







 本文介绍了如何在AutoDL平台上利用WebUI进行GPT-SoVITS的中文语音合成,包括数据预处理、微调训练以及通过官方和用户提供的API进行推理的过程。作者还提到了使用GPT-SoVITS替代OpenAITTS的解决方案和参考的网络资源。
本文介绍了如何在AutoDL平台上利用WebUI进行GPT-SoVITS的中文语音合成,包括数据预处理、微调训练以及通过官方和用户提供的API进行推理的过程。作者还提到了使用GPT-SoVITS替代OpenAITTS的解决方案和参考的网络资源。
OpenAI官方的TTS模型我在这篇博文中给出了使用教程:ChatGPT 3.5 API的调用不全指南(持续更新ing…) - 知乎
但是OpenAI的TTS对中文支持不好,有一种老外说中文的美,所以本文介绍另一个工具GPT-SoVITS。
主要功能是提供声音示例进行微调或者直接少样本生成。
GitHub仓库:https://github.com/RVC-Boss/GPT-SoVITS
中文文档:https://github.com/RVC-Boss/GPT-SoVITS/blob/main/docs/cn/README.md
详细的官方教程:GPT-SoVITS指南
目前本博文仅更新了在AutoDL云服务器上直接用WebUI实现数据预处理、微调和测试,以及获得模型权重后如何调用API进行推理(仅更新了使用官方提供的api.py服务的方案)的简洁教程,更多细节请静待后续更新!
文章目录
1. 直接用WebUI:AutoDL版
这一部分主要参考官方教程中的:AutoDL教程(只要几块钱,方便)
官方提供了一个搭好的社区环境,可以在AutoDL上租个云服务器直接用。直接用这个环境创建实例即可:https://www.codewithgpu.com/i/RVC-Boss/GPT-SoVITS/GPT-SoVITS-Official
打开AutoPanel绑定百度网盘(或者阿里云盘)
下载微调数据(我在这里上传了一个mp4文件)
AutoDL公网网盘帮助文档:https://www.autodl.com/docs/netdisk/
AutoPanel也可以在后续工作流程中检测服务器的内存啊之类的用
打开JupyterLab运行如下代码打开WebUI:echo {}> ~/GPT-SoVITS/i18n/locale/en_US.json && source activate GPTSoVits && cd ~/GPT-SoVITS/ && python webui.py
打开public URL
1. 处理数据集
开启UVR5-WebUI实现人声分离:
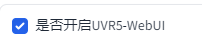
这一步我没做是因为我的训练数据很干净。所以我跳过了这一步。如果以后要用到这一步我再补充本博文内容。
处理完记得把UVR5关了。
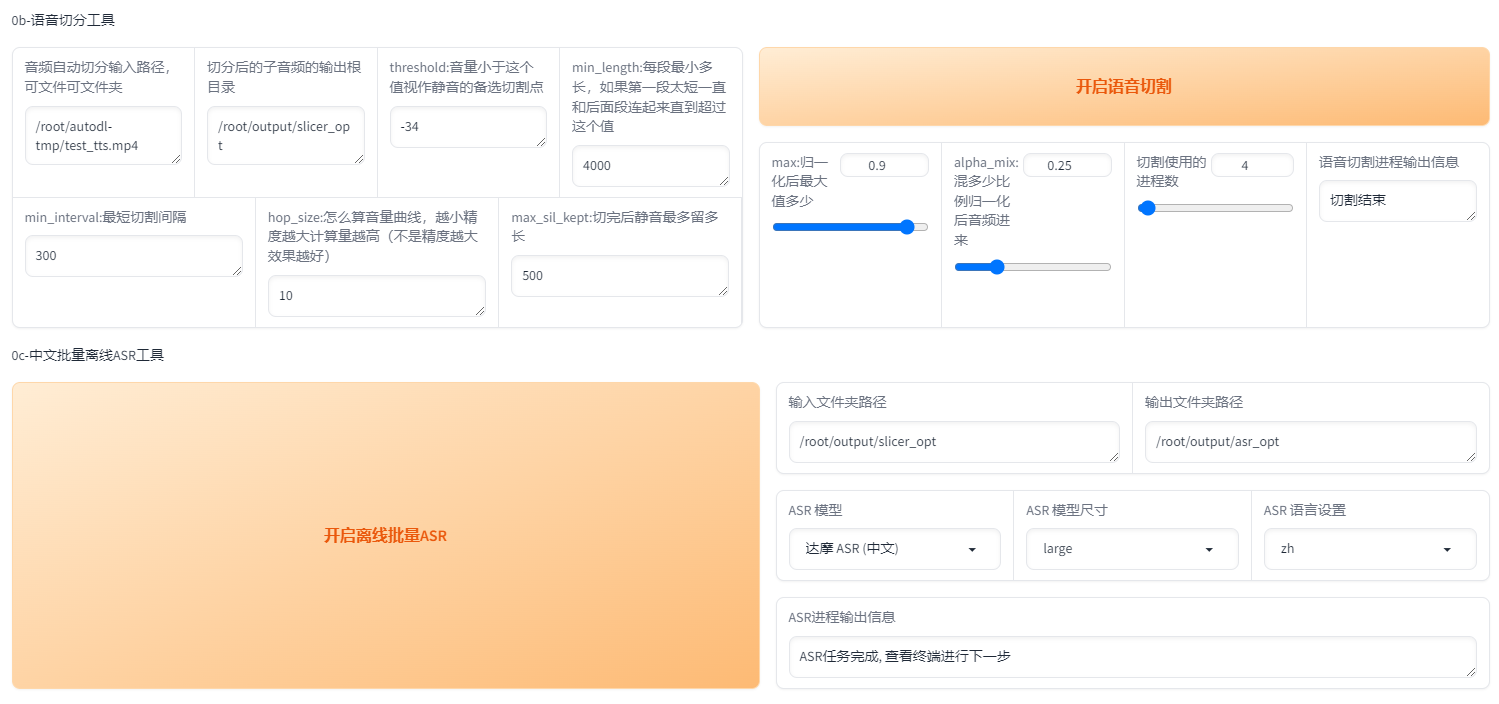
输入上传音频的路径:/root/autodl-tmp/test_tts.mp4
输出前面也要加/root/(也就是说得用绝对路径):/root/output/slicer_opt
开启语音切割
这一步后得到了一堆wav文件,每个文件是切出的小片音频。
ASR(语音转文字)自动打标:
输入文件夹就是那个输出文件夹。输出文件夹依然要加/root/
开启批量ASR
这一步后得到一个list文件,是每个音频对应的自动识别的文字
还有一步是校对,就是打开自动标注结果在标注工具中进行校对。这里因为我懒得搞了所以暂时省略,下次可能会补。
2. 微调训练
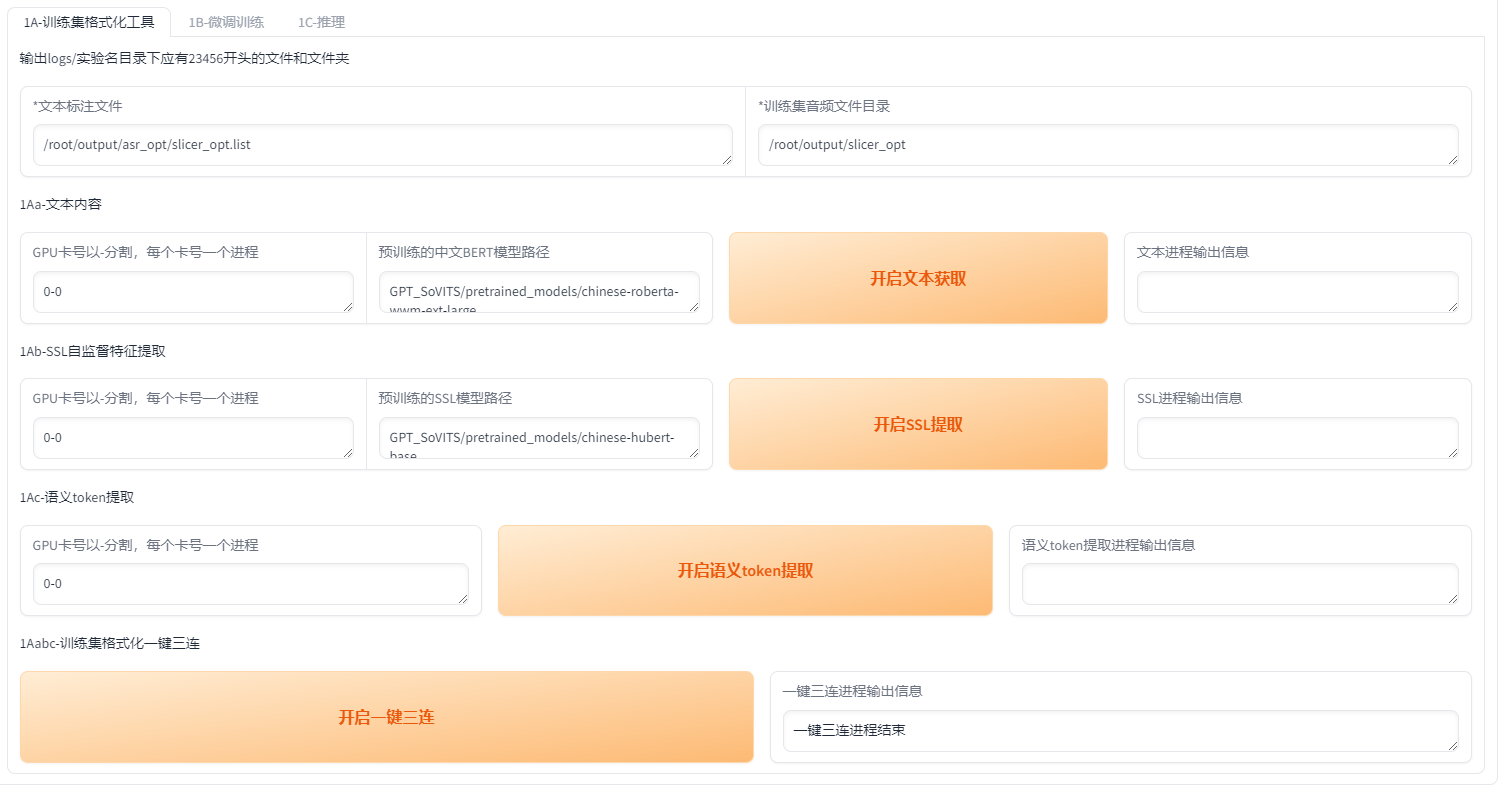
1. 训练集格式化工具
不能使用中文
文本标注文件,使用处理后的结果:/root/output/asr_opt/slicer_opt.list
训练集音频文件目录,使用处理后的结果:/root/output/slicer_opt
直接开启一键三连就可以
结束时会显示一键三连进程结束
2. 微调训练
开启SoVITS训练(这个比较快啦,我1小时的视频切出647个音频文件,训练1个epoch不到1分钟)
输出SoVITS训练完成结束

(GPT训练也差不多,但是GPT训练会慢一些)
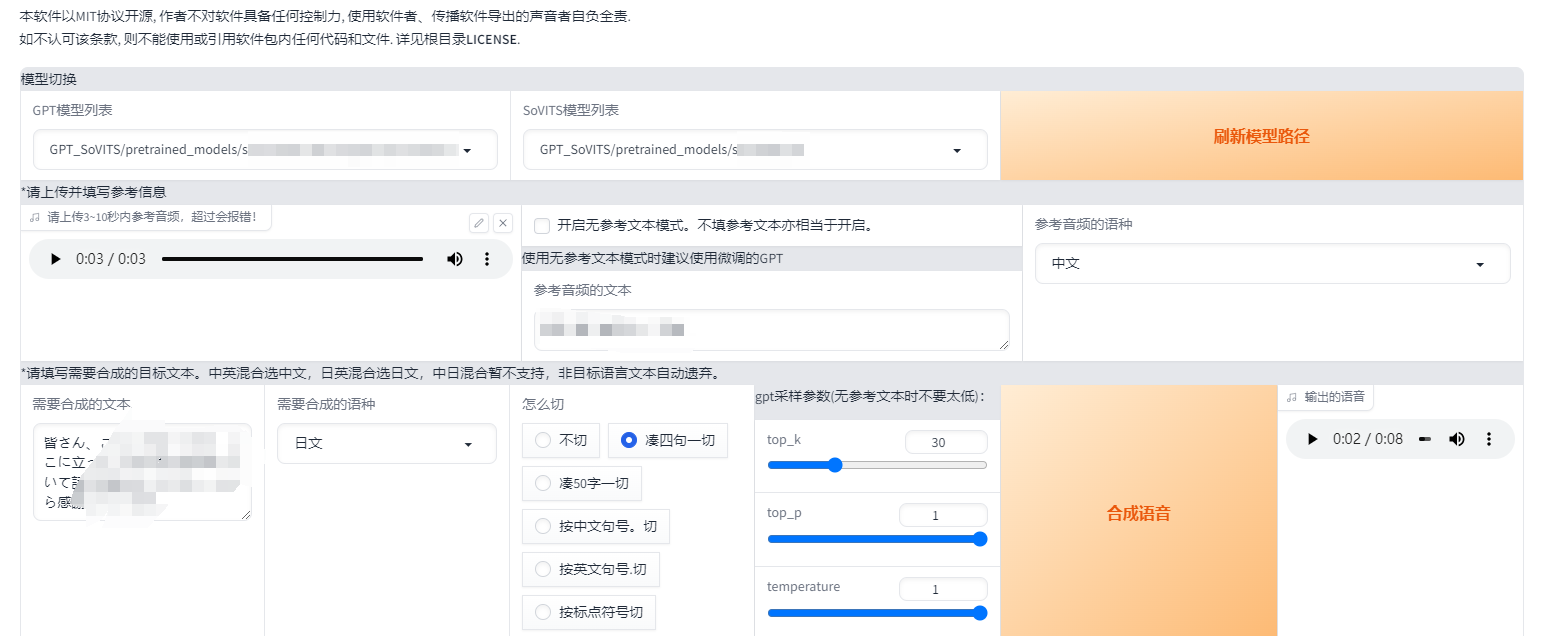
3. 网页推理
开启TTS推理WebUI

在终端中打开新的网页
上传参考音频(建议使用训练集中的音频)
填写需要合成的文本
切分随便选
点击“合成语音”
2. 训练好模型后调用API推理
2.1 官方API服务挂起
如果在AutoDL上需要先激活环境:conda activate GPTSoVits
cd GPT-SoVITS
部署服务:
python api.py -dr "/root/autodl-tmp/output/slicer_opt/test_tts.mp4_0000070720_0000172160.wav" -dt "喂?喂?哦可以,开始" -dl "zh"
https://github.com/RVC-Boss/GPT-SoVITS/issues/938
用requests模拟本地的GET调用(在4090上计时约3秒):
import requests
import time
# 设置请求的URL和参数
url = "http://127.0.0.1:9880"
params = {
'text': '先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。',
'text_language': 'zh'
}
# 记录开始时间
start_time = time.time()
# 发送GET请求
response = requests.get(url, params=params)
# 检查请求是否成功
if response.status_code == 200:
# 打开一个文件用于写入
with open('output.wav', 'wb') as file:
file.write(response.content)
print("文件已下载到本地")
else:
print(f"请求失败,错误代码:{response.status_code}")
# 记录结束时间并计算运行时长
end_time = time.time()
elapsed_time = end_time - start_time
print(f"总运行时长:0.0597秒")
2.2 其他用户提供的服务
- ben0oil1/GPT-SoVITS-Server: 【脱离复杂的环境配置和整合包,极简配置推理服务】从GPT-SoVITS项目里面提取出来的,纯粹的推理服务方案。
- GPT-soVITS-Inference
3. 本文撰写过程中参考的其他网络资料
- 官方视频教程:耗时两个月自主研发的低成本AI音色克隆软件,免费送给大家!【GPT-SoVITS】_哔哩哔哩_bilibili
有教程和效果展示,还有简单的原理讲解,讲了一下SoVITS模型,GPT-SoVITS是用CotentVec替代了SoftVC
















 2321
2321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











