









一、前言
该推理框架的 baseline 和灵感,源于 Github 上的一个项目:
leafqycc/rknn-cpp-Multithreading: A simple demo of yolov5s running on rk3588/3588s using c++ (about 142 frames). / 一个使用c++在rk3588/3588s上运行的yolov5s简单demo(142帧/s)。![]() https://github.com/leafqycc/rknn-cpp-Multithreading 该项目描述清晰,代码整洁。我在部署过程中,遇到了一些编译错误和环境问题,不过这都是常规流程,在攻克了两天后,实现了本地的部署,并达到了作者的最高帧数:141帧(C++),python版本也做了一个快速部署,达到了最高 50 帧。
https://github.com/leafqycc/rknn-cpp-Multithreading 该项目描述清晰,代码整洁。我在部署过程中,遇到了一些编译错误和环境问题,不过这都是常规流程,在攻克了两天后,实现了本地的部署,并达到了作者的最高帧数:141帧(C++),python版本也做了一个快速部署,达到了最高 50 帧。
作者的目的是实现一个 demo,为更多开发者可以快速部署到自己的项目和工程中。我本人也一直在学习作者的编程逻辑以及各个部分的实现方式,尽可能的掌握每一个细节,当然线程池除外,现在看起来还是头大,哈哈哈。
我准备分两部分来讲解项目的设计框架,本篇为第一部分,主要介绍项目总览和加速效果,下一篇主要介绍代码的框架和实现细节。
第二部分:
二、项目贡献
从接触这个项目到完成现在的推理加速框架,断断续续也花了半年的时间。期间也一直在持续优化代码逻辑,并思考如何继续加速 YOLO 的推理速度,因此我的项目也主要在下面这两点做了改进:
1、完善代码框架,增加命令行参数解析、视频解码器的多态实现、OpenCL 可选、RGA 可选、软硬件加速可选以及一些内存管理的优化等。
2、添加硬件加速,使用 RKmpp 实现硬件视频解码、使用 RGA 接口实现 2D 图像缩放和颜色空间转换的硬件加速。
其中 RKmpp 使用 FFmpeg 接口实现,隐藏了 RKmpp 的接口,这样也可以提高项目的可复用性,例如有其他解码器的需求;RGA 则是在反复翻看官方手册和 librga 库的 demo 后,自己总结并编写的即插即用接口,不过目前主要以 OpenCV 的 cv::Mat 对象进行数据传输,RGA 也可以通过 FFmpeg 的过滤器实现,不过我个人觉得直接使用 RGA 接口更方便,效率也更高。
一些小项我也分别写了对应的文章,链接:
编译支持 RKmpp 和 RGA 的 ffmpeg 源码_rk3588 ffmpeg mpp-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146188927?spm=1001.2014.3001.5501C和C++语言应用程序解析命令行参数-CSDN博客
https://blog.csdn.net/plmm__/article/details/146188927?spm=1001.2014.3001.5501C和C++语言应用程序解析命令行参数-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146254801?spm=1001.2014.3001.5501香橙派5Plus使用rkmpp硬件解码的速度优化与输出格式更改-CSDN博客
https://blog.csdn.net/plmm__/article/details/146254801?spm=1001.2014.3001.5501香橙派5Plus使用rkmpp硬件解码的速度优化与输出格式更改-CSDN博客![]() https://blog.csdn.net/plmm__/article/details/146524675?spm=1001.2014.3001.5501 我在 Github 上也在源项目中提了一个 Issue,既是一封感谢信,也是一份引用通知,希望能为开源社区做贡献。
https://blog.csdn.net/plmm__/article/details/146524675?spm=1001.2014.3001.5501 我在 Github 上也在源项目中提了一个 Issue,既是一封感谢信,也是一份引用通知,希望能为开源社区做贡献。
三、加速效果
这里的所有实验效果都是没有优化模型的输入尺寸和网络结构本身,和原作者使用相同的 rknn 模型文件和图像输入参数,这样方便观察硬件加速的效果。
方案1:开启多线程
下面是使用 OpenCV 读取视频,软件 OpenCV 进行图像变换的实拍,以及 CPU、GPU 和 NPU 的占用率:
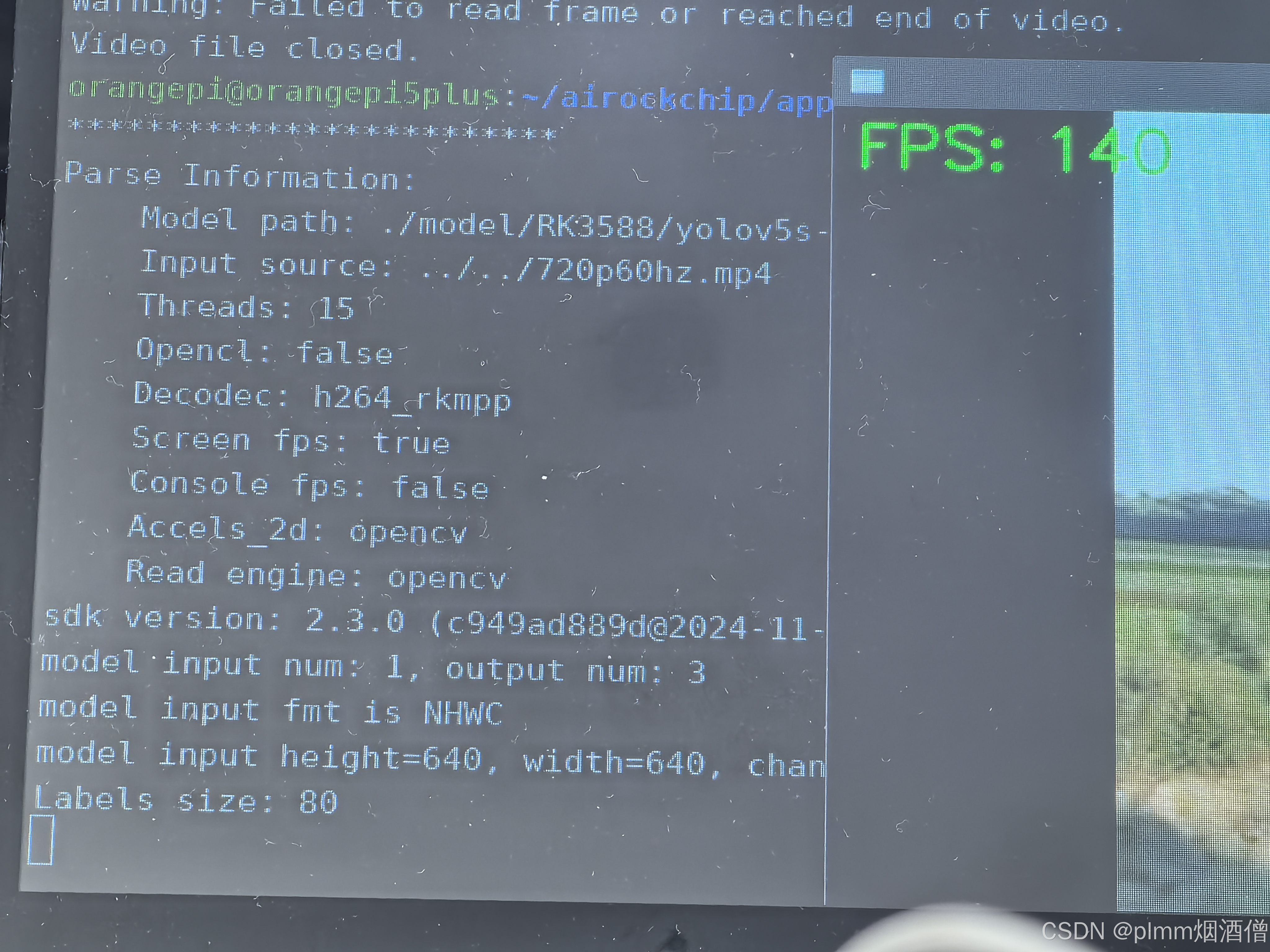

该情况就是原作者的多线程加速方案,约 141 帧。虽然我的截图中,解码器为 h264_rkmpp,但只要读取视频的方式改为 Opencv,就不会使用到 h264_rkmpp 硬件解码。
使用 15 个推理线程(继续增加没有明显变化),CPU 利用率 65,NPU 三核占用率 85-88 。另外,开关 OpenCL 对帧率的影响不大,这个在后期wo想深入研究一下 OpenCV 是如何调用 OpenCL 的。
方案2:开启 RKmpp 硬件解码和多线程
下面是将 OpenCV 读取视频,更换为 FFmpeg 调用 RKmpp 接口调用 VPU 硬件进行解码的实拍,以及 CPU、GPU 和 NPU 的占用率:
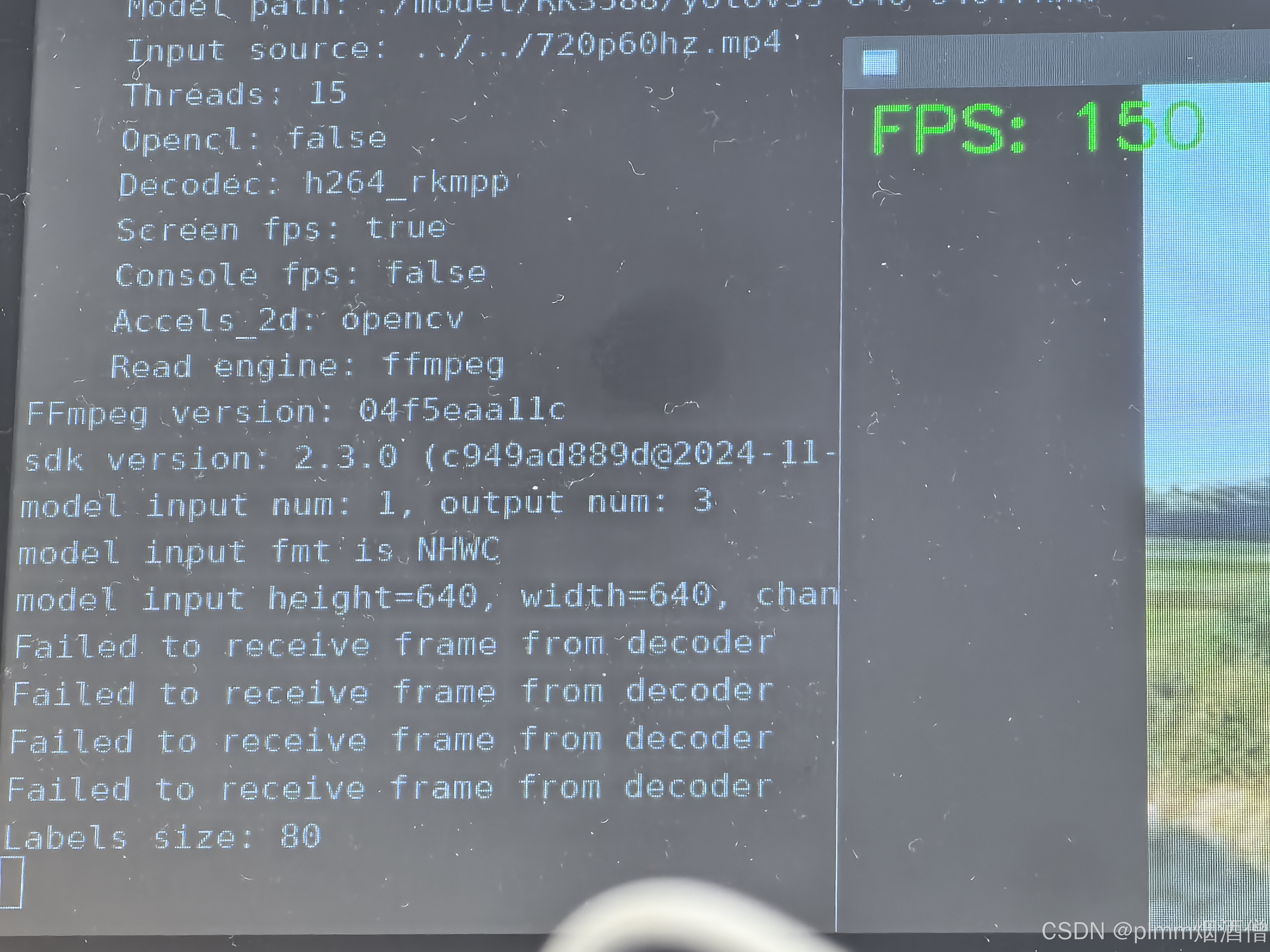

帧率稳定在 150 帧左右,相比第一个方案提高了 10 帧。
使用 15 个推理线程(继续增加没有明显变化),CPU 利用率 65,NPU 三核均到 90 以上。VPU 的服务也有 10 个,说明硬件解码正常并且是多线程:
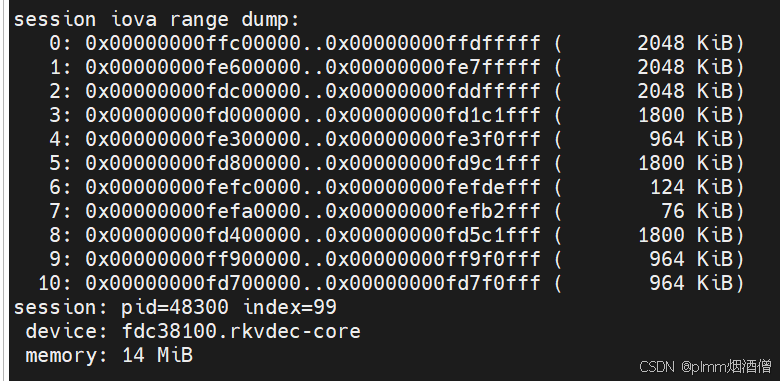
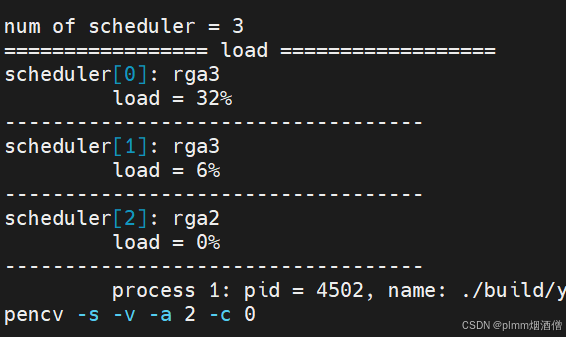
方案3:开启 RGA 加速和多线程
下面是使用 OpenCV 读取视频,并将图像的格式转换、缩放等图像操作从 OpenCV 更换为 RGA 接口的实拍,以及 CPU、GPU 和 NPU 的占用率:
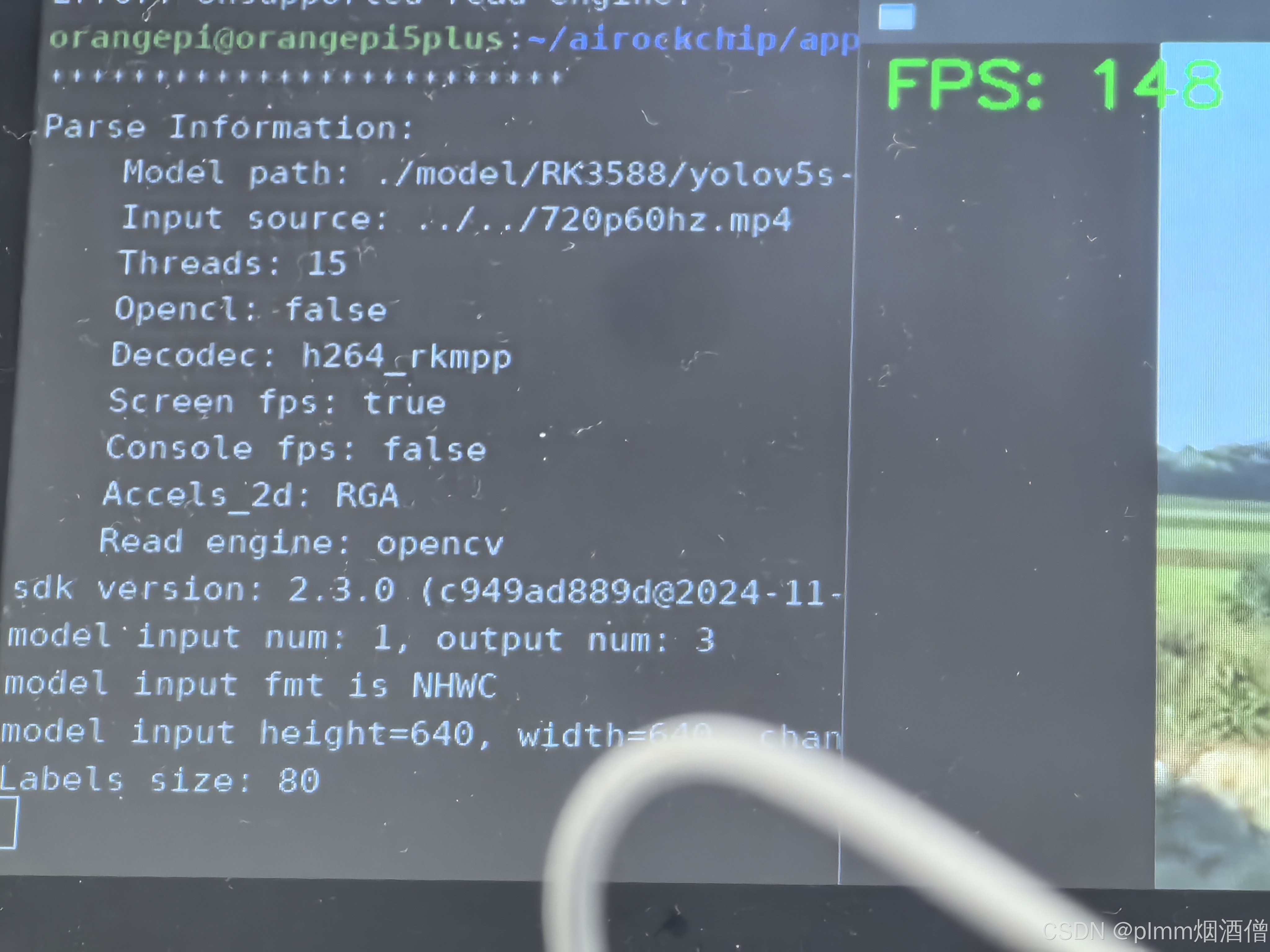

帧率稳定在 147 帧,最高 148 帧,相比第一个方案提高了 7 帧。
使用 15 个推理线程(继续增加没有明显变化),CPU 利用率 60,NPU 三核在 90 上下浮动。下面是 RGA 的使用情况:
方案4:开启硬件解码, RGA 加速和多线程
这个组合方式本应该是最快的方案,但是同时开启硬件解码和 RGA 加速,帧率就下降:


使用 15 个推理线程(继续增加没有明显变化),帧数稳定在 139 帧左右,反倒是等于没有使用硬件加速,与第一种方案的结果相近。
不过好消息是,相比于第一个方案,CPU 和 NPU 的占用率都有下降,CPU 占用率下降了约 21 个百分点,NPU 下降约 8 个百分点,这说明方案4的上限还没到,还有优化的空间。下面是 RGA 的使用情况,使用率与之前保持相同:

第四个实验的具体分析,我准备单独写一篇文章,详细分析我做的对比实验,并讲解设计理念,其中涉及到 RGA 接口的不同实现方式。
四、结果分析
前三个实验结果表明,使用硬件加速均能提高 YOLO 在推理过程中的速度。分别使用 RKmpp 和 RGA 在视频读取和前处理时进行硬件加速,比 OpenCV 的软件解码和软件图像操作均有提高。
希望本项目可以帮助有需要的读者,可以参考并与我讨论,持续优化项目的加速方案。
Gitee链接:
GitCode:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











