







最近利用空闲时间学习了一下大模型,下面就GLM-130B相关文章进行分享,一起学习进步。
1 GLM

论文题目:
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
论文地址:
https://aclanthology.org/2022.acl-long.26
代码地址:
https://github.com/THUDM/GLM
2 ChatGLM

论文题目:
GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL
论文地址:
https://arxiv.org/abs/2210.02414
代码地址:
https://github.com/THUDM/GLM-130B/tree/main
1 介绍
GLM(General Language Model)对已有的预训练范式进行改进,提出了一种基于自回归的,并引入了填空机制的范式,该范式相比于已有的自编码模型(BERT等)、自回归模型(GPT)和编码器-解码器模型(T5等)在NLU、有条件NLG和无条件NLG三类任务上有着更优的效果。

上图就是对GLM任务的描述,在数据处理时,遵循自编码的思想,随机将绿色部分遮盖,遵循自回归的思想,生成对应的字。而且从图中的注意力连接线可以看到,在生成部分保持着单向注意力,在蓝色部分则是双向注意力。GLM将NLU任务制定为包含任务描述的完形填空问题,然后通过自回归来生成回答。作者考虑到”blanking filling“已经在T5中使用过,所以基于此提出了两点改进,分别是”span shuffing“和2D位置编码。
2 实现
2.1 数据处理
GLM在处理数据时会随机采样部分spans,假设 x = [ x 1 , . . . , x n ] x=[x_1,...,x_n] x=[x1,...,xn]作为模型的输入,采样到的spans为 { s 1 , . . . , s m } \{s_1,...,s_m\} {s1,...,sm},每个span对应x中的一个连续片段,并且使用[MASK]这个token来代替每个span。

上图描述了GLM预训练的实现方法,图(b)表示数据的处理过程,从数据数据 x x x中随机选择了两个span(作者从 λ = 3 \lambda=3 λ=3的泊松分布中采样,并且持续采样直到句子中至少15%的token被遮掩), [ x 3 ] [x_3] [x3]和 [ x 5 , x 6 ] [x_5,x_6] [x5,x6],并将被遮盖的句子与选择的span分为partA和partB,在模型训练过程中,GLM需要通过自回归的方式生成partB,对于B中的每个span以[S]作为开头,并附加[E]作为输出,以区分结尾,同时需要注意的是,对于partB,并不是保持原有的语序顺序,如图中是以 [ x 5 , x 6 , x 3 ] [x_5,x_6,x_3] [x5,x6,x3]作为顺序的,也就是说在拼接partB时打乱了序列的顺序。
同时,根据图(c)可以发现,GLM在使用注意力时,partA部分使用的是双向,pabrtB与partB部分使用的是单项,partB与partA部分使用的是双向。并且,2D位置编码通过结合partA和partB合并后的位置编码以及partB的位置编码实现。
位置编码实现代码如下:
# Position ids.
position_ids = torch.arange(seq_length, dtype=torch.long,
device=data.device)
position_ids = position_ids.unsqueeze(0).expand_as(data)
if set_loss_mask:
loss_mask[data == eod_token] = 0.0
# We need to clone as the ids will be modifed based on batch index.
if reset_position_ids:
position_ids = position_ids.clone()
if reset_position_ids or reset_attention_mask:
# Loop through the batches:
for b in range(batch_size):
# Find indecies where EOD token is.
eod_index = position_ids[b, data[b] == eod_token]
# Detach indecies from positions if going to modify positions.
if reset_position_ids:
eod_index = eod_index.clone()
# Loop through EOD indecies:
prev_index = 0
for j in range(eod_index.size()[0]):
i = eod_index[j]
# Mask attention loss.
if reset_attention_mask:
attention_mask[b, 0, (i + 1):, :(i + 1)] = 0
# Reset positions.
if reset_position_ids:
position_ids[b, (i + 1):] -= (i + 1 - prev_index)
prev_index = i + 1
上面的代码的作用是求取position 1。作者使用了一个for循环来遍历一个批次里的数据,并分别处理每条数据对应的位置id。代码中eod_token应该是一个句子的间隔token,(不过笔者在代码中并没有找到这个参数的定义),作者接着对每个句子的间隔token索引进行遍历,并对对应位置的值进行修改,使其满足上图(b)中的形式。不过,笔者在GLM的源码中好像并没有找到对2d位置编码的定义,不过通过下面代码可以看出作者确实是想使用2d位置编码:
block_position_ids = position_ids[:, 1]
position_ids_ = position_ids[:, 0]
代码中对2d位置编码的embedding表示直接相加,如下所示:
if self.block_position_encoding:
position_ids, block_position_ids = position_ids[:, 0], position_ids[:, 1]
position_embeddings = self.position_embeddings(position_ids)
hidden_states = hidden_states + position_embeddings
if self.block_position_encoding:
block_position_embeddings = self.block_position_embeddings(block_position_ids)
hidden_states = hidden_states + block_position_embeddings
代码中position_embeddings表示position 1,block_position_embeddings表示position 2。
由于在源码中没有找到2d位置编码的定义,这里给出huggingface上的定义,如下:
#https://huggingface.co/THUDM/chatglm-6b/blob/main/modeling_chatglm.py
def get_position_ids(self, input_ids, mask_positions, device, use_gmasks=None):
batch_size, seq_length = input_ids.shape
if use_gmasks is None:
use_gmasks = [False] * batch_size
context_lengths = [seq.tolist().index(self.config.bos_token_id) for seq in input_ids]
if self.position_encoding_2d:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
for i, context_length in enumerate(context_lengths):
position_ids[i, context_length:] = mask_positions[i]
block_position_ids = [torch.cat((
torch.zeros(context_length, dtype=torch.long, device=device),
torch.arange(seq_length - context_length, dtype=torch.long, device=device) + 1
)) for context_length in context_lengths]
block_position_ids = torch.stack(block_position_ids, dim=0)
position_ids = torch.stack((position_ids, block_position_ids), dim=1)
else:
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
for i, context_length in enumerate(context_lengths):
if not use_gmasks[i]:
position_ids[i, context_length:] = mask_positions[i]
return position_ids
2.2 预训练任务
GLM的预训练目标有两个,分别是:
- Document-level:目标是生成长文本。从原始句子长度的50%-100%的均匀分布中采样span进行遮掩
- Sentence-level:针对seq2seq任务,预测目标通常是完整的句子或段落。限制被这样的片段必须是完整的句子
在对预训练的目标函数进行设计时,GLM使用下式:
m a x θ E z ∈ Z m [ ∑ i = 1 m l o g p θ ( s z i ∣ x c o r r u p t , s z < i ) ] \underset{\theta}{max}E_{z\in Z_m}[\sum^m_{i=1}logp_{\theta}(s_{z_i}|x_{corrupt},s_{z < i} )] θmaxEz∈Zm[∑i=1mlogpθ(szi∣xcorrupt,sz<i)]
式中 x c o r r u p t x_{corrupt} xcorrupt表示经过span的文本。
2.3 模型结构
GLM在模型结构上有三个方面的改进,如下:
- LN与残差连接的位置
- 将前馈网络变成线性层
- 用GeLU代替ReLU
2.4 微调
GLM在实现时将NLU的任务转换为生成任务进行实现,换言之,将对应的标签使用[MASK]代替,然后模型生成遮掩的对应的文字。如下图所示,作者定义了一个映射
v
(
˙
)
v(\dot{})
v(˙),该映射可以将标签对应到单词上,如下图的情况就是将“positive”映射为“good”,在以good作为生成的单词实现完形填空。

计算方式如下:
p ( y ∣ x ) = p ( v ( y ) ∣ c ( x ) ) ∑ y ′ ∈ y p ( v ( y ′ ) ∣ c ( x ) ) p(y|x)=\frac{p(v(y)|c(x))}{\sum_{y\prime{} \in y}p(v(y\prime{})|c(x))} p(y∣x)=∑y′∈yp(v(y′)∣c(x))p(v(y)∣c(x))
式中 c ( ˙ ) c(\dot{}) c(˙)表示“cloze”,也就是将输入的文本 x x x转化为完形填空的格式,也就是“{sentence}.it’s really [MASK]”的格式。
2.5 对比
下面介绍GLM和其他已经出现的模型的效果对比。作者给出的对比对象为BERT、XLNet、UniLM和T5.
BERT
- 由于MLM的独立性假设,BERT无法捕捉不同[MASK]之间的相互依赖性
- BERT无法实现对多个token的填充,在被遮掩的token数量为 l l l时,模型需要连续预测 l l l次
XLNet
- 位置编码问题,导致其在推理时需要知道答案的长度
- 使用双流注意力来防止信息的泄露,但是这会使时间成本翻倍
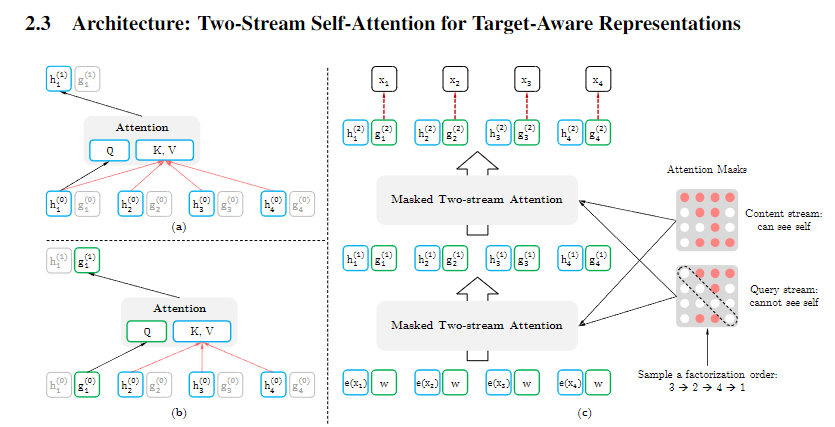
在XLNet中存在双流注意力机制,分别如上图(a)和(b)所示。其中(a)表示基于内容的注意力机制,与标准的自注意力一致;(b)表示基于query的注意力机制。上图中 h h h表示内容表征,与TRM的隐藏层一样; g g g表示query表征,只有 x x x的上下文信息和位置信息,没有 x x x的信息,并且第一层 g g g的初始化使用随机初始化即可。
下面是XLNet中, g g g进行初始化的代码:
##### Word embedding
word_emb_k, lookup_table = embedding_lookup(
x=inp_k,
n_token=n_token,
d_embed=d_model,
initializer=initializer,
use_tpu=use_tpu,
dtype=tf_float,
scope='word_embedding')
if inp_q is not None:
with tf.variable_scope('mask_emb'):
mask_emb = tf.get_variable('mask_emb', [1, 1, d_model], dtype=tf_float)
if target_mapping is not None:
word_emb_q = tf.tile(mask_emb, [tf.shape(target_mapping)[0], bsz, 1])
else:
inp_q_ext = inp_q[:, :, None]
word_emb_q = inp_q_ext * mask_emb + (1 - inp_q_ext) * word_emb_k
output_h = tf.layers.dropout(word_emb_k, dropout, training=is_training)
if inp_q is not None:
output_g = tf.layers.dropout(word_emb_q, dropout, training=is_training)
with tf.variable_scope('layer_{}'.format(i)):
if inp_q is not None:
output_h, output_g = two_stream_rel_attn(
h=output_h,
g=output_g,
r=pos_emb,
...)
reuse = True
else:
reuse = False
with tf.variable_scope(scope, reuse=True):
##### g-stream
# query-stream query head
q_head_g = head_projection(
g, d_model, n_head, d_head, kernel_initializer, 'q')
T5
- T5在训练时使用多个“sentinel token”,但是在下游任务时,只需要使用一个
UniLM
- 仅使用了[MASK]特殊token来代替被遮掩的部分
- 微调效率低

UniLM合成了多种LM,在进行MLM任务时,每种LM使用到的信息有所区别。left-to-right LM仅使用左侧的信息对遮掩的词进行预测;right-to-left LM仅使用右侧的信息预测;bi LM使用上下文信息;s2s LM则是使用全部的输入和target的左侧信息。
3.1 介绍
chatGLM就是以GLM作为基础模型训练的得到的大模型。其原始大小为130B(1300亿参数量),经过量化后可达6B(60亿参数量)。大模型一般是指参数量达到千亿级的模型。chatGLM是一个双语模型(中英),并且完全开源。
首先,作者将chatGLM和已有的其他大模型从几个主要方面进行了对比,如下:

表中的SSL表示self-supervised learnin,MIP表示multi-task instruction pre-training,PE表示位置编码,FFN表示前馈网络。根据上表可以总结出chatGLM的几个创新点:
- 首个使用SSL+MIP的训练方式
- 使用post-LN的归一化方式,结合deepnorm
- 使用旋转位置编码RoPE
- 使用GeGLU代替FFN
- 使用EGS提高训练稳定性
- INT4量化
- 使用faster-trm加速
- 完全开源
- 多平台应用
3.2 模型设计
对于掩码方式,chatGLM有两个掩码标记,分别是:
- [MASK]:主要用来代替句子中的短的span,用于进行NLU任务
- [gMASK]:用于生成式任务,生成句子末尾随机长度的长span
对于chatGLM-130B,其预训练目标是SSL和MIP的结合, 其中95%的tokens用于SSL训练,5%用于MIP训练,这将有助于提升下游的zero-shot的效果。对于SSL,模型同时使用[MASK]和[gMASK],其中[MASK]用来遮掩30%的连续span,span的长度服从 λ = 3 \lambda=3 λ=3的泊松分布,并且最多为输入句子的15%,另外的70%的tokens使用[gMASK]进行遮掩,长度服从均匀分布。T5等模型的结果显示,MIP任务有助于微调的效果,同时,为了防止MIP破坏大模型的其他能力,仅使用5%的tokens进行MIP。
在chatGLM的实现过程中,deepnorm的设计如下:
D e e p N o r m ( x ) = L N ( α ˙ x + N e t w o r k ( x ) ) DeepNorm(x)=LN(\alpha \dot{} x+Network(x)) DeepNorm(x)=LN(α˙x+Network(x))
式中 α = 2 N 2 \alpha=\sqrt[2]{2N} α=22N,并且使用Xavier normal initialization初始化方法。
3.3 训练策略
对于[gMASK]的训练目标,最大文本长度设置为2048;对于[MASK]和MIP,最大文本长度设置为512,但是合并4个样本到2048的长度。在前2.5%的样本中,使用warm-up的策略,将batch_size逐渐从192提升到4224;使用AdamW作为优化器,其中 β 1 = 0.9 , β 2 = 0.95 \beta_1=0.9,\beta_2=0.95 β1=0.9,β2=0.95,权重衰减系数设置为0.1;学习率也使用warm-up策略,对前0.5%的样本,学习率从 1 0 − 7 10^{-7} 10−7逐渐增加到 8 × 1 0 − 5 8\times10^{-5} 8×10−5,然后使用余弦退火的方式衰减学习率;dropout取值为0.1,使用1.0对梯度进行裁剪。
更完整的配置如下:

为了在保证训练精度的同时,提高训练的稳定性,GLM-130B使用了混合精度实现训练。在训练时,使用FP16用于前向和后向,使用FP32用于优化器和权重。不过这样会出现损失爆炸而训练失败的情况,作者通过几个月的研究,总结出了以下的问题,并提出了改进策略:
(1)当使用pre-LN时,深层的trm参数值可能会变得非常大。通过使用post-LN和deepnorm解决了该问题
(2)随着模型规模的扩大,注意力分数会变得很大,超过FP16的表示范围。作者通过使用EGS(Embedding Layer Gradient Shrink),解决这个问题。
通过实验证明,梯度范数可以对训练崩溃进行有效的衡量,并且,训练崩溃通常滞后于梯度范数的“尖峰”几个训练步骤。通过实验,作者观察到这种尖峰通常是由嵌入层的异常梯度引起的,在GLB-130B的早期训练中,其梯度范数通常比其他层的梯度范数大几个数量级,在早期训练中也会出现剧烈波动,如下图所示:

最后,作者发现梯度收缩的方式有利于改善这种情况,该方法最早在多模态模型 CogView中使用。以
α
\alpha
α作为收缩因子,该策略可以表示为:
w
o
r
d
‾
e
m
b
=
w
o
r
d
‾
e
m
b
∗
α
+
w
o
r
d
‾
e
m
b
.
d
e
t
a
c
h
(
)
∗
(
1
−
α
)
word\underline{}emb=word\underline{}emb*\alpha+word\underline{}emb.detach()*(1-\alpha)
wordemb=wordemb∗α+wordemb.detach()∗(1−α)
在GLM-130B的训练过程中,将
α
\alpha
α设置为0.1,效果如下图所示:

3.4 量化
量化可以理解为映射,也就是一个取值区间映射到另一个取值区间,进而降低存储模型参数所需的空间大小,而实现整体模型的资源消耗。比如,模型参数的dtype从FP32到FP16,FP16到INT8,以及GLM-130B的FP-16到INT4。
下图为GLM-130B的参数分布与BLOOM-176B的参数分布对比图:

这些参数的分布会直接影响最后量化的效果,分布更广的线性层需要使用更大的bin进行量化,从而导致更多的参数损失。从图中可以看到GPT类型的大模型BLOOM的分布更宽,因此其INT4量化的成功率更低。两者量化的效果对比如下:

GLM-130B各个精度的效果对比如下:

3.5 技术细节
论文中给出了较为详细的技术细节,这里做简单介绍
3.5.1 tokenizer
作者基于icetk包实现文本分词器,该包的词汇量为150000,其中前20000为图像标记,后续为文本标记,其文本分词器由sentencepiece在25GB的双语预料上训练的。作者在此基础上对分词器进行了调整。
将分词器分为4个成分,通用的tokens处于No.20000到No.20099,主要是一些标点符号、数字和空格;No.20100到No.83822为英文标记;No.83823到No.145653为中文标记;后续的标记为特殊符号,包括标点符号和其他语言的片段。
在固有标记的基础上,添加了[MASK]和[gMASK]用于模型预测,[sop]、[eop]和[eos]用于分隔句子和段落。
3.5.2 位置编码和FFN
在GLM-130B的实现中,使用的是旋转位置编码,这是一种以绝对位置编码形式实现的相对位置编码,这一点与GLM中的二维位置编码不同。其核心如下:
( R m q ) T ( R n k ) = q T R m T R n k = q T R n − m k (R_mq)^T(R_nk)=q^TR_m^TR_nk=q^TR_{n-m}k (Rmq)T(Rnk)=qTRmTRnk=qTRn−mk
式中 R R R的定义如下:

为了让它的值随着距离的增加而衰减,将
θ
\theta
θ设置如下:
θ = { θ i = 1000 0 − 2 ( i − 1 ) d i ∈ [ 1 , 2 , . . . , d 2 ] } \theta=\{\theta_i=10000^{\frac{-2(i-1)}{d}}i\in [1,2,...,\frac{d}{2}]\} θ={θi=10000d−2(i−1)i∈[1,2,...,2d]}
这里用到的旋转位置编码是一维的,作者通过以下方式对GLM的二维进行转化:
- 对于短span,直接去掉第二维
- 对于末尾长span,从上下文标记 s − 1 s-1 s−1开始延长第一维的位置编码
另外,作者将FNN进行了替换,使用带有GeLU的GLU对其替换:
F F N G e G L U ( x ; W 1 , V , W 2 ) = ( G e L U ( x W 1 ) ⨂ x V ) W 2 FFN_{GeGLU}(x;W_1,V,W_2)=(GeLU(xW_1)\bigotimes xV)W_2 FFNGeGLU(x;W1,V,W2)=(GeLU(xW1)⨂xV)W2
为了保持参数量的一致,原本FFN层的 4 × 4\times 4×降低到 8 3 × \frac{8}{3}\times 38×
3.5.3 量化
在量化过程中,GLM-130B主要使用了两种量化方式进行实验。
(1)Absmax Quantization
一种对称量化,将 x x x的范围从 [ − a b s m a x ( x ) , a b s m a x ( x ) ] [-absmax(x),absmax(x)] [−absmax(x),absmax(x)]映射到 [ − ( 2 b − 1 ) , 2 b − 1 ] [-(2^b-1),2^b-1] [−(2b−1),2b−1]的范围:
s
x
=
a
b
s
m
a
x
(
x
)
2
b
−
1
−
1
s_x=\frac{absmax(x)}{2^{b-1}-1}
sx=2b−1−1absmax(x)
x
q
=
r
o
u
n
d
(
x
s
x
)
x_q=round(\frac{x}{s_x})
xq=round(sxx)
式中,
s
x
s_x
sx表示缩放因子,
b
b
b表示bit width
(2)Zeropoint Quantization
这是一种非对称量化,将 x x x从 [ m i n ( x ) , m a x ( x ) ] [min(x),max(x)] [min(x),max(x)]映射到 [ − ( 2 b − 1 ) , 2 b − 1 ] [-(2^b-1),2^b-1] [−(2b−1),2b−1],如下:
s
x
=
m
a
x
(
x
)
−
m
i
n
(
x
)
2
b
−
2
s_x=\frac{max(x)-min(x)}{2^b-2}
sx=2b−2max(x)−min(x)
z
x
=
r
o
u
n
d
(
m
i
n
(
x
)
s
x
)
+
2
b
−
1
−
1
z_x=round(\frac{min(x)}{s_x})+2^{b-1}-1
zx=round(sxmin(x))+2b−1−1
x
q
=
r
o
u
n
d
(
x
s
x
)
−
z
x
x_q=round(\frac{x}{s_x})-z_x
xq=round(sxx)−zx
(3)Col/Row-wise Quantization
对权重矩阵使用单个缩放因子通常会导致更大的量化误差,一个异常值会降低所有元素的精度,因此常用按行或按列对权重矩阵进行分组,每组单独量化,且具有独立的缩放因子。
量化实验结果对比如下:

GLM-130B最后使用的是Absmax量化方法,相比于Zeropoint,在可以模型性能的同时有着更高的计算效率。
以上就是对GLM和GLM-130B的一些较为基础的介绍,通过对GLM-130B论文的阅读,可以发现大模型更加注重的是如何训练,论文中的很多策略也都是为了提高稳定性,同时也提出了很多用于节约资源的并行策略。
















 8554
8554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









