






软件测试
就业方向(功能测试+任一种)

python+测试工具
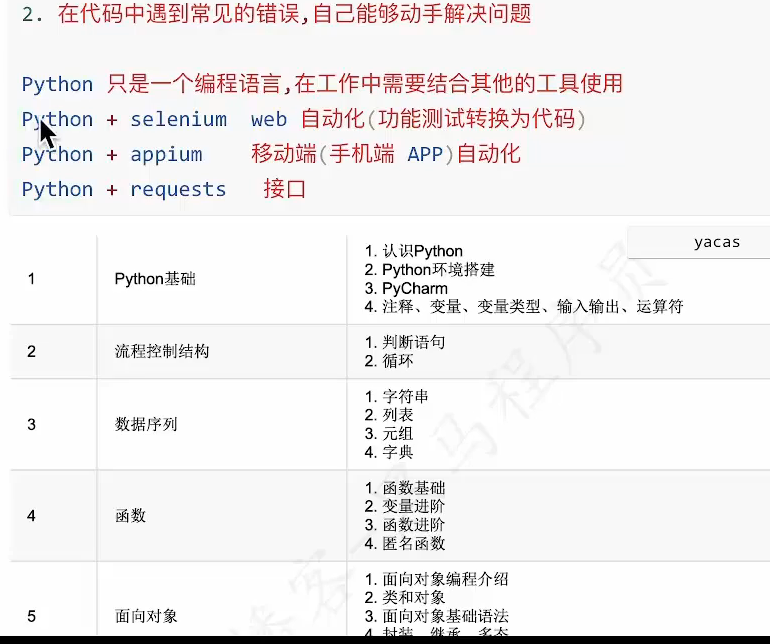
框架的完善
- 过程控制
- 日志记录
- 测试报告
- UI画面回放
考点
1.退出的不同?
driver.close() # 关闭窗口,退出浏览器
driver.quit() # 关闭窗口
2.selenium底层原理
webdriver协议(Http接口),webdriver是浏览器的驱动
对一个不确定的功能测试,首先要明确需求
基础概念
测试分类
测试阶段

代码可见度

质量模型
功能,性能,兼容,易用,安全,可靠性,移植性,维护性。
测试流程
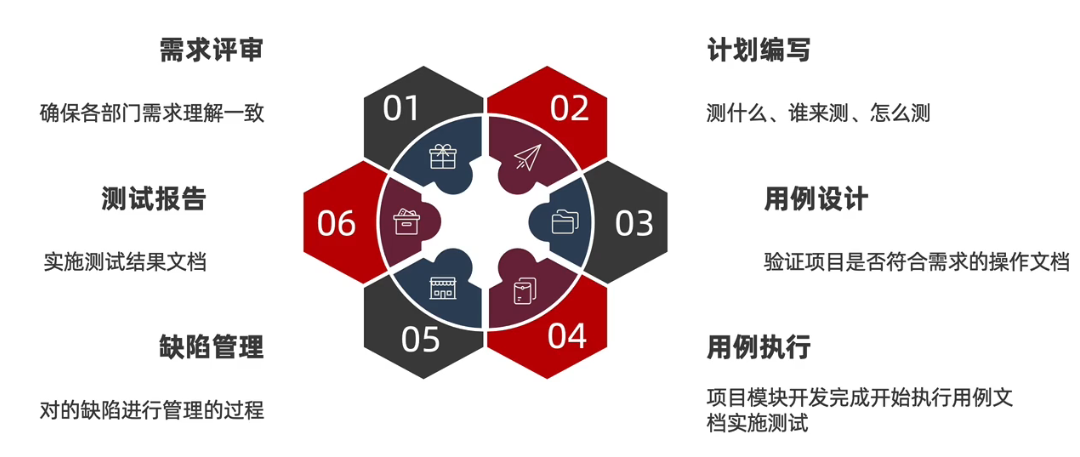
测试用例
作用:防止漏测,实施规范
正向用例:一条尽可能覆盖多条(数测试模块中最多正向方向的)
逆向用例:每一条都是单独用例
用例设计编写格式:

测试方法
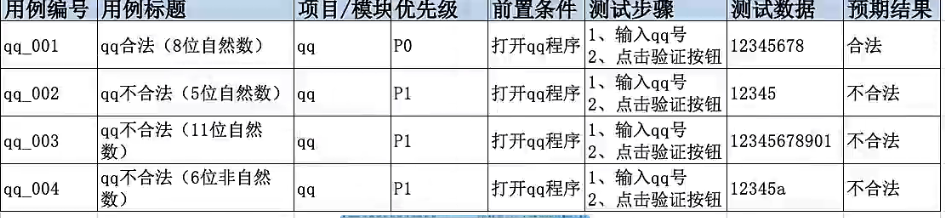
4.1等价类划分(针对穷举场景)
步骤:
1.明确需求
2.确定有效等价,无效等价
3.根据上面设计数据,编写用例
案例:验证6-10位qq合法性
4.2边界值测试方法(针对边界限定问题)
边界范围结点(7个点)
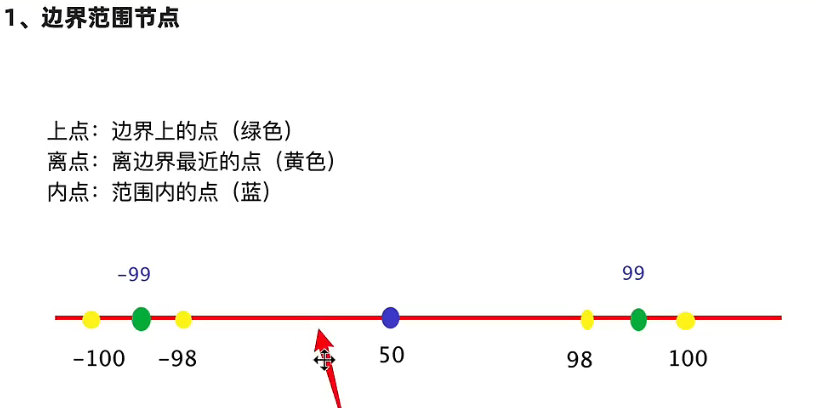
步骤:
1.明确需求
2.确定有效等价,无效等价
3.确定边界值
4.根据上面设计数据,编写用例
优化(7点化5点)
上点,内点是必须的,离点按照开内闭外,开区间选择内部离点,闭区间选择外部离点
单个输入框常用的方式是:边界+等价类
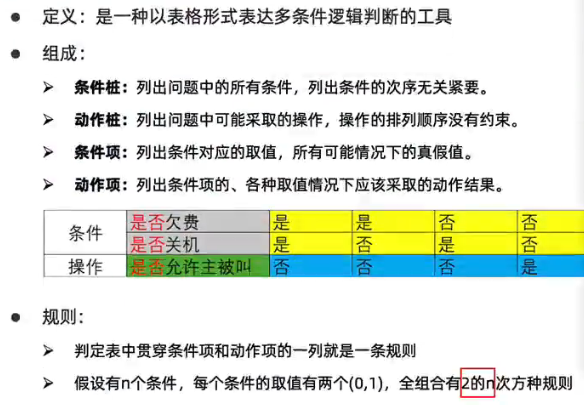
4.3判定表法(针对多条件依赖测试)
步骤:
1.明确需求
2.画出判定表
- 列出条件桩和动作桩
- 填写条件项,
- 根据条件项组合确定动作项
- 简化,合并相似规则
3.设计数据,编写用例
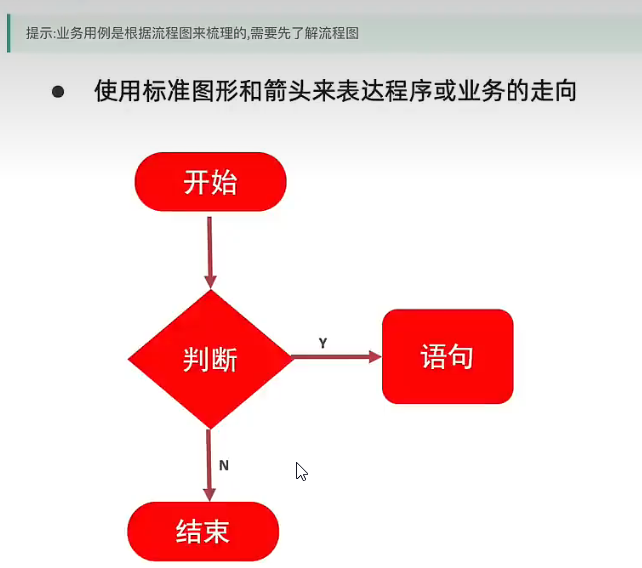
4.4场景法
业务测试覆盖需要使用流程图
先测试业务,再测试单功能,单模块,单页面
流程图使用椭圆做开始结束,使用棱形表判断,使用方框表语句
4.5错误推荐法
缺陷
概念:软件中存在的各种问题,称为缺陷,简称bug;
标准:
- 少功能
- 多功能
- 功能错误
- 隐形错误
- 易用性
产生原因:

缺陷类型:
- 功能错误
- ui页面错误
- 兼容性
- 数据库
- 易用性
- 架构缺陷
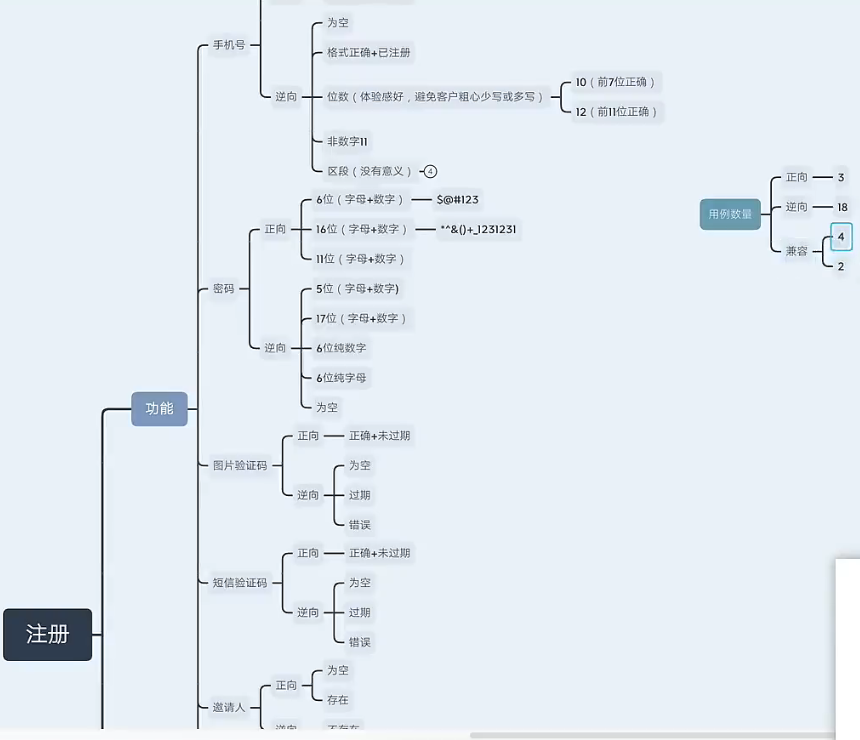
注册案例
缺陷编写
发现bug后首先要确保缺陷可以复现
描述缺陷

登录模块案例
3.1登录测试点
登录测试点分为
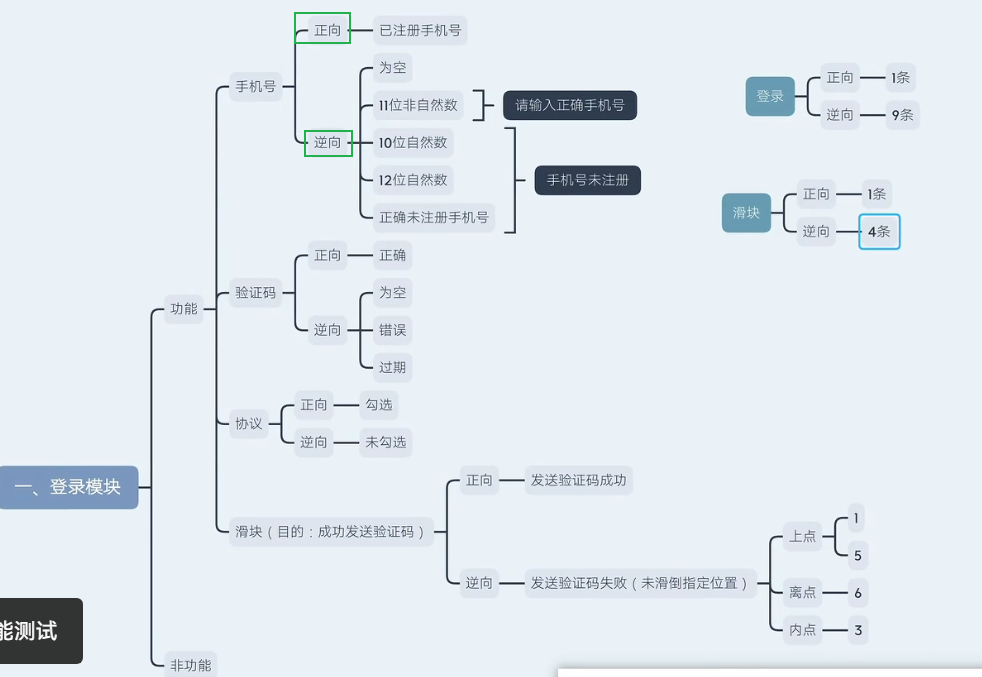
非功能主要是测试五大浏览器的兼容性,兼容与UI布局 还有滑块的拖动。
3.2登录用例编写
用例标题写法:期望结果(实现依据原因)
优先级成功的写p0
项目,前置条件一般不变,测试数据跟前置条件可以先写
测试步骤即实际操作过程,若是边界值要使用次数表明,预期结果根据预测而定
| 用例-模块-编号 | 用例标题 | 项目/模块 | 优先级 | 前置条件 | 测试步骤 | 测试数据 | 预期结果 |
|---|---|---|---|---|---|---|---|
| login-01 | 发送验证码成功(滑块到指定位置) | 滑块 | p0 | 1.输入手机号 2.打开滑块界面 | 1.拖动滑块到指定位置 | 1.手机号:正确手机号 | 手机号收到验证码成功 |
| login-02 | 发送验证码失败(滑块一次未到指定位置) | 滑块 | p1 | 1.输入手机号 2.打开滑块界面 | 1.拖动滑块一次未到指定位置 | 1.手机号:正确手机号 | 1.手机号没有收到验证码2.滑块抖动效果1次3.回到初始位置 |
| login-03 | 发送验证码失败(滑块三次未到指定位置) | 滑块 | p1 | 1.输入手机号 2.打开滑块界面 | 1.拖动滑块三次未到指定位置 | 1.手机号:正确手机号 | 1.手机号没有收到验证码2.滑块抖动效果3次3.回到初始位置 |
| login-04 | 发送验证码失败(滑块五次未到指定位置) | 滑块 | p1 | 1.输入手机号 2.打开滑块界面 | 1.拖动滑块五次未到指定位置 | 1.手机号:正确手机号 | 1.手机号没有收到验证码2.滑块抖动效果5次3.回到初始位置 |
| login-05 | 发送验证码失败(滑块错误次数达到6次) | 滑块 | p1 | 1.输入手机号 2.打开滑块界面 | 1.拖动滑块六次未到指定位置 | 1.手机号:正确手机号 | 1.手机号没有收到验证码2.滑块抖动效果5次3.滑块消失,提示重试 |
基础测试最后有总结,可以观看5-14-总结_哔哩哔哩_bilibili快速回顾
python
input("enter your name") # input函数只能输入str,所以输入数字时需要用int(str)强转
\ 表转义, # 表注释 ,e9表科学计数法中的10的9次方 , r '' 单引号中内容不转义 // 表整除
''' damage
... kewu ''' # 表多行内容
a = 'ABC',创建了字符串'ABC'和变量a,并把a指向'ABC'
b = a,创建了变量b,并把b指向a指向的字符串'ABC':
ord("A") 65 # ord()函数获取字符的整数表示,
chr(66) 'B'# chr()函数把编码转换为对应的字符
len('中文'.encode('utf-8')) 1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
'Hello, %s' % 'world' # 先正常写字符串,接着空格 % '替换字符'
'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125) # :后面的.1f指定了格式化参数(即保留1位小数)
print(f"hello, {x}") # f-string格式化,这里就输出值
f"断言失败: {count=}" # 这里会将count变量及count值一起输出,是新特性
2.1list和tuple
python中一种内置的数据类型列表:list,list是可变的,而str是不可变,尽管指向可以改变
a = ['porter','damage'] # 通过a[-1] 或 a[len(a) - 1]获取到数组最后一个元素
a.append("fly") # 往数组末尾加元素,删除末尾元素用a.pop()
a.insert(1,"dd") #往指定索引处插入元素,删除指定索引元素a.pop(1),替换某个索引处元素直接赋值
p = ['asp', 'php'] s = ['python', 'java', p, 'scheme'] #要拿到'php'可以写p[1]或者s[2][1]
另一种有序列表叫元组:tuple,tuple一旦初始化就不能修改,因此比list更安全
t = (1, 2) # 基本定义 t = () 只有1个元素的tuple定义时必须加一个逗号,来消除歧义
# turple里面的元素也可以是列表,修改列表中元素是可以的,即指向元素不变
2.2条件判断
age = 3
if age >= 18: # 这里的: 相当于{},他会把下面的缩进内容一起执行了
print('adult')
elif age >= 6:
print('teenager')
else:
print("kid")
2.3循环与匹配
匹配
score = "B"
match score:
case 'A':
print("A")
case 'B':
print("B")
case _:
print("表其他任何情况")
循环(for in ; while)
在循环过程中,也可以通过
continue语句,跳过当前的这次循环,直接开始下一次循环。
range(101) # 生成0-100的list列表
for x in [1,2,3]:
sum = sum + x;
print(sum)
sum = 0
n = 99
while n > 0:
sum = sum + n
n = n - 2
print(sum)
2.4字典
dict
字典即dict,即其他语言中的Map,使用键-值(key-value)存储,具有极快的查找速度。
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85} # 直接赋值,里面用逗号隔开
print(d['Michael'])
print("Bob"in d ) # 判断是否有该key
d.get('BOb',10) # dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
set 也是一组key的集合,但不存储value.在set中,没有重复的key。
重复元素在set中自动被过滤:重复元素在set中自动被过滤
remove(key)方法可以删除元素:
2.5函数
hes(254) # 可以将十进制254转为16进制0xfe 255/16 = 15余14
0x表16进制,余数先出来,先从右边开始,商大于16就一直除 15表f,14表e,从右边写起
定义函数
def my_abs(x): # 函数名(x):
if not isinstance(x, (int, float)): # 对参数类型做检查,只允许整数和浮点数类型的参数
raise TypeError('bad operand type')
if x >= 0:
return x
else:
return -x
空函数
def nop():
pass # pass 起到占位作用,可以让代码运行起来
返回多个值
Python的函数返回多值其实就是返回一个tuple ,在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值
import math
def quadratic(a, b, c):
k = b*b - 4*a*c
x1 = (-b + math.sqrt(k)) / (2*a)
x2 = (-b - math.sqrt(k)) / (2*a)
return x1, x2
2.5.1函数参数
函数的参数(默认参数必须指向不变对象)默认参数就是在参数后面赋值,如果没有传参就默认使用该默认值 例如:def power(x, n=2):
# 假设参数定义成L = [] ,因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了
def add_end(L=None): # 这里的None就是不变对象,使用之后就可以避免多次调用后出现end添加多次
if L is None:
L = []
L.append('END')
return L
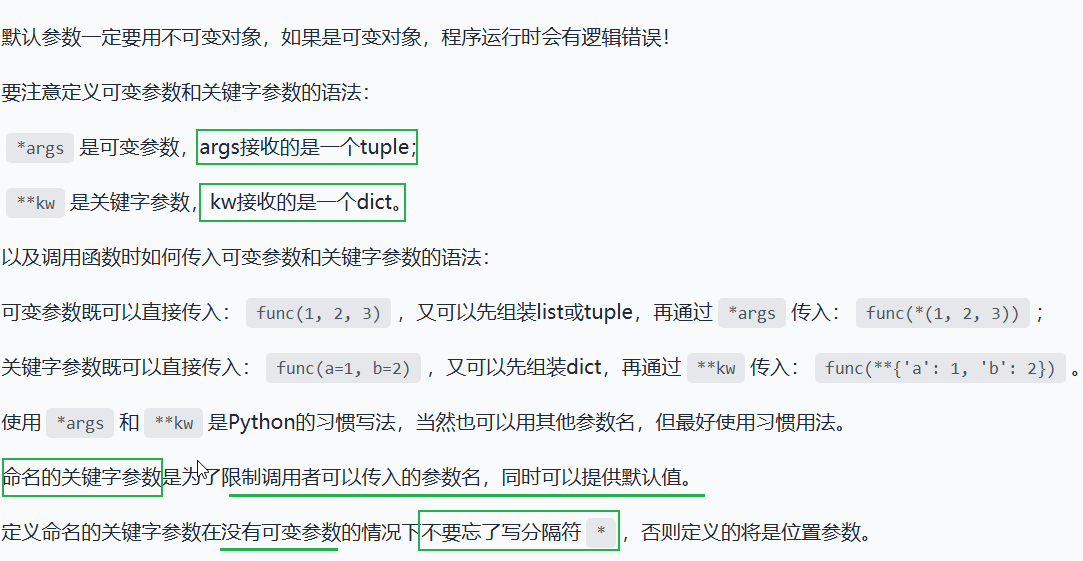
可变参数, 直接在参数前面加*,这里的可变具体是指参数的数量
def calc(numbers): # 这里的numbers可以变为*numbers,这样就可以直接calc(1,2,3)随意参数调用
sum = 0
for n in numbers:
sum = sum + n * n
return sum
calc([1, 2, 3]) # 组装一个list调用,假设已有一个l列表,我们也可以calc(*l)去调用该方法
calc((1, 3, 5, 7)) # 组装一个tuple调用
关键字参数,** kw
允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict(键值对)
可以扩展函数的功能,因此放于函数参数的最后一位
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
# 调用,假设已有一个现成字典d,那么可以则直接person('Adam', 45,**d)
person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'} # 输出
命名关键字参数 即使用*隔开,
*后面的参数被视为命名关键字参数
def person(name, age, **kw):
if 'city' in kw: # 检测是否传入city参数
# 有city参数
pass
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错
def person(name, age, *args, city, job):
参数组合,顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
2.5.2递归函数
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
针对尾递归优化的语言可以通过尾递归防止栈溢出。
2.6高级特性
2.6.1切片
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。还可以省略0,即L[:3]。
倒向切片:L[-3:] 表示取后面三个元素,由于倒数第一个元素的索引是-1,所以L[-3:-1]即取索引为-3.-2的元素。
L[:10:2] # 前10个数,每两个取一个
L[::5] # 所有数,每5个取一个
L[:] # 列出所有数
'abcde'[:3] # 'abc' 对于字符串同样适用
def trim(s):
start = 0
while start<len(s) and s[start].isspace(): # 找到非空白字符的索引
start += 1
end = len(s) -1
while end >= start and s[end].isspace():
end -= 1
return s[start:end+1] # hello s[0:5],这里的end是索引
2.6.2迭代
通过collections.abc模块的Iterable类型判断一个对象是可迭代对象
from collections.abc import Iterable
isinstance(123, Iterable) # 整数是否可迭代
False
各种迭代
for key in dict # 遍历字典中的key
for value in d.values() # 遍历字典中的value
for k,v in dict.item() # 遍历字典中的key跟value
for ch in 'ABC': # 遍历字符串
for i, value in enumerate(['A', 'B', 'C']):
print(i, value) # 可打印索引跟列表元素
小案例
def findMinAndMax(L):
if not L: # 判断是否为空列表
return (None, None)
min_val = max_val = L[0] # 设置第一个元素为最值
for num in L[1:]: # 遍历接下来元素
if num < min_val:
min_val = num
if num > max_val:
max_val = num
return (min_val, max_val)
2.6.3列表生成器
2.9模块
功能模块我们可以在里面写方法,接着我们在要使用的类中引入该类,
2.9.1sys模块
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# 以上两行运行程序在linux,mac,unix上运行,并且编码为utf-8
' a test module ' # 模块注释
__author__ = 'Michael Liao' # 作者
import sys
def test():
args = sys.argv # argv是sys中的一个属性,args则是一个列表,一般默认存储[hello,world]
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__': # 编译时,会把特殊变量_name_变为_main_,并调用上述方法,故此我们可以在这里面添加一些测试代码
test()
2.9.2安装第三方模块
通过python的包管理工具pip去安装各种第三方库
作用域
__xxx__ # 这样的变量是特殊变量
_xxx # 这样的函数或变量就是非公开的(private)
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
2.10面向对象编程
2.10.1类和实例
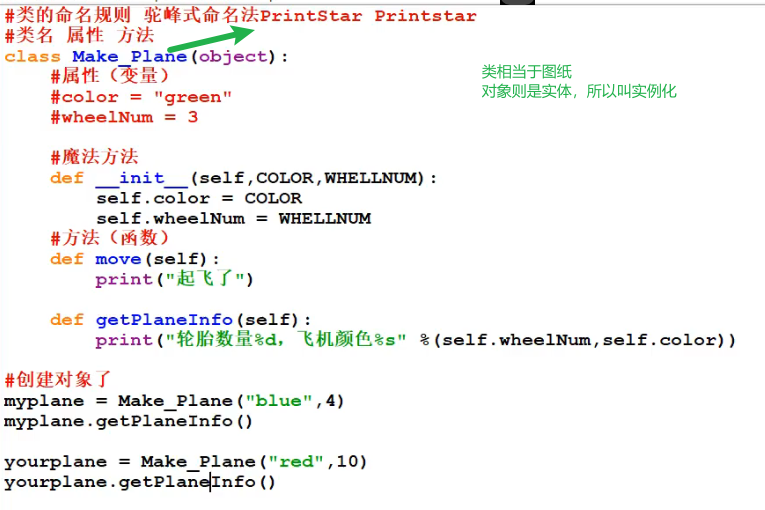
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响;创建实例是通过**类名+()**实现的;
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private)
变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量
不能直接访问__name是因为Python解释器对外把__name变量改成了_Student__name
eg: self._color = Color,
def get_score(self):
return self.__score
def set_score(self, score):
self.__score = score # 通过get,set方法访问私有变量
2.10.2获取对象信息
type(123) # 直接获取类
isinstance('a', str) # 判断是否属于后面数据类型
hasattr(obj, 'y') # 有属性'y'吗?
False
>>> setattr(obj, 'y', 19) # 设置一个属性'y'
>>> hasattr(obj, 'y') # 有属性'y'吗?
True
>>> getattr(obj, 'y') # 获取属性'y'
19
>>> obj.y # 获取属性'y'
# 从文件流fp中读取图像,我们首先要判断该fp对象是否存在read方法,如果存在,则该对象是一个流,如果不存在,则无法读取。hasattr()就派上了用场。
def readImage(fp):
if hasattr(fp, 'read'):
return readData(fp)
return None
2.12错误与异常处理d
2.12.1错误处理
概念:当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
try:
print('try...')
r = 10 / int('2')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e: # 如果其是上述子类,则该异常永远捕获不到,因被截胡
print('ZeroDivisionError:', e)
else: # 如果没有被上述异常捕获就会执行eles语句
print('no error!')
finally: # 这句是一定执行的,但可以没有
print('finally...')
print('END')
记录错误
Python内置的logging模块,可以把错误堆栈打印出来,然后分析错误原因,同时,让程序继续执行下去
raise语句如果不带参数,就会把当前错误原样抛出。由于当前函数不知道应该怎么处理该错误,所以,最恰当的方式是继续往上抛,让顶层调用者去处理。
2.12.2调试
断言:python -O err.py,关闭后,你可以把所有的
assert语句当成pass来看。assert condition, "error_message"
condition是你希望测试的条件。它应该是一个布尔表达式(即True或False)。"error_message"是一个可选的错误消息,当condition为False时,将会显示这个消息。
def foo(s):
n = int(s)
assert n != 0, 'n is zero!' # 断言n!=0为true,如果fasle则会报assertError:n is zero!
return 10 / n
logging
logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。
另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件
import logging
logging.basicConfig(level=logging.INFO) # 设置级别
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
pdb(启动Python的调试器pdb):让程序以单步方式运行,可以随时查看运行状态
pdb.set_trace() # 运行到这里会自动暂停
p n # 查看某个变量的值
c # 继续执行下一步
2.12.3单元测试
2.13IO编程d

Selenium
5.1原理与安装
原理:
- 自动化程序调用Selenium 客户端库函数(比如点击按钮元素)
- 客户端库会发送Selenium 命令 给浏览器的驱动程序
- 浏览器驱动程序接收到命令后 ,驱动浏览器去执行命令
- 浏览器驱动程序获取命令执行的结果,返回给我们自动化程序
- 自动化程序对返回结果进行处理
总结:python------>selenium----->浏览器的驱动------>浏览器
安装浏览器驱动及pip安装客户端库
浏览器驱动根据浏览器的不同进行安装
pip安装客户端库只需要在命令行中输入``
5.2选择元素
选择元素时需要选择到最深层的,如输入就是input,点击就是button
from selenium.webdriver.common.by import By
# 初始化代码 ....
# wd 是webdriver wd.find_element(By.XPATH,'') 获得的是webElement
wd.find_element(By.ID, 'username').send_keys('byhy')
wd.find_elements(By.CLASS_NAME, 'password').send_keys('sdfsdf')
wd.find_element(By.TAG_NAME, 'div').send_keys('sdfsdf')
wd.find_element(By.CSS_SELECTOR,'button[type=submit]').click()
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
5.3等待元素
5.3.1隐式等待
隐式等待也叫全局等待,后续所有find_element都会遵循这个
wd.implicitly_wait(10) # 如果找不到元素, 每隔 半秒钟 再去界面上查看一次, 直到找到该元素, 或者 过了10秒 最大时长。
5.3.2强制等待
time.sleep(1)
5.4操作元素
element.clear() # 清除输入框中内容
element.send_keys('dd') #输入框中输入内容
element.text # 获取元素 展示在界面上的 文本内容
element.get_attribute('value') # 获取输入框中内容,innerText 和 textContent 的区别是,前者只显示元素可见文本内容,后者显示所有内容(包括display属性为none的部分)
element.get_attribute("class")# 获取元素的属性值
element.get_attribute('outerHTML')# 整个元素对应的HTML文本内容,内部的HTML文本内容则是innerHTML
wd.quit() # wd是webdrive对象,关闭浏览器窗口
5.5css表达式
直接子元素是直接包含在标签里面(只有一层),后代元素就是在标签里面。
在浏览器中的element中按住ctrl+f可以通过.class属性来验证选中的元素。
css 选择器支持通过任何属性来选择元素,语法是用一个方括号 [] 。
a[href*="miitbeian"] # 选择a节点,里面的href属性包含了 miitbeian 字符串
a[href^="http"] #选择a节点,里面的href属性以 http 开头
a[[href$='.com'] #选择a节点,里面的href属性以 gov.cn 结尾
div[class=misc][ctype=gun] #选择标签有多个属性的
5.5.1组选择
elements = wd.find_elements(By.CSS_SELECTOR, 'div,#BYHY') #选择div标签中id为BYHY
wd.find_element(BY.CSS_SELECTOR,'.animal','plant') # 选择所有class 为 plant 和 class 为 animal 的元素
5.5.2按次序选择子节点
span:nth-child(2) # span标签下的第二个节点
p:nth-last-child(2) # p标签下的倒数第二个节点
span:nth-of-type(1) # 按类型
p:nth-last-of-type(2) # 按类型倒数
p:nth-child(even) # 父元素的偶数结点
p:nth-of-type(odd) # 父元素的奇数结点
5.6frame窗口切换
切换元素选择范围
wd.switch_to.frame(wd.find_element(By.TAG_NAME, "iframe")) # 切换到该层窗口 wd.switch_to.default_content() # 切换为默认html标签中
切换窗口
mainWindow = wd.current_window_handle # mainWindow变量保存当前窗口的句柄
wd.switch_to.window(mainWindow) # 切回老窗口
for handle in wd.window_handles: # 遍历所有已经打开的窗口
# 先切换到该窗口
wd.switch_to.window(handle)
# 得到该窗口的标题栏字符串,判断是不是我们要操作的那个窗口
if 'Bing' in wd.title:
# 如果是,那么这时候WebDriver对象就是对应的该该窗口,正好,跳出循环,
break
5.7选择框
select_by_value('')
select_by_index(0)
select_by_visible_text('') # 根据选项的 可见文本 ,选择元素。
deselect_by_value() # 根据选项的value属性值, 去除 选中元素,value可替换为index...
deselect_all # 去除选中的所有元素
多选
# 导入Select类
from selenium.webdriver.support.ui import Select
# 创建Select对象
select = Select(wd.find_element(By.ID, "ss_single"))
# 清除可选框
select.delect_all();
# 通过 Select 对象选中小雷老师
select.select_by_visible_text("小雷老师")
select.select_by_value("小红老师")
5.8实战技巧
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://www.baidu.com/')
from selenium.webdriver.common.action_chains import ActionChains
ac = ActionChains(driver) # 获取鼠标对象
# 鼠标移动到 元素上
ac.move_to_element(
driver.find_element(By.CSS_SELECTOR, '[name="tj_briicon"]')
).perform()
调整元素到可见区
driver.execute_script("arguments[0].scrollIntoView({block:'center',inline:'center'})", job)
# js对象的 scrollIntoView 方法,就是让元素滚动到可见部分
#block:'center' 指定垂直方向居中 inline:'center' 指定水平方向居中
冻结窗面(在控制台输入后,过五秒会进入debugger模式,这五秒内可以把鼠标放在会消失的元素上)
setTimeout(function(){debugger}, 5000)
5.8.0案例
# 让页面最大化的方法
driver.maximize_window()
# 获取页面的大小 {'width': 1552, 'height': 840}
print(driver.get_window_size())
# 获取当前网站路径 https://www.bilibili.com/
print(driver.current_url)
# 获取所有窗口代数,并存储在列表中
print(driver.window_handles)
print(driver.current_window_handle) # 当前窗口
driver.get_screenshot_as_file('1.png') # 保存当前图片
time.sleep(3)
# 先定位到上传文件的 input 元素
ele = wd.find_element(By.CSS_SELECTOR, 'input[type=file]')
# 再调用 WebElement 对象的 send_keys 方法(可多次)
ele.send_keys(r'h:\g02.png')
入门案例

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Edge() # 启动浏览器
driver.get("https://baidu.com") # 进入测试页面
A = driver.find_element(By.XPATH,'//*[@id="kw"]') # 输入框元素
B = driver.find_element(By.XPATH,'//*[@id="su"]') # 按钮元素
A.send_keys("北京时间") # 输入内容,还可以导入Keys包,里面封装了ctrl键
B.click() # 点击按钮
time.sleep(1) # 强制等待网页渲染
html = driver.page_source # 获取网页源码
count = html.count('damag') # 统计次数
assert count > 1,f"断言失败:{count=}"
driver.get_screenshot_as_file('page.png') # 截屏
driver.close() # 关闭浏览器
测试页面(web自动化框架封装)
Pom(page object model)+Pytest
对页面进行类的封装,页面中有三个元素,一个登录操作,故class类中有三个属性及一个行为
属性需要我们去先选中元素,然后对其实例化,实例化是为了后面能更好的使用
pages.py
class LoginPage():
ipt_username = LazyElement(BY.CssSelector, '#TANGRAM__PSP_11__userName')
ipt_password = LazyElement(By.XPath,'//*[@id="TANGRAM__PSP_11__password"]')
# 开始时不检查是否存在该元素,而且该元素时有参数变化,所以在可以在控制台术定位该元素$x('//p[@id='']')
btn_login = LazyElement(By.XPATH,'//*[@id="TANGRAM__PSP_11__submit"]',check_on_init=False)
def login(self,username,password):
self.sendkeys(self.ipt_username,username) # 操作封装在一起,这里是以ipt_username.sendkeys(username)
self.sendkeys(self.ipt_password,password)
self.click(self.btn_login)
test_web
from selenium import webdriver
from selenium.webdriver.common.by import By
from pages import LoginPage # 从文件中引入类名(class)
dirver = webdriver.Edge()
dirver.get("http://baidu.com")
dirver.find_element(By.XPATH, '//*[@id="s-top-loginbtn"]').click()
def test_login(): # test_开头表测试方法
page = LoginPage(dirver) # 实例化登录对象
page.login("damage","123456") # 对象调用方法行为
input("please enter")
5.8.1对话框
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://cdn2.byhy.net/files/selenium/test4.html')
# --- alert ---
driver.find_element(By.ID, 'b1').click()
# 打印 弹出框 提示信息
print(driver.switch_to.alert.text)
# 点击 OK 按钮 ,如果是取消就是accept改为dismiss()
driver.switch_to.alert.accept()
Prompt 弹出框:需要用户输入一些信息,提交上去
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(5)
driver.get('https://cdn2.byhy.net/files/selenium/test4.html')
# --- prompt ---
driver.find_element(By.ID, 'b3').click() # 点击后弹出
# 获取到弹出的alert 对象
alert = driver.switch_to.alert
# 打印 弹出框 提示信息
print(alert.text)
# 输入信息,并且点击 OK 按钮 提交
alert.send_keys('web自动化 - selenium')
alert.accept()
5.9XPATH
绝对路径:从根结点,按照/分割找到目标元素
相对路径:// div 表所有标签名为
div的元素
选择 所有的 div 元素里面的 直接子节点 p , xpath,就应该这样写了 //div/p
如果使用CSS选择器,则为 div > p,
通配符 *
eg: //div/* 表div标签下的所有直接子节点
5.9.1根据属性选择
标签名[@属性名=‘属性值’]
// *[@id = 'west'] # 根据id属性选择
// p[@class="capital huge-city"] p标签中的类
xpath也有组选择, 是用 竖线 隔开多个表达式
要选所有的 class 为 single_choice 和 class 为 multi_choice 的元素,可以使用
//*[@class='single_choice'] | //*[@class='multi_choice']
等同于CSS选择器
.single_choice , .multi_choice
要选择 class 为 single_choice 的元素的 所有 前面的兄弟节点,这样写
//*[@class='single_choice']/preceding-sibling::*
要选择后续节点中的div节点, 就应该这样写 //*[@class='single_choice']/following-sibling::div
要在某个元素内部使用xpath选择元素, 需要 在xpath表达式最前面加个点
elements = china.find_elements(By.XPATH, ‘.//p’)
自动化测试框架
pytest
安装pytest与pytest-html
pip install pytest
pip install pytest-html
注意事项
导入pytest,自动执行__init__.py文件
执行pytest,自动执行__main__.py文件
pytest插件中有hock,fixture,类和函数
hock可以改变pytest
1.基本用法
1.1测试用例代码
- 文件必须以必须以
test_开头,或者以_test结尾,例如以下的:test_错误登录.py - 类名必须以
Test为前缀的类 - 用例对应的必须以
test为前缀的方法或函数
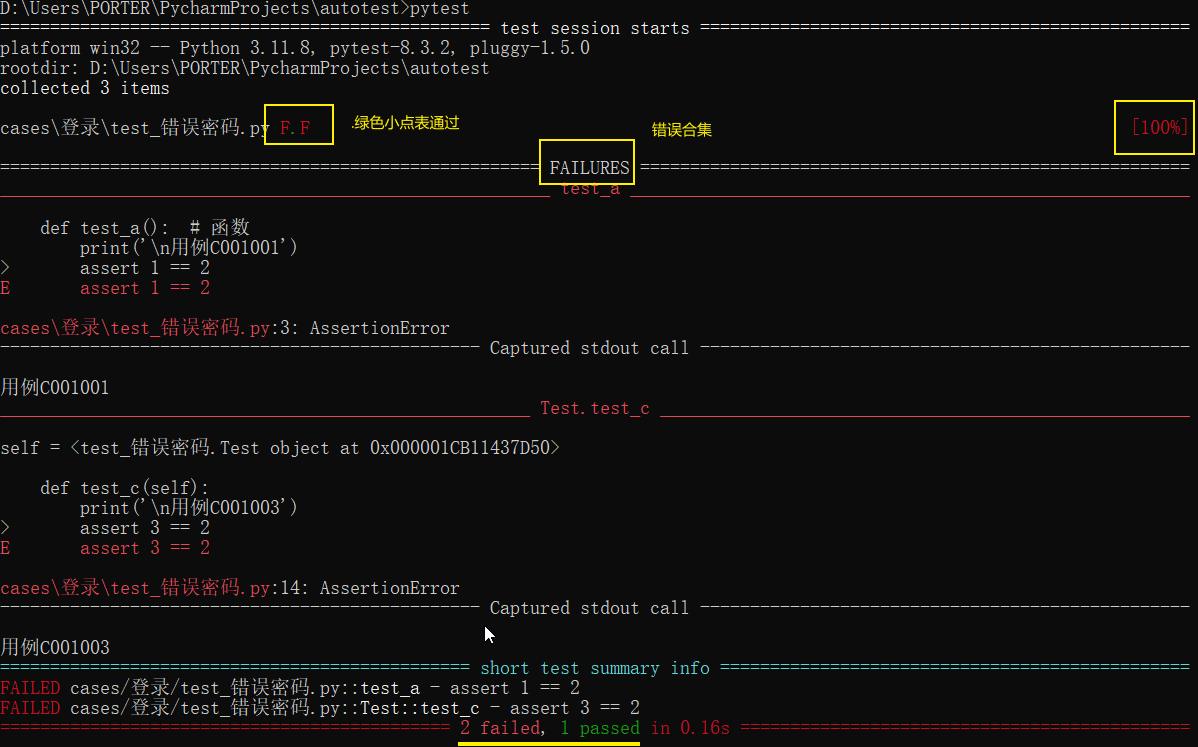
def test_C001003(self): # 函数
print('\n用例C001001')
assert 1 == 2
class Test_错误密码:
def test_C001001(self): # 类的内部就是方法
print('\n用例C001002')
assert 1 == 1
def test_C001003(self):
print('\n用例C001003')
assert 3 == 2
1.2运行测试
运行测试时方法:
- 在终端运行pytest cases (cases表目标测试文件目录)
- 在cmd中进入项目根目录后输入pytest cases
python pytest cases - sv # s表输出测试用例中的打印语句,而v则是更详细的包含方法名称
1.3测试报告
python -m pytest cases --html=report.html --self-contained-html #会生成一个html文件,里面记录了详细信息
2.初始化清除
- 模块级别:
模块级别的初始化、清除 分别 在整个模块的测试用例 执行前后执行,并且只会执行1次。 - 类级别:在
类执行前后执行,但是第二个类时直接连在清除类之后,而不是再次初始化类 - 方法级别:在方法执行前后都执行,但只限于该方法初始化方法有写在对应class类上
- 目录级别:在对应测试文件的目录下新建一个conftest.py文件
import pytest
@pytest.fixture(scope='package',autouse=True)
def st_emptyEnv():
print(f'\n#### 初始化-目录甲')
yield
print(f'\n#### 清除-目录甲')
def setup_module():
print('\n *** 初始化-模块 ***')
def teardown_module():
print('\n *** 清除-模块 ***')
class Test:
@classmethod
def setup_class(cls):
print('\n === 初始化-类 ===')
@classmethod
def teardown_class(cls):
print('\n === 清除 - 类 ===')
def setup_method(self):
print('\n --- 初始化-方法 ---')
def teardown_method(self):
print('\n --- 清除 -方法 ---')
def test_b(self): # 类的内部就是方法
print('\n用例C001002')
assert 1 == 1
def test_c(self):
print('\n用例C001003')
assert 3 == 2
class Test2:
def test_2(self):
print('\ndamage')
assert 1 == 1
def test_3(self): # 类的内部就是方法
print('\n用例3')
assert 1 == 1
3.挑选用例执行
平时写的pytest前面省略了python -m
python -m pytest cases\登录\test_错误登录.py #指定模块
pytest cases1 cases2\登录 #指定多个目录
pytest cases\登录\test_错误登录.py::Test_错误密码::test_01 # 指定模块中类时,在模块后面直接加::,指定类中方法也是::
pytest -k "not 错误 or not 01" -s #指定名字,名字间有并列关系
pytest cases -m webtest -s #根据标签mark指定,其直接在对应类,方法上加上@pytest.mark.XXX
例如
@pytest.mark.网页测试
class Test_错误密码2:
def test_C001021(self):
print('\n用例C001021')
assert 1 == 1
# 定义一个全局变量 pytestmark 为 整个模块文件 设定标签
import pytest
pytestmark = pytest.mark.网页测试
项目实战
金融项目
6.1梳理(p15)
基础知识

业务模块
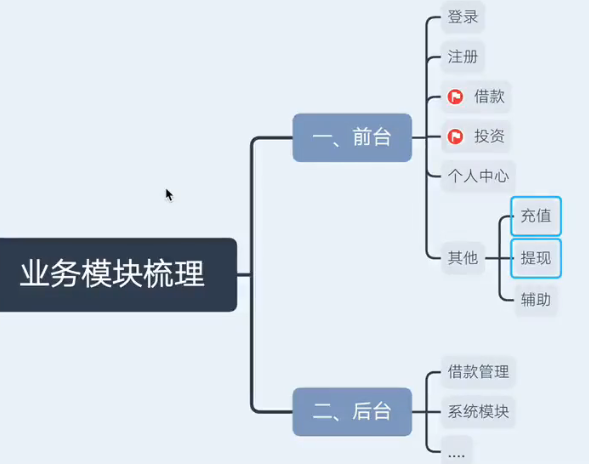
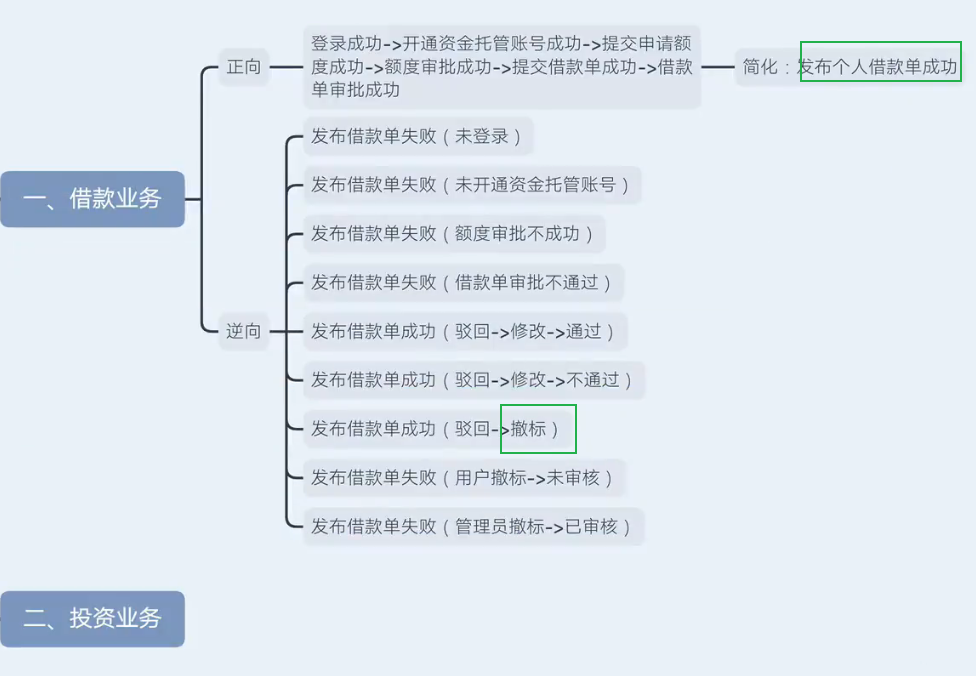
6.2提取测试点

借款业务
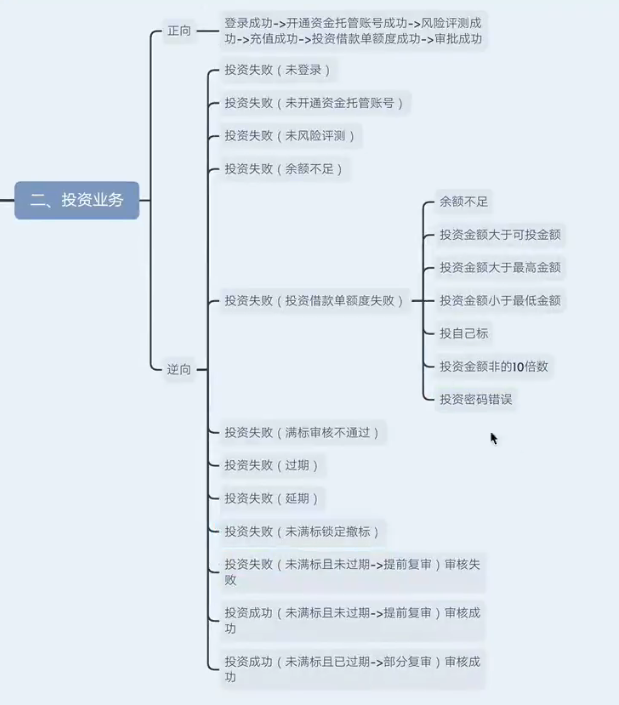
投资业务
6.3测试流程
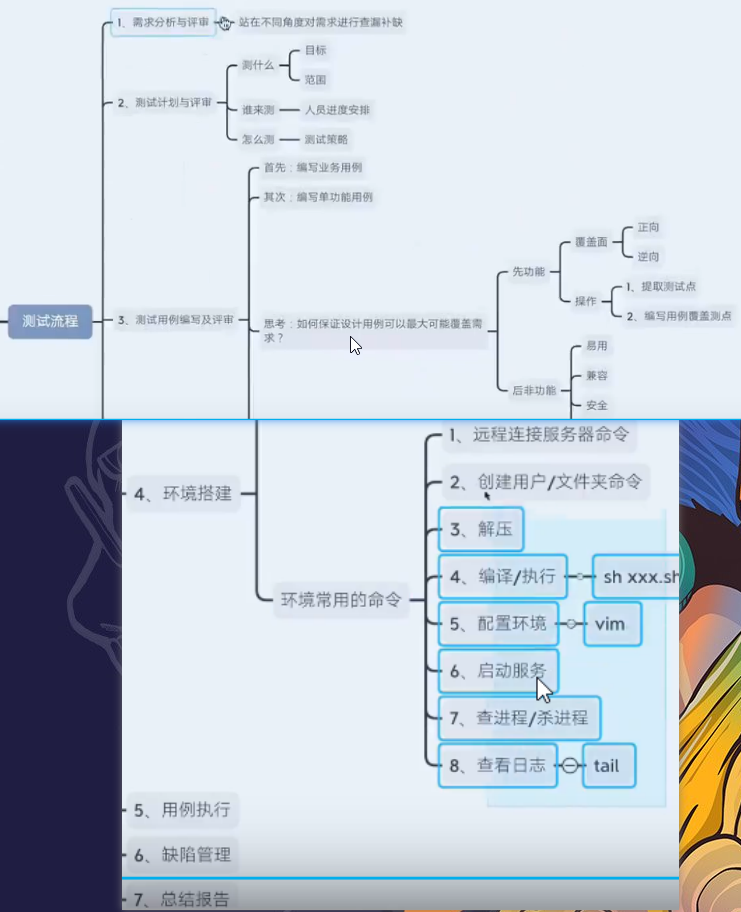
参考网站
selenium+pytest+api接口自动化+appium:
https://www.byhy.net/auto/appium/01/
python:
https://liaoxuefeng.com/books/python/advanced/index.html
ai:
https://chat18.aichatos8.xyz















 2611
2611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









