







本文介绍一篇图文结合的论文,论文发布于2021年

论文题目:
Seeing Out of tHe bOx:End-to-End Pre-training for Vision-Language Representation Learning
论文地址:
https://arxiv.org/abs/2104.03135
代码地址:
https://github.com/researchmm/soho
论文提出的模型简称 SOHO。早先的图文模型,对图片进行处理时都会先对其中的特定区域进行特征提取,再以该特征作为图片的向量表征,这部分特征也称作ROI特征。
但是,作者认为,这种方式只能获取到图片的一部分特征,这对图片的语义信息与文本的语义信息的对齐是一项挑战。因此,作者提出SOHO的输入为一个完整的图片,同时因省略了边界框注释,使得模型的推理时间比region-base的模型快了10倍。
1、模型结构
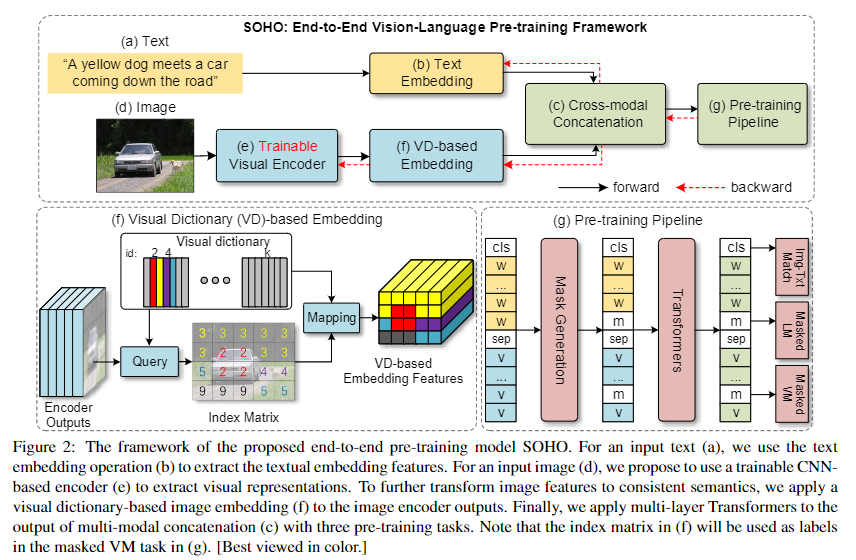
可以看到SOHO采用的也是一个双流的模型,相比与之前工作的不同有两个模块:
- 图片侧的输入为整张图片,而不是对应的ROI区域
- 加入了VD来求图片的向量表征
Trainable Visual Encoder
使用CNN-base的模型对输入的图片进行编码,并且使用整张图片作为输入,使用image-level的视觉特征,而非rigion-level的视觉特征。没有了边框的限制,编码器可以从预训练损失或者下游任务的损失中进行端到端的学习更新。
其中 E ( ) E() E()表示视觉编码器, I I I表示输入图片, θ \theta θ表示编码器的参数, l l l表示特征向量的数量, c c c表示向量维度, V V V表示特征向量。
本文使用的CNN-base编码器为ResNet(在ImageNet上预训练好的),后接一个1x1的卷积层和一个2x2的最大池化层
VD-base embedding
VD(visual dictionary)如下图所示:

视觉编码器提取的特征比文本tokens更加的多样和密集,这会给跨模态理解的学习带来困难。为了解决这个问题,作者提出了VD的思想,通过将相似的视觉语义聚合到相同的图像特征中,以此得到图像对应的tokens。
本文通过欧几里得距离实现对语义相似度的计算。更具体地说,事先会定义一个VD矩阵 D ∈ R k × c D\in{R^{k\times{c}}} D∈Rk×c,该矩阵有k个embedding向量,维度都是c。那么,字典映射的索引的计算方式为:
h i = a r g m i n j ∣ ∣ v i − d j ∣ ∣ 2 h_i=argmin_j||v_i-d_j||_2 hi=argminj∣∣vi−dj∣∣2
其中 d j d_j dj表示第j个embedding向量, v i v_i vi表示需要计算的视觉特征。将VD embedding定义为一个函数f,有:
f ( v i ) = d h i f(v_i)=d_{h_i} f(vi)=dhi
以此求得视觉特征V到VD embedding的映射关系。
矩阵D一般是随机初始化的,并通过移动平均对其进行更新:
d j ^ = γ ∗ d j + ( 1 − γ ) ∗ ∑ h i = j v i ∣ f − 1 ( j ) ∣ \hat{d_j}=\gamma*d_j+(1-\gamma)*\frac{\sum_{h_i=j}v_i}{|f^{-1}(j)|} dj^=γ∗dj+(1−γ)∗∣f−1(j)∣∑hi=jvi
其中 γ \gamma γ表示动量系数,取值在[0,1]。
因为在求映射函数的时候,使用了 a r g m i n argmin argmin函数,因为该函数不可微分,所以bp将被VD停止,为了使视觉特征可以被训练,作者使用以下的方式更新 f ( v i ) f(v_i) f(vi):
f ( v i ) = s g [ d h i − v i ] + v i f(v_i)=sg[d_{h_i}-v_i]+v_i f(vi)=sg[dhi−vi]+vi
其中 s g [ ⋅ ] sg[\cdot] sg[⋅]表示停止梯度操作。
作者实验发现VD存在冷启动的问题,直接将梯度从随机初始化的嵌入向量复制到视觉特征图会导致模型的优化方向不正确,因此,作者在前10个epoch会冻结CNN-base encoder的参数。
文本侧按照常用方式进行编码即可,之后文本的向量表征与根据图片得到的VD-base embedding进行concat,开头和文本结尾使用[CLS]和[SEP]进行标记,最后输入多层Transformer,至此模型搭建完毕。最后根据预训练任务,对模型进行训练即可。
2、预训练任务
SOHO一共进行了3个预训练任务:
(1)MVM(Masked Vision Model)
作者新提出的任务,以VD作为虚拟视觉语义标签。这部分的预训练任务与MLM对称,MLM是针对文本的,MVM是针对图像的,将图像特征在输入Transformer之前随机mask。
其损失函数的计算公式为:
L
M
V
M
=
−
E
(
W
,
f
(
V
)
)
∈
D
l
o
g
p
(
f
(
v
j
)
∣
W
,
f
(
V
)
/
j
)
L_{MVM}=-E_{(W,f(V))\in{D}}logp(f(v_j)|W,f(V)_{/j})
LMVM=−E(W,f(V))∈Dlogp(f(vj)∣W,f(V)/j)
MVM的目标就是通过没有被mask的相邻的图像特征 f ( V ) / j f(V)_{/j} f(V)/j和所有的文本 W W W去预测图像中masked特征。
MVM可以帮助模型从上下文视觉信息和语言中推断视觉知识。当图像的特征 v i v_i vi被mask后,它在VD中的映射索引 h i h_i hi将作为其虚拟标签。
在视觉特征图中,相邻特征可能具有相似的值,因此共享相同的映射索引,如果直接以此进行损失函数的计算,就会导致模型直接使用周围特征的标签,而无法学得真正的视觉上下文信息。为了解决这个问题,在mask阶段,先随机选择一个现有的标签索引j,然后[MASK]标记替换 f − 1 ( j ) f^{-1}(j) f−1(j)中所有的视觉向量。
(2)MLM(Masked Language Model)
这部分的任务和BERT里面基本是一样的,不过加入了视觉特征对文本的mask进行辅助预测。其中 f ( V ) f(V) f(V)就是之前提到的映射函数。
损失函数的计算公式为:
L M L M = − E ( W , f ( V ) ∈ D ) l o g p ( w i ∣ W / i , f ( V ) ) L_{MLM}=-E_{(W,f(V)\in{D})}logp(w_i|W_{/i},f(V)) LMLM=−E(W,f(V)∈D)logp(wi∣W/i,f(V))
其中 W / i W_{/i} W/i表示文本tokens中,未被mask的tokens, w i w_i wi则表示被mask的tokens,也就是需要预测的tokens。
(3)ITM(Image-Text Match)
图文匹配任务,二分类,图文结合模型常用的预训练任务。其损失函数的计算方式为:
L
I
T
M
=
−
E
(
W
,
f
(
V
)
)
−
∈
D
l
o
g
p
(
y
∣
ϕ
(
W
,
f
(
V
)
)
)
L_{ITM}=-E_{(W,f(V))-\in{D}}logp(y|\phi(W,f(V)))
LITM=−E(W,f(V))−∈Dlogp(y∣ϕ(W,f(V)))
作者最后给三个预训练任务分配了相同的权重,所以最后的损失函数为:
L
p
r
e
−
t
r
a
i
n
i
n
g
=
L
M
L
M
+
L
M
V
M
+
L
I
T
M
L_{pre-training}=L_{MLM}+L_{MVM}+L_{ITM}
Lpre−training=LMLM+LMVM+LITM
作者只使用了领域内的数据集进行预训练,更具体地,通过MSCOCO和VG数据集构造了自己的预训练数据集。
在预训练时,一张图片将会与4个文本进行组合,其中两个是正样本,两个是负样本,并且MLM和MVM只会在正样本上进行。
3、下游任务
下游任务的基本情况如下:

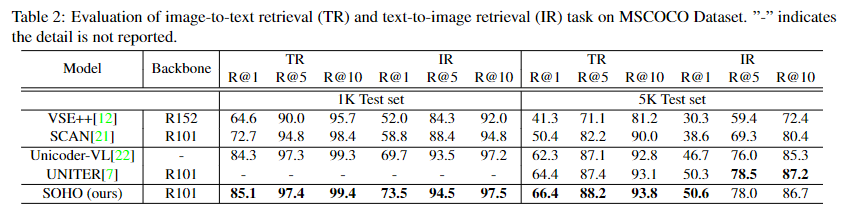
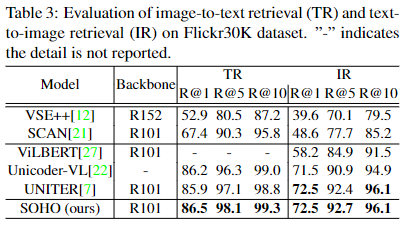
(1)Image-Text Retrieval
该任务包括两个子任务,图文和文图。该部分的做法与之前预训练任务ITM是一致的,当成一个二分类问题去做就行。
其实验结果如下:
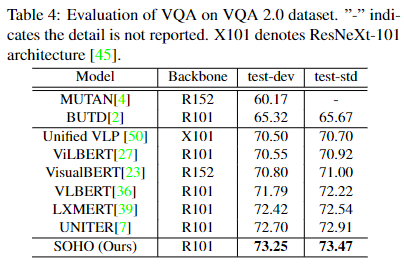
(2)Visual Question Answering
该任务是的输入是一张图片和一个问题,输出对应的答案。作者将其建模为一个分类任务,使用[CLS]对应的向量表征去做。
实验结果如下:
(3)Visual Reasoning
预测文本是否与给定的图像对相关。实验结果如下:

(4)Visual Entailment
预测图像是否在语义上包含文本,标签为true、false和neutral。实验结果如下:

作者针对是否使用VD以及VD对应的维度进行了调参。消融实验结果如下:
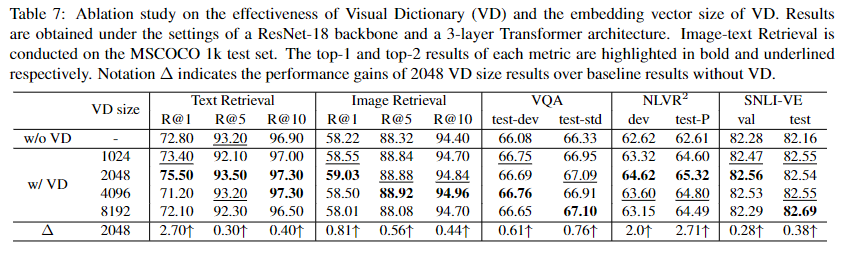
基于实验结果,作者最后使用维度为2048的VD。
SOHO的贡献有以下几点:
-
一种不需要提取区域边框的,端到端的VLPT模型。在提高精度的同时,大量降低了推理时间
-
提出了一种全新的动态更新的视觉词典映射方式,用来表示图像中相似语义的视觉抽象,可以更好的对齐图像和文本之间的tokens
总结
这篇文章的内容比较契合毕设的方向,甚至方法也可以借鉴,不过,SOHO是使用领域内的数据进行预训练的,所以,如果要用到其他领域就需要自己预训练,比较耗费资源。
同时,毕设用的数据集(文本和图像)比论文中使用的公开数据集更脏,这也会有可能导致最后的结果不尽人意。不过SOHO丢弃了边框提取,确实降低了对图像处理的能力要求,更加容易上手,是一个值得尝试的方案。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









