










elasticsearch使用logstash同步数据库实战查询分页接口
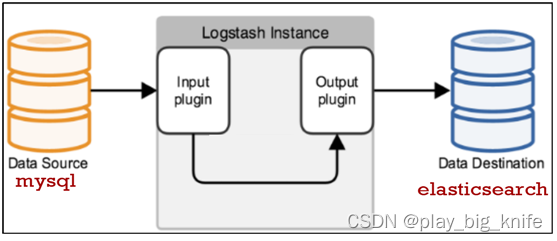
在这个项目架构中,logstash充当一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端。Mysql结合到logstash中做为管道的输入端,将Mysql的数据提交到logstash,logstash负责将信息同步到elasticsearch,elasticsearch做为logstash管道的输出端,利用倒排索引将Mysql中的数据建立索引文档,在索引文档中实现数据的查询,并进行实际的分页需求。Flask作为后端框架,将elasticsearch中的查询结果以json数据的形式接收,通过接口的方式传送到前端。
一、mysql中的数据文件
根据项目的具体要求,logstash同步的数据库数据来自于mysql,对于mysql关系型数据库来讲,必须数据库中存在数据才能进行查询操作。因此这里使用mysql的数据产生文件,文件内容如下。
create database mycompany default charset=utf8;
use mycompany;
create table employee(empno varchar(4),ename varchar(20),job varchar(20),mgr varchar(4),hiredate datetime,sal double,COMM double,deptno int)engine=InnoDB default charset=utf8;
insert into employee values("1001","甘宁","文员","1013","2000-12-17",8000.00,NULL,20);
insert into employee values("1002","黛琦丝","销售员","1006","2001-02-20",16000.00,3000.00,30);
insert into employee values("1003","殷天正","销售员","1006","2001-02-22",12500.00,5000.00,30);
insert into employee values("1004","刘备","经理","1009","2001-04-02",29750.00,NULL,20);
insert into employee values("1005","谢逊","销售员","1006","2001-09-28",12500.00,14000.00,30);
insert into employee values("1006","关羽","经理","1009","2001-05-01",28500.00,NULL,30);
insert into employee values("1007","张飞","经理","1009","2001-09-01",24500.00,NULL,10);
insert into employee values("1008","诸葛亮","分析师","1004","2007-04-19",30000.00,NULL,20);
insert into employee values("1009","曾阿牛","董事长",NULL,"2001-11-17",50000.00,NULL,10);
insert into employee values("1010","韦一笑","销售员","1006","2001-09-08",15000.00,0.00,30);
insert into employee values("1011","周泰","文员","1008","2007-05-23",11000.00,NULL,20);
insert into employee values("1012","程普","文员","1006","2001-12-03",9500.00,NULL,30);
insert into employee values("1013","庞统","分析师","1004","2000-12-03",30000.00,NULL,20);
insert into employee values("1014","黄盖","文员","1007","2002-01-23",13000.00,NULL,10);
insert into employee values("1015","张三","保洁员","1001","2013-05-01",80000.00,50000.00,50);
create table dept(deptno int,dname varchar(20),loc varchar(20))engine=InnoDB default charset=utf8;
insert into dept values(10,"教研部","北京");
insert into dept values(20,"学工部","上海");
insert into dept values(30,"销售部","广州");
insert into dept values(40,"财务部","武汉");
以上数据文件的内容,读者可以在文末的github地址中获取。也可以自行敲入相关的命令。对于mysql的命令这里不做过多的解释,以上的指令最终会建立数据库,打开数据库,在数据库中建立两个表格,employee员工表和dept部门表,两个表格之间通过部门编号可以连接数据,多条insert语句的组合就是向员工表employee和部门表dept中插入多条数据。
二、logstash的搭建
logstash 是一个实时的管道式开源日志收集引擎。其具体架构决定了在输入端采集各种样式,大小和相关来源数据,在此项目的技术架构中,logstash采集来自于mysql中的数据。输出端负责将过滤出的数据保存到那些数据库和相关存储的技术中,在此项目的技术架构中,输出端采用elasticsearch。
具体技术架构如下图所示。
安装logstash,可以直接下载tar包,然后解压到指定的文件夹内,这里的logstash使用的版本是7.8.0。笔者这里以windows系统为例,把logstash的压缩包解压到d盘的bigdata目录中,如下图所示。
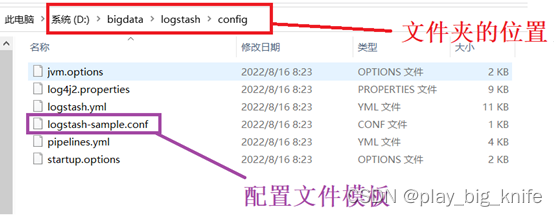
在logstash的文件夹中有一个config目录,对应的配置文件就在这个config目录下,其配置文件模板名称为logstash-sample.conf。如下图所示。
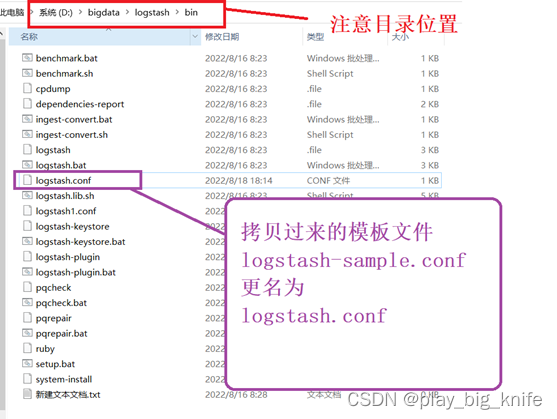
这里为了启动时方便,将这个配置文件模板拷贝到logstash目录中的bin目录下,拷贝成功后将其更名为logstash.conf。如下图所示。
如上图所示,更名成功后可以编辑logstash的内容,原模板内容中有input和output两个设置项,将mysql的相关设置配置到input设置项中,将output的设置配置到output设置项中。
具体input项设置内容如下。
input {
jdbc{
type=>"employee"
jdbc_connection_string=>"jdbc:mysql://localhost:3306/mycomany?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user=>"root"
jdbc_password=>"admin"
jdbc_driver_library=>"d:/bigdata/driver/mysql-connector-java-5.1.48.jar"
jdbc_driver_class=>"com.mysql.jdbc.driver"
statement=>"select * from employee"
jdbc_paging_enabled=>"true"
jdbc_page_size=>"30"
}
jdbc{
type=>"dept"
jdbc_connection_string=>"jdbc:mysql://localhost:3306/mycomany?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user=>"root"
jdbc_password=>"admin"
jdbc_driver_library=>"d:/bigdata/driver/mysql-connector-java-5.1.48.jar"
jdbc_driver_class=>"com.mysql.jdbc.driver"
statement=>"select * from dept"
}
}
在input配置项中,我们设置了两个jdbc的连接,这两个jdbc分别连接到employee员工表和dept部门表中。在jdbc的相关的配置项的具体解释如下。
type=>"employee":这里使用自定义类型employee,目的是把type当成一个变量,在output中通过type值可以将数据输出到不同的es索引文档中。相当于es利用此参数标明不同的山头。
jdbc_connection_string:配置数据库连接的地址,这里包括协议、ip、端口号以及数据库,同时还有数据库的编码及使用的时区。具体地址设置内容如下。

jdbc_user:mysql数据库连接的用户名,这里使用root。
jdbc_password:mysql数据库连接的密码,这里设置成了admin,具体根据数据库密码来设定其值。
jdbc_driver_library:jdbc连接mysql的驱动,各个数据库都有各自不同的驱动,可以自行下载。这里笔者将驱动下载后,存储到了bigdata目录下的driver端,因此其设置项的值如下 。
"d:/bigdata/driver/mysql-connector-java-5.1.48.jar"
jdbc_driver_class:不同的数据库有不同的class设置, mysql数据库的设置其为com.mysql.jdbc.Driver。
statement:接收sql语句的参数,把sql语句的执行结果作为其值。这里使用select查询出不同表中的数据。这里有一个参数schedule没有设置,其表示mysql数据库间隔多长时间周期收集数据同步到elasticsearch中。这个schedule称之为定时器,可以按照“分 时 天 月 年”的格式来设置。如schedule=> 22 表示每天22点执行一次。
logstash中input配置项配置成功后,可以配置其output的输出项,如下所示。
output {
if[type]=="employee"{
elasticsearch {
hosts => ["http://localhost:9200"]
index => "employee"
}
}
if[type]=="employee"{
elasticsearch {
hosts => ["http://localhost:9200"]
index => "dept"
}
}
}
三、安装和启动elasticsearch
Elasticsearch简称ES,是一个分布式的开源搜索和分析引擎,在 Apache Lucene 的基础上开发而成。
Elasticsearch 是面向文档的,这意味着索引和搜索数据的最小单位是文档。这个文档通常是以JSON 的数据格式来表示的。例如,一项评选活动可以通过如下文档表达:
{
“name”:”评选活动”,
“organizer”:”民间评选组织”,
“location”:”民间田头小路上”
}
一篇单独的文档也可以包含一组数值,索引非常像关系型世界的数据库,是独立的大量文档集合。每个索引存储在磁盘上的同组文件中,索引存储了所有映射类型的字段,还有一些设置。
安装ES可以直接下载压缩包,这里使用的是7.6.1版本。安装包下载后进行解压,解压后在windows的cmd命令窗口中进入bin目录,执行elasticsearch.bat即可。如下图所示。
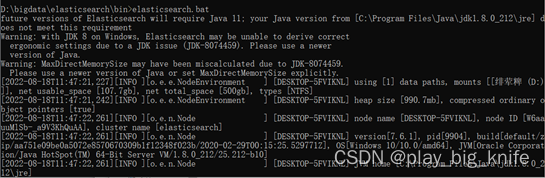
执行过程中,出现Starting标志,表示elasticsearch执行成功。
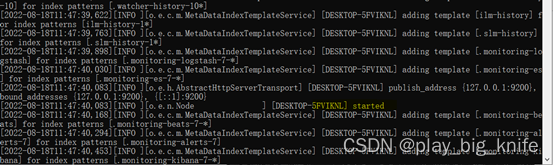
图中标黄的部分为“started”的标志,其表示ES已启动。ES启动后,可以使用http://localhost:9200地址来访问,访问结果如下图所示。
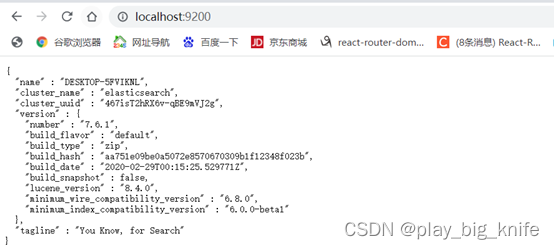
上图中会显示出ES的版本信息。接下来,需要使用操作ES的图形化界面工具kibana。不过这里需要注意,elaticsearch的版本需要与kibana的版本要求是一致的,不然kibana不能正常工作,笔者使用的kibana版本是和elasticsearch的版本保持一致的,都是7.6.1。
四、安装和启动kibana
Kibana 是设计出来用于和 Elasticsearch 一起使用的开源的分析与可视化平台,可以用来搜索、查看存放在Elasticsearch 索引里的数据,使用各种不同的图表、表格、地图等展示高级数据分析与可视化,基于浏览器的接口的方式使你能快速创建和分享展现Elasticsearch查询变化的动态仪表盘,让大量数据变得简单,容易理解。
Kibana也是一个压缩包,解压后需要进行配置文件的修改。配置文件在解压后kibana目录中的config目录下。如下图所示。
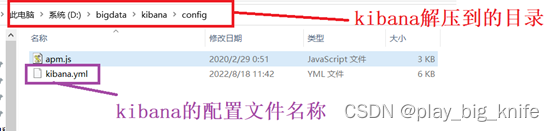
上图中kibana.yaml文件就是kibana的配置文件,打开文件后,在其中配置elasticsearch的启动地址。如下图所示。

上图中红框标注的语句就是elasticsearch的启动地址,这个地址在文件初始打开的时候前面有一个“#”号注释,只需要把“#”号注释去掉即可。
执着可以将配置文件中的i18n.locale设置成“zh-CN”,其目的可以显示中文。如下图所示。

文件配置成功后,可以进入kibana的bin目录中,启动bin目录中的kibana.bat文件。运行结果如下图所示。

Kibana启动后会连接elaticsearch,连接时会有相关信息显示。启动的最后Kibana会显示访问地址和端口的信息,通过访问本机及端口5601就可以访问kibana的图形界面,显示的信息如下图所示。
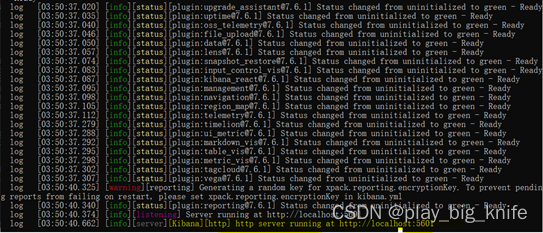
通过信息的提示,使用浏览器访问http://localhost:5601,显示结果如下。

在这个页面中,点击“explore on my own”选项。出现的界面如下。
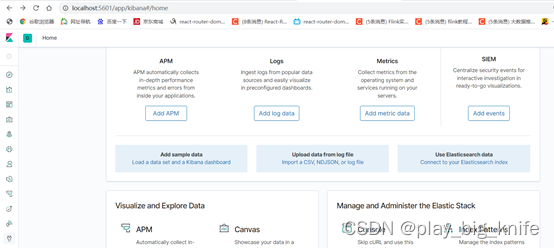
在这个界面的左侧边栏有Dev tools的图标,表示开发工具,直接点击Dev tools的图标,显示如下。
点击工具图标后的效果如下图。
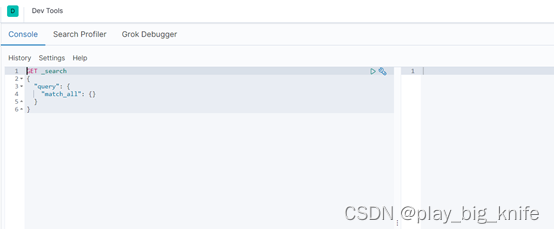
在Dev tools的命令行中可以通过PUT上传ES的数据,然后通过GET显示最终上传的数据,查看最终kibana的操作是否能够正常显示ES中的数据。
如上传一个student的数据,在Dev tools命令行中输入内容如下。
PUT /school/student/1
{
"name":"zhangshan",
"age":23
}
点击命令行中右侧的绿色三角按钮,可以执行该指统,在Dev tools中执行效果如下。

通过查询该索引文下的数据,可以显示最终是否把数据上传到ES文档中。Dev tools命令行查询命令如下。
GET school/student/_search
{
"query":{
"match_all":{}
}
}
在右侧命令行点击绿色三角执行按钮后,最终查询结果如下图所示。
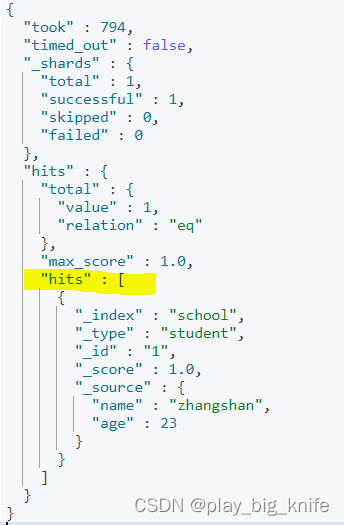
图中黄线标注的为hits项,表示击中查询的其中一个数据,名字为zhangshan,年龄为23。
这样Kibana就可以操作elasticsearch了。
不过,这里对中文没有分词化,需要中文分词化的词库,在ES指令中使用analize进行分词化,命令格式如下。
POST /_analyze
{
“text”:“中华人民共和国”
}
这里没有进行中文的分词化,没有分词化的效果如下图所示。
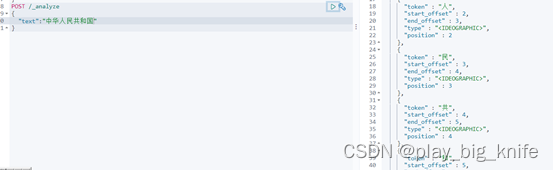
在右边的结果面板中是一个中文字一个索引,这样并没有形成词。需要中文分词器。这里将ik的分词器拷贝到elasticsearch的plugin目录下。如下图所示。
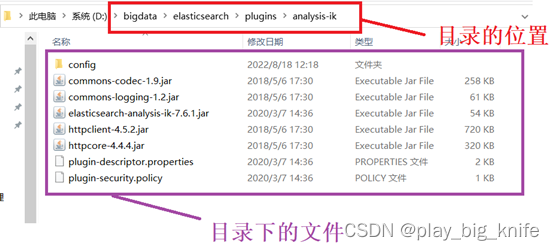
拷贝成功后,相当于安装分词器ik成功,再次重启elasticsearch和kibana。
重启后再次执行指令analyze,此时指定分词器。命令如下。
POST /_analyze
{
"analyzer":"ik_smart",
"text":"中华人民共和国"
}
命令执行后,最终得到的结果如下图。
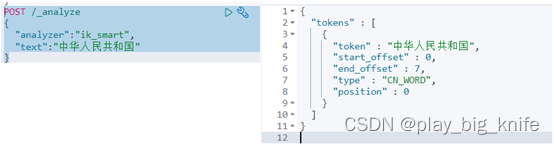
从图中可知结果,“中华人民共和国”成为一种词汇,这是由于ik_smart对分词做了粗粒度的切分。
在保证elasticsearch和kibana两个服务都能正常启动后,这里接下来启动logstash,将之前存储到mysql表中的数据存储到ES中。
在logstash的bin目录下执行命令如下。
logstash -f logstash.conf
执行后如下图所示。
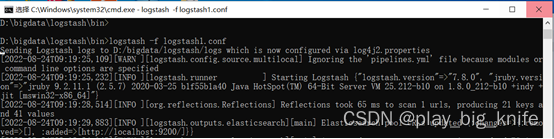
当其执行结果的信息中显示出两条sql语句表示执行成功。这两个语句分别取出employee员工表和dept部门表的全部数据。如下图所示。
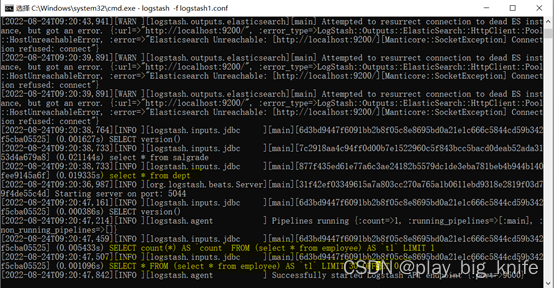
上图中标黄的部分即为取出employee员工表的数据和取出dept部门表中的所有数据。,这样logstash就会把数据取出存放在ES索引文档,其中employee员工表数据存储在索引名字为employee的索引文档中,dept部门表数据存储在索引名字为dept的索引文档中。ES可以通过GET指令去查询索引employee中的数据。具体查询指令如下。
GET /employee/_search
{
"query":{
"match_all":{}
}
}
在kibana可视化图形界面中Dev tools中输入该指令,执行结果如下图所示。
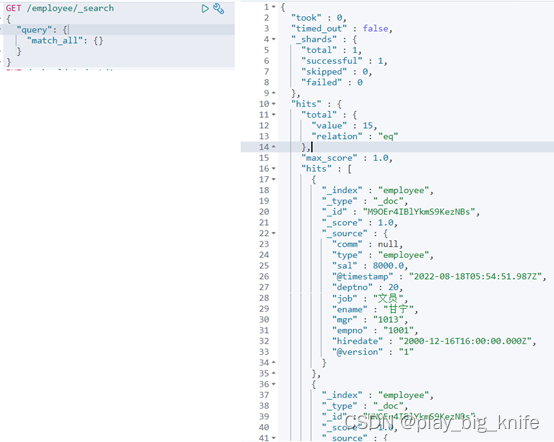
根据图中所示结果,这里只显示了10条记录,也可以显示多条记录。在query后面加入from和size属性,命令如下。
GET /employee/_search
{
"query":{
"match_all":{}
},
"from":0,
"size":15
}
from属性表示从哪一条索引记录开始,size表示一个页面中显示多少条记录。
修改指令后,运行结果如下图所示。
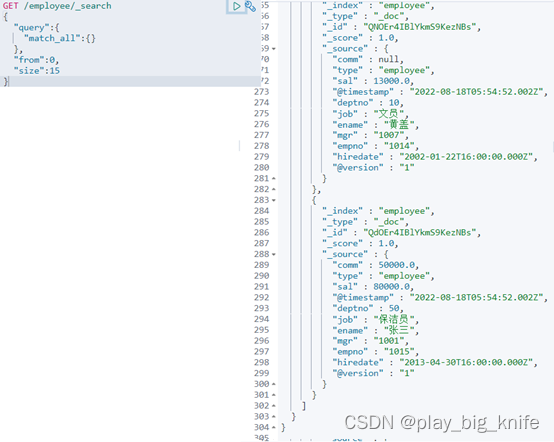
这里显示了15条记录,ES输出结果中显示的记录数是通过from和size作用出来的。
这时导入的数据在ES中,只能进行单表查询。
可以从以下查询方法中慢慢体会其查询方法。
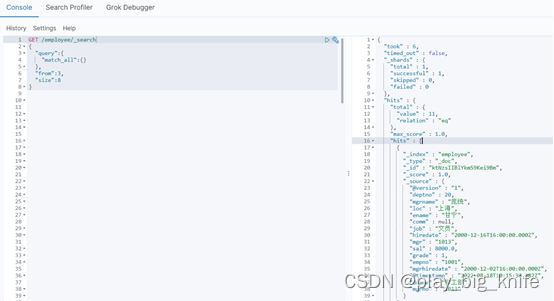
1、分页查询员工表所有数据,从第3条索引记录开始,每页显示8条数据。
分析:ES查询参数都是json数据,根据获取员工表所有数据,可以使用“query”键,其值是一个字典型数据,“match_all”键匹配所有数据,同时在“query”主键中还需要存在“from”主键,指从哪条记录开始,这里题意要求从第3条索引记录数据开始,from后面的参数就是3,题意又要求每页显示8条数据,这里的size后面的参数就是8。
根据分析具体指令如下。
GET /employee/_search
{
"query":{
"match_all":{}
},
"from":3,
"size":8
}
指令的具体执行结果如下图所示。
2、删除所有数据,或者根据查询删除数据
分析:删除数据需要提供删除数据的地址,根据查询结果删除索引中数据的地址是:
/employee/_delete_by_query
这个地址是通过POST请求实现的。
具体指令如下。
POST /employee/_delete_by_query
{
"query":{
"match_all":{}
},
}
执行后效果图如下。

从输出结果中可以看到deleted的信息条数为15,最终failures的错误条数为0。表示15条数据全部删除成功。
3、列出薪资小于15000,大于5000的所有员工信息。
分析:薪资小于15000和大于5000这是两个条件的布示运算模式,一般在程序设计中使用逻辑或or方法进行结合。ES中使用布尔运算需要在query查询的键中声明bool的键,在其值中指定逻辑或的键名should,如果是逻辑与使用键名为must,在逻辑或及逻辑与的键值中指定range表示范围,在范围中指定限制的字段名称,并指定字段要求的数字,大于使用gt,大于等于使用gte ,小于使用lt,小于等于使用lte。这样,具体指令如下。
GET /employee/_search
{
"query":{
"bool":{
"should":[
{
"range":{
"sal":{
"lt":15000
}
}
},
{
"range":{
"sal":{
"gt":25000
}
}
}
]
}
}
执行命令后的结果如下图所示。

4、列出在销售部工作的员工的姓名。
分析:具体员工在哪个部门,在员工表中只能看到员工工作的部门编号,不知道这个编号是哪个工作部门,需要把员工表和部门表合成为一个表,也就是mysql的关联查询,对于关联查询,ES并没有提供两个不同索引间的查询方式,只能在logstash导入ES索引文档时数据就是员工表和部门表的联合表,这就需要重新编写logstash配置文件的输入,在输入中把sql语句变成两个表数据的合成。配置文件中输入的修改如下。
jdbc{
jdbc_connection_string=>"jdbc:mysql://localhost:3306/
mycomany?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user=>"root"
jdbc_password=>"admin"
jdbc_driver_library=>"d:/bigdata/driver/mysql-connector-java-5.1.48.jar"
jdbc_driver_class=>"com.mysql.jdbc.driver"
statement=>"select employee.*,dept.* from employee,dept where employee.deptno=dept.deptno
}
上面的配置文件中,修改的也是sql语句中的select查询语句,这里在查询语句中把employee员工表和dept部门表通过deptno部门编号合成了一个表,最终将数据收集到logstash,由于不需要两个独立的表,所以input配置中也不需要提供type值,在输出项配置中直接把两个表的数据合表输出到ES中。输出项的配置如下。
elasticsearch {
hosts => ["http://localhost:9200"]
index => "employee"
}
配置成功后,再次重启logstash,将数据导入到ES中,然后就可以直接通过dname字段匹配数据,不过这里是精确匹配,精确匹配需要使用term,match方法只针对于分词的匹配,如果使用match方法匹配“销售部”,就会把带“部”的词都会查询出来,不能精确地定位到部门名称是“销售部”的数据。而term只能精确匹配到一个数据,如果匹配多个词的数据,需要使用terms,不过这里使用terms报错,只能使用term结合于must来将部门名称即要匹配“销”,也可匹配“售”,还要匹配“部”,三者条件都满足。最终匹配ES的查询指令如下。
GET /employee/_search
{
"query":{
"bool":{
"must":[{
"term":{
"dname":"销"
}
},
{"term":{
"dname":"售"
}},
{"term":{
"dname":"部"
}}
]
}
}
}
命令执行后的效果图如下所示。

5、查询与“刘备”的工作不同种的工作。
分析:这里通过题意可知,首先需要知道刘备的工作是什么,然后通过ES索引文档中查询逻辑非的条件,也就是与刘备工作不同的人是哪些。需要要注意的是ES不支持子查询,这样查询刘备的工作和查询与刘备工作不同种的工作名称这两项查询不能写在一起。只能单独去写。
(1)先实现查询刘备的工作,也就是查询刘备的信息,可以使用精确匹配term,然后名字中必须有“刘”字和“备”字,也是逻辑与的关系,使用must,由于数据库中的数据没有其它匹配“刘”与“备”的数据,这里使用match也不会被分词出其它的数据,只是一个巧合而已,不是必然的结果。执行命令如下所示。
GET /employee/_search
{
"query":{
"bool":{
"must":[{
"match":{
"ename":"刘"
}
},{
"match":{
"ename":"备"
}
}]
}
},
"_source":["job"]
}
指令中加入“_source”表示只显示job工作字段内容,不显示其他字段内容。执行结果如下图所示。

从图中所示,已知道刘备的工作是“经理”,接下来,通过查询其他员工的工作不是“经理”的数据信息。“经理”经过分词后变成了“经”和“理”两个词,需要term的精确匹配,布尔的逻辑非取反使用must not,这样,得到的指令如下。
GET /employee/_search
{
"query":{
"bool":{
"must_not":[{
"term":{
"job":"经"
}
},{
"term":{
"ename":"理"
}
}]
}
},
"_source":["job"]
}
上面的指令在kibana中执行结果如下图。
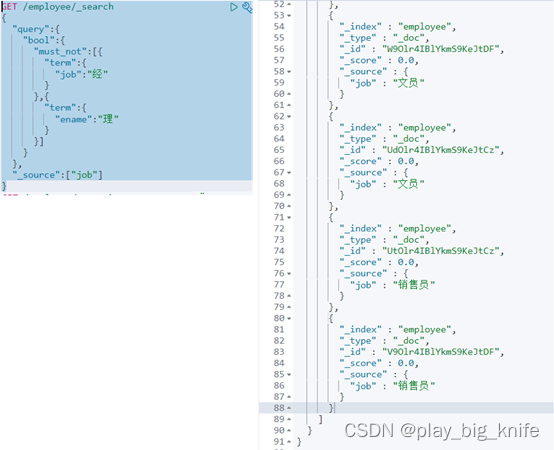
由图中所知,这里得出与刘备工作不同种的工作有“文员”和“销售员”等。
6、查出至少有三个员工的部门。显示部门编号、部门名称、部门位置、部门人数。
思路:从查询的本意是需要聚合函数的参数。在ES查询中aggs表示聚合的意思,在aggs中分组的方法通过可以先统计每个部门的人数。命令如下。
GET /employee/_search
{
"size":0,
"aggs":{
"depts":{
"terms":{
"field":"deptno"
}
}
}
}
运行命令后效果图如下。

由图中的输出结果可以看出,ES已经计算出统计值,doccount分别为6,3,2等数值,其数值表示分组后各分组项中的统计个数。这里需要限制统计数据的最小值,在ES中有一个mindoc_count这个键可以指定数据统计的最小值。这样命令修改成如下形式。
GET /employee/_search
{
"size":0,
"aggs":{
"depts":{
"terms":{
"field":"deptno",
"min_doc_count":3
}
}
}
}
上面命令在特征匹配时,指定了“mindoccount”的ES文档统计最小值。指令执行后,输出结果如下图。

图中结果中的buckets显示的字段有“key”和“doccount”,如果需要添加其它字段,需要继续增加汇总aggs键,并在键中定义sample示例键,在sample示例键中指明tophits命中的其他字段名称,在top_hits中指定source键,source的键值就是增加显示的字段名称。指令如下。
GET /employee/_search
{
"size":0,
"aggs":{
"depts":{
"terms":{
"field":"deptno",
"min_doc_count":3
},
"aggs":{
"sample":{
"top_hits":{
"size":1,
"_source":["dname","loc"]
}
}
}
}
}
}
注意: top_hits接触记录只有一条,所以这里size=1。
执行后结果如下图所示。
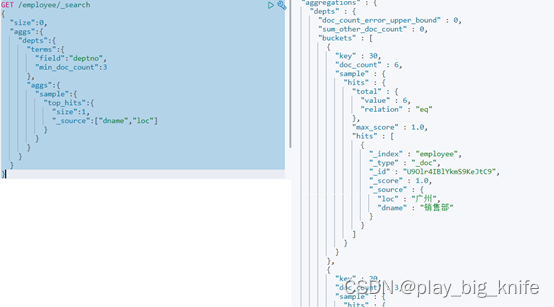
7、列出受雇日期早于直接上级的所有员工的编号、姓名。
分析:受雇日期早于上级,必须把上级的受雇日期也做为ES索引文档的显示数据,由于ES不支持两个不同索引的联接,因此只能再次把上级的受雇日期也作为索引文档中的数据,员工表只能查询到上级的员工编号,根据这个员工编号再去查找其受雇日期,这里存在了员工表,员工表和部门表的三表统一,之所以两个员工表是因为只有两个员工表才能建立上级的员工编号及上级的受雇日期与下属的员工编号及下属的受雇日期都统一在一张表中,继续编辑logstash.conf的输入项设置,将statement指示的sql语句变成三个表格的联合体。具体logstash.conf中输入项的设置如下。
input {
jdbc{
jdbc_connection_string=>"jdbc:mysql://localhost:3306/mycomany?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user=>"root"
jdbc_password=>"admin"
jdbc_driver_library=>"d:/bigdata/driver/mysql-connector-java-5.1.48.jar"
jdbc_driver_class=>"com.mysql.jdbc.driver"
statement=>"select e.*,k.ename mgrname,k.hiredate mgrhiredate,k.empno mgrno,dept.*,salgrade.grade from employee e,employee k,dept,salgrade where e.deptno=dept.deptno and e.sal>salgrade.losal and e.sal<salgrade.hisal and e.mgr=k.empno"
}
}
设置项中statement后面的sql语句实现了员工表,员工表及部门表的三个表的合体。其输出项的配置没有任何变化,还是直接输出ES地址和索引即可,配置如下所示。
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "employee"
}
}
完成logstash.conf的配置后,重新启动logstash,把数据同步到elasticsearch中。
把数据完成三表统一后,主管的受雇时间与员工的受雇时间是两个字段,两个字段的值需要用到script参数。并且需要注意,时间的比较不能直接使用value,需要把value通过时间戳函数getMillis()做转化,将其转化为时间的时间戳,时间戳大的值表示入职时间晚,时间戳小的值表示入职时间早。指令如下。
GET /employee/_search
{
"query":{
"bool":{
"filter":{
"script":{
"script":{
"source":"doc['hiredate'].value.getMillis()<doc['mgrhiredate'].value.getMillis()"
}
}
}
}
}
}
其命令执行后的结果如下图所示。
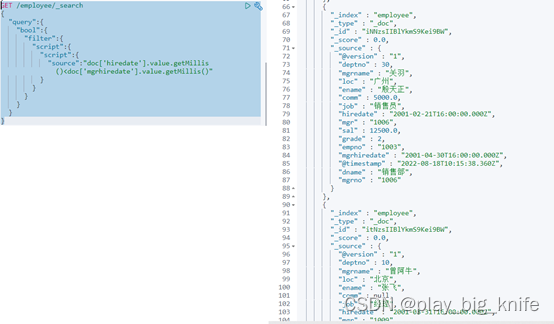
四、flask连接elasticsearch
Flask通过elasticsearch模块与elasticsearch进行连接,安装elasticsearch模块的时候注意elasticsearch模块的版本,版本不同连接是不会成功的。这里使用的elasticsearch的版本为7.6.1,安装python支持的elasticsearch版本时,并没有7.6.1版本,可以使用7.6.0的版本,flask对版本是向下兼容的。这样在python项目中使用flask和elasticsearch的结合需要安装的模块如下。
pip3 install flask
pip3 install elasticsearch==7.6.0
安装成功后,elasticsearch可以通过模块中实例化的Elasticsearch对象配合ES查询语句,调用search方法最终得到查询的结果,查询所有数据的代码如下。
from elasticsearch import Elasticsearch
from flask import Flask,request
import json
app=Flask(__name__)
es=Elasticsearch(["http://localhost:9200"])
@app.route("/findall")
def findall():
body={
"query":{
"match_all":{}
}
}
result=es.search(index="employee",body=body)
return json.dumps(result,ensure_ascii=False)
if __name__=="__main__":
app.run()
代码实例化Flask类,并将name作为参数,实例化后的对象为app变量,主程序中可以使用app.run()启动flask程序。
代码中使用@app.route(“/findall”)定义“/findall”的路由方法,其目的可以在地址栏输入“/findall”,最终映射到ES中索引文档employee中的全部数据,Elasticsearch类中传入了ES中的服务器地址,在findall接口对应的函数方法中,body定义了全部查询的参数,调用es.search方法,把body参数传入search方法中,并指定index索引的名称,查询成功后会返回json数据,调用json包的dumps方法把json数据作为字符串传到前端,ensure_ascii保持传输到前端后的编码保持utf8格式不变。这样访问后,就可以在浏览器中显示employee索引文档的全部json数据。如下图所示。
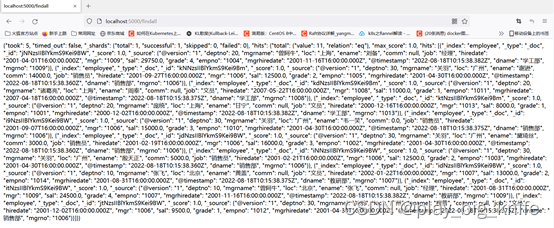
根据这样的思路,再定义一个路由对应的方法,查询按部门分组,找出部门内人数大于3的部门名称的相关指令传入body参数中,同样调用search方法,就可以定位到部门人数大于3人的结果数据。代码如下。
@app.route("/finddept")
def findDept():
body={
"size":0,
"aggs":{
"depts":{
"terms":{
"field":"deptno",
"min_doc_count":3
},
"aggs":{
"sample":{
"top_hits":{
"size":1,
"_source":["dname","loc"]
}
}
}
}
}
}
return json.dumps(es.search(index="employee",body=body),ensure_ascii=False)
对于分页信息而言,需要传入分页的参数,参数可以在地址栏中以page=1或page=2来传输,其地址传输格式如下。
http://localhost:5000/findAllByPage?page=1
地址格式中findAllByPage是路由的地址,“?”号后面page=1表示传入的参数值。在flask中可以使用request.args来接收page的参数值。然后将参数值转化为整型数并且减去1,因为如果page=1表示第1页的话,ES中索引0表示第一页,ES中索引1表示第二页,这样对应page的值就是第几页的基础上减去1,接下来从哪一个索引开始显示,根据每页显示几条数据,下一页显示的第一条数据必然是索引值和显示数据条数的乘积。这样,在query参数中,from表示从哪一个索引开始,计算式子应该是:(page-1)*size,计算式子中的size就是每页显示的数据条数。代码如下。
@app.route("/findByPage")
def findAllByPage():
pageId=request.args.get("page")
pageId=int(pageId)-1
body={
"query":{
"match_all":{}
},
"from":pageId*5,
"size":5
}
return json.dumps(es.search(index="employee",body=body),ensure_ascii=False)
这样,可以实现flask接口ES后返回前端全部索引文档的数据,分页显示的文档数据,按部门分组显示的文档数据等。整体代码如下。
from elasticsearch import Elasticsearch
from flask import Flask,request
import json
app=Flask(__name__)
es=Elasticsearch(["http://localhost:9200"])
@app.route("/findall")
def findall():
body={
"query":{
"match_all":{}
}
}
result=es.search(index="employee",body=body)
return json.dumps(result,ensure_ascii=False)
@app.route("/findByPage")
def findAllByPage():
pageId=request.args.get("page")
pageId=int(pageId)-1
body={
"query":{
"match_all":{}
},
"from":pageId*5,
"size":5
}
return json.dumps(es.search(index="employee",body=body),ensure_ascii=False)
@app.route("/finddept")
def findDept():
body={
"size":0,
"aggs":{
"depts":{
"terms":{
"field":"deptno",
"min_doc_count":3
},
"aggs":{
"sample":{
"top_hits":{
"size":1,
"_source":["dname","loc"]
}
}
}
}
}
}
return json.dumps(es.search(index="employee",body=body),ensure_ascii=False)
if __name__=="__main__":
app.run()
项目对应代码github地址:
https://github.com/wawacode/logstash_es_flask_project
项目视频地址:
https://www.bilibili.com/video/BV1s14y1t73c/













 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









