







MySQL索引底层采用B+ tree的原因
哈希索引
https://www.cs.usfca.edu/~galles/visualization/ClosedHash.html
通过 哈希 函数计算和类似取余运算,可以将元素插入到对应的bucket中,find的过程是o(1)时间复杂度,那find速度这么快,为啥Mysql底层不用呢?
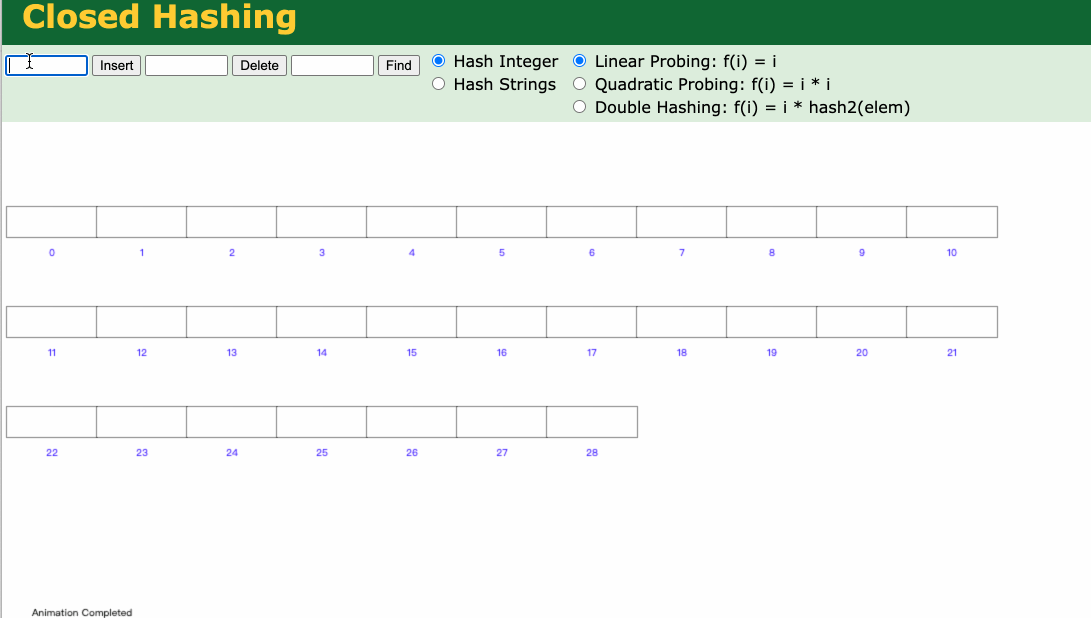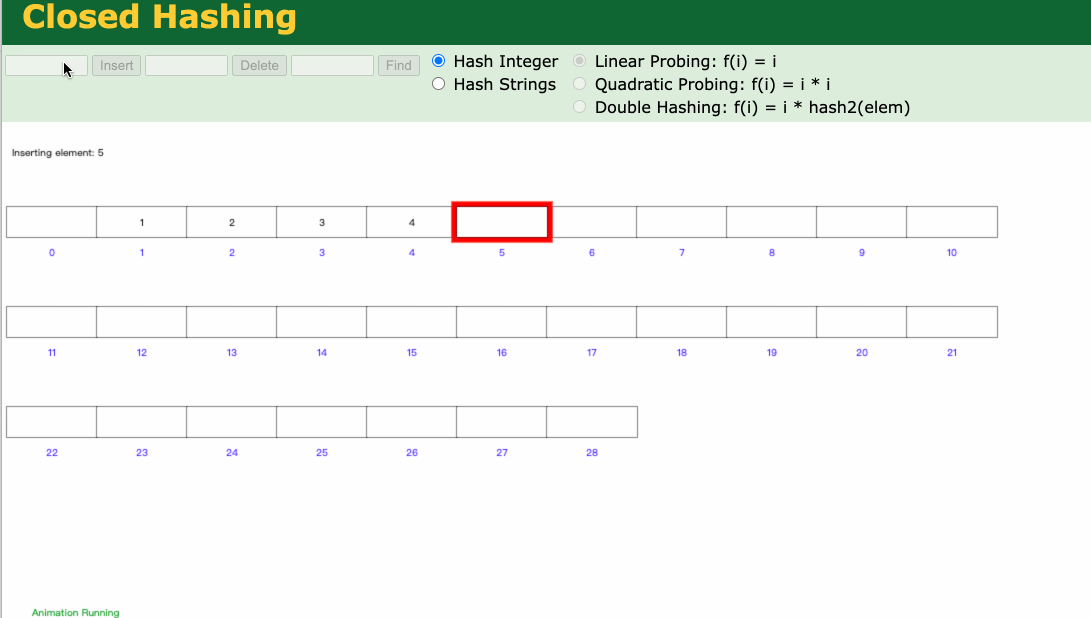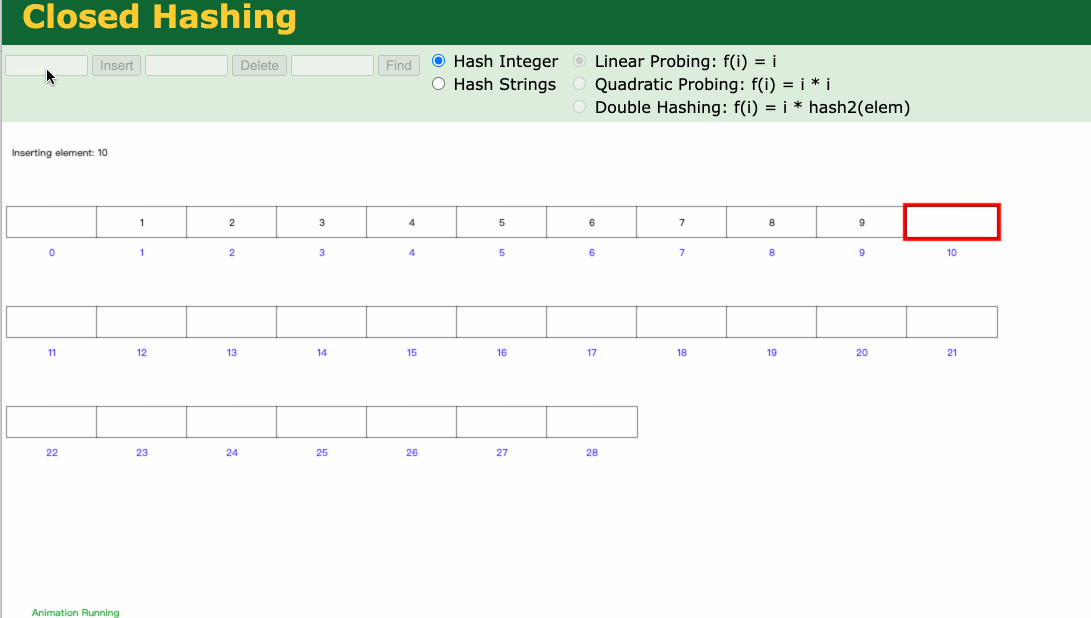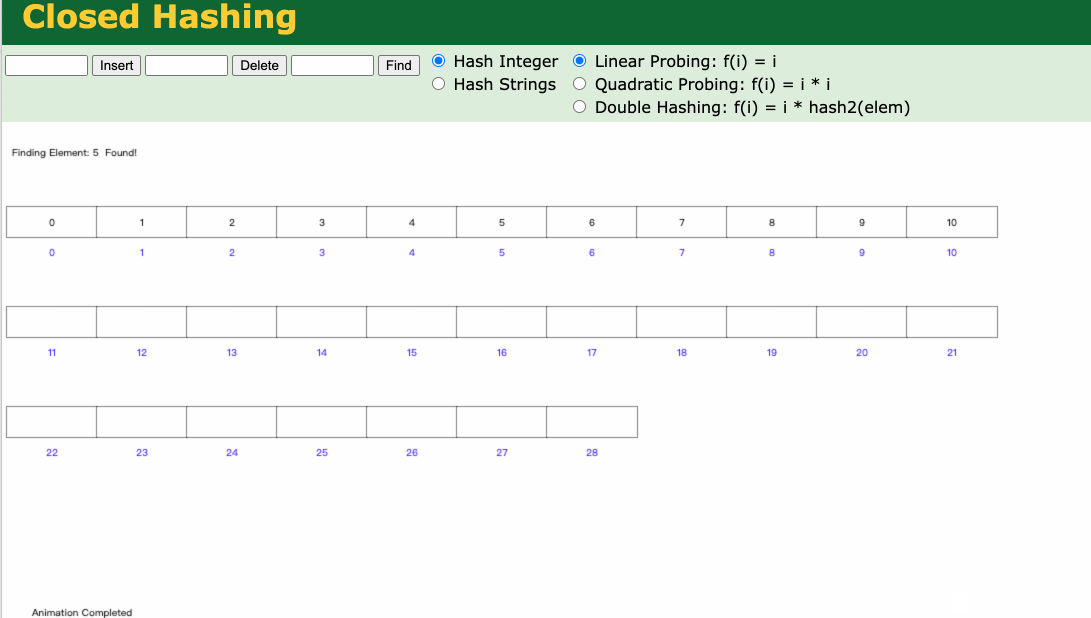
因为Mysql的查询涉及大量的范围查询,Hash索引这个无序集合,是不支持范围查询的,再比如mysql的排序查询(order by),而哈希是无序的,也无法支持!就像我们的uuid是无序的,不可能用他来做主键。
平衡二叉树
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
平衡二叉树的左右子树的高度差不会大于1。
无论怎么插,高度差都会维持,
随着树的高度增加,他的查询速度也会逐渐变慢,
比如这里找8,一次就找到了,但是找10找了三次。
还有一个致命缺点,如果我们去查5,通过三次定位找到了5,如果要找大于5的数据,就要从5这个节点往回查找,找到6,7,再回到更上一层的8,往下再9、10,这样才把大于5的数据找出来了,想象一下,如果大于5的数据特别多,那么回旋查询的次数就会增多,在这种范围查找上的效率很低。
这就是平衡二叉树的缺点:
- 高度越高,查询速度越慢
- 范围查找需要回旋的次数很大,效率低
B树
https://www.cs.usfca.edu/~galles/visualization/BTree.html

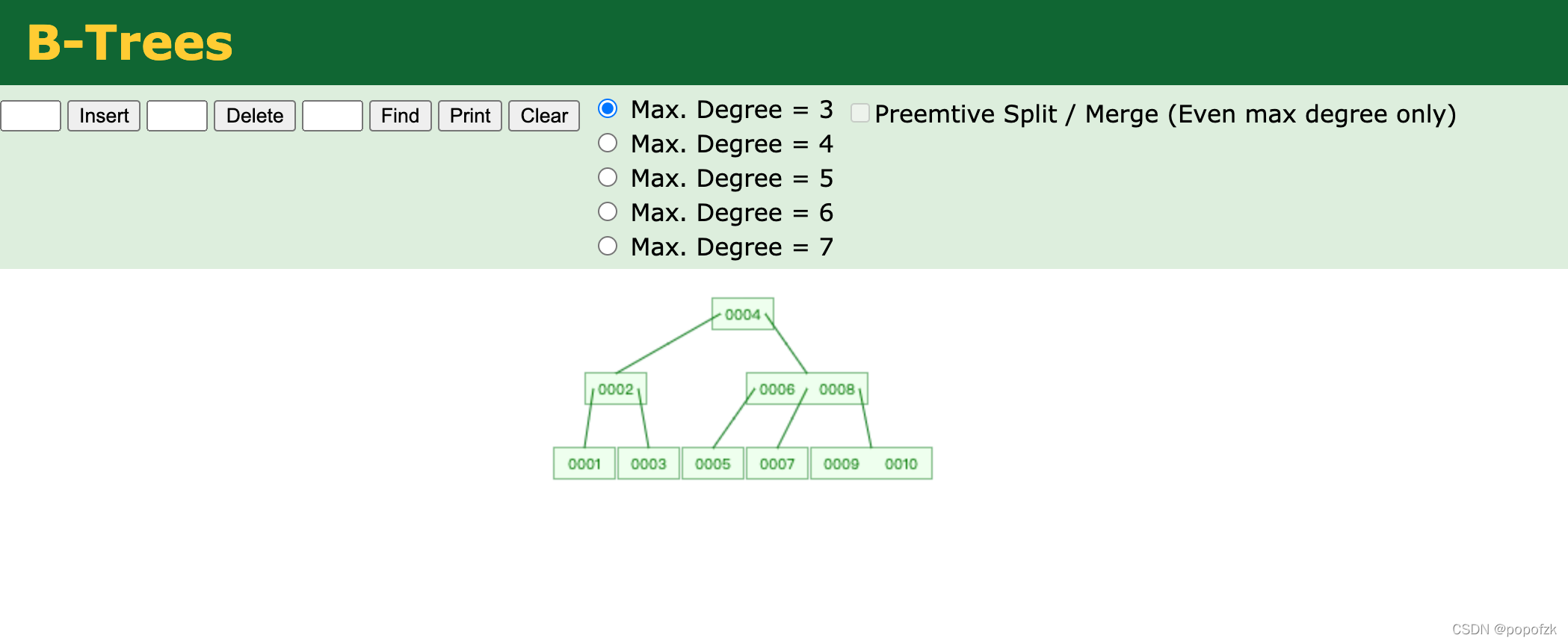
B树最大的特点就是一个节点可以存两个值
这样存储有什么好处呢?
对比平衡二叉树,同时存10个数字的情况下,平衡二叉树有4层,而B树只有三层。
树的高度上面,B树更优(毕竟一个节点存放的数字更多了,更紧凑)
变矮之后的好处就在于:查询的效率变高了,查数字的速度更快了
样例:之前平衡树找10需要找3次,而B树只用了2次。
所以,从平衡二叉树->B树,解决了树的高度的问题,树越矮,查询的效率越高。
那么,B树存在回旋查找的问题吗?答案是肯定的:
比如要查找大于5的数,一样需要回旋到上一层的6、8…,所以B树的范围查找仍然不太理想。
B+ Tree
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html

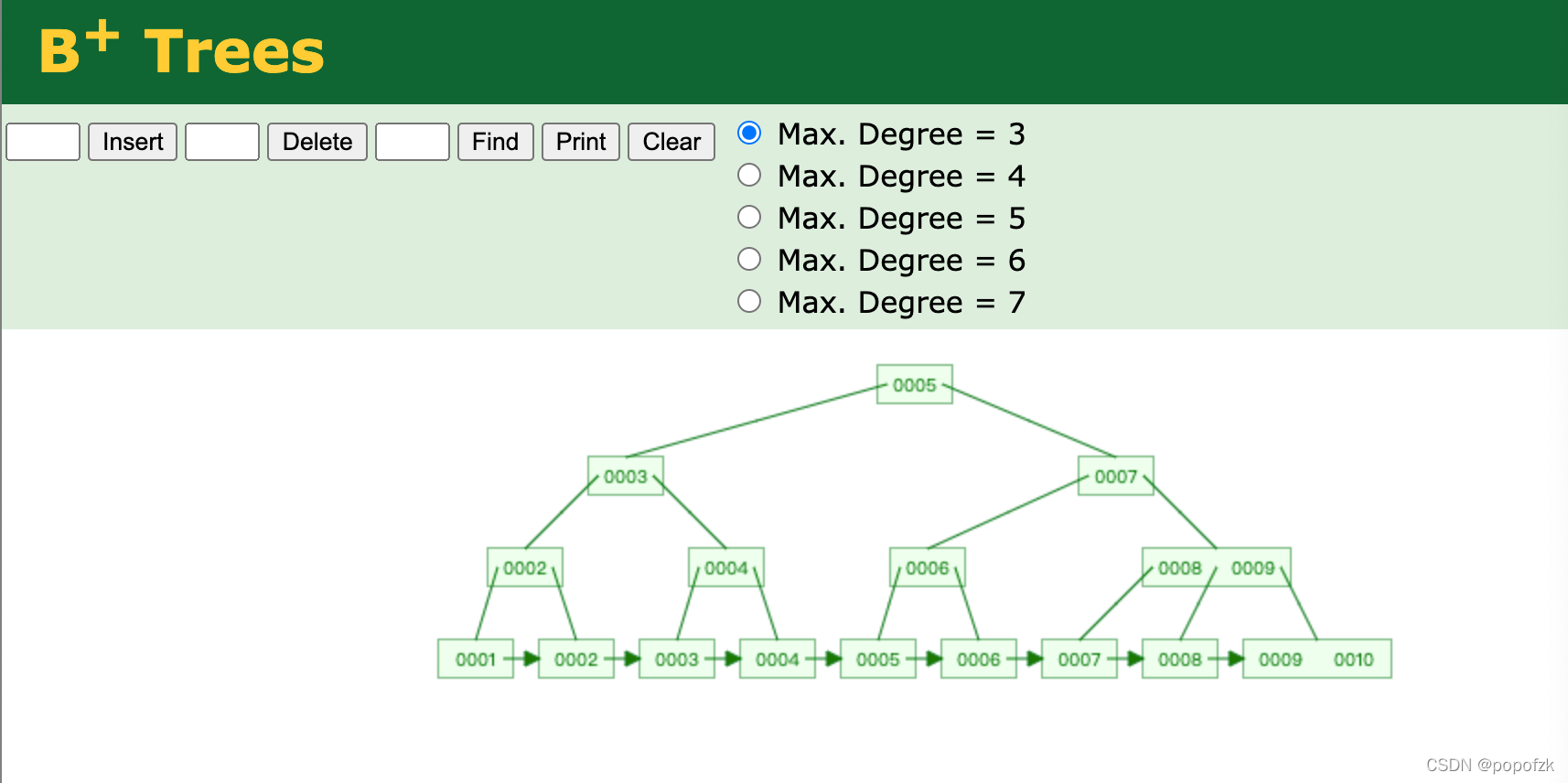
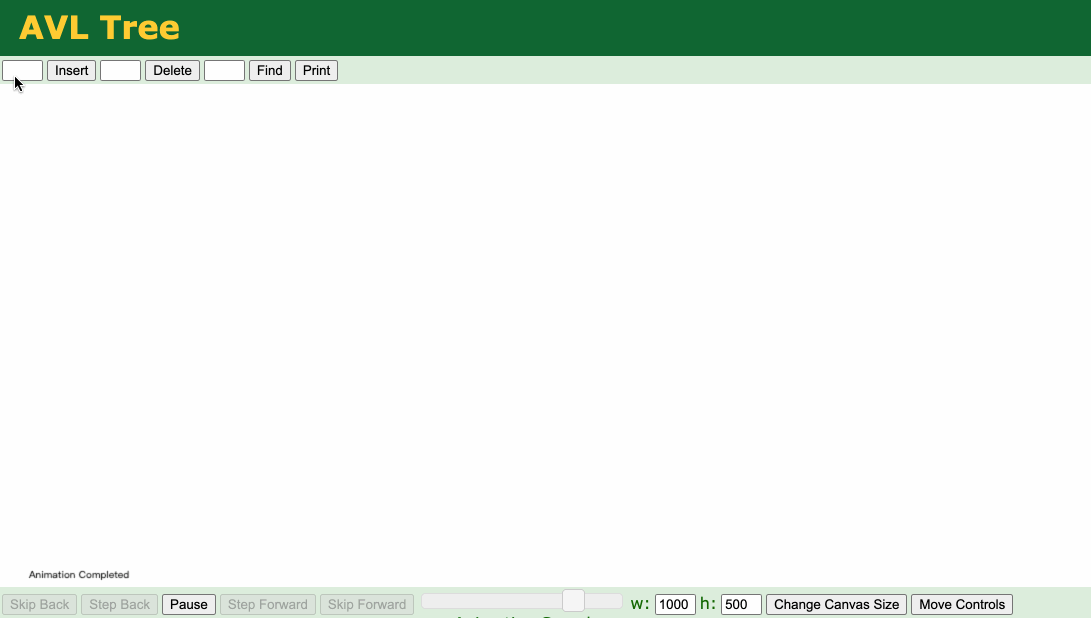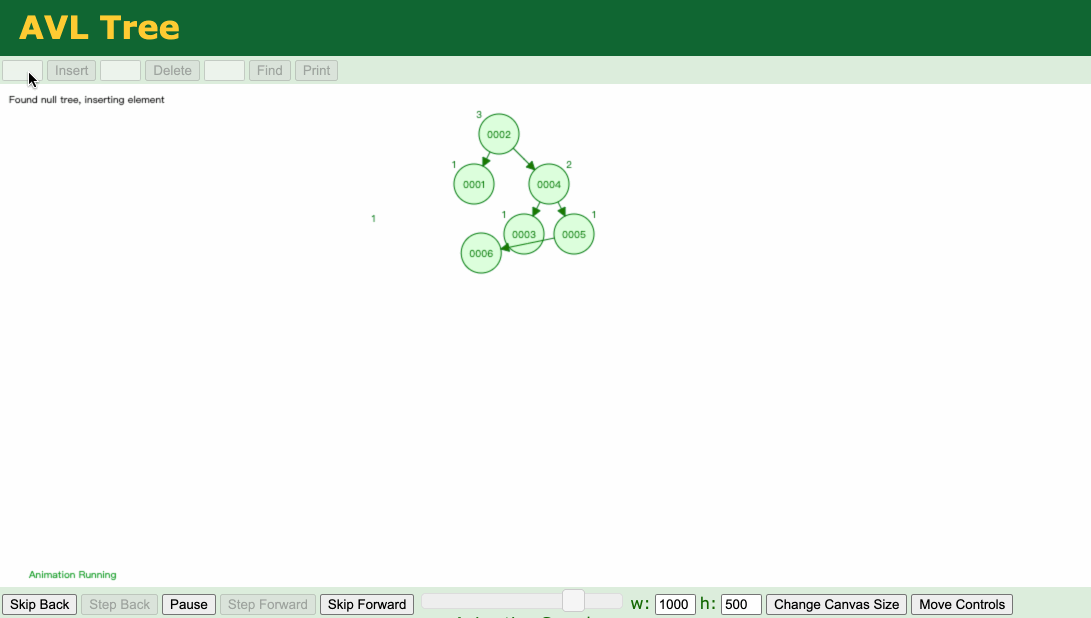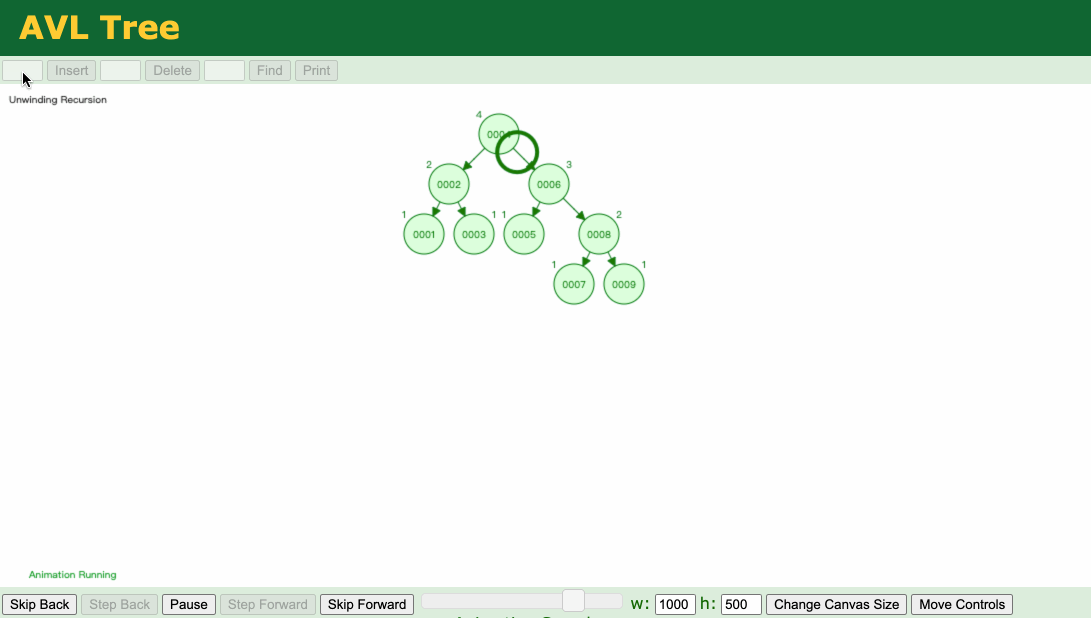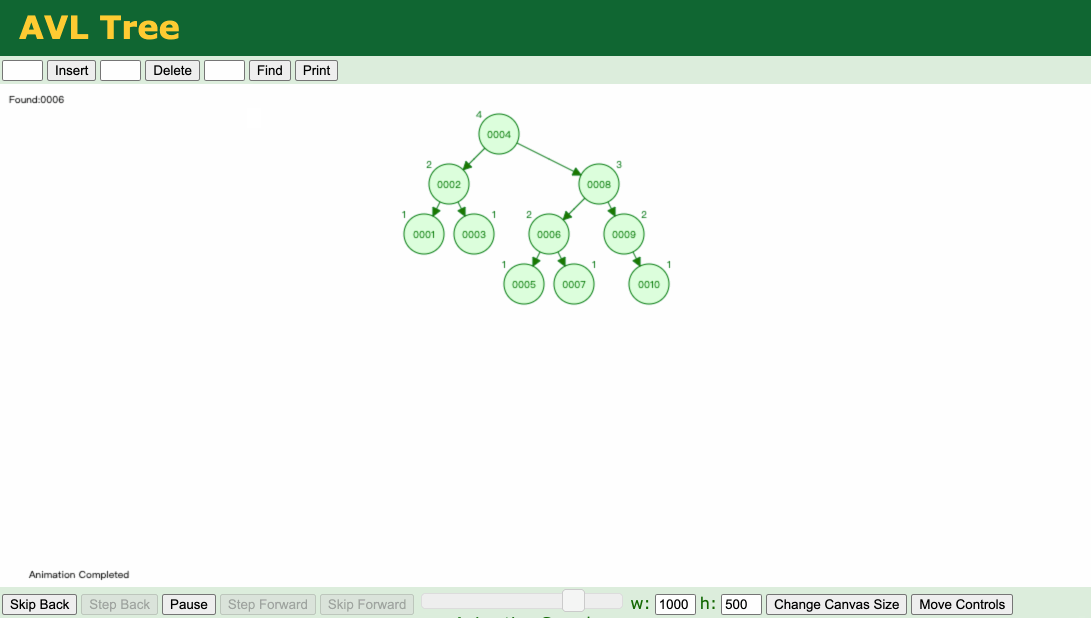
B+树彻底解决了回旋查找的问题
它和B树的共同特点是一个节点可以存两个值,B+树和B树的明显区别就在叶子节点,B+树用了一个链表去解决了回旋查找的问题(比如查找大于5的数,找到5之后,通过链表直接把后面的数字全拿出来了),所以范围查找的效率极高。
这也解释了为什么排序的时候要用索引去排序,因为B+树已经帮我们排好序了!我们按照索引排序的话,就不会触发文件内排序了!
上面的树和叶子节点的关系:
-
凡是非叶子结点出现的数组都会出现的叶子节点
-
非叶子节点只存储key,不存储value,这里的key就是这些数字索引,而叶子节点存储的除了key之外,还有value(数字的地址)















 143
143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









