







 本文介绍了如何在本地使用Maven搭建Spark 2.1.1的开发环境,包括创建Scala Maven项目,导入Spark依赖,编写WordCount,打包与上传jar包。此外,还详细阐述了远程调试步骤,如设置SPARK_SUBMIT_OPTS,IntelliJ IDEA的remote debug配置,以及如何在Linux服务器上执行和调试Spark程序。
本文介绍了如何在本地使用Maven搭建Spark 2.1.1的开发环境,包括创建Scala Maven项目,导入Spark依赖,编写WordCount,打包与上传jar包。此外,还详细阐述了远程调试步骤,如设置SPARK_SUBMIT_OPTS,IntelliJ IDEA的remote debug配置,以及如何在Linux服务器上执行和调试Spark程序。
快速看完《Spark大数据处理 技术、应用与性能优化》前四章后,对Spark有了一个初步的了解,终于踏出了第一步,现在需要在Spark集群中做些测试例子,熟悉一下开发环境和开发的流程。本文主要总结了如何在本地使用Maven搭建开发环境以及如何进行远程debug。由于采用的Spark是今年5月24号才发布的Spark2.1.1,网上大多数例子都是Spark1.X,因此走了不少弯路,才搭建好开发环境。
一:版本概述
Spark版本:2.1.1
IntelliJ IDEA:2017.1.5
开发环境:mac
测试环境:Linux
二:本地开发环境搭建
1、新建一个Maven项目,archetype选择scala
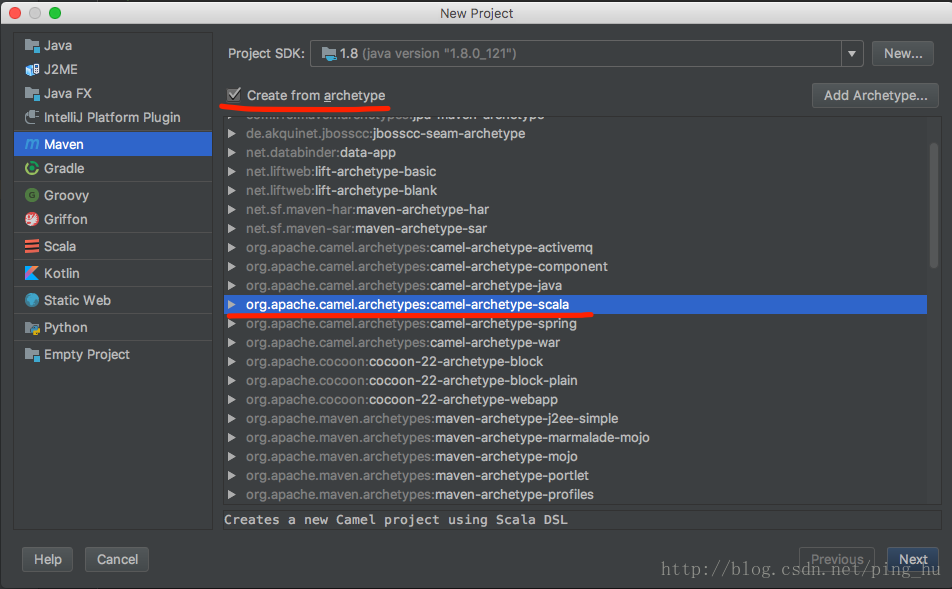
2、导入spark相关包
配置pom.xml,然后Maven自动下载依赖包,Spark2.X已经不提供spark-assembly-1.5.0-hadoop2.4.0.jar 之类的jar包,改成了一些小的jar包,存放在jars目录下。开发的时候可以全部导入jars目录下的jar包,但更方便的是使用maven可以方便的自动导入spark2.1.1开发所需要的包。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









