一、介绍
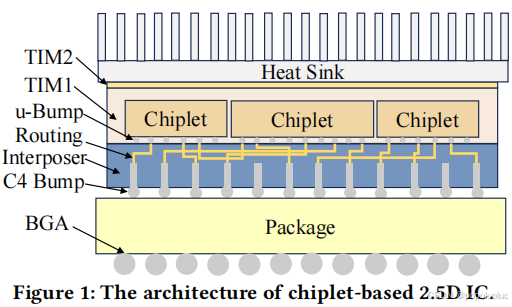
这张图展示了基于Chiplet技术的 2.5D IC架构 的组成部分,具体解读如下:
1. Heat Sink(散热器):
- 位于顶层,用于将运行过程中产生的热量有效散发,保持芯片的稳定性和性能。
2. TIM1 和 TIM2(Thermal Interface Material热界面材料):
- TIM1:放置在散热器与Chiplet之间,确保热量高效传导。
- TIM2:用于散热器与其它接触层之间的导热。
3. Chiplet:
- 这是2.5D架构的核心,每个Chiplet是功能独立的芯片模块,可以是逻辑芯片、存储芯片或其他功能芯片。
- 多个Chiplet并排放置,通过中介层互连。
4. u-Bump(微凸点,一般做在Chiplet底面上):
- 连接Chiplet和Routing Interposer(中介层)的关键元件。
- 微型焊点用于实现高密度的电气连接。
5. Routing Interposer(中介层):
用于连接各个Chiplet。
提供高密度互连,支持信号和电源的分配,同时降低延迟和功耗。
采用硅、玻璃或有机材料制成,内含TSV(硅通孔)或布线结构。
6. C4 Bump(C4凸点):C4 是指 Controlled Collapse Chip Connection,即“可控塌陷芯片连接”,它是一种广泛使用的 凸点互连技术。C4 技术通常用于将芯片(如处理器)直接连接到基板,支持高密度、高可靠性和高性能的封装方式。将不规则分布的信号引出到规则的栅格或网格阵列中,使其与 C4 凸点对接更加方便。通常由锡(Sn)或锡合金(如 SnPb、SnAgCu)制成。
7. BGA(球栅阵列):
- 封装底部的输出接口,用于将整个芯片封装连接到PCB(印刷电路板)。
8. Package(封装层):
- 连接整个架构至PCB的底层,负责提供机械支持、电气连接和进一步的散热功能。
二、架构设计
2.2 支持2.5D架构的原因:1. 高产,chiplet只需要支持子系统而不是原来的大系统,减少了尺寸,相同的硅晶圆预算下,产出更多的芯片。2.模块化设计,每个chiplet有自己的功能和特性,可使用不同的组合实现适应不同的场景。3.设计效率提高,一个成熟的chiplet可以视为硬件知识产权,设计公司可以用这些成熟的chiplet更高效的设计新产品。
2.3 架构模拟
采用系统级模拟器Gem5 来整合由基板规划引入的芯片延迟信息(网上有学习资料)

存在问题:
1).许多现有的仿真工具未能充分考虑芯片之间的复杂交互,导致不准确的性能预测。
2).现有的仿真工具通常缺乏对这些异构组件的支持,这限制了设计的灵活性和优化能力。
3).难以模拟复杂的通信协议。
2.4 功率分析
McPAT [21]被广泛用于对SoCs的功率进行建模,并已使用机器学习(ML)进行校准,以分析先进技术节点[22]中的芯片功率。
[22] J. Zhai, C. Bai, B. Zhu
et al.
, “McPAT-Calib: A RISC-V BOOM Microarchitecture
Power Modeling Framework,”
IEEE TCAD
, vol. 42, no. 1, pp. 243–256, 2023.
[23]
J. Zhai, Y. Cai, and B. Yu, “Microarchitecture Power Modeling via Artificial Neural
Network and Transfer Learning,” in
Proc. ASPDAC
, 2023, p. 302–307.
[24]
Q. Zhang, S. Li
et al.
, “PANDA: Architecture-Level Power Evaluation by Unifying
Analytical and Machine Learning Solutions,” in
Proc. ICCAD
, 2023, pp. 1–9.
[25]
J. Kim, V. C. K. Chekuri, N. M. Rahman
et al.
, “Chiplet/interposer co-design for
power delivery network optimization in heterogeneous 2.5-D ICs,”
IEEE TCPMT
,
vol. 11, no. 12, pp. 2148–2157, 2021.
[26]
X. Li, L. Chen, S. Chen
et al.
, “Power management for chiplet-based multicore
systems using deep reinforcement learning,” in
Proc. ISVLSI
, 2022, pp. 164–169.
软件介绍: 关于芯片的计算机辅助设计热仿真平台搭建
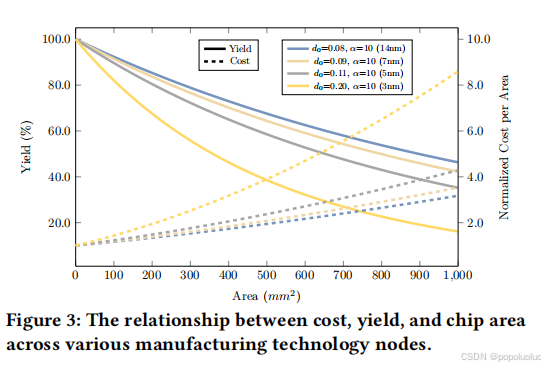
2.5 成本分析
集成人工智能技术将显著提高未来芯片开发中成本评估的效率和准确性。
2.6 Chiplet 架构的设计探索
探索方法大致分为分析性方法和基于机器学习的方法。分析方法的目的是创建轻量级的、可解释的模型,描述硬件设计配置和PPA(性能、功率、面积)之间的关系,然而,这些方法往往需要广泛的领域知识,并面临着在准确性的限制。为了克服这些限制,[31–37]利用基于学习的方法来系统地探索微体系结构设计或DNN加速器的芯片配置。Pal等人[38]开发了一个专门用于2.5D架构的设计空间探索的框架,重点关注在芯片分区和互连策略中的权衡,以优化性能和成本。等等。
目前的许多方法都集中在孤立的方面,如微体系结构配置或工作负载映射。需要一个集成的框架,以考虑多种设计因素,如热管理、功率传递和机械应力。未来的努力应该致力于创建统一的design space exploration(DSE)方法,以合并这些元素,
[31]
C. Bai, Q. Sun, J. Zhai
et al.
, “Boom-explorer: Risc-v boom microarchitecture
design space exploration framework,” in
Proc. ICCAD
, 2021, pp. 1–9.
[32]
J. Zhai and Y. Cai, “Microarchitecture design space exploration via pareto-driven
active learning,”
IEEE TVLSI
, vol. 31, no. 11, pp. 1727–1739, 2023.
[33]
C. Bai, J. Zhai, Y. Ma
et al.
, “Towards Automated RISC-V Microarchitecture Design
with Reinforcement Learning,” in
Proc. AAAI
, vol. 38, no. 1, 2024, pp. 12–20.
[34]
X. Yi, J. Lu, X. Xiong
et al.
, “Graph Representation Learning for Microarchitecture
Design Space Exploration,” in
Proc. DAC
, 2023, pp. 1–6.
[35]
S. Chen, S. Zheng, C. Bai
et al.
, “SoC-Tuner: An importance-guided exploration
framework for DNN-targeting SoC design,” in
Proc. ASPDAC
, 2024, pp. 207–212.
[36]
Z. Wang, J. Wang,
et al.
, “A hierarchical adaptive multi-task reinforcement learn
ing framework for multiplier circuit design,” in
Proc. ICML
, 2024.
[37]
W. Zhihai, W. Jie, Y. Qingyue, B. Yinqi
et al.
, “Towards next-generation logic
synthesis: A scalable neural circuit generation framework,” in
Proc. NeurIPS
, 2024
[38]
S. Pal, D. Petrisko, R. Kumar, and P. Gupta, “Design space exploration for chiplet
assembly-based processors,”
IEEE TVLSI
, vol. 28, no. 4, pp. 1062–1073, 2020.
[39]
J. Cai, Z. Wu, S. Peng
et al.
, “Gemini: Mapping and Architecture Co-exploration
for Large-scale DNN Chiplet Accelerators,” in
Proc. HPCA
, 2024, pp. 156–171.
[40]
Z. Tan
et al.
, “NN-Baton: DNN Workload Orchestration and Chiplet Granularity
Exploration for Multichip Accelerators,” in
Proc. ISCA
, 2021, pp. 1013–1026.
[41]
S. Schlag, T. Heuer, L. Gottesbüren, Y. Akhremtsev, C. Schulz, and P. Sand
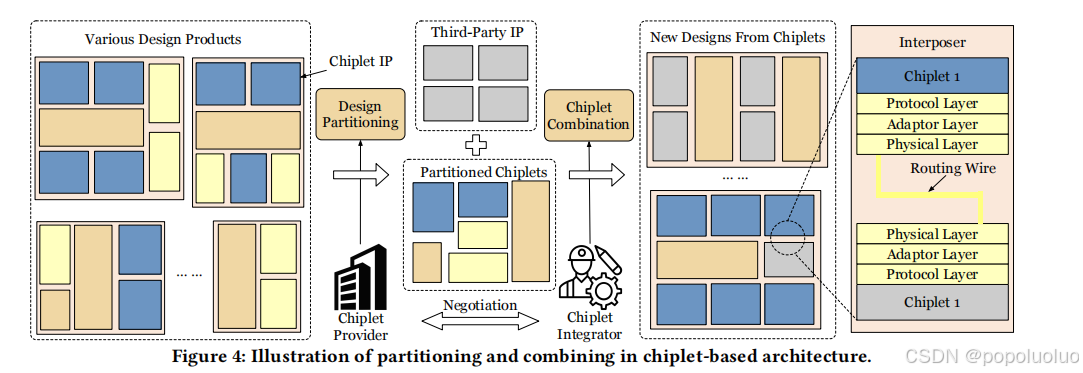
3. Chiplet的分割和互联
将一个复杂的系统设计分割成多个小的模块(Chiplet),可以简化设计过程。每个Chiplet可以独立开发,降低单个模块设计的复杂度。
实现最优分割涉及到一些挑战,如管理功能模块之间的耦合、最小化通信开销以及确保有效的资源分配。一旦系统被分割,组合阶段的重点是将这些芯片模块集成到一个内聚的系统中。这一阶段需要仔细优化拓扑结构和互连,以满足性能目标,同时最小化成本。
为了解决分割的挑战。KaHyPar [41]是一个超图划分工具,它可以最大限度地减少通信开销和资源重叠。Chen等人[19]使用递归树结构来优化SoC模块的划分和封装布局,解决了通信延迟和资源失衡问题。Chipletizer [42]采用多层分区和模拟退火来增强核心重用和降低成本。
[41]
S. Schlag, T. Heuer, L. Gottesbüren, Y. Akhremtsev, C. Schulz, and P. Sanders,
“High-quality hypergraph partitioning,”
ACM J. Exp. Algorithmics
, vol. 27, 2023.
[42]
F. Li, Y. Wang, Y. Wang
et al.
, “Chipletizer: Repartitioning SoCs for Cost-Effective
Chiplet Integration,” in
Proc. ASPDAC
, 2024, pp. 58–64.
关于组合,目标是优化芯片选择和互连拓扑。Li等人[43]提出了支持自适应互连配置的GIA(
集成栅极驱动
电路),并为芯片选择、拓扑生成和布局评估提供了一个自动化框架,实现了异构芯片的高效集成。Pal等人[38]引入了一个框架,用于探索不同应用程序的芯片配置,降低成本,同时满足性能限制,提高芯片的可重用性。
[38]
S. Pal, D. Petrisko, R. Kumar, and P. Gupta, “Design space exploration for chiplet
assembly-based processors,”
IEEE TVLSI
, vol. 28, no. 4, pp. 1062–1073, 2020.
[43]
F. Li, Y. Wang, Y. Cheng
et al.
, “GIA: A Reusable General Interposer Architecture
for Agile Chiplet Integration,” in
Proc. ICCAD
, 2022, pp. 1–9.
关于拓扑,[44]提出了风筝拓扑,优化芯片放置以提高吞吐量,而帕特里克等人的HexaMesh[45]采用六角形布局来最小化通信路径和最大化带宽。
[43]
F. Li, Y. Wang, Y. Cheng
et al.
, “GIA: A Reusable General Interposer Architecture
for Agile Chiplet Integration,” in
Proc. ICCAD
, 2022, pp. 1–9.
[44]
S. Bharadwaj, J. Yin, B. Beckmann, and T. Krishna, “Kite: A family of hetero
geneous interposer topologies enabled via accurate interconnect modeling,” in
Proc. DAC
. IEEE, 2020, pp. 1–6.
[45]
P. Iff, M. Besta, M. Cavalcante, T. Fischer, L. Benini, and T. Hoefler, “HexaMesh:
Scaling to Hundreds of Chiplets with an Optimized Chiplet Arrangement,” in
Proc. DAC
, 2023, pp. 1–6.
[46] H. Zheng, K. Wang, and A. Louri, “A versatile and flexible chiplet-based system
design for heterogeneous manycore architectures,” in
Proc. DAC
, 2020, pp. 1–6.
日益增加的异构性带来了一些挑战,比如管理跨芯片的不同功能和功率配置文件。未来的研究应探索自适应划分方法,动态调整不同芯片的特定需求,优化性能、功率和面积,热管理和机械应力之间的平衡。
3.2 互联和通信
对跨芯片的高速、低延迟通信的需求使系统集成和配置进一步复杂化,使互连和协议的设计成为系统效率的一个关键因素。
Feng等人[51]引入了一个集成了并行接口和串行接口的异构接口架构,允许在具有不同需求的芯片之间进行灵活的通信。这种体系结构在具有混合工作负载的系统中特别有利。
此外,与传统的电气互连相比,光通信技术可以提供显著的更高的数据传输速率,使大规模的多芯片系统能够处理更高的带宽需求[52]。Li等人[53]提出了HPPI,一种针对深度学习加速器优化的可重构光子互连,它提高了数据流效率和降低了能耗。
[51]
Y. Feng, D. Xiang, and K. Ma, “Heterogeneous die-to-die interfaces: Enabling
more flexible chiplet interconnection systems,” in
Proc. MICRO
, 2023, p. 930–943.
[52]
Y. Thonnart
et al.
, “POPSTAR: A robust modular optical NoC architecture for
chiplet-based 3D integrated systems,” in
Proc. DATE
, 2020, pp. 1456–1461.
[53]
G. Li and Y. Ye, “HPPI: A high-performance photonic interconnect design for
chiplet-based DNN accelerators,” IEEE TCAD, vol. 43, no. 3, pp. 812–825, 2024
通信路由算法也已经发展到可以处理动态流量和异构工作负载的复杂性,Feng等人[54]开发了负优先路由算法,结合了安全和不安全的流控制策略,以优化带宽利用率和减少延迟。
[54]
Y. Feng, D. Xiang, and K. Ma, “A scalable methodology for designing efficient
interconnection network of chiplets,” in
Proc. HPCA
, 2023, pp. 1059–1071.
[55]
E. Taheri, S. Pasricha
et al.
, “DeFT: A Deadlock-Free and Fault-Tolerant Routing
Algorithm for 2.5D Chiplet Networks,” in
Proc. DATE
, 2022, pp. 1047–1052.
随着系统规模的扩大,跨通信层处理电源管理和维护数据完整性将变得越来越重要。实时分析和人工智能驱动是有前途的方法,使通信策略能够动态优化。
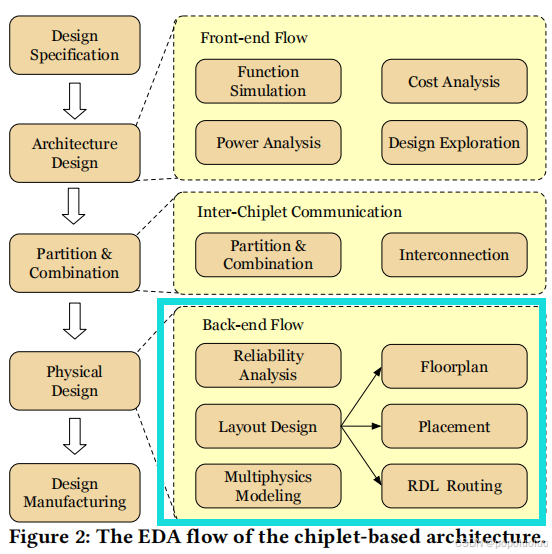
4. Chiplet体系结构的物理设计
4.1物理设计流程
4.2 布局和放置
关于芯片系统的放置,有两个关键问题。首先,需要一个精确反映布局设计影响的评估框架,考虑诸如热性能、通信延迟和扭曲等指标。其次,布局优化算法必须达到较高的求解质量和快速的求解速度。在chiplet中,放置通常是指确定芯片在插入器上的位置。启发式方法使用指定的数据结构来表示放置解决方案,并利用模拟退火(SA)算法来优化目标,如面积、宽度和应力。
[56]
H.-W. Chiou, J.-H. Jiang
et al.
, “Chiplet placement for 2.5 D IC with sequence
pair based tree and thermal consideration,” in
Proc. ASPDAC
, 2023, pp. 7–12.
[57]
Y. Ma, L. Delshadtehrani
et al.
, “TAP-2.5D: A Thermally-Aware Chiplet Placement
Methodology for 2.5D Systems,” in
Proc. DATE
, 2021, pp. 1246–1251.
[58]
A. Coskun
et al.
, “Cross-layer co-optimization of network design and chiplet
placement in 2.5-D systems,”
IEEE TCAD
, vol. 39, no. 12, pp. 5183–5196, 2020.
[59]
Y. Hsu, M.-H. Chung, Y.-W. Chang
et al.
, “Transitive Closure Graph-Based
Warpage-Aware Floorplanning for Package Designs,” in
Proc. ICCAD
, 2022.
[60]
Y. Duan, X. Liu, Z. Yu
et al.
, “RLPlanner: Reinforcement learning based floorplan
随着人工智能的发展,放置算法也受益于基于ml的方法,Molter等人[61]采用贝叶斯优化方法进行热感知芯片布局优化,Deng等人[62]提出了一种基于图神经网络的芯片排列顺序排序框架,利用学习到排序的方法来选择最优的芯片排列顺序。一种主要基于RankNet [80]的网络体系结构
被设计,并结合图神经网络进行特征提取。
[61]
M. Molter, R. Kumar, S. Koller
et al.
, “Thermal-Aware SoC Macro Placement
and Multi-chip Module Design Optimization with Bayesian Optimization,” in
Proc. ECTC
, 2023, pp. 935–942.
[62]
Z. Deng, Y. Duan, L. Shao
et al.
, “Chiplet Placement Order Exploration based on
Learning to Rank with Graph Representation,” in
Proc. ISEDA
, 2024, pp. 605–610.
[80]
C. Burges, T. Shaked, E. Renshaw
et al.
, “Learning to rank using gradient descent,”
in
Proc. ICML
, 2005, pp. 89–96.
总体而言,现有的方法可以在接受时间内处理小规模的2.5D芯片集,并具有良好的性能。然而,未来的2.5D芯片系统的规模可能会增加到几十个甚至更多的小芯片,而上面提到的算法需要几个小时来处理包含更多小芯片的系统。因此,寻找更有效的芯片布局算法和工具来缩短优化时间,是大规模2.5D IC物理设计的重要研究方向。
在2.5D/3D封装中,
interposer也叫RDL(
Redistribution Layer),用于连接堆叠的芯片,而Routing负责单个芯片内部连接
4.4
Multiphysics Simulation
未来,基于机器学习的方法正在被用于多物理模拟,以加速模拟。例如,Chen等人[70]提出了一种新的图卷积网络架构,用于估计基于2.5D芯片的系统中的热图,利用全局功率特征和先进的技术。
[67]
A. Inc. (2024) Ansys icepak. [Online]. Available:
https://www.ansys.com/
products/thermal/ansys-icepak
[68] (2024) Hotspot7.0. [Online]. Available:
https://github.com/uvahotspot/HotSpot
[70]
L. Chen, W. Jin, and S. X.-D. Tan, “Fast thermal analysis for chiplet design based
on graph convolution networks,” in
Proc. ASPDAC
, 2022.
4.5 其他议题
除了讨论的物理设计考虑之外,还有几个其他关键主题影响着芯片系统整体性能和可靠性。其中一个主题是信号完整性(SI)和电源完整性(PI),它们在电子设计中起着至关重要的作用,特别是在高速数字电路中的信号传输质量和可靠性方面。
5
Challenges and Future Directions
1. 电路的功能和可靠性受到电、磁、热、机械等各种应力因素的影响。目前还没有考虑所有相关因素的全面平台;相反,许多单点工具不能提供整体视图或集成反馈,这可能会降低设计效率。
2.早期的多物理建模工具依赖于大量的数学和物理模型,而这种建模的计算密集型特性可能会减慢设计过程,阻碍整体设计效率。
3. 多个芯片之间的相互作用需要先进的算法,目前的工具通常缺乏有效地建模这些芯片间连接的能力。
4.2.5D IC的设计规则检查需要更复杂的方法,因为控制不同芯片之间相互作用的规则可能与单模设计有显著不同。现有的工具可能无法装备来处理多芯片交互的细微差别,这增加了设计错误的风险。
5.必须开发支持多领域模拟的EDA工具,并提供符合2.5D IC设计的独特要求的集成解决方案。这包括增强工具的互操作性,允许无缝的数据交换,以及实现机器学习算法来优化设计工作流。
6
Conclusion
展望未来,随着人工智能和机器学习等技术的进步

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









