







1. 来由
为什么要写提取注释呢,起因是工作需要。弄这么个不太重要的功能点来讲,旨在抛砖引玉。
一般而言,大家使用antlr解析源代码的时候,不会关心注释和空格之类内容,默认会过滤掉,不会放到语法树里,讲了,真把空格这类东西保留在语法树里,会带来很多问题。要保留注释的话,也不会放进语法树里,而是会导流到不同的channel里。channel可以理解为不同的管道,源文件解析后的token会通过默认管道,而注释等其它一些元素,可以导流到自定义管道。这样既不会给解析带来额外负担,也不会丢弃任何内容。
2. 抽取注释
闲话少说,怎么提取代码里的注释呢,在 12.1 Broadcasting Tokens on Different Channels这一节专门有讲。
2.1 语法定义-导流
首先在语法文件里进行不同channel的导流定义:
先看默认的,直接扔掉了:
WS : [\t\n\r]+ -> skip
SL_COMMENT
: '//' .*? '\n' -> skip
;重新定义-导流:
@lexer::members{
public static final int WHITESPACE = 1;
public static final int COMMENTS = 2;
}
WS : [ \t\n\r]+ -> channel(WHITESPACE); //channel(1)
SL_COMMENT
: '//' .*? '\n' -> channel(COMMENTS) //channel(2)
;效果如下图所示,默认的是channel 0,其它用户自定义的都是hidden channel:
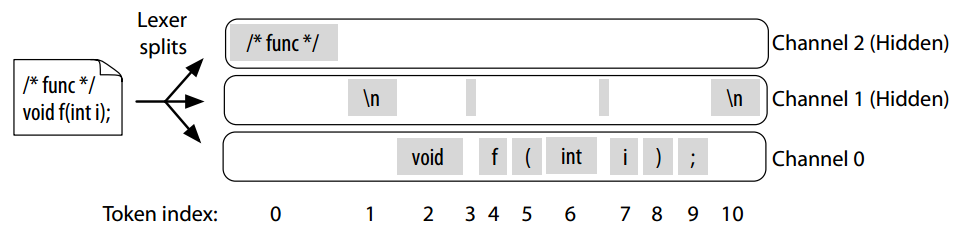
2.2 按规则(位置)提取
下面是12.1节里的示例,为什么说按位置提取呢,因为它是按照某个具体的规则定义来抽取注释的。示例代码是要将变量定义右侧的注释,挪动到代码行的上面。

具体实现:
/***
* Excerpted from "The Definitive ANTLR 4 Reference",
* published by The Pragmatic Bookshelf.
* Copyrights apply to this code. It may not be used to create training material,
* courses, books, articles, and the like. Contact us if you are in doubt.
* We make no guarantees that this code is fit for any purpose.
* Visit http://www.pragmaticprogrammer.com/titles/tpantlr2 for more book information.
***/
import org.antlr.v4.runtime.*;
import org.antlr.v4.runtime.tree.ParseTreeWalker;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.List;
public class ShiftVarComments {
public static class CommentShifter extends CymbolBaseListener {
BufferedTokenStream tokens;
TokenStreamRewriter rewriter;
/** Create TokenStreamRewriter attached to token stream
* sitting between the Cymbol lexer and parser.
*/
public CommentShifter(BufferedTokenStream tokens) {
this.tokens = tokens;
rewriter = new TokenStreamRewriter(tokens);
}
@Override
public void exitVarDecl(CymbolParser.VarDeclContext ctx) {
Token semi = ctx.getStop();
int i = semi.getTokenIndex();
List<Token> cmtChannel =
tokens.getHiddenTokensToRight(i, CymbolLexer.COMMENTS);
if ( cmtChannel!=null ) {
Token cmt = cmtChannel.get(0);
if ( cmt!=null ) {
String txt = cmt.getText().substring(2);
String newCmt = "/* " + txt.trim() + " */\n";
rewriter.insertBefore(ctx.start, newCmt);
rewriter.replace(cmt, "\n");
}
}
}
}
public static void main(String[] args) throws Exception {
String inputFile = null;
if ( args.length>0 ) inputFile = args[0];
InputStream is = System.in;
if ( inputFile!=null ) {
is = new FileInputStream(inputFile);
}
ANTLRInputStream input = new ANTLRInputStream(is);
CymbolLexer lexer = new CymbolLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CymbolParser parser = new CymbolParser(tokens);
RuleContext tree = parser.file();
ParseTreeWalker walker = new ParseTreeWalker();
CommentShifter shifter = new CommentShifter(tokens);
walker.walk(shifter, tree);
System.out.print(shifter.rewriter.getText());
}
}
从上述代码可以看到,CommentShifter继承listener模式,重载了exitVarDecl方法。在遍历parse tree的时候,会自动调用exitVarDecl,完成了注释顺序改写功能。exitVarDecl对应了语法文件里面的变量定义规则,每当有变量定义的时候,就会调用该方法。
2.3 按channel提取所有注释
上面的注释提取方法有个问题,就是只能提取相应规则的注释。函数有注释,类有注释,参数可能有注释,等等,还有很多别的地方,如果都提取的话,则要费一番周折,弄上一堆函数定义。
如果不关心注释所在的具体规则,只提取注释的话,可以遍历token,通过判断token所在的channel来实现。语法文件里将注释导流到channel(2),那么凡是channel值为2的token则为注释,这就好办了。
private static void printComments(String code){
CPP14Lexer lexer = new CPP14Lexer(new ANTLRInputStream(code));
CommonTokenStream tokens = new CommonTokenStream(lexer);
List<Token> lt = tokens.getTokens();
for(Token t:lt){
// if t is on channel 2 which is comments channel(configured in grammar file)
// simply pass t, otherwise for two adjacent comments line the first comment line will
// appear twice
if(t.getChannel() == 2) continue;
// getHiddenTokensToLeft will suffice to get all comments
// no need to call getHiddenTokensToRight
int tokenIndex = t.getTokenIndex();
List<Token> comments = tokens.getHiddenTokensToLeft(tokenIndex);
if(comments != null && comments.size() > 0){
for(Token c:comments){
System.out.println(" " + c.getText());
}
}
}
}

















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









