







一.自动化构建代码
1.1什么是make/makefile
我们在使用vs的时候可以直接创建.c或者.h文件,想编译直接运行就可以了
编译器把预处理形成可执行程序都做了
但Linux上1到2个文件我们手动编译一下形成可执行程序,在做项目的时候
有100个文件怎么办?文件有更改又怎么办?
这时就可以使用make/makefile
make:是一个命令
makefile:是一个在当前目录下存在的一个具有特定格式的文本文件
1.2make / makefile的使用
touch makefile创建文本文件,也可以首字母大写Makefile
![]()
在进行编译vim makefile
第一行是:
形成可执行程序的名字
![]()
mybin:code.c :冒号后面是可以执行程序从那个源文件来的
第二行是:
要以tab键开头就是按一下tab键
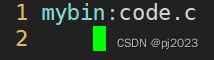
用code.c源代码形成mybin可执行程序
![]()
保存退出![]()
cat Makefile形成文件

![]()
帮我们自动生成mybin文件
./mybin直接运行
![]()

依赖关系+依赖方法=描述清楚一件事情的原因和做法,能够达到我们的目标
1.3make/makefile的清理
vim makefile进行编译
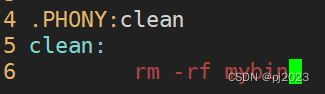
.PHONY:clean依赖关系
clean:伪目标总是被执行,目标文件可以没有依赖关系也可以没有依赖方法
rm -rf mybin:依赖方法删除
直接make clean就可以清除了


没清理之前mybin可执行程序还在

清理之后就mybin就没有了
1.4make/makefile的运行原理
文件编译过程
我们可以把makefile理解为脚本
make是makefile的解释器
我们在生成可执行程序的时候make后面什么都不带
![]()
为什么清理的时候make后面要加clean
![]()
难道是因为代码编写顺序的原因吗?
![]()
![]()
编译器从上往下按顺序编译遇到mybin就会停下来
不会往下继续扫描
自动识别文件的新旧
当我们连续2次make的时候就报错
说mybin文件太新了

我们把test.c文件内容增加一行再make

make
![]()
伪目标
.PHONY可以把clean变成伪目标
为什么要变成伪目标呢?
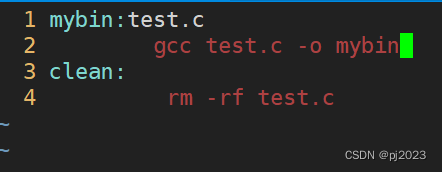
把伪目标去除了会怎么样呢?
![]()
make clean可以正常使用啊
当我连续编译2次就不让我编译了

把源代码更改一下
多添加一行打印

再make一下![]() 让我编译
让我编译
再make一下又不让我编译了
我们可以知道.PHONY可以把一个目标文件修饰成伪目标
形成可执行程序操作在gcc编译时不是每次都能重新编译
我们把mybin也改成伪目标会怎样呢?
.PHONY:clean


可以看到make被伪目标修饰之后总是可以被执行
没改之前为什么不让我重复编译呢?
原因是自己原始的代码并没有做更改,make和Makefile就会识别到
当前文件不需要重新编译的,节省时间降低成本提高编译效率
那makefile怎么知道当前代码是新的还是旧的呢?
原因是文件被修改的时候对应的时间属性会发生变化
时间其实不是本质,通过时间对比新旧才是本质
源文件和谁对比体现新旧呢?
我们形成的可执行程序也是文件
重新编译的本质就是重新写入一个二进制可执行文件
第一次的时候,一定是先有源文件,才有mybin文件
源文件的修改时间<mybin文件的修改时间
第二次的时候,对源文件做任何修改的时候
源文件的修改时间>mybin文件的修改时间
在重新编译的时候,mybin文件的时间就会大于源文件的时间
一直循环下去
大部分情况下都是没问题的,问题的产生不仅仅是修改新文件就能
解决的有些历史问题需要重新清理项目才能解决
1.知道文件的新旧是对比出来的
2.源文件和可执行程序进行对比
二.文件的时间
2.1stat查看文件时间

有属性就有时间
我们知道文件=内容+属性
其中Access是文件最近的访问时间![]()
Modify是文件内容修改时间![]()
Change对文件的属性修改时间![]()
这三个时间是各玩各的还是联动的呢
stat code.c查看文件时间

去掉文件的写权限![]()
![]()
可以发现只有Change的时间发生的改变
vim code.c打开code.c文件增加内容

可以发现Modify和Change的时间同时发生了变化
再来看一下Access
cat test.c查看文件
![]()
查看后的变化
![]()
当我们连续几次查看文件的时候发现Access的时间
并没有发生变化原因是文件被查看的频率是非常高的
更改文件的本质是访问磁盘如果每次更改Access的时间
就会导致Linux系统充满大量的访问磁盘的IO操作,就减慢
系统效率
现在就可以清晰的理解为什么不让我们连续make的原因

test.c的Modify时间
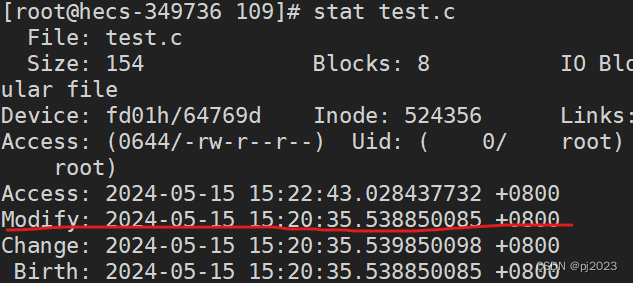
mybin的Modify时间
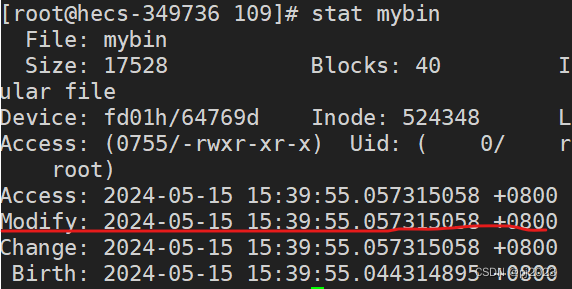
test.c的文件时间相对于mybin的文件时间老
系统就不会去编译老的文件make自然就不能编译了
有人就会问了我把文件的时间更新一下不就可以编译了吗?
这个办法确实可以
2.2touch修改文件时间
引出touch命令![]()
touch -a test.c
更改前的时间

更改后的时间

man手册上说只更改access的时间
我们可以发现Change的时间也更改了
原因是access也是属性
touch -m test.c
![]()
此时test.c文件的时间相对于mybin文件时间新

make一下

不让我们编译的时候就touch
touch -m test.c

2.3.PHONY伪目标
通过时间对比我们可以不让某些代码或者操作重新编译
.PHONY:clean修饰的伪目标可以总是被执行,原因是依
赖方法总是被执行,不受时间的限制不会被任何情况拦截
我们把mybin也带上.PHONY:mybin,他也不会受到时间的
限制


可以一直make下去不受时间的限制
2.3make和Makefile具有依赖性的推导能力
我们知道文件在编译的时候会经历预处理,编译,链接过程
通过Makefile实现代码编译中间的过程
我们知道一个可执行程序需要源文件和test文件链接形成
可执行程序mybin依赖的是test.o文件
将test.c修改为test.o
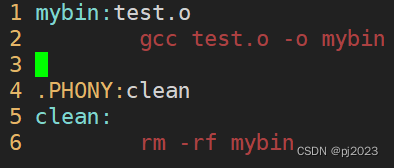
![]()
系统给我们生成了test.o文件,我并没有创建test.o文件
这是Makefile的隐式推导
要形成mybin必须要有test.o文件删掉系统自己创建的test.o文件
自己创建

编译器从上往下扫描第一个遇到的是mybin依赖的文件是
test.o但当前没有test.o文件这个方法就无法运行
编译器就会自动往下扫描test.o是怎么形成的
因为只有test.o文件存在才会形成mybin可以执行
如果后面没有test.o编译器会报错或者隐式形成一个test.o文件
找到test.o后,test.o依赖的是test.s, test.s当前不存在就继续往下执行
找到test.s后,test.s依赖的是test.i, test.i当前不存在就继续往下执行
找到test.i后,test.i依赖的是test.c,test.c存在就会根据gcc方法
![]()
形成test.i,就好比栈结果上面依赖关系一直不存在就入栈
到最后test.i存在后依赖关系成立就会逆向出栈

形成文件的顺序从下往上输出的
输入make的时候会回显要执行的命令
![]()
但有人不想要这种效果就可以用@隐藏掉回显的指令
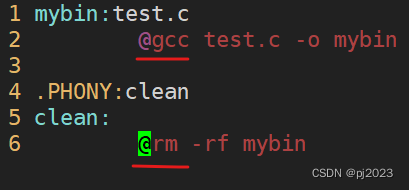

隐藏回显
echo输出的时候用@就很合适
更改前

更改后


变量替换
在makefile中准许编写变量

可以把变量理解为宏
作用是以后不用gcc编写用g++编写的时候
把上面变量的内容修改一下就可以了下面不用修改

依赖关系简写
依赖方法中的test.c和mybin可以简写,因为依赖关系中已经有了

依赖方法就可以简写
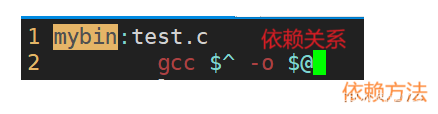
$@代表依赖关系中:左侧要形成的目标文件
$^代表依赖关系中:右侧所有内容
三.用Makefile编写程序
有以下三个版本的进度条:
1.简单原理版本
2.实际工程实践版本
3.C语言扩展
3.1缓冲区
这串代码是先运行printf再运行sleep
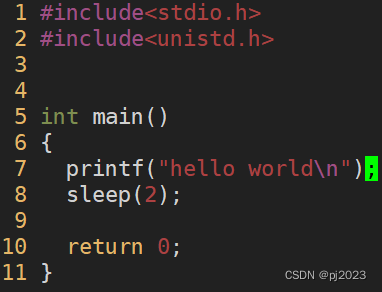
先把hell world再等2秒结束程序
![]()
那我去掉\n是什么效果
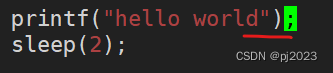
看到的现象是先sleep等2秒再打印
![]()
我们知道c语言中代码默认是从上往下执行的
代码的执行一定是从上往下执行的,看到的现象与实际情况无关
printf实际早就运行了,只是字符串没有被显示刷新出来
在sleep期间printf打印的字符串在输出缓冲区中
stdout就是输出缓冲区,fflush(stdout)强制刷新

立马见到hello world是因为数据刷新了
没有刷新就暂存在输出缓冲区中stdout
fflus强制刷新stdout就会hello world显示出来
![]()
\n也是强制刷新的一种,行刷新
我们知道回车和换行不是一回事,回车把光标放在最开头
换行是换到下一行
/r只回车,/n换行回车

带\r的时候发现什么都没有打印![]()
因为输出的数据被缓存起来了,fflush(stdout)强制刷新就可以了

强制刷新后的结果
![]()
3.2字符输入
把cnt从9换成10![]() 发现打印的结果从10到90.80.70等等
发现打印的结果从10到90.80.70等等
不应该是10,9,8,7....吗?为什么会这样呢?
我们往显示器输出的是10,9,8,7整数吗?答案不是的
输出的10是1字符和0字符,166是1字符6字符和6字符并不是所谓的整数而是字符
计算机只能显示字符不能显示整数,计算机把整数转化成字符再把字符一个
一个往显示器打印只不过是这个字符放在了一起你就会分为这是整数
printf函数就来充当整数转化为字符的工作,也叫做格式化控制函数

第一打印cnt显示的是10字符\r回车到最左侧,第二次打印9的时候
因为9只有一位覆盖一个字符显示的是90
![]()
让它按照2位字符打印就可以解决问题
![]()
-d靠左对齐
![]()
![]()
scanf是字符输入
键盘和显示器都是字符设备
3.3进度条
创建好文件:
首先要创建3个文件

把上级目录的Makefile拷贝到当前目录来也可以自己重新创建

vim Makefile进入

这里包含2个依赖文件,process.c和main.c形成一个可执行process
不包含头文件process.h的原因是系统自能在当前目录下找到
cat Makefile

vim process.h进入头文件
![]() 防止头文件被重复包含
防止头文件被重复包含
1.process.h函数声明

2.main.c函数调用

3.process.c函数实现

make形成可执行process
./process编译代码
![]()
代码编译:
vim process.c进入文件

进度条都是以百分比的形式循环向前推进的
![]() 定义一个rate
定义一个rate
一个进度条每一次都要比上一次多打印一个#警号依次推进,那我咋知道当前有多少个#警号
![]() 先定义100个字符,字符的话要加\n不然进度到100的时候
先定义100个字符,字符的话要加\n不然进度到100的时候
就不够用了要改为101![]()
将字符串都初始化为0![]()
还有一种方式是使用memset函数

代码写好后./process编译

效果与我们预期的不一样
我们想实现的是在一行上打印,就需要在打印完第一个字符后光标立马要回到最左侧
不应该换行而是回车上面有讲过回车就用\r

如果你发现什么结果都没有的话就加上fflush(stdout)强制刷新

如果觉得sleep休眠的时间有点慢就用usleep调成0.几秒
![]()
带上rate百分比![]()
![]()
优化一下让百分号不动![]() ,加上百分号
,加上百分号![]()
优化后的结果

再加上旋转光标
![]()
![]()
看效果
![]()
#include"process.h"
2
3 #define SIZE 101
4 #include<string.h>
5 #include<unistd.h>
6
7 #define STYLE '#'
8 #define MAX_RATE 100
9 #define STIME 1000*40 //*5,1秒钟 , 不*5,0.0几秒
10
11 const char *str="|/-\\"; //旋转光标
12
13 void process()
14 {
15 //版本1
16 int rate=0;
17 //char bar[SIZE] ={0};
18
19 char bar[SIZE];
20 memset(bar, '\0' , sizeof(bar)); //初始化字符串为0
21 int num =strlen(str); //计算字符串长度
22
23 while(rate <= MAX_RATE) //循环打印#
24 {
25 printf("[%-100s][%d\%][%c]\r", bar, rate,str[rate%num]);
26 fflush(stdout); //强制刷新
27 //sleep(1);
28 usleep(STIME);
29 bar[rate++] = STYLE; //后置++
30 }
31
32 }
本小节完结,点个赞和关注吧!!!















 637
637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









