
boxplot Box Plots
boxplot.matrix Draw a Boxplot for each Column (Row) of a
Matrix
bxp Draw Box Plots from Summaries
cdplot Conditional Density Plots
clip Set Clipping Region
contour Display Contours
coplot Conditioning Plots
curve Draw Function Plots
dotchart Cleveland's Dot Plots
filled.contour Level (Contour) Plots
fourfoldplot Fourfold Plots
frame Create / Start a New Plot Frame
graphics-package The R Graphics Package
grconvertX Convert between Graphics Coordinate Systems
grid Add Grid to a Plot
hist Histograms
hist.POSIXt Histogram of a Date or Date-Time Object
identify Identify Points in a Scatter Plot
image Display a Color Image
layout Specifying Complex Plot Arrangements
legend Add Legends to Plots
lines Add Connected Line Segments to a Plot
locator Graphical Input
matplot Plot Columns of Matrices
mosaicplot Mosaic Plots
mtext Write Text into the Margins of a Plot
pairs Scatterplot Matrices
panel.smooth Simple Panel Plot
par Set or Query Graphical Parameters
persp Perspective Plots
pie Pie Charts
plot.data.frame Plot Method for Data Frames
plot.default The Default Scatterplot Function
plot.design Plot Univariate Effects of a Design or Model
plot.factor Plotting Factor Variables
plot.formula Formula Notation for Scatterplots
plot.histogram Plot Histograms
plot.raster Plotting Raster Images
plot.table Plot Methods for 'table' Objects
plot.window Set up World Coordinates for Graphics Window
plot.xy Basic Internal Plot Function
points Add Points to a Plot
polygon Polygon Drawing
polypath Path Drawing
rasterImage Draw One or More Raster Images
rect Draw One or More Rectangles
rug Add a Rug to a Plot
screen Creating and Controlling Multiple Screens on a
Single Device
segments Add Line Segments to a Plot
smoothScatter Scatterplots with Smoothed Densities Color
Representation
spineplot Spine Plots and Spinograms
stars Star (Spider/Radar) Plots and Segment Diagrams
stem Stem-and-Leaf Plots
stripchart 1-D Scatter Plots
strwidth Plotting Dimensions of Character Strings and
Math Expressions
sunflowerplot Produce a Sunflower Scatter Plot
symbols Draw Symbols (Circles, Squares, Stars,
Thermometers, Boxplots)
text Add Text to a Plot
title Plot Annotation
xinch Graphical Units
xspline Draw an X-spline

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









