









Python实战案例:金庸的功夫流派、人物关系的分析案例(上)
一、项目说明
在香港的探案剧中, 经常见到这样的场景,为了分析某一桩谋杀案或者是失踪案,会把案件的可疑人员和与被害者的关系人员全部找出来,构建一个关系网。对关系网中的每一个人分析其做案动机。如下图所示。
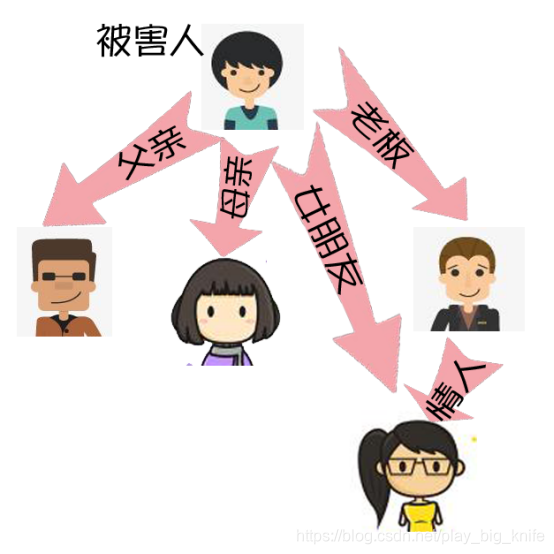
类似上图这种网络关系的图表,可能使用python的networkx来进行网络关系图的绘制。不过,这里没有案件,这里没有被害人。我们以金庸的人物、武功及小说原文来说明networkx的使用,这也可以说是金庸的功夫流派、人物关系的分析案例。
二、金庸小说爬取
要完成金庸的功夫流派,人物关系的分析,首先需要爬取金庸的小说内容,然后爬取金庸小说中的人物,再去爬取金庸小说中的功夫密籍,也要去爬取金庸小说中的门派。
这里先爬取金庸小说的数据,爬取的网站是http://www.jinyongwang.com,进入页面后,点击导航中的“金庸小说阅读”。页面如下图所示。

可以看到图中数据有金庸小说的修订版、新修版和旧版。这里爬取的数据为金庸小说修订版的所有文本数据。使用的模块就是requests和lxml.
首先用requests.get()方法获取网页http://www.jinyongwang.com/book/中所有代码。可以添加请求头headers={“User-Agent”:”Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36”}
这样,requests的请求语句就变成了。
res=requests.get(“http://www.jinyongwang.com/book/”,headers=headers)
在这句代码中,res存储的就是请求这个页面后的结果.get中的参数headers=headers的作用就是在请求的时候模拟浏览器的效果.
获取代码后的结果数据是保存在res.content中,把res.content中的数据进行decode(“utf8”)解码,就可以把形如”\0304”这样的代码解析成”utf8”编码的汉字.代码如下.
result=res.content.decode("utf8")
接下来用lxml进行网页数据的提取.
首先需要调用lxml中的etree方法,然后通过etree.HTML(请求响应结果)将获取的结果形成树,最终使用xpath从树结构中选取网页元素.相关代码如下.
from lxml import html
etree=html.etree
html_result=etree.HTML(result)
接下来要xpath技术提取网页中包含的书的名字及书详情内容的链接地址页.
在金庸书名列表页的”查看网页元素"后的效果图如下所示.
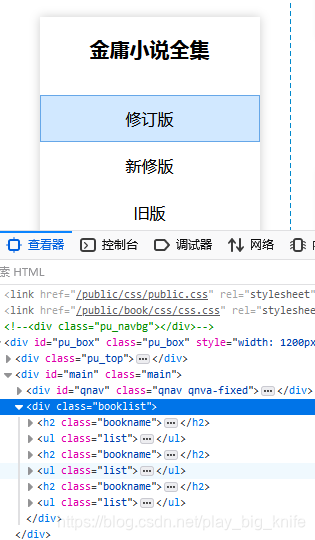
从上图的html树形结构中可以看出,在<div class=”booklist”>这个元素内部包含了3个<h2>和<ul>元素标签,每个<h2>标签里面其实就是金庸小说版本的相关说明,如下图所示。
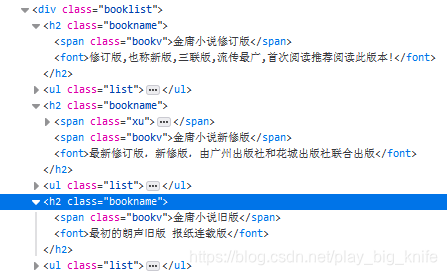
再去看每个<ul>标签的下面就是一堆的<li>标签,也就是金庸各版小说对应的书名及链接标签。
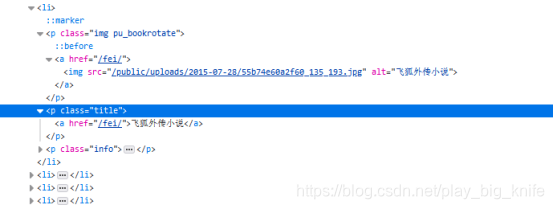
如下图展开“飞狐外传小说”的html标签名称,结构如下。
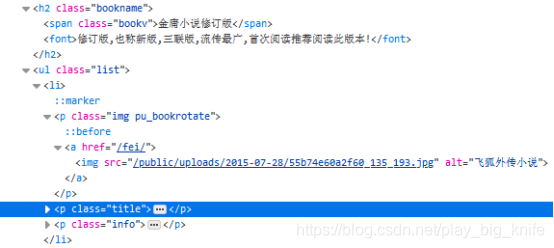
通过对html展开式可以得到,需要获取到金庸每本小说修订版的链接地址和书名,需要先访到ul元素,因为页面中有3个<ul class=”list”>元素,这里需要访问到是有修订版内容h2标的同级ul标签,当然我通过内容可以看出来是第一个ul,如果直接定位第一个ul是可以把ul标签定位,这样显得技术含量有些欠缺了,最重要的不是定位元素的结果,是如何用一种不变的方法去定位元素,提高技术的含金量,有助于面试时的表现。然后再去遍历ul下面的<li>元素标签,再将每个li标签中的a标签元素及<p class=title>标签元素找到,就可以解决书名及具体链接内容地址的获取。
先用代码去找到h2中含有“修订版”3个字的元素,xpath可以通过contains方法去查找包含关系,通过[@属性=”属性名"]去定位具备这种属性的元素.代码如下.
h2s=html_result.xpath("//h2[@class='bookname']/span[contains(text(),'修订版')]")[0]
上述代码的xpath是从class=”bookname”属性的h2元素中找到span标签中的文本包含"修订版"的元素.因为获取到的是列表,所以用到[0]的索引来获取列表的中第一个元素,也是唯一的元素.
找到包括"修订版"的元素之后,再找跟"修订版"元素的兄弟ul元素,就定位到了金庸小说修订版书目的页面.xpath可以通过following-sibling查找当前元素后面的兄弟元素,如果要查找当前元素前面的兄弟元素,可以使用preceding-sibling,这里查找的是当前元素后面的第一个ul标签元素,可以使用下面的代码查找.
ul=h2s.xpath("../following-sibling::ul[1]/li")
上面的代码就会把h2中包含”修订版"内容的下一个兄弟元素ul中的所有的li标签取出.继续遍历每个li标签,查找每个li标签下的<p class=“title”>元素里面的a标签的href属性和text()文本内容,href属性中存放的就是小说内容的链接,text()内容中存放的就是小说的名称。
截图如下。
提取每个li元素金庸小说的链接和内容代码如下:
for li in ul:
p_title=li.xpath("./p[@class='title']/a/text()")[0]
p_href=li.xpath("./p[@class='title']/a/@href")[0]
通过代码爬取到的书名可以存到文件夹中,书的具体详情地址就需要再次请求获取的a标签链接。继续用requests.get去请求页面的地址,需要注意的是,页面地址是由爬取的内容地址前加上http://www.jinyongwang.com得到的。具体代码如下。
os.makedirs("./book/"+str(p_title))
url2="http://www.jinyongwang.com"+p_href
res2=requests.get(url2,headers=headers)
再次请求每本书章节列表的内容返回也是放在content属性中,也是需要decode进行解码的。代码如下。
result2=res2.content.decode("utf8")
有了金庸小说书名章节列表的页面,就可以查看每个章节的html树形结构。如下图所示.

由上图显示可以看出,这里需要获取的是<ul class=”mlist”>中的所有li元素,再取出<li>元素标签中<a>标签的内容和链接即可.内容就是章节名,链接就是小说章节中的具体地址.这种取元素的方式仍然是调用lxml中etree的xpath方法.具体代码如下.
html_result2=etree.HTML(result2)
lis=html_result2.xpath("//ul[@class='mlist']/li")
for li_text in lis:
sub_title=li_text.xpath("./a/text()")[0]
print(sub_title)
sub_href=li_text.xpath("./a/@href")[0]
这段代码中,xpath参数中的@href就是获取a链接的herf属性,xpath参数中的text()就是获取a链接的标签内容。接下来继续请求章节内容标签的链接,也是通过request.get()这样的方法,请求的地址也需要在获取的详情地址中加入”http://www.jinyongwang.com”,再次将请求的内容进行decode(“utf8”)解码.请求代码如下.
res3=requests.get("http://www.jinyongwang.com"+sub_href,headers=headers)
result3=res3.content.decode("utf8")
这样,获取到的内容就是章节的具体小说内容.需要通过xpath技术对小说具体内容页面进行解析。
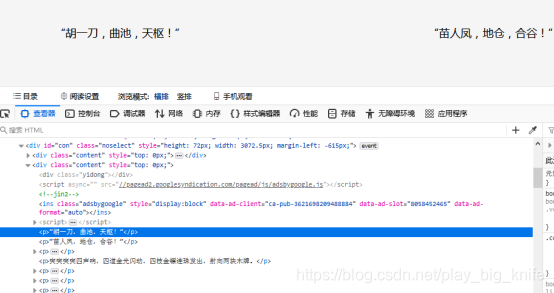
由上图所示的html网页结构,再进行xpath定位网页元素。获取<div class=”content”>元素中的p标签。把每个p标签的内容全部取出,用逗号连接成句。代码如下。
result_content=html_result3.xpath("//div[@class='content']")[0]
ps=result_content.xpath("./p/text()")
str_content=""
for p1 in ps:
str_content+=p1+"\n"
with open("book/"+str(p_title)+"/"+str(sub_title)+".txt","w",encoding="utf8") as f:
f.write(str_content)
通过上述的讲解,金庸小说的具体内容就爬取完毕了.爬取的全部代码如下.
import requests
from lxml import html
import os
etree=html.etree
headers={ "User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"}
url="http://www.jinyongwang.com/book/"
res=requests.get(url,headers=headers)
result=res.content.decode("utf8")
html_result=etree.HTML(result)
h2s=html_result.xpath("//h2[@class='bookname']/span[contains(text(),'修订版')]")[0]
ul=h2s.xpath("../following-sibling::ul[1]/li")
for li in ul:
p_title=li.xpath("./p[@class='title']/a/text()")[0]
p_href=li.xpath("./p[@class='title']/a/@href")[0]
os.makedirs("./book/"+str(p_title))
url2="http://www.jinyongwang.com"+p_href
print(url2)
res2=requests.get(url2,headers=headers)
result2=res2.content.decode("utf8")
html_result2=etree.HTML(result2)
lis=html_result2.xpath("//ul[@class='mlist']/li")
for li_text in lis:
sub_title=li_text.xpath("./a/text()")[0]
print(sub_title)
sub_href=li_text.xpath("./a/@href")[0]
print("http://www.jinyongwang.com"+sub_href)
res3=requests.get("http://www.jinyongwang.com"+sub_href,headers=headers)
result3=res3.content.decode("utf8")
with open("test.html","w",encoding="utf8") as f:
f.write(result3)
html_result3=etree.HTML(result3)
result_content=html_result3.xpath("//div[@class='vcon']")[0]
print(result_content)
ps=result_content.xpath("./p/text()")
str_content=""
for p1 in ps:
str_content+=p1+"\n"
with open("book/"+str(p_title)+"/"+str(sub_title)+".txt","w",encoding="utf8") as f:
f.write(str_content)
三、爬取金庸小说的人物
爬取了金庸小说的文本后,继续爬取金庸小说的人物、功夫和门派。
先进行金庸小说的人物。
通过金庸小说网http://www.jinyong.com/,点击导航中的“金庸数据”一项,接下来选择“人物”,现在请求的网页地址就变成了“http://www.jinyongwang.com/data/renwu/”。通过下面代码。
requests.get(“http://www.jinyongwang.com/data/renwu/”,headers=headers)
这句代码的作用是用浏览器的请求头去请求“http://www.jinyongwang.com/data/renwu/”,将获取到的内容再进行后面的解码。解码代码如下。
result=res.content.decode("utf8")
接下来调用etree中的HTML,对出现的页面通过html树形结构定位到具体内容,如下图所示。
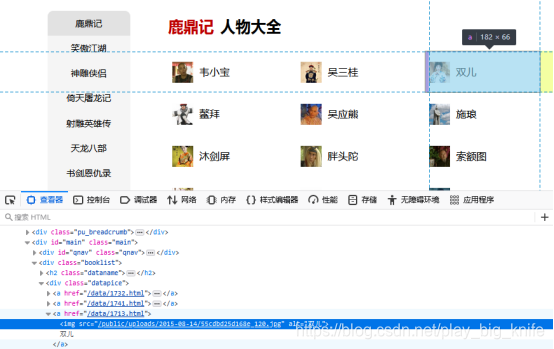
从图中可以看出,获取的html元素是<div class=”booklist”>中的<h2 class=”dataname”>元素提取的是书的名字,<div class=”datapice”>元素中的每个<a>标签的文本就是书中所出现的每一个人的名字。这里也可以使用xpath先定位到h2元素,然后利用following-sibling去定位h2元素后面的第一个<div class=”datapice”>元素,遍历这个元素里面所有的a标签元素,找到a标签元素里面的标签内容即可。最后把爬取的h2标签中显示的金庸书名字作为文件名称,<div class=”datapice”>元素里面每一个标签<a>中的文本内容(即人名)作为金庸书名对应的人物列表文本.代码如下.
import requests
from lxml import html
etree=html.etree
headers={ "User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"}
res=requests.get("http://www.jinyongwang.com/data/renwu/",headers=headers)
result=res.content.decode("utf8")
html1=etree.HTML(result)
novels=html1.xpath("//h2[@class='dataname']")
for novel in novels:
title=novel.xpath("./span/text()")[0]
datas=novel.xpath("./following-sibling::div[1]")
for data in datas:
names= data.xpath("./a/text()")
for name in names:
with open('renwu/' + title + ".txt", "a", encoding="utf8") as f:
f.write(name+"\n")
三、爬取金庸小说的功夫
爬取小说的人物后,继续爬取金庸每本小说出现的功夫.
由于代码及分析方面与爬取小说的人物方法内容类似,这里直接给出代码.
import requests
from lxml import html
etree=html.etree
headers={ "User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"}
res=requests.get("http://www.jinyongwang.com/data/wugong/",headers=headers)
result=res.content.decode("utf8")
html1=etree.HTML(result)
novels=html1.xpath("//h2[@class='dataname']")
for novel in novels:
title=novel.xpath("./span/text()")[0]
datas=novel.xpath("./following-sibling::div[1]")
for data in datas:
names= data.xpath("./a/text()")
for name in names:
with open('wugong/' + title + ".txt", "a", encoding="utf8") as f:
f.write(name+"\n")
三、爬取金庸小说的门派
接下来,继续爬取金庸小说网中的门派.
代码及分析方面与爬取小说的人物或者功夫方法内容类似,这里直接给出代码.
import requests
from lxml import html
etree=html.etree
headers={ "User-Agent":"Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36"}
res=requests.get("http://www.jinyongwang.com/data/menpai/",headers=headers)
result=res.content.decode("utf8")
html1=etree.HTML(result)
novels=html1.xpath("//h2[@class='dataname']")
for novel in novels:
title=novel.xpath("./span/text()")[0]
datas=novel.xpath("./following-sibling::div[1]")
for data in datas:
names= data.xpath("./a/text()")
for name in names:
with open('menpai/' + title + ".txt", "a", encoding="utf8") as f:
f.write(name+"\n")代码的github地址:https://github.com/wawacode/jinyong_kongfu_style_analyse
项目对应的视频地址:
金庸知识图谱1-金庸数据爬取
https://www.bilibili.com/video/BV1yy4y1E72Z/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









