




 布隆过滤器是一种节省空间的概率数据结构,用于检查元素是否存在,可能存在误判但不支持删除。其特点是快速、低内存占用,常用于URL去重、垃圾邮件过滤和缓存安全。初始化时,根据预期插入数量和错误率计算所需哈希函数和内存。插入和检查元素通过哈希函数映射到二进制数组,误判率随元素增加而上升。Redis提供了布隆过滤器插件,便于在缓存系统中使用。
布隆过滤器是一种节省空间的概率数据结构,用于检查元素是否存在,可能存在误判但不支持删除。其特点是快速、低内存占用,常用于URL去重、垃圾邮件过滤和缓存安全。初始化时,根据预期插入数量和错误率计算所需哈希函数和内存。插入和检查元素通过哈希函数映射到二进制数组,误判率随元素增加而上升。Redis提供了布隆过滤器插件,便于在缓存系统中使用。
什么是布隆过滤器
布隆过滤器(Bloom filter)是一种非常节省空间的概率数据结构,运行速度快,占用内存小,但是有一定的误判率且无法删除元素。本质上由一个很长的二进制向量和一系列随机映射函数组成。
布隆过滤器有什么特性
1、用于检查一个元素是否在集成中,检查结果分为2种:不存在,可能存在;
2、支持添加元素、检查元素,但是不支持删除元素;
3、可能存在有一定误判率;
4、相比set、Bitmaps非常节省空间:因为只存储了指纹信息,没有存储元素本身;
5、添加的元素超过预设容量越多,误报的可能性越大。
布隆过滤器的应用
网页爬虫对URL的去重,避免爬取相同的URL地址;
反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱;
缓存击穿,将已存在的缓存放到布隆过滤器中,当访问不存在的缓存时迅速返回避免缓存及DB挂掉。
所以,在游戏中,布隆过滤器是非常适合用来防止缓存击穿的一个工具,因为上线的游戏都会接入GameManageControl,一般用于游戏运营,这些接口经常会输入一些错误的玩家ID到游戏服,而没有布隆过滤器的阻拦,这种错误的uid会直接访问到DB,是一件非常危险的事情。且游戏中也会开放一些玩家搜索之类的功能,总而言之,一切第三方可输入玩家ID的地方,都需要加布隆过滤器判断,才能保证我们游戏的安全。
布隆数据结构原理图
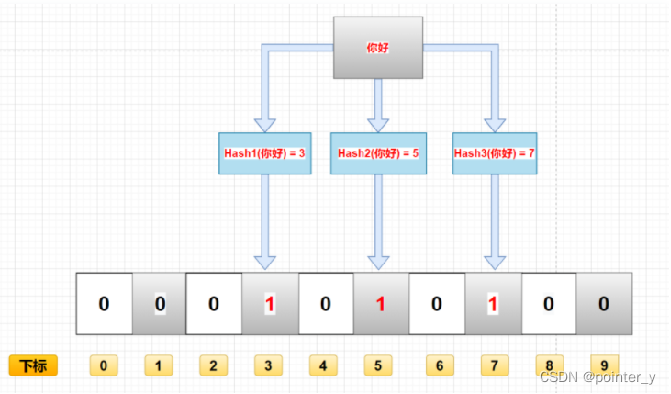
布隆数据结构的原理是这样的:假设有字符串“你好”要放进布隆过滤器中,“你好”字符串会经过N个哈希函数,计算出N个对应的数组位,并将对应的这些位设置为1,这样“你好”就被插入到了布隆过滤器中,当检查“你好”是否存在于布隆过滤器中时,又会经过同样的哈希函数计算出位置,检查对应的位置是否是1,如果所有计算出来的位置都是1,则认为“你好”是存在于布隆过滤器中的。所以,当越来越多的数据插入布隆中时,数组里被设置为1的位越来越多,就有可能出现某个数据经过哈希函数计算后的几个位置都已经被设置为1了,那么就会误判这个数据是存在的,我们称发生了哈希碰撞,哈希碰撞是不可百分百避免的,布隆过滤器对这种误判率称之为假阳性概率或者错误率,在实践过程中,我们可以自己定义这个错误率,布隆会根据我们定义的错误率计算出需要的哈希函数数量。
Redis布隆插件源码分析
struct bloom {
uint32_t hashes; //哈希 bpe*ln(2) 进行多少次哈希
uint8_t force64; //强制64位
uint8_t n2; //取模使用,64和32的取模
uint64_t entries; //预期插入的条目数量
double error; //错误率(碰撞概率)
double bpe; //字节对编码
unsigned char *bf; //过滤器字符串,存储数据的地方,hash取模后存储在这里
uint64_t bytes; //字节数
uint64_t bits; //位数
};
typedef struct SBLink {
struct bloom inner; //< bloom内部结构
size_t size; // < 链接中的项目数
} SBLink;
typedef struct SBChain {
SBLink *filters; //< 当前过滤器
size_t size; //< 所有过滤器中的项目总数
size_t nfilters; //< 链节数
unsigned options; //< 直接传递给bloom_init的选项
} SBChain;
基本数据结构bloom是一个struct结构体
主要的成员:hashes是哈希函数数量,entries是我们预期的插入数量,error是预设的错误率,bf就是存储指纹信息的地方,接着将bloom结构体封装为SBLink,存储了当前布隆过滤器中的数据量。因为布隆过滤器在插入数据量超过预设数量时要进行扩容和分层,所以他这里继续封装出SBChain,filters是一个数组指针,存放多层布隆过滤器的首地址,所以可以访问到多层的布隆过滤器,这里记录了所有过滤器中的数据总量以及链接数目。
int bloom_init(struct bloom *bloom, uint64_t entries, double error,
unsigned options) {
if (entries < 1 || error <= 0 || error >= 1.0) {
return 1;
}
bloom->error = error;
bloom->bits = 0;
bloom->entries = entries; //预设容量
bloom->bpe = calc_bpe(error); //预设错误率
uint64_t bits;
if (options & BLOOM_OPT_ENTS_IS_BITS) {
if (/* entries == 0 || */ entries > 64) {
return 1;
}
bloom->n2 = entries;
bits = 1LLU << bloom->n2;
bloom->entries = bits / bloom->bpe;
} else if (options & BLOOM_OPT_NOROUND) {
bits = bloom->bits = (uint64_t)(entries * bloom->bpe);
bloom->n2 = 0;
}
else { double bn2 = logb(entries * bloom->bpe);
if (bn2 > 63 || bn2 == INFINITY) {
return 1;
}
bloom->n2 = bn2 + 1;
bits = 1LLU << bloom->n2;
size_t itemDiff = bitDiff / bloom->bpe;
bloom->entries += itemDiff;
}
if (bits % 64) {
bloom->bytes = ((bits / 64) + 1) * 8; //对齐
} else {
bloom->bytes = bits / 8;
}
bloom->bits = bloom->bytes * 8;
bloom->force64 = (options & BLOOM_OPT_FORCE64);
bloom->hashes = (int)ceil(0.693147180559945 * bloom->bpe); // ln(2) 哈希函数数量由错误率计算得来
bloom->bf = (unsigned char *)BLOOM_CALLOC(bloom->bytes, sizeof(unsigned char)); //申请数组空间
if (bloom->bf == NULL) {
return 1;}
return 0;
}
布隆的初始化接口,首先对预设数据量和错误率进行合法性检查,接着是根据预设进行赋值和计算,options通过每个位可以定义不同初始化选项,比如这个IsBits的宏意思是Entries 实际上是位数,而不是要保留的条目数,这个选项不常用,这里计算初始化时的比特大小,可以看到预设容量和错误率都会影响初始化比特,计算完再进行一次字节对齐,这里计算哈希函数数量并赋值,这个哈希函数数量的计算方式实际上就是应用了数学上对于布隆过滤器的推导公式。
//检查链条值是否存在
int SBChain_Check(const SBChain *sb, const void *data, size_t len) {
bloom_hashval hv = SBChain_GetHash(sb, data, len);
for (int ii = sb->nfilters - 1; ii >= 0; --ii) {
if (bloom_check_h(&sb->filters[ii].inner, hv)) {
return 1;
}
}
return 0;
}
//通过hash值,计算映射到字符串的具体字节
int bloom_check_h(const struct bloom *bloom, bloom_hashval hash) {
if (bloom->n2 > 0) {
if (bloom->force64 || bloom->n2 > 31) {
return bloom_check_add64((void *)bloom, hash, MODE_READ);
} else {
return bloom_check_add32((void *)bloom, hash, MODE_READ);
}
} else {
return bloom_check_add_compat((void *)bloom, hash, MODE_READ);
}
}
#define CHECK_ADD_FUNC(T, modExp) \
T i; \
int found_unset = 0; \
const register T mod = modExp; \
for (i = 0; i < bloom->hashes; i++) { //取hashes次index设置位 \
T x = ((hashval.a + i * hashval.b)) % mod; \
if (!test_bit_set_bit(bloom->bf, x, mode)) { \
if (mode == MODE_READ) { \
return 0; \
} \
found_unset = 1; \
} \
} \
if (mode == MODE_READ) { \
return 1; \
} \
return found_unset;
static int bloom_check_add32(struct bloom *bloom, bloom_hashval hashval, int mode) {
CHECK_ADD_FUNC(uint32_t, (1 << bloom->n2));
}
static int bloom_check_add64(struct bloom *bloom, bloom_hashval hashval, int mode) {
CHECK_ADD_FUNC(uint64_t, (1LLU << bloom->n2));
}
这里是布隆过滤器的插入和检查逻辑,前面用你好举例的时候,我们知道插入和检查数据是否存在实际上都是同样的步骤,所以这里插入和检查底层都调用到了同一个接口,同操作模式只读或者写入来区分是否修改数据。检查data是否存在于sb中,先根据哈希函数计算出data的基础哈希值,这个bloom_hash_val结构实际上只计算出了两个哈希值,但是我们前面看到哈希函数数量是由公示计算出来的,有可能有非常多的哈希函数,但是这里却只有两个哈希值,实际上他是通过双重哈希实现的,使用了两个固定的哈希函数,生成任意多个哈希值。遍历多层布隆过滤器,存在返回1,不存在返回0,他使用的哈希函数库是Murmurhash2这个库,感兴趣的话大家可以自己去看。
inline static int test_bit_set_bit(unsigned char *buf, uint64_t x, int mode) {
uint64_t byte = x >> 3; //计算unsigned char的位置
uint8_t mask = 1 << (x % 8);//计算掩码
uint8_t c = buf[byte]; //取出对应的unsigned char
if (c & mask) { //如果位置本来就是1直接返回1
return 1;
} else {
if (mode == MODE_WRITE) {
buf[byte] = c | mask; //将目标位置为1
}
return 0; //返回原来的值
}
}为什么使用static修饰:
如果使用者跳过bloom_add和bloom_check直接调用test_bit_set_bit函数,就相当于给了用户直接修改bitmap任意一位的权限,这会导致检查元素是否存在失效,此外,bloom_check_add这是个中间函数,也不希望用户调用它。虽然它们并没有加入到头文件中,但是用户仍然可以使用extern关键字访问到它们,故需要添加static关键字,使这两个函数只能对本文件的其它函数可见
为什么使用inline:
test_bit_set_bit函数将在bloom_check_add函数中调用多次,函数执行过程中的压栈和出栈会及其消耗资源,所以我们使用inline关键字将其申明为一个内联函数,使其直接在bloom_check_add中展开,以代码拷贝的代价换取效率的提升。
置1:
hashcode = byte * 8 + bit
hashcode:计算出来的哈希值
byte:所在unsigned char的下标
bit:在unsigned char的位置
bit = hashcode % 8;
byte = (hashcode - bit) / 8;
二进制:
hashcode = byte << 3 + bit
byte = hashcode >> 3
bit = hashcode % 8
对于置1操作,我们需要把输入的哈希值作为下标,找到bitmap的相应位置,然后通过某种方式改变那一位的值,其它位保持不变。对于取值操作,我们同样需要先找到相应的位,然后获得那一位的值,所有值保持不变。对于找到要操作的那一位,如果bitmap存储在一个bit数组中的时,这个操作会很简单,直接传入哈希值作为下标即可,但是由于C语言的限制,只能将bitmap以unsigned char数组的形式存储,那么我们只能先找到该位所在的unsigned char,再从此unsigned char中找到那一位,很容易地,我们就可以发现, bit是 hashcode 除以8的一个余数,那么 byte 就是hashcode 减去 bit 除以8,但是除法效率比较低,改成二进制之后,hashcode是byte左移三位再加bit得到的,那以此类推,byte就可以通过hashcode右移三位得到,空出来的左边三位因为是无符号整形会被0填充。这样就得到了所在字节和具体的位,我们可以将一个unsigned char 按位或 上一个第bit位为1,其它位是0的掩码,来进行置1操作。
测试
当需要的误差范围越精确时,哈希函数数量和内存都会有所增长 占用内存大小和预期插入数据数量以及错误率相关 哈希函数数量和错误率相关
| 误差 | 容量 | 占用内存 | Hash函数数量 |
| 0.0001 | 60000000 | 147.43433 | 15 |
| 0.00001 | 60000000 | 181.71317 | 18 |
| 0.000001 | 60000000 | 215.992 | 21 |
| 0.0001 | 100000000 | 245.72387 | 15 |
| 0.00001 | 100000000 | 302.85527 | 18 |
| 0.000001 | 100000000 | 359.98667 | 21 |
应用
redis以插件形式提供布隆过滤器,需要升级redis版本到4.0以上,安装布隆过滤器插件,在配置中加载,重启redis即可。
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.2.tar.gz
tar v2.2.2.tar.gz cd RedisBloom-2.2.2
make
cp redisbloom.so /usr/local/lib64/
找到redis.conf,加载布隆过滤器模块
loadmodule /usr/local/lib64/redisbloom.so

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









