







目录
JAX [1] 是 Google 推出的可以对 NumPy 和 Python 代码进行自动微分并跑到 GPU/TPU(Google 自研张量加速器)加速的机器学习库。Numpy [2] 是 Python 著名的数组运算库,官方版本只支持 CPU 运行(后面 Nvidia 推出的 CuPy 支持 GPU 加速,这里按住不表)。JAX 前身是 AutoGrad [3],2015 年哈佛大学来自物理系和 SEAS(工程与应用科学学院)的师生发表论文推出的支持 NumPy 程序自动求导的机器学习库。AutoGrad 提供和 NumPy 库一致的编程接口,用户导入 AutoGrad 就可以让原来写的 NumPy 程序拿来求导。JAX 在 2018 年将 XLA [4](Tensorflow 线性代数领域编译器)引入进来,使得 Python 程序可以通过 XLA 编译跑到 GPU/TPU 加速器上。简单地理解 JAX = NumPy + AutoGrad + XLA。可以说,XLA 加持下的 JAX,才真正具备了实施深度学习训练的基础和能力。
JAX Github: https://github.com/google/jax
JAX API Docs: https://jax.readthedocs.io/en/latest/
# 使用介绍 #
# 自动微分
JAX 提供兼容 NumPy 风格的接口,照顾用户原 NumPy 编程习惯。JAX 面向 Python 用户提供自动微分接口,包括生成梯度函数、求导等。
例 1:使用 jax.grad() 求导
from jax import grad
def f(x):
return x * x * x
D_f = grad(f) # 3x^2
D2_f = grad(D_f) # 6x
D3_f = grad(D2_f) # 6
f(1.0) # 1.0
D_f(1.0) # 3.0
D2_f(1.0) # 6.0
D3_f(0.0) # 6.0 (always)jax.grad:只接受输出标量的原始函数 f,生成对应的梯度函数 ▼f。▼f 接受和原始函数一样的入参 x,输出为参数梯度 dx。▼f 亦可被 grad(),相当于对原始函数计算高阶梯度,但需满足一样的要求:输出为标量。如果被求导的函数计算结果不止一个数值,不能直接传给 grad()。需要先 reduce 成一个标量。
例 2:对数组函数求导
from jax import numpy as np
from jax import grad
import matplotlib.pyplot as plt
def f(x):
return x * x * x
D_f = grad(lambda x: np.sum(f(x)))
D2_f = grad(lambda x: np.sum(D_f(x)))
D3_f = grad(lambda x: np.sum(D2_f(x)))
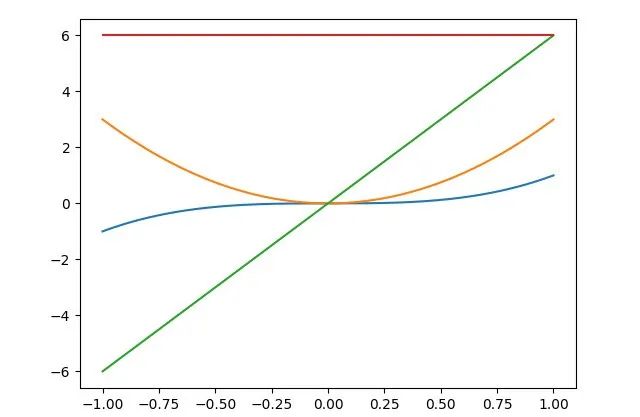
x = np.linspace(-1, 1, 200)
plt.plot(x, f(x), x, D_f(x), x, D2_f(x), x, D3_f(x))
plt.show()和例 1 相比主要区别在于例 2 分别对函数(f、D_f、D2_f)结果进行求和(sum)再求导。函数 f 和它的一阶、二阶、三阶导函数曲线如下图所示。
JAX 支持不同模式自动微分。grad() 默认采取反向模式自动微分。另外显式指定模式的微分接口有 jax.vjp 和 jax.jvp。
-
jax.vjp:反向模式自动微分。根据原始函数f、输入x计算函数结果y并生成梯度函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









