







 本文介绍了神经网络的正向传播与反向传播过程。正向传播将数据通过多层变换得到输出,反向传播则从输出层开始计算各层的误差并更新权重参数,以最小化代价函数。反向传播中的关键包括误差的计算、权重的梯度更新以及梯度检验,以确保模型的训练效果。
本文介绍了神经网络的正向传播与反向传播过程。正向传播将数据通过多层变换得到输出,反向传播则从输出层开始计算各层的误差并更新权重参数,以最小化代价函数。反向传播中的关键包括误差的计算、权重的梯度更新以及梯度检验,以确保模型的训练效果。
上一篇文章中讲到了神经网络,通俗地说,就是一堆源数据X(第一层),经过一个空间的线性变换后,再被激活函数处理这个变换,变身成为隐层(下一层),然后得到的新的数据作为这一层的输出,重复上一层的方法,又得到下一层,就像神经一个节点一个节点传播信息一样,数据一层一层地变换,到最后一层输出时,再进行分类得到结果。下面这张图更加直观,当然这个只是四层:
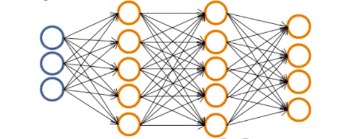
而像以上的过程,我们称之为正向传播。
那么,我们可能会思考,这么传播下去,如果中间存在误差,误差会不会一层一层地被放大,以至于最后一层的分类效果十分不理想呢?
换句话说,根据我们前面学习的线性回归和逻辑回归的知识,这个误差error可以由cost来表示,通过梯度下降法或者正规方程法可以得到满足要求的误差(近似认为正确)。我们可以想象,神经网络的初始参数  (类似之前线性回归中的
(类似之前线性回归中的  ,只不过 是 的集合),我们不可能一开始就刚好设置得到了一个优秀的 ,一开始的误差大概率是大的,所以,有木有类似梯度下降法的方法可以调整参数 呢?直至 使得整个训练模型的误差降低到一个微小范围内,我们就认为这个模型就是好的了。
,只不过 是 的集合),我们不可能一开始就刚好设置得到了一个优秀的 ,一开始的误差大概率是大的,所以,有木有类似梯度下降法的方法可以调整参数 呢?直至 使得整个训练模型的误差降低到一个微小范围内,我们就认为这个模型就是好的了。
所以,个人简单的理解,机器学习的训练过程,其实就是训练出一个优秀的参数 ,这样,新的数据集进来,通过这些 的变换,就可以得到结果了(与真实值类似的结果)。
好的,所以不卖关子了,就如同标题所说,神经网络如何训练出优秀的参数 呢?当然是Backpropagation Algorithm(反向传播算法)。
话不多说,Let's go!
----------------我是萌萌的分割线-------------------
之前的文章中我们看到了二元分类,简单地利用逻辑回归,分类成0和1,后来又讲到如果是多分类,譬如四类分类,我们可以将四种类型这样表现:
![y^{(i)} = \left[ \begin{array}{ccc} 1 \\ 0 \\ 0\\0 \end{array} \right], \left[ \begin{array}{ccc} 0 \\ 1 \\ 0\\0 \end{array} \right], \left[ \begin{array}{ccc} 0 \\ 0 \\ 1\\0 \end{array} \right], \left[ \begin{array}{ccc} 0 \\ 0 \\ 0\\1\end{array} \right]](https://i-blog.csdnimg.cn/blog_migrate/389ce592393c26e2b7d9f4f3f646f33f.png)
如果不理解的话,可以将它看成是1,2,3,4。以此类推,如果有更多分类,那就继续扩展,简单地说,分类的标签不再是0,1,2,3,4等数字了,而是用一个向量表示。所以,我们这个时候,再定义一个变量K,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









