







初学python,写个小爬虫去爬取百度图片的图片
如果是静态加载图片的话 直接requests.get(url)获取源码 并转换成text格式 利用正则表达式匹配图片的链接直接下载
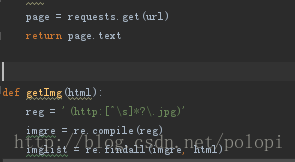
右键查看源代码 如果没有找到<img src="***.jpg">等信息 则表示网页加载图片是动态的(个人理解)
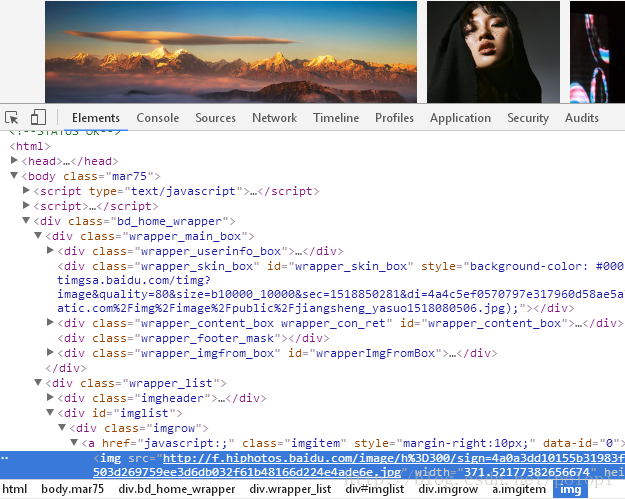
通过f12 或者 右键审查元素
点击左上角的鼠标 然后点击图片 即可显示图片的相关代码在源码中的位置
动态页面的话,我们可以通过抓包 ,点击 Network 然后 F5 刷新页面 查看NetWork下的XHR
然后点击左边的js响应信息 查看Preview 中的data信息 (如果没有出现data 则转动鼠标滚轮刷新页面)
出现data 然后点击Headers 查看Query String Parameters
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 8490
8490











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









