








 超级会员免费看
超级会员免费看

 本文介绍了如何使用Python进行网页抓取,以获取漫画《海贼王》的分集标题。通过查看网页源代码,确定分集标题位于`comic-title`的class中。文章对比了两种方法:直接获取全部文本再处理和直接提取特定标签内的文本,认为后者更符合程序逻辑。提供了完整的Python代码实现。
本文介绍了如何使用Python进行网页抓取,以获取漫画《海贼王》的分集标题。通过查看网页源代码,确定分集标题位于`comic-title`的class中。文章对比了两种方法:直接获取全部文本再处理和直接提取特定标签内的文本,认为后者更符合程序逻辑。提供了完整的Python代码实现。
说到爬虫,我们就会想到python,python的网页提取模块让爬虫不再困难。
当然了,其他语言都可以做到的。只不过python更方便而已。
需求描述:
我们的功能就是抓取分集标题,然后写入文件text
首先我们来看看某个漫画网站海贼王的那一页,分集标题都有,不像其他网站缺的比较多,那么就选它了。
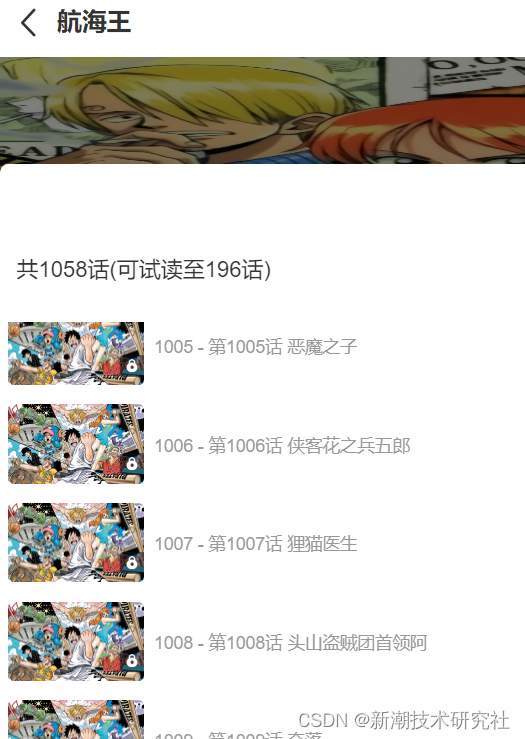
然后我们打开网站源代码或者开发者工具,看看分集标题在什么标签里面,这样待会抓取的时候就可以针对这个标签进行提取了。

很显然,分集标题都在comic-title的class里面,所以我们就需要对这个标签进行提取操作,
这里有两种处理方式:
1.使用get_text获取网页所有的文本,然后自己处理文本,或复制或进行再提取。
2.使用find_all获取comic_title的标签,然后再提取标签

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











