







spark怎么学习呢?在一无所知的前提下,首先去官网快速了解一下spark是干什么的,官网在此。然后,安装开发环境,从wordcount开始学习。第三,上手以后可以学习其他算法了。最后,不要放弃,继续深入学习。
那么,首先解决的就是如何搭建开发环境的问题。
1、确保你的电脑安装了JDK,以及配置了JAVA_HOME环境变量。
2、安装Intellij IDEA,下载地址。目前15.0版本对Scala的支持性就很好。
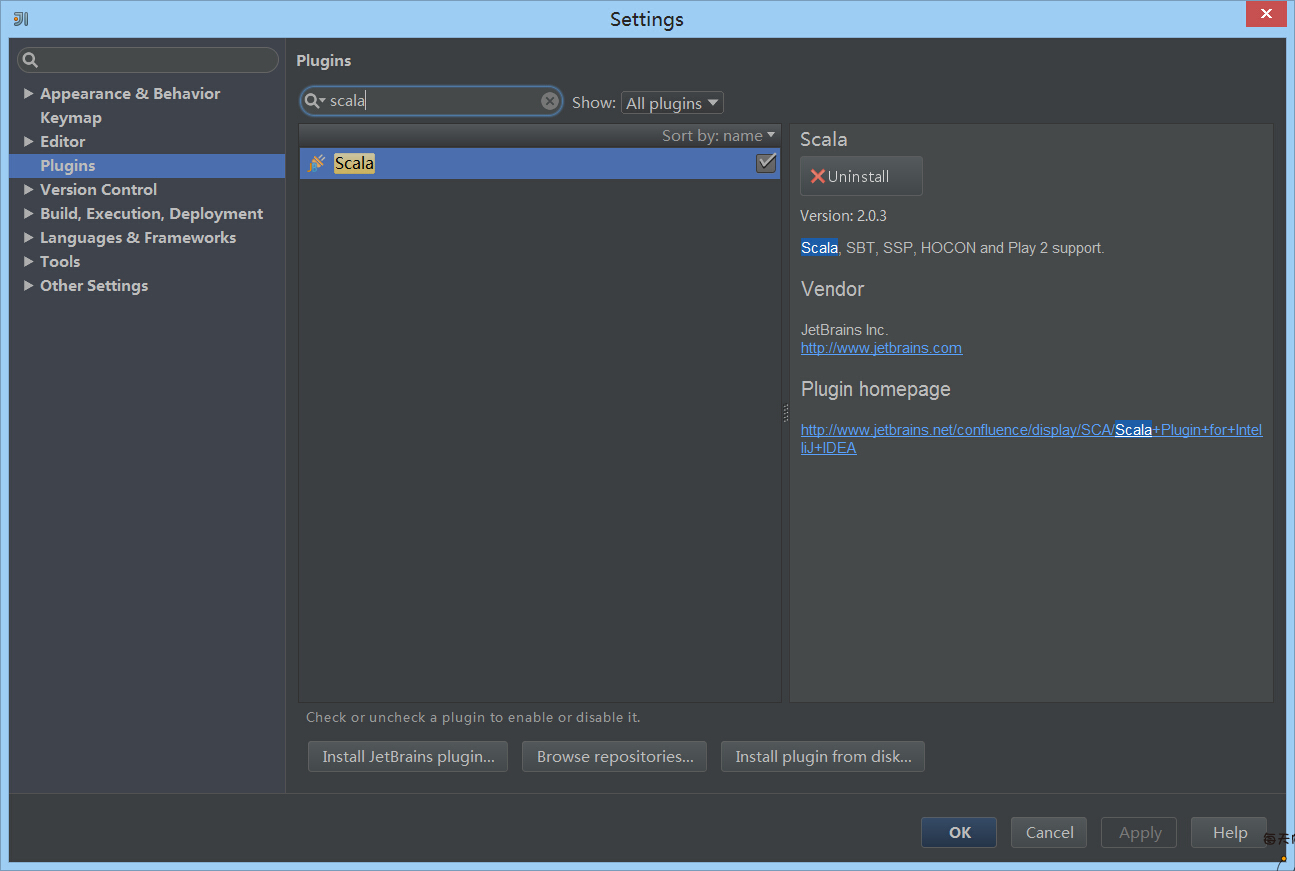
3、安装scala插件。在首次使用Intellij的时候会出现安装插件的提示,如果错过了也没有关系,在setting里,找到Plugins,输入scala,安装即可。
4、搭建spark开发环境。
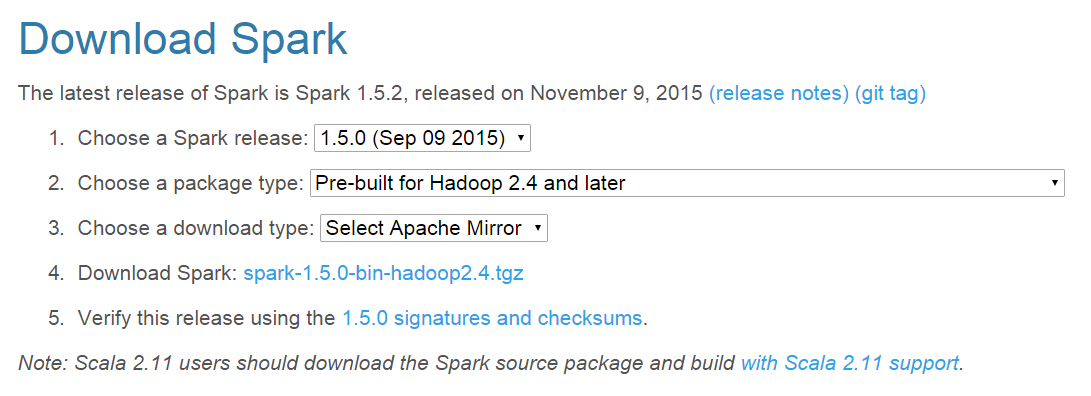
4.1 下载spark的jar包,下载地址。例如我要下载1.5.0版本的spark,hadoop是2.4版本,选项如图:
4.2 解压下载的包,我们需要用的是lib下的spar
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









