









上期与大家分享的传统分类算法都是建立在判别函数的基础上,通过判别函数值来确定目标样本所属的分类,这类算法有个最基本的假设:线性假设。今天继续和大家分享下比较现代的分类算法:决策树和神经网络。这两个算法都来源于人工智能和机器学习学科。
首先和小伙伴介绍下数据挖掘领域比较经典的Knn(nearest neighbor)算法(最近邻算法)
算法基本思想:
Step1:计算出待测样本与学习集中所有点的距离(欧式距离或马氏距离),按距离大小排序,选择出距离最近的K个学习点;
Step2:统计被筛选出来的K个学习点,看他们在分类中的分布,频数最大的分类及为待测点的分类;
决策树(Decision tree)
该算法主要来源于人工智能,常用语博弈论,基本逻辑如下图(解释女网友见男网友的决策过程)。决策数学习集的属性可以是非连续的,可以是因子,也可以逻辑是非等。决策过程中需要找到信息增益最大的属性作为根节点,然后逐级找出信息增益次小的属性,作为下一层决策点,逐级按照信息增益排列的所有属性,即可做出决策树。目前用的最多的ID3和其后续升级版。
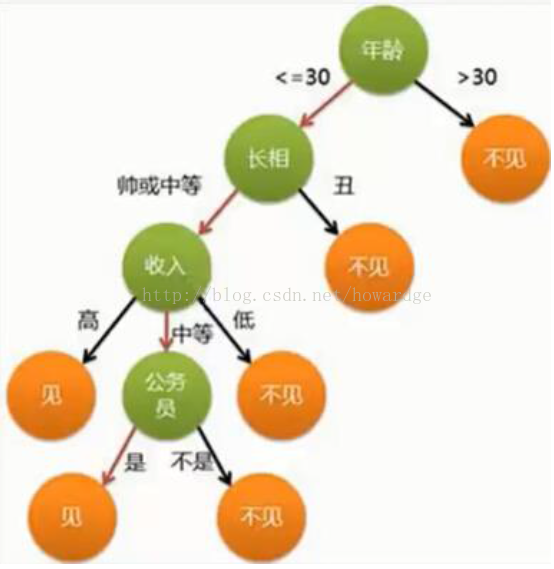
现在我们来看看如何用R帮我们做决策树分析,我们借助鸢尾花数据集来做,同时我们需要导入rpart包来做决策树分析:
install.packages("rpart")
library(rpart)
iris.rp=rpart(Species~.,data=iris,method="class")
plot(iris.rp,uniform=T,branch=0,margin=0.01,main="DecisionTree")
text(iris.rp,use.n=T,fancy=T,col="blue")结果如下图:

人工神经网络
ANN(Artificial NeuralNetWorks)

通过学习集构造出一个模型(感知器:如下图),图中0.3即为该分支的权值,0.4为偏置因子(t), sum求和为本例的激活函数(也可是其他函数:三角,指数等),人工神经网络也就是通过学习集来修正权值,通过负反馈过程进行,具体算法如下:
Step1:另D={(xi,yi)|i=1,2…n}作为训练集;
Step2:随机生成初始权值向量w;
Step3: for 每一个训练集
计算输出预测yyi
For 每个权值wj
更新权值wj(k+1)=wj(k)+a(yi-yyi(k))*xij
EndFor
endFor
until满足终止条件
Ps: a 为学习效率,通常是是一个较小的数字
显示的问题往往比较复杂,需要构造多层神经网络如下图:

接下来给小伙伴们分享下R语言如何实现人工神经网络分析,我们需要安装AMORE包,我们就解决上文提到的3个变量分类y 的案例:
library(AMORE)
x1=c(1,1,1,1,0,0,0,0)
x2=c(0,0,1,1,0,1,1,0)
x3=c(0,1,0,1,1,0,1,0)
y=c(-1,1,1,1,-1,-1,1,-1)
p<-cbind(x1,x2,x3)
target=y
net <- newff(n.neurons=c(3,1,1),learning.rate.global=1e-2,
momentum.global=0.4,error.criterium="LMS",Stao=NA,hidden.layer="tansig",output.layer="purelin",method="ADAPTgdwm")# n.neurons=c(输入节点个数,……中间节点,输出节点个数), error.criterium="LMS"判断收敛的依据,最小平均平方法,hidden.layer="tansig"隐藏层的激活函数,output.layer="purelin"输出层的哦激活函数
result <- train(net,p,target,error.criterium="LMS",report=TRUE,show.step=100,n.shows=5)
z<-sim(result$net,p)
输出结果见下图:
其中Z看符号变可区分,对比Z 和Y,发现神经网络得出的结果和目标值100%吻合。

由此,我们可以看出人工神经网络的强大魅力,我们可以不用去弄明白内部具体算法原理,我们只需要确定输入输出和设置相应的节点便可以轻松完成分类。对于隐藏层个数设置我们需要做一定的分析,并非隐藏层数越多,模型越精确,原因有两个:
1、 对于问题规模不那么复杂时,较多的隐藏层会浪费我们过多没有必要的时间;
2、 隐藏层越多确实可以给我们带来更好的拟合效果,但需要注意的是,对学习集的过度拟合会造成预测时的巨大误差。
神经网络的黑箱性是把双刃剑,一方面黑箱给我们带来很大的方便;但另一方面黑箱的隐藏性让我们无法把控,得出的模型无法和业务结合做解释,因此神经网络需要新的思路来重构算法,Hopfield神经网络的出现就解决了早期神经网络的黑箱性和过度拟合等缺点。
关于Hopfield大家就自己百度试试吧,住大家好运 。
。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









