









1. 两表合并查询(Combine Two Tables)
题目描述:
Table: Person
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+-------------+---------+
PersonId is the primary key column for this table.
Table: Address
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+-------------+---------+
AddressId is the primary key column for this table.Write a SQL query for a report that provides the following information for each person in the Person table, regardless if there is an address for each of those people:
FirstName, LastName, City, State这个还是挺简单的,直接上:
select Person.FirstName,Person.LastName,Address.City,Address.State from Person left join Address on Person.PersonId= Address.PersonId;描述:
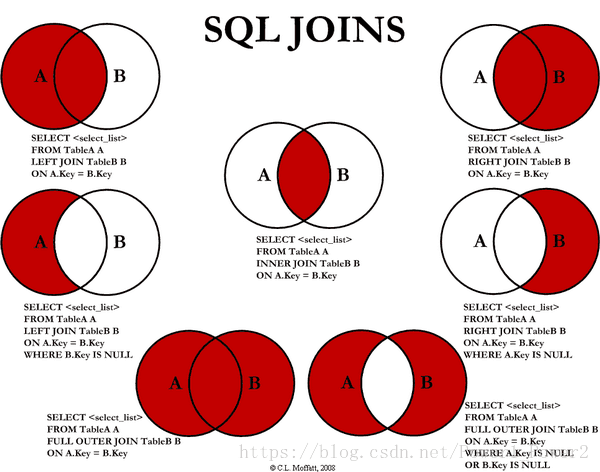
SQL中常见的JOIN
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行上图:
2. 第二高薪(Second Highest Salary)
Write a SQL query to get the second highest salary from the Employee table.
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
For example, given the above Employee table, the query should return 200 as the second highest salary. If there is no second highest salary, then the query should return null.
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+找出第二高的,也就是在除去最高的剩余里面找出最高的;
select max(Salary) as SecondHighestSalary from Employee where Salary not in (select max(Salary) from Employee);3. 挣钱比经理多(Employees Earning More Than Their Managers)
题目描述:
The Employee table holds all employees including their managers. Every employee has an Id, and there is also a column for the manager Id.
+----+-------+--------+-----------+
| Id | Name | Salary | ManagerId |
+----+-------+--------+-----------+
| 1 | Joe | 70000 | 3 |
| 2 | Henry | 80000 | 4 |
| 3 | Sam | 60000 | NULL |
| 4 | Max | 90000 | NULL |
+----+-------+--------+-----------+
Given the Employee table, write a SQL query that finds out employees who earn more than their managers. For the above table, Joe is the only employee who earns more than his manager.
+----------+
| Employee |
+----------+
| Joe |
+----------+对于本题,Joe的经理是编号为3的Sam,Henry的经理为编号为4的Max,按照题目要求,Joe的工资是高于他的经理Sam的(7K>6K),所以本例的目的是返回Joe:
类似于两表查询:
select name as Employee from Employee e1 where Salary > (select Salary from Employee e2 where e1.ManagerId=e2.Id)
或者:
select name as Employee from Employee e1
where exists (select * from Employee e2 where e2.Id=e1.ManagerId and e1.Salary>e2.Salary )
建议写exists语句时,子查询中直接用*,而不用对列进行任何函数操作,避免碰到官方bug,4. 重复值查询
题目描述:
Write a SQL query to find all duplicate emails in a table named Person.
+----+---------+
| Id | Email |
+----+---------+
| 1 | a@b.com |
| 2 | c@d.com |
| 3 | a@b.com |
+----+---------+
For example, your query should return the following for the above table:
+---------+
| Email |
+---------+
| a@b.com |
+---------+
Note: All emails are in lowercase.
这个比较简单:
Select Email from Person group by Email having count(Email)>1;这里注意三点:
- group by:常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。
- having:having字句可以让我们筛选成组后的各种数据,where字句在聚合前先筛选记录,也就是说作用在group by和having字句前。
- count():它返回检索行的数目, 不论其是否包含 NULL值。














 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









