







Title: Knowledge Distillation and Student-Teacher Learning for Visual Intelligence: A Review and New Outlooks
摘要
1)provide explanations of what knowledge distillation is and how/why it works
2)provide comprehensive survey of Knowledge Distillation and Student-Teacher frameworks in vision tasks
3)investigate some fundamental questions that have been driving this research area and thoroughly generalize the research progress and technical details
4)systematically analyze the research status of KD in vision applications
5)discuss the potentials and open challenges of existing methods and prospect the future directions
Introduction
知识蒸馏的应用场景:model compression 和 knowledge transfer
Section 2:What is KD and why concern it?
知识蒸馏的概念:在大的教师模型的监督指导下,帮助小的学生模型的训练过程。最开始的知识蒸馏的方法是最小化教师模型与学生模型之间的预测输出。
但是教师模型与学生模型的输出会造成目标类占据绝对优势,而其他预测类的概率接近于0,在这种情况下,模型预测输出无法提供足够的信息和知识。为了解决这一问题,Hinton提出了softmax temperature,用于把模型预测输出的logits转换为soft label
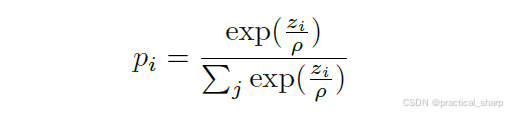
温度系数越大,概率分布越平滑,也就是更加soft,包含更多的类间信息,被称之为dark knowledge
对于学生模型的训练过程,其损失函数包含学生任务的损失,和教师到学生的蒸馏损失
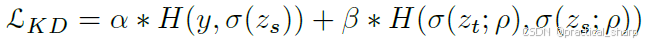
Section 3:A theoretical analysis of KD
no commonly agreed theory as to how knowledge is transferred
一些学者提出KD的核心就是最大化两个模型表征之间的互信息 Ahn et al., Hedge et al., and Tian et al. formulate KD as a maximization of mutual information between the representations of the teacher and the student networks.
S. Ahn, S. X. Hu, A. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
S. Hegde, R. Prasad, R. Hebbalaguppe, and V. Kumar, “Variational student: Learning compact and sparser networks in knowledge distillation framework,” ICASSP,2020.
Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” in International Conference on Learning Representations (ICLR), 2019.
基于Bayes理论,两个数学分布的mutual information可以被表示为
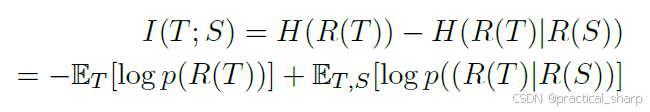
其中H()表示熵函数,直观地说,当R(S)已知时,互信息用于增加R(T)中所提供信息的确定性程度。

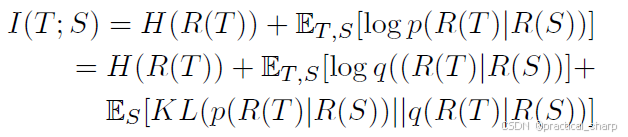
因此
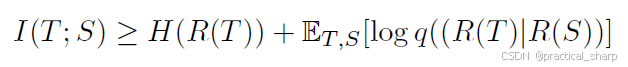
对于变分分布q,其可以用高斯分布(Gaussian Distribution),蒙特卡罗近似(Monte Carlo approximation)或噪声对比估计(noise contrastive estimation)来建模
作者确实认为,从理论上解释知识蒸馏(KD)的工作原理与表征学习相关,其中捕捉了教师和学生之间的相关性以及高阶输出依赖关系。关键挑战是提高信息的下限,这在 [10] 中也有所指出。
Section 4:KD based on the number of teachers
4.1 Distillation from one teacher
4.1.1 Knowledge from logits
Softened labels and regularization
早期的Hinton使用温度参数的方法来从logits中得到soft label,其本质是缓解固有的类别不平衡来软化标签分布。
相比之下,一些研究者指出软标签和硬标签之间的权衡很少能达到最优状态,而且由于在训练期间、损失权重alpha和温度参数T是固定的,在没有给定软化标签的情况下,它缺乏足够的灵活性来应对这种情况。
为此,Ding等人[13]提出了residual label和residual loss,使学生在训练阶段能够利用错误经验,防止过拟合并提高性能。
同样,Tian等人[10]将教师模型的知识表述为结构化知识,并训练学生在对比学习过程中获取更多的互信息。
Hegde等人 [9] 提议通过基于变分推理添加稀疏正则化器来训练一个变分学生模型.
学生训练的稀疏化可减少过拟合并提高分类的准确性。Wen等人 [15] 注意到来自教师的知识是有用的,但不确定的监督也会影响结果。因此,他们提议通过平滑正则化来修正教师的错误预测(知识),并使用动态温度来避免过度不确定的监督
Cho等人[16] 发现early-stopped的教师能够更好的指导学生,特别是当教师模型的capacity远远大于学生模型时。
Liu等人 [18] 专注于将参数的分布建模为先验知识,通过聚合来自教师网络的分布(对数几率)空间来进行建模。然后,通过稀疏记录惩罚对先验知识进行约束,以限制学生模型避免过度正则化。Mishra等人 [19] 通过使用知识蒸馏技术训练一个学生模型,将网络量化与模型压缩相结合,并表明通过蒸馏教师网络的对数几率,可以显著提高低精度网络的性能。Yang等人 [17] 提出了一种快照蒸馏方法,可在iteration内进行师生(相似网络架构)优化。他们的方法基于循环学习率策略,其中每个iteration的最后一个snapshot在下一个iteration中充当教师。因此,snapshot蒸馏的思路是在同一代的早期 epoch 中提取监督信号,以确保教师和学生之间的差异足够大,从而避免欠拟合。snapshot蒸馏损失可以被表示为
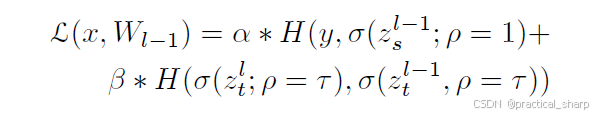
Learning from noisy labels 侧重于数据问题,为数据集增加噪声或者使用带噪声的标签。
Imposing strictness in distillation
相比之下,Yang et al. [25], Yu et al. [26], Arora et al. [27], RKD [28] and Peng et al. [29] 转向了一个新的视角,更侧重于通过优化(例如,distribution embedding, mutual relations等)对蒸馏过程施加严格性。特别是,[25] 开始对教师模型施加严格性,而 [26] 则提出了两个教学指标来对学生模型施加严格性。杨等人观察到,除了学习主要类别(即真实情况)之外,学习次要类别([1] 中提到的隐含知识中的高置信度分数类别)可能有助于降低学生模型过拟合的风险。因此,他们引入了一个在iteration中优化神经网络的框架,该框架要求训练一个仅由数据集监督的初始模型M0,经过m轮迭代之后,学生模型在第Mm代由教师模型Mm-1监督进行训练。由于次要信息对于训练一个稳健的教师模型至关重要,所以为每张图像选择一个固定整数K来代表语义相似类别,并计算主要类别与其他得分最高的K-1个类别的置信度分数之间的差距。
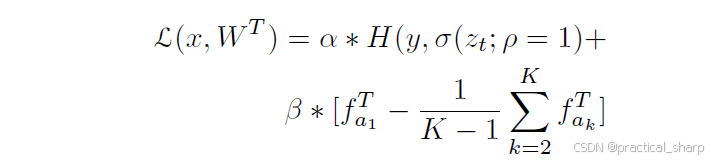
其中fak表示输出logits概率中第k大的元素。
文献[26]将模型从image中预测的information投影到embedding空间中。这种embedding被用于教师与学生之间的距离计算。从这个角度来看,基于嵌入网络计算出的知识是实际知识,因为它代表了数据分布。他们设计了两种不同的教师模型:绝对教师模型和相对教师模型。对于绝对教师模型,其目标是最小化教师模型和学生模型嵌入之间的距离;而对于相对教师模型,其目标是促使学生学习任何嵌入,只要它能使数据点之间产生相似的距离即可。他们还探索了hint [1] 和attention [36] 机制来强化嵌入网络的蒸馏过程。我们将在 4.1.2 节对这两种技术给出更明确的解释。
文献[27]提出了一个embedding模块,该模块用于捕捉问答场景中query信息和document信息之间的交互作用。输出表示(logits)的嵌入包含一个简单的注意力模型,该模型带有一个查询编码器、一个提问者历史编码器、一个回答者历史编码器以及一个文档编码器。受 [1] 的启发,这个注意力模型将交叉熵损失和 KL 散度损失的总和最小化。另一方面,[31] 和关系知识蒸馏(RKD)[28] 考虑了另一种严格性,即教师和学生在所学表示中两个示例的相互关系或关系知识。这种方法与 [26] 中的相对教师模型非常相似,因为两者都旨在测量教师和学生嵌入之间的距离。然而,RKD [28] 还考虑了角度方面的关系度量,这类似于在 [25] 中保留次要信
息。
Ensemble of distribution
尽管已经提出了各种各样的从logits中提取知识的方法,但一些研究工作[16, 32, 33, 34] 表明,由于知识的不确定性,知识蒸馏(KD)并非总是切实可行的。当学生模型和教师模型之间的gap较大时,学生模型的性能会下降。[33] 指出,估计模型的不确定性至关重要,因为这能确保转移更可靠的知识。他们强调采用ensemble方法来估计数据不确定性和分布不确定性。为了估计分布不确定性,一种ensemble分布蒸馏方法会调整 softmax 的温度,这样不仅能捕捉集成软标签的均值,还能捕捉分布的多样性。同时,[35] 提出了一种类似的方法,即匹配基于蒸馏的multiexit架构的分布,在该架构中,一系列特征层在不同深度增加了早期出口。通过这样做,公式 2 中定义的损失就变成 (类似于深监督,多个层级的监督信号)
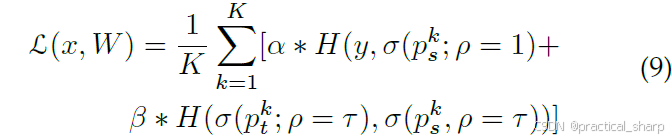
K表示监督出口的数量,pk表示第k个输出的预测logits输出。
相反,[2, 27, 30, 32, 34, 37, 38, 39, 40, 41, 42, 43, 44, 45, 47, 48, 49, 50] 提议增加更多的教师或其他辅助手段,比如teacher assistant和small students(小模型),以提高ensemble distribution的稳健性。我们将在接下来的 4.2 节中对这些方法进行明确分析。
Summary
表格1总结了使用logits或者soft label的KD方法,本文将这些方法分为四类。总结来说,利用logits进行蒸馏需要传递隐含知识以避免过拟合或欠拟合。同时,教师模型和学生模型之间的模型容量差距对于有效蒸馏也至关重要。此外,从logits中学习存在明显的弊端。首先,蒸馏的有效性受限于 softmax 损失且依赖于类别数量。其次,无法将这些方法应用于没有标签的知识蒸馏问题(例如,低级视觉领域)。
Open challenge
文献[1] 中的原始想法具有明显的通用性:任何学生模型都可以向任何教师模型学习;然而,有研究表明,即使应用了正则化或严格性技术,在一些数据集 [16, 36](例如 ImageNet [51])上也很难实现这种通用性的预期。当学生模型的能力过低时,学生模型很难成功地吸收教师模型的对数几率信息。因此,人们期望提高通用性并提供一种能让学生模型更易吸收的对数几率信息的更好表示形式。
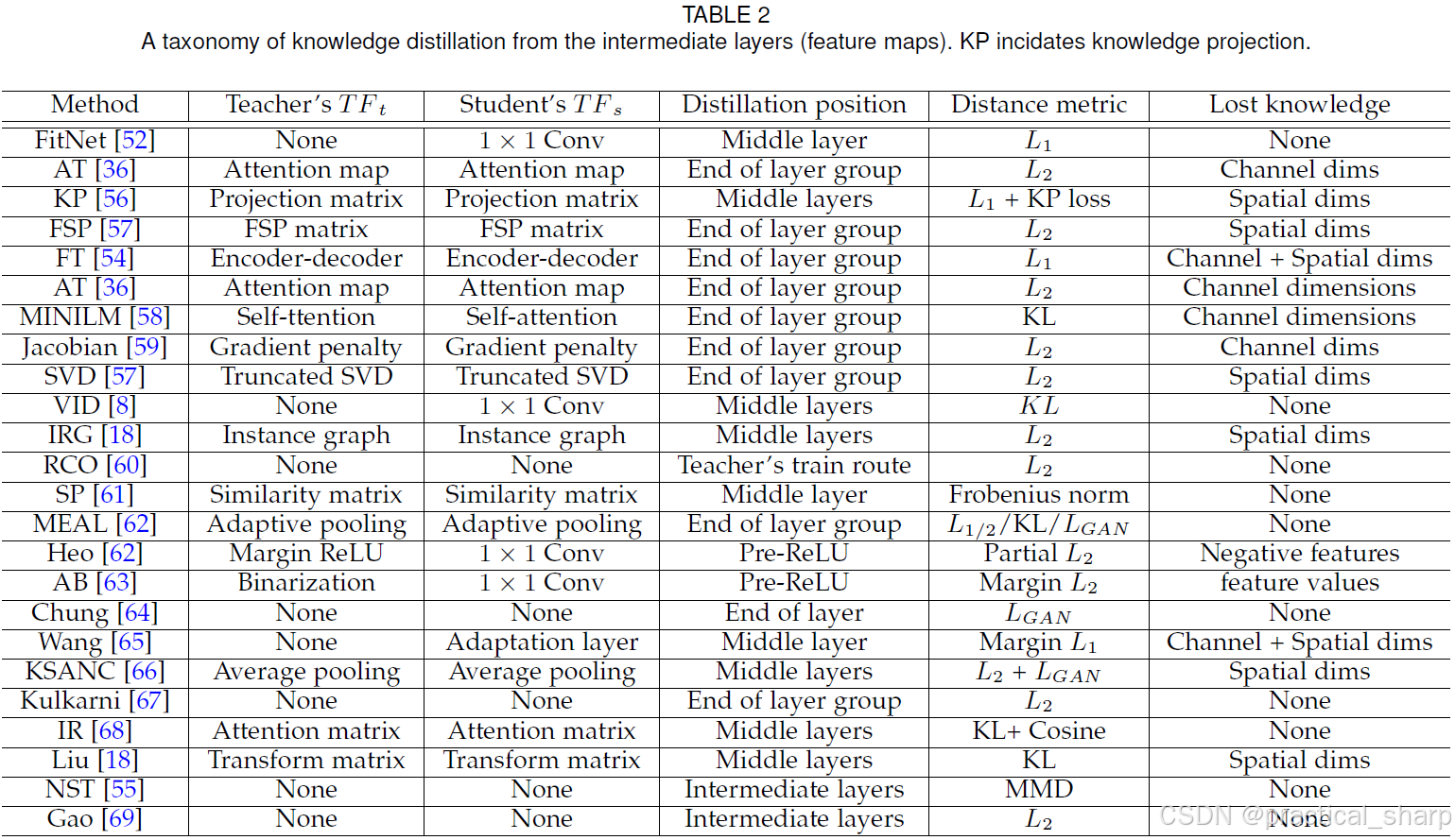
4.1.2 Knowledge from the intermediate layers
Overall insights: Feature-based distillation enables learning richer information from the teacher and provides more flexibility for performance improvement.
除了从softened labels中蒸馏知识之外,Romero[52]首次提出了hint的概率,hint指的是教师模型hidden层的输出,也就是教师的特征层,能帮助学生的引导学习。学生学习的目标是学习一种feature representation,该特征表示是对teacher’s intermediate representations的最优预测。从本质上讲,hints的作用是一种正则化形式;因此,必须谨慎选择一对教师的hint层和学生的引导层(学生的一个隐藏层),以避免学生被过度正则化。受 [52] 的启发,人们已经做了很多努力来研究通过各种层变换(例如,transformer [53, 54])和距离(例如,最大均值差异 MMD[55])度量来选择、传输和匹配提示层(或多个提示层)与引导层(或多个引导层)的方法。一般来说,提示学习目标可以写成:
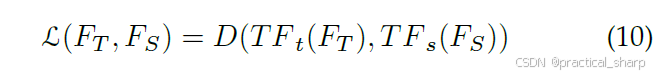
其中FT和FS表示teacher的hint层和学生的guided层,D表示距离函数,你如L2距离,来衡量the similarity of the hint and the guided layers.
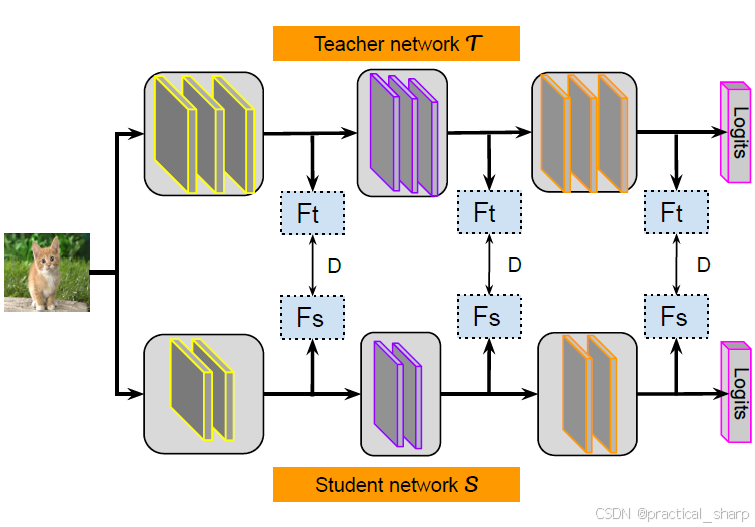
上图描述了基于特征的蒸馏的一般范式。可以看出,各种中间特征表示可以从不同位置提取出来,并通过某种类型的回归器或变换器进行变换。经过变换后的表示的相似性最终通过任意距离度量(例如,L1距离或L2距离)进行优化。在本文中,我们仔细审视了基于特征的知识蒸馏(KD)方法的各种设计考量因素,并总结了经常被考虑的四个关键因素:transformation of the hint、transform of the guided layer、position
of the selected distillation feature, and distance metric [53]。
在接下来的部分中,我们将针对这四个方面对所有现有的基于特征的知识蒸馏方法进行分析和分类。
Transformation of hints
如[8]中指出的,教师的知识必须很容易被学生学习。为此,教师的hidden特征经常被transformation函数转换。
Note that the transformation of teacher’s knowledge is a very crucial step for feature-based KD since there is a risk of losing information in the process of transformation.
The transformation methods of teacher’s knowledge in AT [36], MINILM [58], FSP [57], ASL[70], Jacobian [59], KP [56], SVD [71], SP [61], MEAL [62], KSANC [66], and NST [55] cause the knowledge to be missing due to the reduction of feature dimension.
具体而言,AT[54]和MINILM[58]专注于attention mechanism(例如self-attention),通过利用一个attention transformer将特征F属于CxHxW进行transform为C个HxW大小的特征图
FSP[57]和ASL[70]基于Gramian矩阵计算信息流,F属于CxHxW is transformed to G属于CxN,其中N表示矩阵的数量。
Jacobian[59]和SVD[71]通过first-order Taylor series和truncated SVD将F属于CxHxW的特征映射为G属于CxN,导致了信息的丢失。
KP[56]将F属于CxHxW投影为M个特征图属于MxHxW,造成了loss of knowledge.
同样,SP [61] 提出了一种保持相似性的知识蒸馏方法,该方法基于这样一种观察:语义相似的输入往往会引发相似的激活模式。
To achieve this goal, the teacher’s feature F属于BxCxHxW is transformed to G属于BxB, where B is the batch size. G编码了教师层特征的激活相似性,但是在transformation中导致了information loss.
MEAL [62] 和 KSANC [66]都使用池化pooling来对齐teacher和student的intermediate特征图的大小,同样也导致了信息的丢失。
NST[55]和PKT[73]对教师网络和学生网络之间神经元选择性模式的分布以及数据样本的亲和性进行匹配。其损失函数分别基于最小化这些分布之间的最大平均差异(MMD)和Kullback - Leibler,KL散度,因此在选择神经元时会导致信息丢失。
另一方面,FT[54]提出提取良好的因子,通过这些因子来生成可迁移的特征。 The transformer TFt is called the paraphraser and the transformer TFs is called the translator.
要提取教师因子,需要一个经过充分训练的paraphraser。同时,为了让学生能够根据自身能力吸收和消化知识,在paraphraser中使用用户定义的释义比例来控制迁移因子。
Heo等人[63]以二值化的形式使用原始教师的特征,即通过一个分离超平面(激活边界(AB))来确定神经元是被激活还是未被激活。由于 AB 只考虑神经元的激活情况,而不考虑神经元反应的幅度,所以在特征二值化过程中会存在信息丢失。
IRG [18] 中也会发生类似的信息丢失情况,在该方法中,教师的特征空间被转换为带有顶点和边的图表示形式,并且计算出关系矩阵。
IR[68] 将教师模型的内部表示蒸馏到学生模型中。然而,由于教师模型中的多层被压缩到学生模型的一层中,在匹配特征时会存在信息丢失。
Heo等人 [53] 设计带有边缘margin修正线性单元(ReLU)函数的 TFt,以排除负面(不利)信息并允许正面(有益)信息通过。margin值 m 是在学生的变换器 TFs 中经过 1×1 卷积后,基于批量归一化 [74] 来确定的。
相反, FitNet [52], RCO [60], Chung et al. [64], Wang et al. [65], Gao et al. [69] and Kulkarni et al. [67]并未对教师的知识添加额外的转换;这使得教师一方不会出现信息丢失的情况。
然而,并非教师的所有知识对学生都是有益的。正如 [53] 所指出的,特征既包含不利信息也包含有利信息。为了实现有效的蒸馏,重要的是要阻止不利信息的使用,并避免遗漏有利信息。
Transformation of the guided features
学生层特征的transform也是有效的知识蒸馏的重要一个步骤。
有趣的是, the SOTA works such as AT [36], MINILM [58], FSP [57], Jacobian [59], FT [54], SVD [71], SP [61], KP [56], IRG [18], RCO [60],MEAL [62], KSANC [66], NST [55], Kulkarni et al. [67], Gao et al. [69] and Aguilar et al. [68] use the same TFs as the TFt, which means the same amount of information might be lost in both transformations of the teacher and the student.
不同于teacher的transformation,FitNet [52], AB [63], Heo et al. [53], and VID [8] change the dimension
of teacher’s feature representations and design TFs with a ‘bottleneck’ layer (1×1 convolution) to make the student’s features match the dimension of the teacher’s features.
值得注意的是,Heo et al. [53] add a batch normalization layer after a 1×1 convolution to calculate the margin of the proposed margin ReLU transformer of the teacher.
There are some advantages of using 1×1 convolution in KD.
First, it offers a channel-wise pooling without a reduction of the spatial dimensionality. 它能在不降低空间维度的情况下实现通道方向的池化
Second, it can be used to create a one-toone linear projection of the stack of feature maps. 它可用于对特征图堆叠进行一对一的线性投影
Lastly, the projection created by 1×1 convolution can also be used to directly increase the number of feature maps in the distillation model. 由 1×1 卷积创建的投影还可用于直接增加蒸馏模型中特征图的数量
In such a case, the feature representation of student does not decrease but rather increase to match
the teacher’s representation; this does not cause information loss in the transformation of the student. 在这种情况下,学生模型的特征表示不会减少,反而会增加以匹配教师模型的表示;这在学生模型的转换过程中不会导致信息丢失。
特别地,一些研究工作聚焦于学生特征表示转换的不同方面。
Wang等人 [65] 让学生模仿教师表示中靠近物体实例的细粒度局部特征区域。这是通过设计一个特定的适配函数 TFs 来完成模仿任务实现的。
IR [68] 旨在让学生通过匹配内部表示来获取教师某一隐藏层中的抽象内容。也就是说,要教会学生如何将来自教师多层的知识压缩到单层中。在这样的设定下,学生引导层的转换是通过一个自注意力变换器完成的。
另一方面,Chung等人 [64] 提议不对学生和教师进行任何转换,而是添加一个鉴别器来区分不同网络(教师或学生)的特征图分布。
Distillation positions of features
除了对教师和学生的特征进行转换之外,在很多情况下,所选特征的蒸馏位置也非常关键。早些时候, FitNet [52], AB [63], and Wang et al. [65]将任意中间层的末尾作为蒸馏的节点。然而,这种方法被证明蒸馏性能较差。
基于 layer group的定义 [75],即一组层具有相同的空间大小,AT [36], FSP[57], Jacobian [59], MEAL [62], KSANC [66], Gao et al. [69] and Kulkarni et al. [67] 将蒸馏位置定义在每个layer group的末尾,这与FT [54] 和NST [55] 不同,后两者的蒸馏位置仅位于最后一个layer group的末尾。
与FitNet相比,FT取得了更好的结果,因为它更侧重于信息性知识。
IRG [18] 考虑了上述所有关键位置;也就是说,蒸馏位置不仅位于较早层组的末尾,而且还位于最后一个层组的末尾。
有趣的是,VID [8]、RCO [60]、Chung等人 [67]、SP [61]、IR [68] 以及Liu等人 [18] 通过采用variational information maximization变分信息最大化 [76]、curriculum learning课程学习 [77]、adversarial learning对抗学习 [78]、similarity-presentation in representation learning表示学习中的相似性呈现 [79]、mutitask
learning多任务学习 [80] 和reinforcement learning强化学习 [81] 对蒸馏位置的选择进行了推广。我们将在后面的章节中对这些方法进行更详细的讨论。
Distance metric for measuring distillation
从教师模型到学生模型的知识蒸馏(KD)质量通常通过各种距离度量来衡量。最常用的距离函数基于 L1 或 L2 距离。
FitNet [52], AT [36], NST[55], FSP [57], SVD [71], RCO [60], FT [54], KSANC [66], Gao et al. [69] and Kulkarni et al. [67] 主要使用L2距离, 然而 MEAL [62] and Wang et al. [65] 主要使用L1距离
另一方面,Liu et al. [18] and IR [68] 使用KL散度来衡量特征的距离。
此外,IR [68] 和RKD [28] 采用 a cosine-similarity loss 余弦相似度损失来对教师和学生的特征分布上的上下文表示进行正则化。
一些研究工作还借助对抗损失来衡量知识蒸馏的质量。MEAL[62] 表明,通过判别器学习蒸馏知识的学生模型比原始模型能得到更好的优化,并且学生模型可以从任意结构的教师模型中学习蒸馏知识。
在专注于基于特征的蒸馏的研究工作中,KSANC[60] 在教师和学生网络的最后一层添加了对抗损失,而MEAL[62]在每个提取的特征表示位置添加了多阶段判别器。值得一提的是,使用对抗损失在提高知识蒸馏性能方面已显示出相当大的潜力。我们将在接下来的 8.1 节中明确讨论现有的基于对抗学习的知识蒸馏技术。
Potentials and open challenges
表格2总结了基于feature-based的KD方法。研究表明,大多数工作都会对教师和学生的特征进行变换。L1 或 L2 损失是衡量知识蒸馏(KD)质量最常用的损失函数。人们可能会自然而然地提出一个问题:直接匹配教师和学生的特征有什么问题呢?如果我们将每个空间位置的激活情况视为一个特征,那么每个滤波器的扁平化激活图就是所选神经元空间(维度为高 × 宽,即 HW)的一个样本,它反映了深度神经网络(DNN)是如何学习一幅图像的 [55]。因此,正如 [52] 所指出的,在匹配分布时,直接匹配样本是不太可取的,因为在该空间中可能会丢失样本密度。尽管 [69] 提出通过直接匹配特征图来蒸馏知识,但引入了一个助教来学习学生和教师特征图之间的残差误差。这种方法能更好地缩小教师和学生之间的性能差距,从而提高泛化能力。
Potentials: 基于特征的方法展现出了更强的泛化能力以及相当有前景的结果。在接下来的研究中,人们期望能有更灵活的方式来确定具有代表性的特征知识。表示学习中所采用的方法(例如参数估计、图模型)对于这些问题而言可能是合理的解决方案。此外,神经架构搜索(NAS)技术或许能更好地处理特征的选择问题。而且,基于特征的知识蒸馏(KD)方法有可能应用于跨领域迁移和低级视觉问题。
Open challenges:尽管我们已经讨论了大多数现有的基于特征的方法,但仍然很难说哪一种方法是最好的。首先,很难衡量信息丢失的不同方面。此外,大多数研究工作都是随机选择中间特征作为知识,却没有说明为什么这些特征能在所有层中成为具有代表性的知识。第三,特征的蒸馏位置是根据网络或任务手动选择的。最后,多个特征所代表的知识未必就比单层特征所代表的知识更好。因此,可以探索从各层中选择知识以及表示知识的更好方法。
4.2 Distillation from multiple teachers
Overall insight: The student can learn better knowledge from multiple teachers, which are more informative and instructive than a single teacher 相比单个教师,多个教师更加有信息量和指导性
在常见的单一教师(S-T)知识蒸馏(KD)范式下,已经取得了令人瞩目的进展,即知识从一个高容量的教师网络转移到一个学生网络。然而在这种设定下,知识容量相当有限 [48],并且在某些特殊情况(如跨模型知识蒸馏 [82])下,知识多样性也很匮乏。为此,一些研究工作探索了从多个教师或教师集合中学习一个可迁移的学生模型。这背后的直觉可以用人的学习认知过程来类比解释。在实际情况中,学生并非仅仅从单个教师那里学习,而是在同一任务上接受多个教师的有益指导,或者在不同任务上接受不同教师的指导时,能更好地学习某个知识概念。通过这种方式,学生可以融合并吸收来自多个教师网络的各种知识表示示例,从而构建一个全面的知识体系 [37, 39, 83]。结果,许多新的知识蒸馏方法 [2, 18, 30, 32, 33, 34, 37, 38, 39, 40, 41, 42, 43, 45, 46, 48, 49, 69, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103] 被提了出来。尽管这些工作在不同的蒸馏场景和假设下有所不同,但它们都有一些共同的典型特征,
可以归纳为五种类型:
- ensemble of logits 对数几率的集成、
- ensemble of feature-level information 特征层级信息的集成、
- unifying data sources 统一数据源、
- obtaining sub-teacher networks from a single teacher network从单个教师网络获取子教师网络、
- customizing student network from heterogeneous teachers and learning a student network with diverse peers, via the ensemble of logits根据不同教师定制学生网络以及通过对数几率的集成让学生网络与不同的同类模型一起学习。
现在我们将详细分析每一个类别,并就它们为何以及如何对相关问题有价值提供见解。
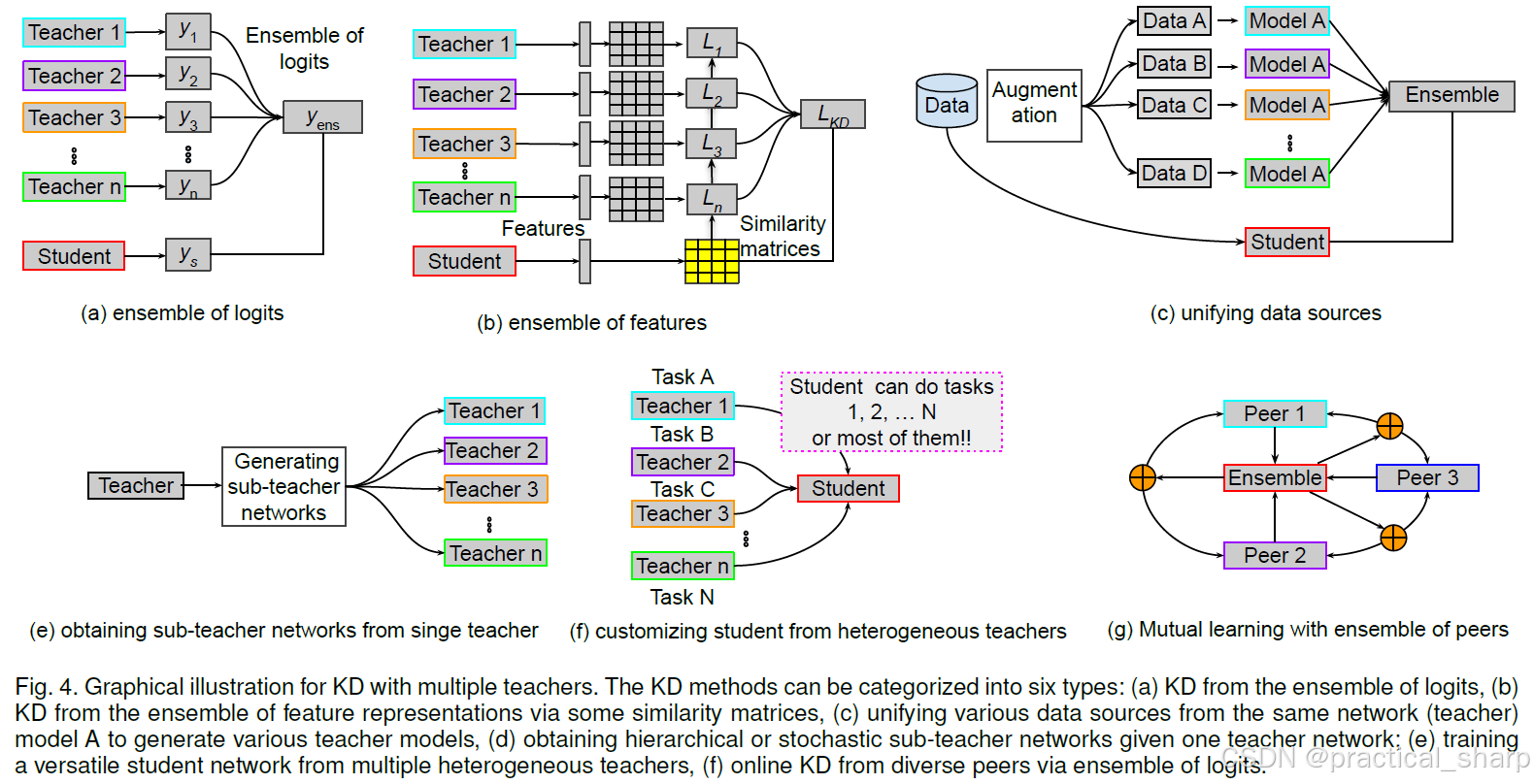
4.2.1 Distillation from the ensemble of logits
如图 4 (a) 所示,logits的模型集成是从多个教师进行知识蒸馏(KD)的常用方法之一。在这种设定下,鼓励学生通过交叉熵损失来学习组合教师的对数几率的软化输出(隐含知识),就像在 [2, 30, 32, 37, 38, 40, 43, 46, 87, 88, 90, 92, 93, 95, 96, 101, 102] 中所做的那样。形式化可以定义为
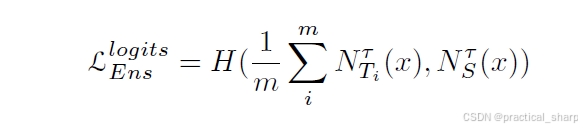
m代表教师模型的数量,H表示交叉熵损失,N表示输出的logits,平均后的soft label可作为输出层中多个教师网络的融合结果。最小化公式 11 可实现该层知识蒸馏(KD)的目标。需要注意的是,平均后的soft label出比任何单个教师网络的soft label更具客观性,因为它可以减轻某些输入数据中存在的软化输出的意外偏差。
与上述研究工作不同,[40, 82, 84, 91, 103] 指出,对单个预测取平均值可能会忽略集成中成员教师的多样性和重要性差异。因此,他们提议通过模仿带有门控组件的教师预测总和来学习学生模型。本质就是对每个教师模型的预测进行加权。
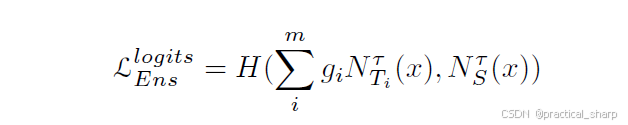
其中,gi表示第i个教师的门控权重参数。在[84]中,gi的计算是通过计算normalized similarity sim(DSi ;DT ) of the source domain DS and target domain DT.
Summary 从对数几率集成中蒸馏知识主要依赖于对各个教师的对数几率取平均值或求和。取平均值能减轻意外偏差,但可能会忽略集成中各个教师的多样性。每个教师的对数几率求和可以通过门控参数来平衡,但确定更佳取值的方法是在后续工作中值得研究的一个问题。
4.2.2 Distillation from the ensemble of features
相比 logits ensemble的方法,ensemble of feature representation更加flexible和advantageous,因为它能为学生提供更丰富多样的交叉信息。然而,从特征的集成中进行蒸馏 [18, 45, 45, 82, 92, 94, 102] 更具挑战性,因为每个教师在特定层的特征表示都彼此不同。因此,对特征进行变换,并形成教师的特征图层级表示的集成便成了关键问题,如图 4 (b) 所示。
为了解决这一问题,Park等人[48] 提出把学生的feature map输入到一些nonlinear layers中,被称之为tranformers。然后用转换后的特征用于模仿教师模型的特征图。
通过这种方式,如 4.1.2 节所述的一般模型集成和基于特征的知识蒸馏(KD)方法的优势都能够被结合起来。损失函数如下所示:
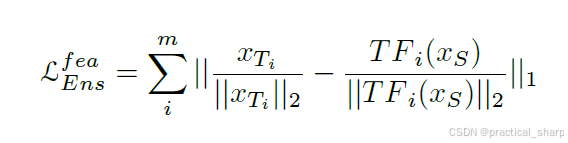
其中TF is the transformer (e.g.,3x3 convolution layer) used for adapting the student’s feature with that of the teacher.
相比之下,Wu等人 [45] 和Liu等人 [18] 提议让学生模型去模仿教师模型的可学习变换矩阵。这种方法是单一教师模型 [61] 的升级版。对于 [45] 中的第i个教师和学生网络,特征图之间的相似性是基于欧几里得度量来计算的,如下所示:
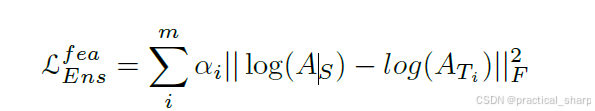
其中,alpha是控制第i个教师的权重参数,所有的alpha的和为1。As和At表示学生和教师的自相似矩阵,可以用As=XsTXs 和 At=XtTXt计算。
Open challenges:根据我们的综述,很明显只有少数研究提出 distilling knowledge from the ensemble of feature representations。尽管 [48, 90] 提出让学生通过非线性变换或带有加权机制的相似性矩阵直接模仿教师们的特征图集成,但仍然存在一些挑战。首先,我们如何知道在这个集成中哪位教师的特征表示更可靠或更具影响力呢?其次,我们如何以自适应的方式为每个学生确定加权参数alpha_i呢?第三,除了将所有特征信息汇总在一起之外,是否存在一种从集成中选择一位教师的最佳特征图作为代表性知识的机制呢?
4.2.3 Distillation by unifying data sources
尽管上述使用多个教师的知识蒸馏(KD)方法在某些方面表现不错,但它们都假定所有教师和学生模型的目标类别是相同的。此外,用于训练的数据集往往很稀缺,而且高容量的教师模型也有限。为了解决这些问题,一些近期的研究工作 [39, 42, 45, 86, 103, 104] 提出通过统一来自多个教师的数据源进行数据蒸馏,如图 4 © 所示。这些方法的目标是通过各种数据处理方法(例如数据增强)为未标记数据生成标签,以便训练学生模型。
Vongkulbhisal等人 [86] 提议统一一组异构分类器(教师),这些分类器可能经过训练以对不同的目标类别集进行分类,并且可以共享相同的网络架构。为了推广蒸馏过程,提出了一种将异构分类器的输出与统一(集成)分类器的输出相连接的概率关系。同样,Wu等人 [45] 和Gong等人 [104] 也探索了利用未标记数据将在现有数据中训练的教师模型的知识转移到学生模型,以形成决策函数。此外,一些研究工作利用数据增强方法的潜力,从一个经过训练的教师模型构建多个教师模型。Radosavovic等人 [42] 提出了一种通过对未标记数据进行多次变换来构建具有相同网络结构的多样教师模型的蒸馏方法。该技术包括四个步骤。首先,在人工标记的数据上训练一个单一的教师模型。其次,将经过训练的教师模型应用于未标记数据的多次变换。第三,将对未标记数据的预测转换为大量预测的集成。第四,在人工标记的数据和自动标记的数据的并集上训练学生模型。Sau等人 [39] 提出了一种通过向训练数据注入噪声并扰动教师的对数几率输出的方法来模拟多个教师的效果。通过这种方式,扰动后的输出不仅模拟了多个教师的设置,而且在 softmax 层产生噪声,从而对蒸馏损失进行正则化。
Summary: Unifying data sources using data augmentation techniques and unlabeled data from a single teacher model to build up multiple sub-teacher models is also valid for training a student model. However, it requires a high-capacity teacher with more generalized target classes, which could confine the application of these techniques. In addition, the effectiveness of these techniques for some lowlevel vision problems should be studied further based on feature representations.
4.2.4 From a single teacher to multiple sub-teachers
已有研究表明,将多个教师网络用作集成形式或分开使用都能进一步提升学生模型的性能。然而,使用多个教师网络会占用大量资源,并且会延缓训练进程。基于此,一些方法 [37, 41, 49, 84, 88, 90, 97] 被提出来从单个教师网络生成多个子教师网络,如图 4 (d) 所示。Lee等人 [49] 提出在教师网络中设置随机块和跳跃连接,这样就能在单个教师网络的相同资源下获得多个教师的效果。这些子教师网络具有可靠的性能,因为对于每一批数据都存在一条有效的路径。通过这种方式,在整个训练阶段学生都可以接受多个教师的训练。同样地,Ruiz等人 [89] 引入了分层神经集成,通过采用二叉树结构在不同模型之间共享一部分中间层。该方案允许动态控制推理成本,并能决定需要评估多少个分支。Tran等人 [88]、Song等人 [41] 和He等人 [97] 引入了多头架构来构建多个教师网络,同时通过一个共享的主体网络分摊计算量。每个头都被分配给一个集成成员,并试图模仿该集成成员的个体预测。
Open challenges: Although network ensembles using stochastic (随机的) or deterministic(确定性的) methods can achieve the effect of multiple teachers and online KD, many uncertainties remain. Firstly, it is unclear how many teachers are sufficient for online distillation. Secondly, which structure is optimal among the ensemble of sub-teachers is unclear? Thirdly, balancing the training efficiency and accuracy of the student network is an open issue. These challenges are worth exploring in further studies.
4.2.5 Customizing student form heterogeneous teachers
在许多情况下,经过良好训练的深度网络(教师网络)专注于不同的任务,并针对不同的数据集进行了优化。**然而,大多数研究侧重于通过从同一任务或同一数据集上的教师网络中蒸馏知识来训练学生网络。**为了解决这些问题,近期的一些研究工作 [18, 46, 83, 98, 99, 100, 102, 105, 106, 107] 已经开始进行知识融合,旨在通过从所有教师的专业知识中蒸馏知识来学习一个通用的学生模型,如图 4 (e) 所示。
Shen等人 [83]、Ye等人 [99]、Luo等人 [100] 和Ye等人 [105] 提出在不获取人工标注注释的情况下,通过定制任务来训练学生网络。这些方法依赖于诸如分支扩展(branch-out)[108] 或选择性学习(selective learning)[109] 等方案。这些方法的优点在于它们能够重用在各种不同任务的数据集上预训练的深度网络,以便根据用户需求构建一个量身定制的学生模型。学生网络继承了异构教师网络的大部分能力,因此能够同时执行多项任务。
Shen等人 [98] 和Gao等人 [106] 采用了类似的方法,但侧重于同一任务的分类,有两位教师专门从事不同的分类问题。在这种方法中,学生网络能够处理综合性或细粒度的分类任务。
Dvornik等人 [46] 试图通过小样本学习从教师网络中蒸馏知识来学习一个能够预测未见过类别的学生网络。
Rusu等人 [107] 提出了一种多教师单学生策略蒸馏方法,该方法能够将强化学习智能体的多个策略蒸馏到一个学生网络中,用于序列预测任务。
Open challenges: Studies such as the ones mentioned above have shown considerable potential in customizing versatile student networks (定制的通用型学生网络)for various tasks. However, there are some limitations in such methods.
Firstly, the student may not be compact due to the presence of branch-out structures. 由于存在分支扩展结构,学生网络可能不够紧凑
Secondly, current techniques mostly require teachers to share similar network structures (e.g., encoder–decoder), which confines the generalization of such methods. 当前的技术大多要求教师网络共享相似的网络结构(例如,编码器 - 解码器结构),这限制了此类方法的泛化能力。
Thirdly, training might be complicated because some works adopt a dualstage strategy, followed by multiple steps with fine-tuning. 训练过程可能会很复杂,因为一些研究工作采用了两阶段策略,随后还伴有多个微调步骤。
These challenges open scopes for future investigation on knowledge amalgamation.
4.2.6 Mutual learning with ensemble of peers (同伴)
使用多个教师的传统知识蒸馏(KD)方法存在的一个问题是其计算成本和复杂性,因为它们需要经过预训练的高容量教师,并采用两阶段(也称为离线)学习方式。为了简化蒸馏过程,如图 4 (f) 所示,一阶段(在线)知识蒸馏方法 [34, 40, 50, 64, 82, 85, 101, 110, 111] 应运而生。这些方法并非预先训练一个静态的教师模型,而是通过让一组学生模型以同伴教学的方式相互学习,从而同时对它们进行训练。
这类方法有一些优点。**首先,这些方法将教师模型和学生模型的训练过程合并起来,并利用同伴网络来提供教学知识。**其次,这些在线蒸馏策略可以提高任何容量模型的性能,从而实现通用应用。第三,这种同伴蒸馏方法有时能够优于基于教师的两阶段知识蒸馏方法。对于具有相互学习的知识蒸馏,两个同伴之间的蒸馏损失基于KL散度,其可表述为:
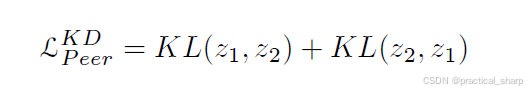
KL表示KL散度计算损失,z1和z2表示peer1和peer2的predictions
除此之外,Lan等人[40]和Chen等人[50]还通过添加辅助分支构建了给定目标(学生)网络的多分支变体,以便从所有分支创建一个局部集成教师(也称为组长)模型。每个分支都使用一种蒸馏损失进行训练,该蒸馏损失使该分支的预测与教师的预测对齐。从数学角度来讲,蒸馏损失可通过最小化集成教师Ze的预测与第个i分支同伴Zi的预测的KL散度来表述:
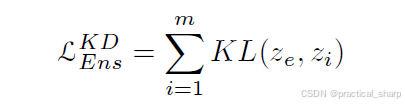
集成教师的预测Ze为所有Zi的加权求和或者是attention-based weights方法[50]。
虽然这些方法中的大多数仅考虑使用logit information,但也有一些研究工作会利用feature information。
Chung等人 [64] 通过采用对抗学习(判别器)提出了一种特征图层级的蒸馏方法。
Kim等人 [110] 引入了一个特征融合模块来形成一个集成教师模型。然而,这种融合是基于来自分支同伴的特征(输出通道)的拼接。
此外,Liu等人 [18] 提出了一个知识流框架,该框架将知识从多个教师网络的特征转移到一个学生网络。
Summary: 与使用预训练教师的两阶段知识蒸馏(KD)方法相比,从学生同伴中进行蒸馏有许多优点。这些方法基于同伴间的相互学习,有时还基于同伴的集成。大多数研究依赖于logits信息;然而,一些研究工作也通过对抗学习或特征融合来利用特征信息。在这个方向上还有改进的空间。例如,对于知识蒸馏处理而言最适宜的同伴数量值得探究。此外,当有教师可用时,同时使用在线和离线方法的可能性也很有意思。在不牺牲准确性和泛化能力的情况下降低计算成本也是一个有待解决的问题。我们将在 6.1 节讨论在线和离线知识蒸馏的优缺点。
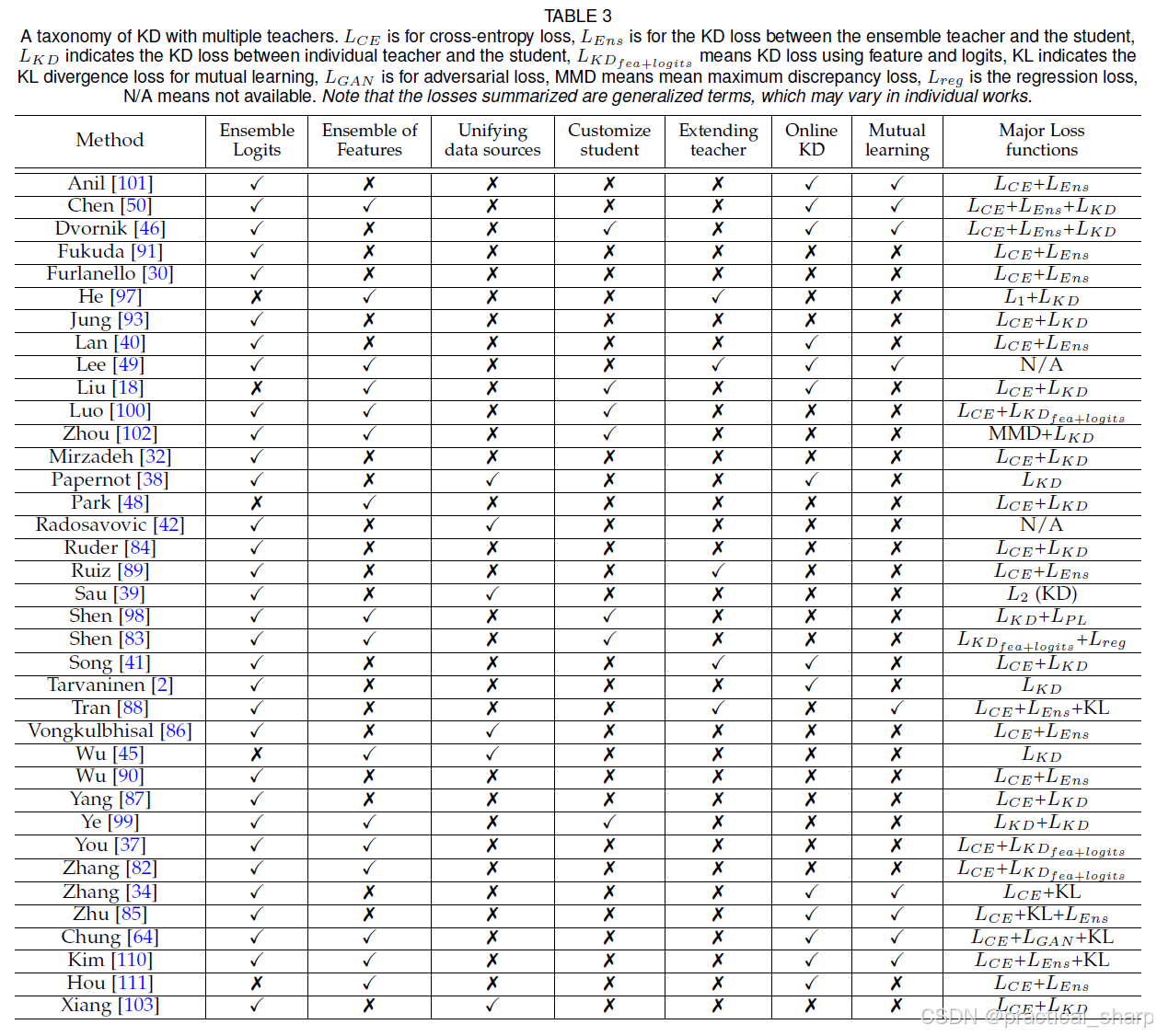
Potentials:表 3 总结了具有多个指导者的知识蒸馏(KD)方法。总体而言,大多数方法依赖于logits的集成。然而,特征表示的知识并没有得到太多的考量。因此,通过设计更好的门控机制来利用特征表示集成的知识是有可能的。统一数据源和扩展教师模型是减少单个教师模型的两种有效方法;然而,它们的性能会有所下降。因此,克服这个问题需要更多的研究。定制一个通用型学生是一个很有价值的想法,但现有的方法受到网络结构、多样性和计算成本的限制,这些方面在未来的工作中必须加以改进。
Section 5: Distillation based on data format
5.1 Data-free distillation
Overall insight:Can we achieve KD when the original data for the teacher or (un)labeled data for training student are not available?
大多数现有KD方法的一个重要的限制,例如[1,28,48,52]假设教师和学生的训练样本都是可获取的。然而, 在现实应用中受限于隐私或者transmission concerns,训练数据往往是不可获取的。To handle this problem, some representative data-free KD paradigms [112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122] are newly developed. 这些方法的分类总结在表 4 中,详细的技术分析如下所述。
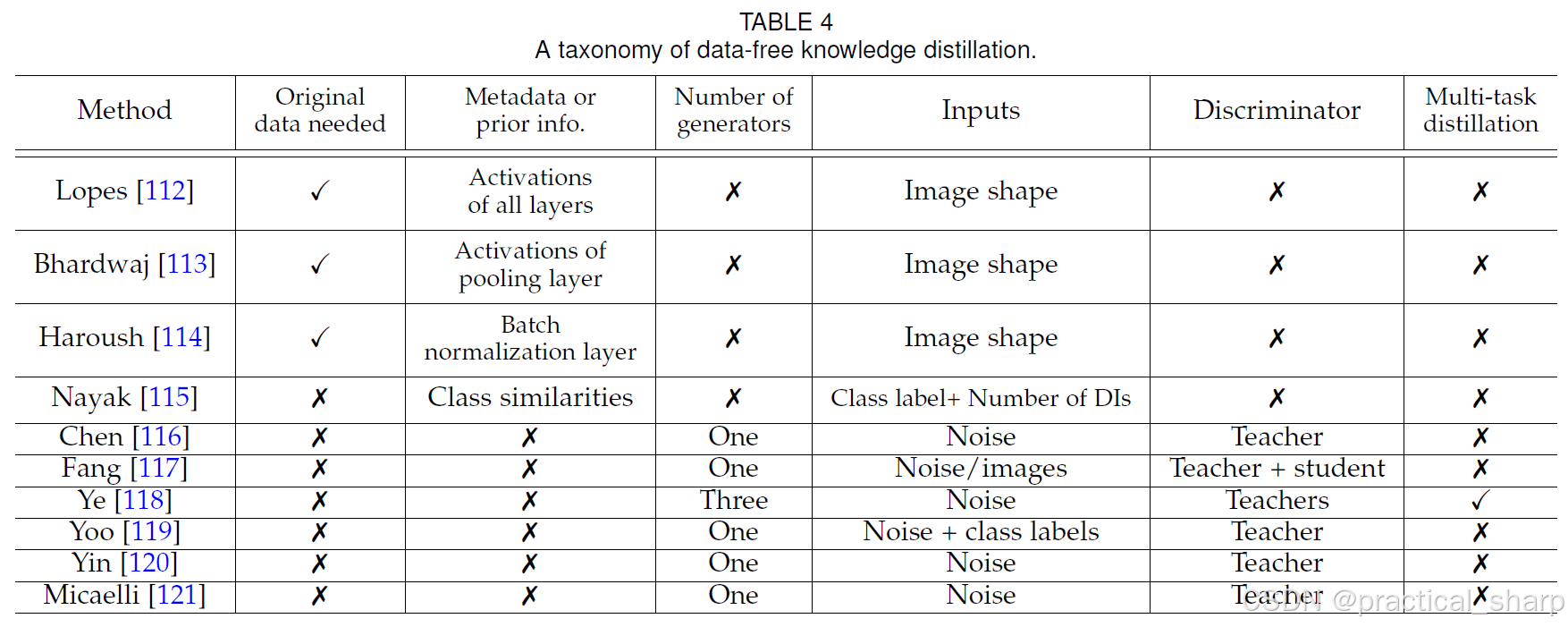
5.1.1 Distillation based on metadata
Lopes等人 [112] 最初提出仅使用教师模型以及以预先计算的激活统计数据形式记录的元数据来重建原始训练数据集。因此,目标是找到这样一组图像,其表征与教师网络给出的表征最为匹配。高斯噪声被随机作为输入传递给教师网络,然后利用梯度下降法(GD)来尽量减小元数据与噪声输入表征之间的差异。为了更好地对重建过程加以约束,教师模型所有层的元数据都被使用并记录下来,以便高精度地训练学生模型。Bhardwaj等人 [113] 证明,利用 K 均值聚类从单层(平均池化层)获取的元数据足以实现较高的学生模型准确率。与 [112, 113] 中需要对真实数据产生的激活值进行采样不同,Haroush等人 [114] 提议使用来自批量归一化(BN)[74] 层的、结合合成样本的元数据(例如,按通道计算的均值和标准差)。基于元数据的知识蒸馏目标可以表述为:
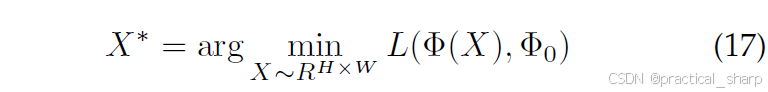
其中X*是需要寻找的图像, is the representation of X, is the representation of the metadata, and L is the loss function (e.g., L2).
5.1.2 Distillation based on class-similarities
Nayak等人 [115] 认为,[112, 113] 中所使用的元数据实际上并非完全无数据的方法,因为这些元数据本身就是利用训练数据形成的。他们转而提出了一种零样本知识蒸馏方法(zero-shot KD approach),该方法既不使用数据样本,也不使用元数据信息。具体而言,这种方法从教师模型的参数中以类别相似性的形式获取有关潜在数据分布的有用先验信息。通过将教师模型的输出空间建模为狄利克雷(Dirichlet)分布,该先验信息可进一步用于精心构造数据样本(也称为数据印记(DIs))。与 [61] 类似,类别相似性矩阵是基于教师模型的 Softmax 层来计算的。数据印记Xik的目标可以基于交叉熵损失来表述:
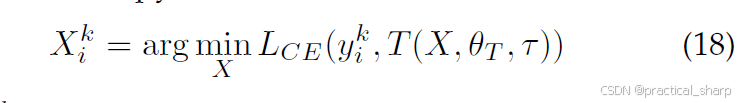
其中yki表示采样的第i-th的softmax向量,k表示类别
5.1.3 Distillation using generator
考虑到基于元数据和基于相似性的知识蒸馏方法的局限性,一些研究工作 [116, 117, 118, 119, 120, 121] 通过对抗学习 [78, 123, 124] 提出了新颖的无数据知识蒸馏方法。尽管在这些方法中任务和网络结构各不相同,但大多数都构建在一个通用框架之上。也就是说,预训练的教师网络被固定用作鉴别器,同时设计了一个生成器,用于在给定各种输入源(例如噪声 [116, 118, 119, 120])的情况下合成训练样本。然而,在一些研究中存在细微差异。Fang等人 [117] 指出了将教师网络作为鉴别器所存在的问题,因为这样会忽略学生网络的信息,并且在没有学生网络参与的情况下无法定制生成的样本。因此,他们将教师网络和学生网络都用作鉴别器以减少两者之间的差异,同时训练一个生成器来生成一些样本,以通过对抗的方式扩大这种差异。
相比之下,Ye等人 [118] 更侧重于强化生成器结构,设计了三个生成器并巧妙地加以运用。具体而言,训练一个组堆叠生成器来生成原本用于预训练教师网络的图像以及中间激活值。然后,一个对偶生成器将生成的图像作为输入,将对偶部分作为目标网络(学生网络),并重新组合以进行多标签分类。为了计算生成图像和中间激活值的对抗损失,还设计了多个组堆叠鉴别器(多个教师网络),以便将多知识融合到生成器中。
Yoo等人 [119] 让生成器接收两个输入:一个采样的类别标签y和噪声z。同时,还应用了一个解码器,用于从生成器根据噪声输入z和类别标签y生成的假数据x’中重构噪声输入z’和类别标签y’。因此,通过最小化y与y’以及z与z’之间的误差,生成器能够生成更可靠的数据。
尽管在 [120] 中没有使用对抗损失,但名为 “深度反演(DeepInversion)” 的生成器(它采用图像先验正则化项来合成图像)是在 DeepDream[125] 的基础上改进而来的。
5.1.4 Open challenges for data-free distillation
尽管无数据知识蒸馏(KD)方法已展现出可观的潜力,并为知识蒸馏开辟了新方向,但仍然存在诸多挑战。首先,恢复得到的图像不够真实且分辨率较低,在一些对数据要求较高的任务(例如语义分割)中可能无法使用。其次,由于使用了众多模块,现有方法的训练和计算过程可能会很复杂。第三,与数据驱动的蒸馏方法相比,恢复数据的多样性和泛化能力仍然有限。第四,此类方法在低级任务(例如图像超分辨率)中的有效性还需进一步研究。
5.2 Distillation with a few data samples
Overall insight: How to perform efficient knowledge distillation with only a small amount of training data?
大多数具有师生(Teacher-Student,简称 S-T)结构的知识蒸馏(KD)方法,例如文献 [1, 48, 54, 64] 中提及的那些方法,都是基于匹配信息(例如logits、hint等),并利用带有完整标注的大规模训练数据集来优化知识蒸馏损失的。因此,训练过程仍然依赖大量数据,且处理效率低下。为了在使用少量训练数据的情况下实现学生模型的高效学习,一些研究工作 [122, 126, 127, 128, 129] 提出了少样本知识蒸馏策略。这些方法的技术亮点在于生成伪训练样本,或者利用逐层估计指标来使教师模型和学生模型对齐。
5.2.1 Distillation via pseudo examples
Insight: If training data is insufficient, try to create pseudo examples for training the student.
当训练数据稀缺并导致学生网络出现过拟合问题时,[122, 126, 128] 这些研究着重于创建伪训练样本。具体而言,Kimura等人 [128] 采用诱导点(inducing points)[130] 的思路来生成伪训练样本,然后通过应用对抗样本(adversarial examples)[131, 132] 对这些伪训练样本进行更新,并借助模仿损失(imitation loss)对其做进一步优化。
Liu等人 [126] 从一个教师模型(用 ImageNet 数据集训练得到的模型)中生成伪 ImageNet [51] 标签,并且还利用语义信息(例如词语)为学生模型添加一个监督信号。
有趣的是,Kulkarni等人 [122] 创建了一种 “mismatched” 的unlabeled stimulus(例如,由在 CIFAR 数据集 [134] 上训练的教师模型所提供的 MNIST 数据集 [133] 的软标签),这些 “mismatched” 的无标注刺激被用于扩充少量训练数据,进而用于训练学生模型。
5.2.2 Distillation via layer-wise estimation
Insight: Layer-wise distillation from the teacher network via estimating the accumulated errors on the student network can also achieve the purpose of few-example KD.
在Bai等人 [129] 和Li等人 [127] 的研究中,首先会对教师网络进行压缩,通过网络剪枝 [135] 的方式构建出一个学生网络,然后运用逐层的蒸馏损失来减少在给定有限样本情况下的估计误差。
为了进行逐层蒸馏,Li等人 [127] 在学生网络中每个经过剪枝的层块之后添加一个 1×1 的卷积层,并估算最小二乘误差,以便使参数与学生网络相匹配。Bai等人 [129] 则采用交叉蒸馏损失,在教师网络当前估计值的基础上,去模拟教师网络的行为表现。
5.2.3 Challenges and potentials
尽管受到数据增强和逐层学习技术启发的少量样本知识蒸馏(KD)方法颇具说服力,但这些技术仍然受到教师网络结构的限制。这是因为大多数方法依靠对教师网络进行网络剪枝来创建学生网络。此外,学生网络的性能在很大程度上依赖于精心制作的伪标签的数量,这可能会阻碍这些方法发挥效力。最后,大多数相关研究侧重于通用分类任务,尚不清楚这些方法对于无类别标签的任务(例如低级视觉任务)是否有效。
5.3 Cross-modal distillation
Overall insight: KD for cross-modal learning is typically performed with network architectures containing modal-specific representations or shared layers, utilizing the training images in correspondence of different domains.
我们提出的一个自然而然的问题是:当训练样本在不同领域间相互对应时,是否有可能将来自针对某一任务预先训练好的教师网络的知识,迁移到正在学习另一任务的学生网络中。需要注意的是,跨模态学习的知识蒸馏与领域自适应的知识蒸馏有着本质区别,在领域自适应中,数据是从不同领域独立抽取的,但任务是相同的。
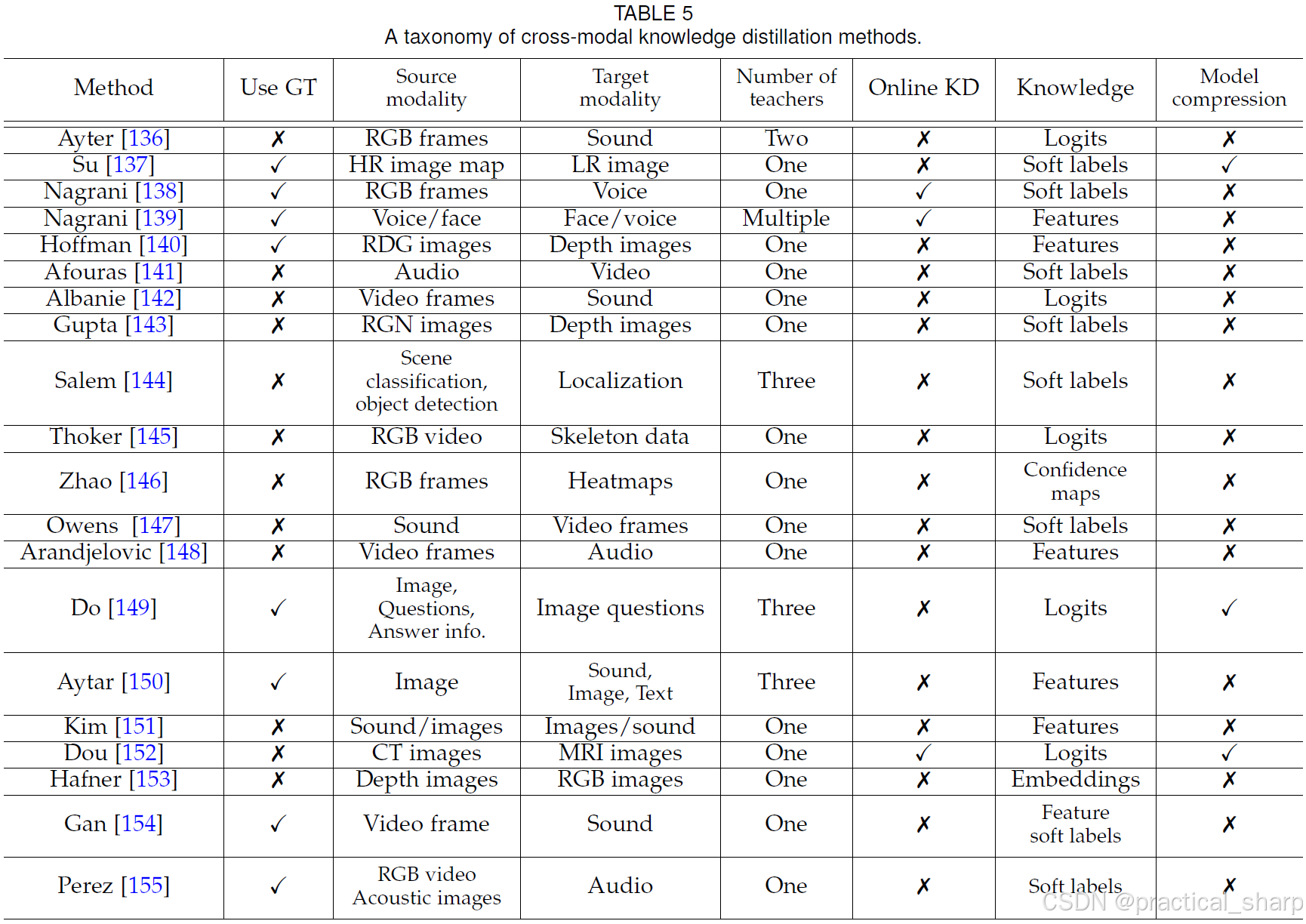
与前文提及的侧重于在教师与学生之间的同一模态内传递监督信息的知识蒸馏方法相比,跨模态知识蒸馏将教师的表征用作监督信号,以训练正在学习另一任务的学生。在此问题设定下,学生需要依靠教师的视觉输入来完成其任务。基于此,许多新颖的跨模态知识蒸馏方法 [136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 152, 153, 156] 已被提出。我们现在对其技术细节进行系统分析,并指出跨领域蒸馏所面临的挑战及潜在优势。
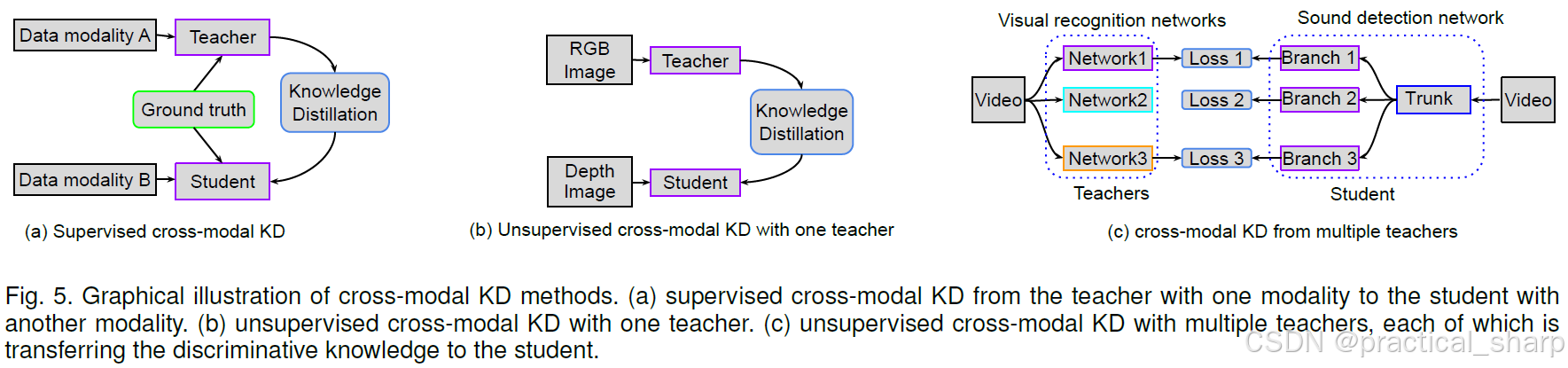
5.3.1 Supervised cross-modal distillation
如图 5(a)所示,使用学生网络所用数据的真实标签是跨模态知识蒸馏(KD)的常见方式。Do等人 [149]、Su等人 [137]、Nagrani等人 [138]、Nagrani等人 [139] 以及Hoffman等人 [140] 依靠有监督学习来进行跨模态迁移。多项研究 [138, 139, 141, 155] 利用视频数据中视觉和音频信息的同步性,学习两种模态之间的联合嵌入。Afouras等人 [141] 和Nagrani等人 [139] 将语音知识进行迁移,以学习视觉检测器,而Nagrani等人 [138] 则利用视觉知识来学习语音检测器(作为学生网络)。
相比之下,Hoffman等人 [140]、Do等人 [149] 以及Su等人 [137] 仅聚焦于视觉领域内的不同模态。具体而言,Hoffman等人 [140] 通过从 RGB 网络迁移知识来学习深度网络,并融合跨模态的信息,这提高了测试阶段的目标识别性能。Su等人 [137] 利用来自高质量图像的知识来学习一个对低质量图像(成对的)具有更好泛化能力的分类器。
5.3.2 Unsupervised cross-modal distillation
Most cross-modal KD methods exploit unsupervised learning, since the labels in target domains are hard to get. Thus, these methods are also called distillation ‘in the wild’. In this setting, the knowledge from the teacher’s modality provides supervision for the student network. To this end, some works [136, 141, 142, 143, 144, 145, 146, 147, 148, 150, 151, 152, 153, 156] aimed for cross-modal distillation in an unsupervised manner.
5.3.3 Learning from one teacher
Afouras et al. [141], Albanie et al. [142], Gupta et al. [143], Thoker et al. [145], Zhao et al. [146], Owens et al. [147], Kim et al. [151], Arandjelovic et al. [148], Gan et al. [154], and Hafner et al. [153] focus on distilling knowledge from one teacher (see Fig. 5(b)), and mostly learn a single student network. Thoker et al. [145] and Zhao et al. [146] learn two students. Especially, Thoker et al. refer to mutual learning [34], where two students learn from each other based on two KL divergence losses. In addition, Zhao et al. [146] exploit the feature fusion strategy, similar to [110, 157] to learn a more robust decoder. Do et al. [149] focuses on unpaired images of two modalities, and learns a semantic segmentation network (student) using the knowledge from the other modality (teacher).
5.3.4 Learning from multiple teachers
Aytar et al. [136], Salem et al. [144], Aytar et al. [150] and Do et al. [149] exploit the potential of distilling from multiple teachers as mentioned in Sec. 4.2. 挖掘了如 4.2 节所述的从多位教师网络中提取知识的潜力
大多数方法依赖视觉、音频和文本信息之间的并发知识,如图 5(c)所示。
Salem等人 [144] 仅聚焦于视觉模态,在该模态下,各位教师通过多任务方法学习目标检测、图像分类以及场景分类的相关信息,并将这些知识提炼后传递给单个学生网络。
5.3.5 Potentials and open challenges
Potentials:
基于对表 5 中现有跨模态知识蒸馏(KD)技术的分析,我们可以看出,跨模态知识蒸馏拓展了从教师模型所学知识的泛化能力。跨领域知识蒸馏在减轻对单模态或双模态下大量标注数据的依赖方面有着可观的潜力。此外,跨领域知识蒸馏的可扩展性更强,能够轻松应用于新的蒸馏任务。而且,它对于学习 “自然环境中” 的多模态数据是有利的,因为基于其他数据来获取单模态数据相对容易。在视觉应用方面,跨模态知识蒸馏具备在由不同类型相机拍摄的图像之间提炼知识的潜力。例如,可以将知识从 RGB 图像提炼到事件流(由事件相机采集的堆叠事件图像)中 [137, 158]。
Open challenges:
由于知识是教师模型转移过来的表征(例如,逻辑值、特征),确保转移知识的稳健性至关重要。我们希望转移的是良好的表征,但负面的表征确实存在。因此,教师所提供的监督信息与目标模态相互补充是必不可少的。 此外,现有的跨模态知识蒸馏方法高度依赖数据源(例如,视频、图像),然而找到具有配对(例如,带有深度信息配对的 RGB 图像)或多模态(类别标签、边界框和分割标签)的数据并非总是一件易事。我们不禁要问,是否有可能想出一种无数据蒸馏或基于少量样本进行蒸馏的方法呢?换句话说,是否有可能仅依据教师的知识,利用来自目标模态的数据来学习学生模型,而不参考源模态呢?
此外,现有的跨模态知识蒸馏(KD)方法大多是离线方法,这类方法计算量和内存占用量都很大。因此,如果能考虑一种在线知识蒸馏策略就更好了。最后,一些研究工作(例如 [144, 150])利用来自多位教师的知识来学习学生模型。然而,这样学习到的学生模型通用性较差,且依赖特定模态。
受 4.2.5 节分析的启发,我们提出一个研究问题:是否有可能学习到一个通用性强、能够执行多种模态任务的学生模型呢?
Section 6:ONLINE AND TEACHER-FREE DISTILLATION
6.1 Online distillation
Overall insight: With the absence of a pre-trained powerful teacher, simultaneously training a group of student models by learning from peers’ predictions is an effective substitute for twostage (offline) KD
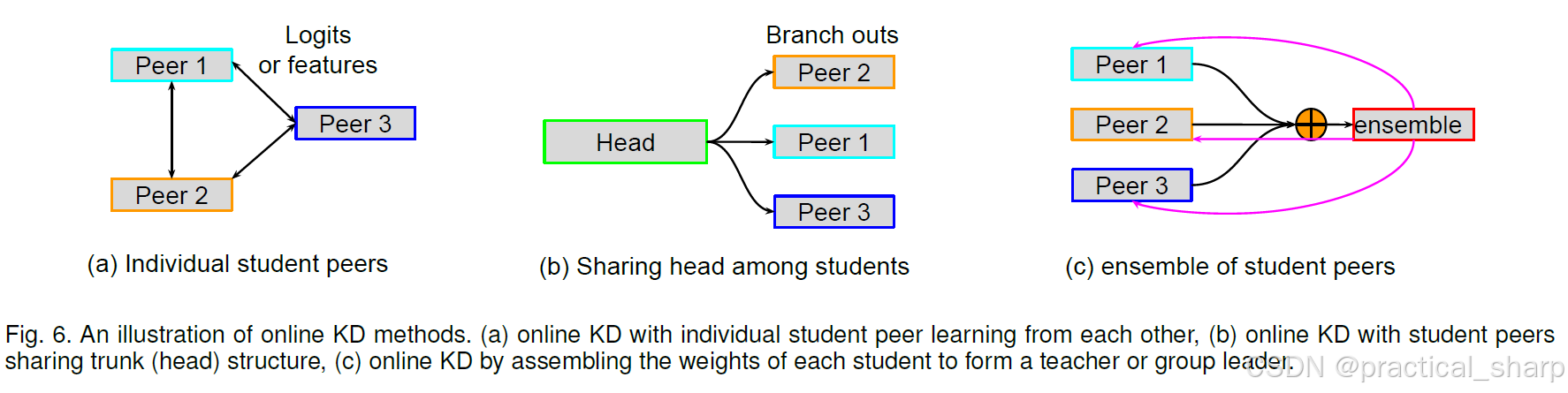
In this section, we provide a deeper analysis of online (one-stage) KD methods in contrast to the previously discussed offline (two-stage) KD methods. Offline KD methods often require pre-trained high-capacity teacher models to perform one-way transfer [1, 8, 37, 54, 91, 111, 159, 160, 161].
However, it is sometimes difficult to get such ‘good’ teachers, and the performance of the student gets degraded when the gap of network capacity between the teacher and the student is significant. In addition, two-stage KD requires many parameters, resulting in higher computation costs. To overcome these difficulties, some studies focus on online KD that simultaneously trains a group of student peers by learning from the peers’ predictions.
6.1.1 Individual student peers
Zhang et al. [34], Gao et al. [160] and Anil et al. [101] focus on online mutual learning [34] (also called codistilation) in which a pool of untrained student networks with the same network structure simultaneously learns the target task.
In such a peer-teaching environment, each student learns the average class probabilities from the other (see Fig. 6(a)).
However, Chung et al. [64] also employ individual students, and additionally design a feature map-based KD loss via adversarial learning. Hou et al. [111] proposed DualNet, where two individual student classifiers were fused into one fused classifier.
During training, the two student classifiers are locally optimized, while the fused classifier is globally optimized as a mutual learning method. Other methods such as [159, 162], focus on online video distillation by periodically updating the weights of the student, based on the output of the teacher. Although codistillation achieves parallel learning of students, [34, 64, 101, 111] do not consider the ensemble of peers’ information as done in other works such as [50, 160].
6.1.2 Sharing blocks among student peers
Considering the training cost of employing individual students, some works propose sharing network structures (e.g., head sharing) of the students with branches as shown in Fig. 6(b). Song et al. [41] and Lan et al. [40] build the student peers on multi-branch architectures [131]. In such a way, all structures together with the shared trunk layers (often use head layers) can construct individual student peers, and any target student peer network in the whole multi-branch can be optimized.
6.1.3 Ensemble of student peers
While using codistillation and multi-architectures can facilitate online distillation, knowledge from all student peers is not accessible.
为此,一些研究 [40, 50, 110, 160, 161] 提议利用所有学生同伴的知识集合(逻辑值信息)来构建一个即时生成的教师(或称为小组组长),然后再将其知识反向提炼回所有学生同伴那里,以闭环的形式促进学生学习,如图 6(c)所示。需要注意的是,在集成蒸馏中,学生同伴之间既可以是相互独立的,也可以共享相同的头部结构(主干部分)。集成蒸馏损失由 4.2 节中的公式 12 给出,其中添加了一个门控组件gi,用于平衡每个学生的贡献。陈等人 [50] 基于自注意力机制 [72] 来获取门控组件gi。
6.1.4 Summary and open challenges
Summary:
基于上述分析,我们确定了协同蒸馏(co-distillation)、多架构(multi-architectures)以及集成学习(ensemble learning)是在线知识蒸馏的三种主要技术。与离线知识蒸馏相比,在线知识蒸馏具有一些优势。首先,在线知识蒸馏不需要预先训练教师模型。其次,在线学习通过与其他学生同伴一同训练,为提高网络的学习效率和泛化能力提供了一种简单却有效的方式。第三,与同伴一起进行在线学习往往能比离线学习取得更好的学习效果。
Open challenges: There are some challenges in online KD.
首先,对于为何在线学习有时优于离线学习,目前缺乏理论分析。其次,在在线集成知识蒸馏(KD)中,仅仅聚合学生的逻辑值来构建集成教师会限制学生同伴的多样性,进而限制在线学习的有效性。第三,现有方法局限于存在真实(Ground Truth,简称 GT)标签的问题(例如分类问题)。然而,对于一些问题(例如低级视觉问题),还需要探索学生同伴构建有效集成教师的方法。
6.2 Teacher-free distillation
Overal insight: Is it possible to enable the student to distill knowledge by itself to achieve plausible performance?
传统的知识蒸馏(KD)方法 [1, 52, 57, 61, 110] 尽管已经在性能提升方面取得了显著成效,但仍有许多有待解决的问题。首先,这些方法效率低下,因为学生模型很难充分利用教师模型中的所有知识。其次,设计和训练高容量的教师模型仍然面临诸多阻碍。第三,两阶段蒸馏需要高昂的计算和存储成本。为应对这些挑战,近期已经提出了几种新颖的自蒸馏框架 [25, 30, 80, 163, 164, 165, 166, 167, 168, 169, 170, 171]。自蒸馏的目标是在不借助其他模型的情况下,通过对自身知识进行蒸馏来学习学生模型。现在,我们对自蒸馏的技术细节进行详细分析。
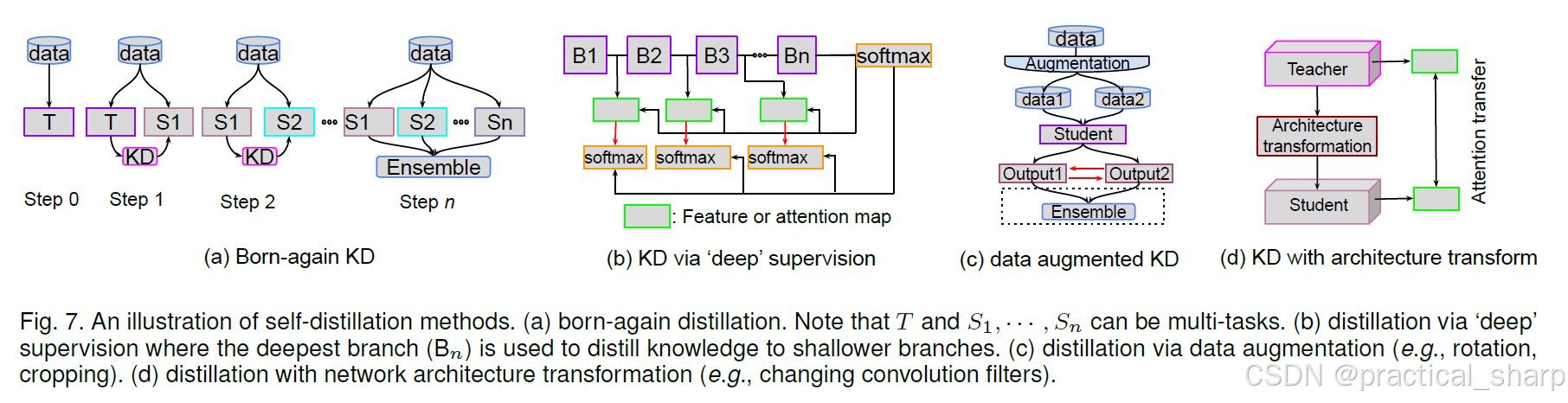
6.2.1 Born-again distillation
Insight: Sequential self-teaching of students enables them to become masters, and outperform their teachers significantly. 学生的循序渐进式自我教学能让他们成为高手,并显著超越他们的老师。
Furlanello等人 [30] 开创了self-distillation的概念,在该概念中,学生模型与教师模型采用相同的参数化方式,如图 7(a)所示。通过循序渐进式教学,学生模型不断得到更新,并且在这一过程结束时,通过对多代学生模型进行集成可实现额外的性能提升。
Hahn等人 [165] 将 “重生蒸馏”(born-again distillation)[30] 应用于自然语言处理领域。Yang等人 [25] 注意到师生(S-T)优化的工作原理尚不明确,于是他们着重于对教师模型设置严格性要求(在标准交叉熵损失的基础上添加额外项),以便学生模型能够更好地学习类间相似性,并有可能防止过拟合现象的发生。
Clark等人 [80] 没有局限于学习单个任务,而是将 [30] 中的方法扩展到多任务场景中,在该场景下,单任务模型被依次蒸馏,以训练一个多任务模型。由于 “重生蒸馏” 方法是基于多阶段训练的,与后续的方法相比,其效率较低且计算量较大。
6.2.2 Distillation via ‘deep’ supervision
Insight: The deeper layers (or branches) in the student model contains more useful information than those of shallower layers.
在这些方法中,Hou等人 [169]、Luan等人 [170] 以及Zhang等人 [168] 提出了类似的方法,即根据目标网络(学生网络)的深度及其原有结构将其划分为若干较浅的部分(分支)(见图 7(b))。由于最深的部分可能比更浅的部分包含更多有用且具有判别性的特征信息,因此可以利用较深的分支向较浅的分支进行知识蒸馏。
与之不同的是,在 [169] 中,并非直接对特征进行蒸馏,而是采用了 [36] 中使用的基于注意力的方法,迫使较浅层去模仿较深层的注意力图。Luan等人 [170] 将每一层分支(残差网络块)都当作一个分类器。这样一来,最深层的分类器就被用于向更早期的分类器的特征图和逻辑值进行知识蒸馏。
6.2.3 Distillation based on data augmentation
Insight: Data augmentation (e.g., rotation, flipping, cropping, etc) during training forces the student network to be invariant to augmentation transformations via self-distillation.
尽管大多数方法侧重于研究在自蒸馏过程中如何更好地对学生模型进行监督,但用于训练学生模型的数据表征并未得到充分挖掘和利用。为此,Xu等人 [164] 和Lee等人 [166] 着重通过对训练样本进行数据增强的方式来实现自蒸馏,如图 7(c)所示。这样的框架具有一些优势。
首先,在无需进行分支划分或借助其他模型帮助的情况下,对单个学生网络进行优化是高效且有效的。其次,通过数据到数据的自蒸馏,学生模型能够学习到更多用于泛化的内在表征。第三,学生模型的性能能够在计算成本和内存负载相对较低的情况下得到显著提升。
Xu等人 [164] 对来自训练数据的批量图像应用随机镜像和裁剪操作。此外,受相互学习 [34] 的启发,原始批量图像和经过扭曲的批量图像的最后特征层以及 softmax 输出分别通过最大均值差异(MMD)损失 [55] 和 KL 散度损失进行相互蒸馏。
与之不同的是,Lee等人 [166] 考虑了两种类型的数据增强方式(对同一图像进行旋转和颜色置换),并且采用了 [40, 50, 85] 中所使用的集成方法,将学生模型的所有logits聚合为一个,然后学生模型再利用这个聚合后的结果将知识传递给自身。
6.2.4 Distillation with architecture transformation
Insight: A student model can be derived by changing the convolution operators in the teacher model with any architecture change. 通过对教师模型中的卷积算子进行改变,并做任何架构上的变动,就能推导出一个学生模型。
与上述所有自蒸馏方法不同的是,Crowley等人 [167] 提出了结构模型蒸馏方法,旨在通过用成本更低的卷积来替换标准卷积块以减少内存占用,如图 7(d)所示。通过这种方式,可以生成一个学生模型,它是对教师模型架构进行简单变换后的产物。然后,运用注意力转移(AT)[55] 方法来使教师的注意力图与学生的注意力图对齐。
6.2.5 Summary and open challenges
Summary
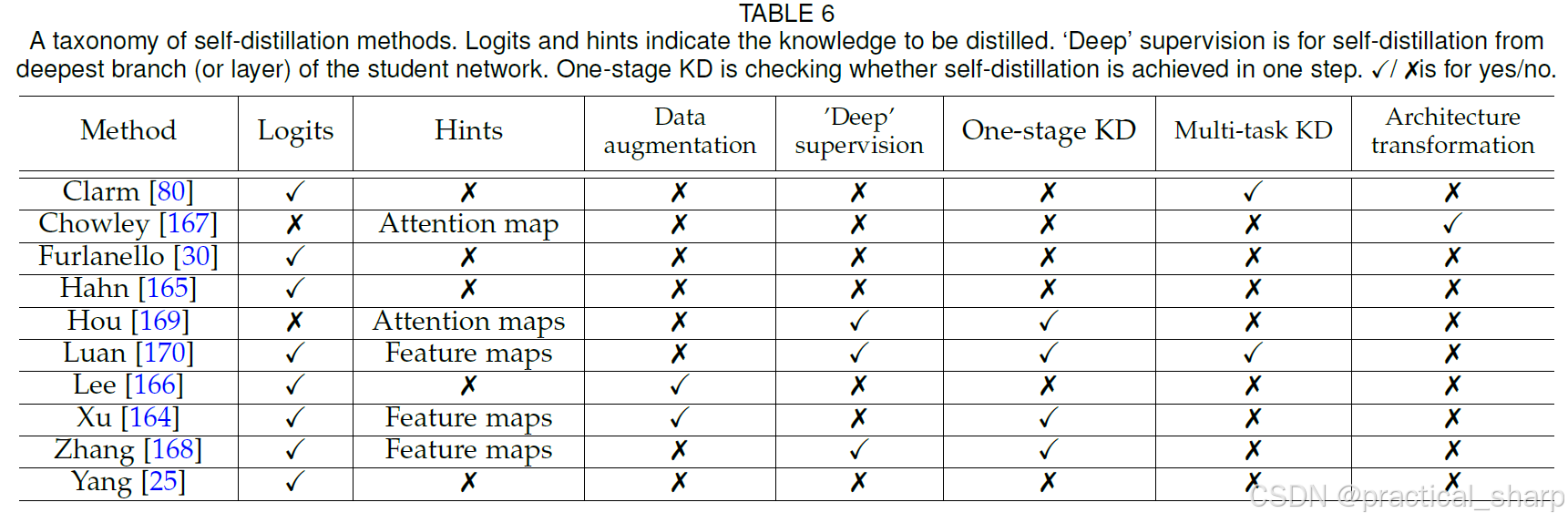
在表 6 中,我们对不同的自蒸馏方法进行了总结与比较。总体而言,利用逻辑值 / 特征信息以及采用两阶段训练,并借助来自最深分支的 “深度” 监督来进行自蒸馏是主流做法。此外,基于数据增强和基于注意力的自蒸馏方法颇具前景。最后,研究表明结合自蒸馏的多任务学习也是一个很有价值的方向,值得开展更多的研究。
Open challenges
目前仍存在诸多有待解决的挑战。首先,在解释自蒸馏为何效果更好这一点上缺乏理论支撑。Mobahi等人 [163] 对 “重生蒸馏”[30] 进行了理论分析,发现自蒸馏可能通过循环训练减少过拟合现象,从而带来良好的性能表现。然而,对于其他自蒸馏方法(例如在线 “深度” 监督 [168, 169, 170])为何效果更佳,目前仍不清楚。
此外,现有方法侧重于针对特定类型的基于分组的网络结构(例如残差网络分组)进行自蒸馏。因此,自蒸馏方法的泛化能力和灵活性有待进一步探究。最后,所有现有方法都聚焦于基于分类的任务,而自蒸馏对于其他任务(例如低级视觉任务)是否有效尚不明确。
Section 7 Label-Required / -Free Distillation
Overall insights: It is possible to learn a student without referring to the labels of training data?
7.1 Label-required distillation
知识蒸馏(KD)的成功依赖于这样一个假设:标签能够为当前任务提供所需水平的语义描述 [1, 4]。例如,在大多数现有的用于分类相关任务的知识蒸馏方法 [1, 8, 9, 28, 48, 131, 172] 中,学习学生网络需要图像级别的标签。同时,在训练数据稀缺的情况下,一些研究工作会利用伪标签。现在,我们对这两类方法进行系统分析。
7.1.1 KD with original labels.
在学生网络中使用真实的数据标签是知识蒸馏(KD)的常见方式。如公式 2 所示,总体损失函数由学生损失和蒸馏损失两部分组成。学生损失在很大程度上依赖于真实标签。按照这种方式,主流方法大多利用原始标签并设计更优的蒸馏损失项,以实现更好的性能表现 [50, 55, 173, 174, 175, 176]。这一惯例在近期的知识蒸馏方法中也一直被沿用,比如在线蒸馏 [50, 159]、无教师蒸馏 [82, 154, 168],甚至跨模态学习 [137, 138, 139, 143, 149, 150]。虽然使用标签拓展了学习学生网络时知识的泛化能力,但在标签稀缺或无法获取的情况下,这类方法就会失效。
7.1.2 KD with pseudo labels.
一些研究工作也会利用伪标签。最常见的方法可分为两类。
第一类旨在创建含噪标签。[20, 21, 22, 23] 提议利用大量含噪标签来扩充少量的干净标签,这有助于提高学生网络的泛化能力和鲁棒性。
第二类方法侧重于通过元数据 [112]、类别相似性 [115] 或生成标签 [117, 118] 等方式来创建伪标签。
7.2 Label-free distillation
然而,在现实世界的应用中,学生网络所用数据的标签并非总是易于获取。因此,人们已经进行了一些无标签蒸馏方面的尝试。现在,我们对这些方法展开更详细的分析。
7.2.1 KD with dark knowledge.
这启发了一些研究在无需标签的情况下利用知识蒸馏(KD)技术。根据我们的综述,无标签蒸馏大多是在跨模态学习中实现的,正如 5.3 节所讨论的那样。在有配对模态数据(例如视频和音频)的情况下,若其中一种模态(例如视频)的标签是可用的,那么学生网络仅依据公式 2 中的蒸馏损失来学习最终任务 [136, 141, 144, 147, 148, 153]。也就是说,在这种情形下,教师网络的隐含知识为学生网络提供了 “监督” 作用。
7.2.2 Creating meta knowledge.
近期,一些方法 [117, 118, 120] 提出了用于知识蒸馏(KD)的数据 / 标签无依赖框架。其核心技术是利用特征或logits信息(也被称作元知识)来精心制作带有标签的样本。尽管这些方法为知识蒸馏指出了一个有趣的研究方向,但要实现合理的性能表现,仍然存在诸多挑战。
7.3 Potential and challenges.
无标签蒸馏是一个很有前景的方向,因为它减轻了对数据标注的需求。然而,目前的研究现状表明,在这个方向上仍然存在诸多不确定性和挑战。主要关注点在于如何确保教师提供的 “监督” 足够可靠。由于一些研究将知识解释为一种标签正则化 [172] 或类别相似性 [177] 的方式,所以保证学生能够获取这些知识就至关重要。
有标签蒸馏面临的另一个关键挑战是,在公式 2 中,尽管学生损失(例如交叉熵损失)会用到标签,但知识蒸馏(KD)损失项从不涉及任何标签信息。由于标签为学生学习提供了有价值的知识,所以寻找一种将标签用于知识蒸馏损失以进一步提升性能的方法是很有意义的。
虽然人们普遍认为预训练的教师已经掌握了足够多的关于标签信息的知识,但其预测结果与真实标签之间仍然存在相当大的差距。根据我们的文献综述,将标签信息引入蒸馏损失存在一定的困难。也就是说,要引入标签信息,教师可能需要进行更新或微调,这可能会导致额外的计算成本。不过,基于近期一些关于元学习或持续学习的尝试,仅利用少量样本学习标签信息是有可能的。此外,像文献 [178] 中所做的那样,基于标签学习一种引导性表征,并将该信息进一步融入知识蒸馏损失也是有可能的。我们确实认为这个方向在现实世界的应用中很有前景,因此期望未来的研究能够朝着这个方向发展。
Section 8 KD with Novel Learning Metrics
8.1 Distillation via adversarial learning
Overall Insight: GAN can help learn the correlation between classes and preserve the multi-modality of S-T framework, especially when student has relatively small capacity. 生成对抗网络(GAN)有助于学习类别之间的相关性,并保留师生(S-T)框架的多模态特性,尤其是在学生模型容量相对较小的情况下。
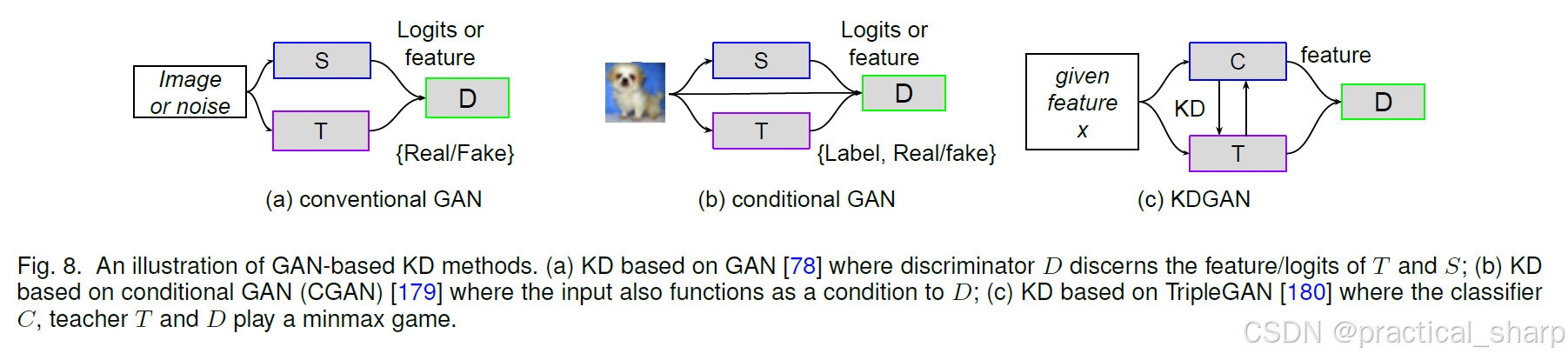
在 4.1 节中,我们已经讨论了两种最常用的知识蒸馏(KD)方法。然而,关键问题在于,由于教师模型无法完美地对真实数据分布进行建模,学生模型很难从教师模型那里学到真实的数据分布情况。生成对抗网络(GANs)[78, 123, 124, 158, 180] 已被证明在图像转换中学习真实数据分布方面具有潜力。为此,近期的一些研究工作 [62, 64, 116, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, 198, 199] 已经尝试探索对抗学习来提升知识蒸馏的性能。实际上,这些工作是基于生成对抗网络的三种基本原型 [20, 78, 179] 构建而成的。因此,我们阐述了这三种生成对抗网络的原理(如图 8 所示),并对现有的基于生成对抗网络的知识蒸馏方法进行分析。
8.1.1 A basic formulation of GANs in KD
如图 8(a)所示,第一种生成对抗网络(GAN)旨在通过训练生成器G和判别器D来生成连续数据,判别器D会对生成器G生成的不合理结果进行惩罚。 生成器G根据从特定分布(例如正态分布)中采样得到的随机噪声z生成合成样本G(z)(例如图像)[78]。这些合成样本会与从真实数据分布p(x)中采样得到的真实样本一同被输入到判别器D中。判别器D试图区分这两种输入,而生成器G和判别器D会在一个极小极大博弈中提升各自的能力,直至判别器D无法区分真假样本为止。其目标函数可写成如下形式:
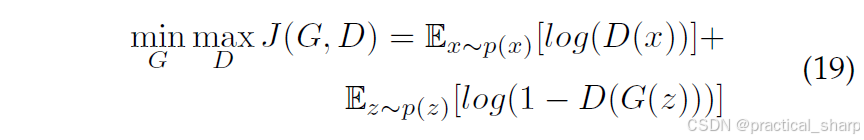
其中p(z)表示噪声的分布(例如均匀分布或正态分布)。
用于知识蒸馏(KD)的第二种生成对抗网络(GAN)是基于条件生成对抗网络(CGAN)[123, 124, 179, 200] 构建的,如图 8(b)所示。条件生成对抗网络(CGAN)经过训练,可依据类别条件分布c生成样本。生成器使用有用信息而非随机噪声来进行替换。因此,给定条件信息后,生成器的目标就是生成逼真的数据。从数学角度来说,其目标函数可写成如下形式:
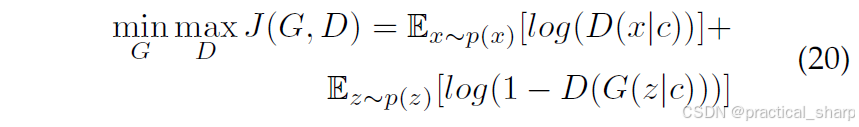
给定条件分布c生成样本。
与上述两种GAN不同,三元生成对抗网络(Triple-GAN)[20](第三种类型)引入了一个三方博弈,其中包含一个分类器C、一个生成器G和一个判别器D,如图 8(c)所示。生成器G和判别器D的对抗学习克服了一些难题 [78],例如优化效果不佳以及生成器无法控制生成样本的语义等问题。
我们假设存在一对来自真实分布p(x, y)的数据(x, y)。从p(x)中采样得到一个样本x后,分类器C会依据条件分布pc(y|x)赋予一个伪标签y,也就是说,分类器C对条件pc(y|x)≈p(y|x)分布进行了刻画。生成器的目标是对另一个方向的条件分布pg(x|y)≈p(x|y)进行建模,而判别器D则负责判断一对数据(x,y)是否来自真实分布p(x,y)。因此,极小极大博弈可以表述为:
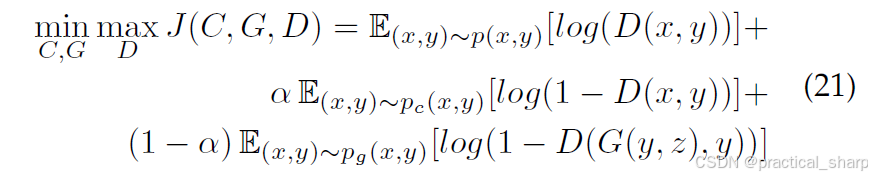
其中阿尔法是超参数来控制损失权重,但是z是什么?
8.1.2 How does GAN boost KD?
Based on the aforementioned formulation of GANs, we analyze how they are applied to boost the performance of KD with S-T learning.
KD based on the conventional GAN (first type)
Chen等人 [116] 和Fang等人 [117] 专注于通过第一种生成对抗网络(如图 8(a)所示)将教师模型的逻辑值(logits)知识蒸馏到学生模型中。基于判别器预测逻辑值有几个好处。首先,如公式 19 所描述的那样,学习到的损失在图像转换任务中可能是有效的 [123, 124, 200]。第二个好处与网络输出的多模态特性密切相关;因此,不必像通常所做的那样 [1, 52] 精确地模仿一个教师网络的输出以实现良好的学生模型性能。然而,由于判别器只捕捉教师和学生输出(逻辑值)的高级统计信息,所以缺少了低层级特征的对齐。
相比之下,Belagiannis等人 [183]、Liu等人 [185]、Hong等人 [192]、Aguinaldo等人 [198]、Chung等人 [64]、Wang等人 [194]、Wang等人 [186]、Chen等人 [203] 以及Li等人 [199] 旨在通过对抗学习来区分特征是来自教师模型还是学生模型,这有效地使这两种分布相互靠近。由于维度方面的原因,教师和学生模型的特征被用作判别器的输入。从教师模型中提取的特征表示是高级抽象信息,便于分类,这降低了判别器出错的概率 [185]。然而,在这种设定下的生成对抗网络训练有时不稳定,甚至难以收敛,尤其是当学生模型和教师模型的容量差异较大时。为了解决这个问题,一些正则化技术,如随机失活(dropout)[24] 或 L2 或 L1 正则化 [183] 被添加到公式 19 中以约束权重。
KD based on CGAN (second type)
Xu等人 [206] 和Yoo等人 [119] 将条件生成对抗网络(CGAN)[179] 应用于知识蒸馏(KD)中,他们训练判别器来区分标签分布(逻辑值)是来自教师模型还是学生模型。被视作生成器的学生模型通过对抗训练的方式来欺骗判别器。Liu等人 [184] 也利用条件生成对抗网络(CGAN)对图像生成网络进行压缩。不过,判别器会连同辅助分类器生成对抗网络(GAN)[205] 一起预测教师模型和学生模型的类别标签。
与之不同的是,Roheda等人 [187]、Zhai等人 [193]、Li等人 [199]、Chen等人 [203] 以及Liu等人 [197] 侧重于在条件生成对抗网络(CGAN)框架下区分教师模型和学生模型的特征空间。有趣的是,陈(Chen)等人 [203] 部署了两个判别器,即教师判别器和学生判别器,用于压缩图像转换网络。为避免模型崩溃,刘(Liu)等人 [197] 使用了Wasserstein loss [202] 来稳定训练过程。
KD based on TripleGAN (third type)
与基于常规生成对抗网络(GAN)和条件生成对抗网络(CGAN)的蒸馏方法不同,Wang等人 [181] 提出了一种名为知识蒸馏生成对抗网络(KDGAN)的三方博弈,它由一个分类器(可视为学生模型)、一个教师模型以及一个判别器(与三元生成对抗网络 [20] 中的原型类似)组成,如图 8(c)所示。分类器和教师模型通过蒸馏损失相互学习,并依据公式 21 中定义的对抗损失与判别器进行对抗训练。通过同时优化蒸馏损失和对抗损失,分类器(即学生模型)能够在平衡状态下学习到真实的数据分布。
8.1.3 Summary and open challenges
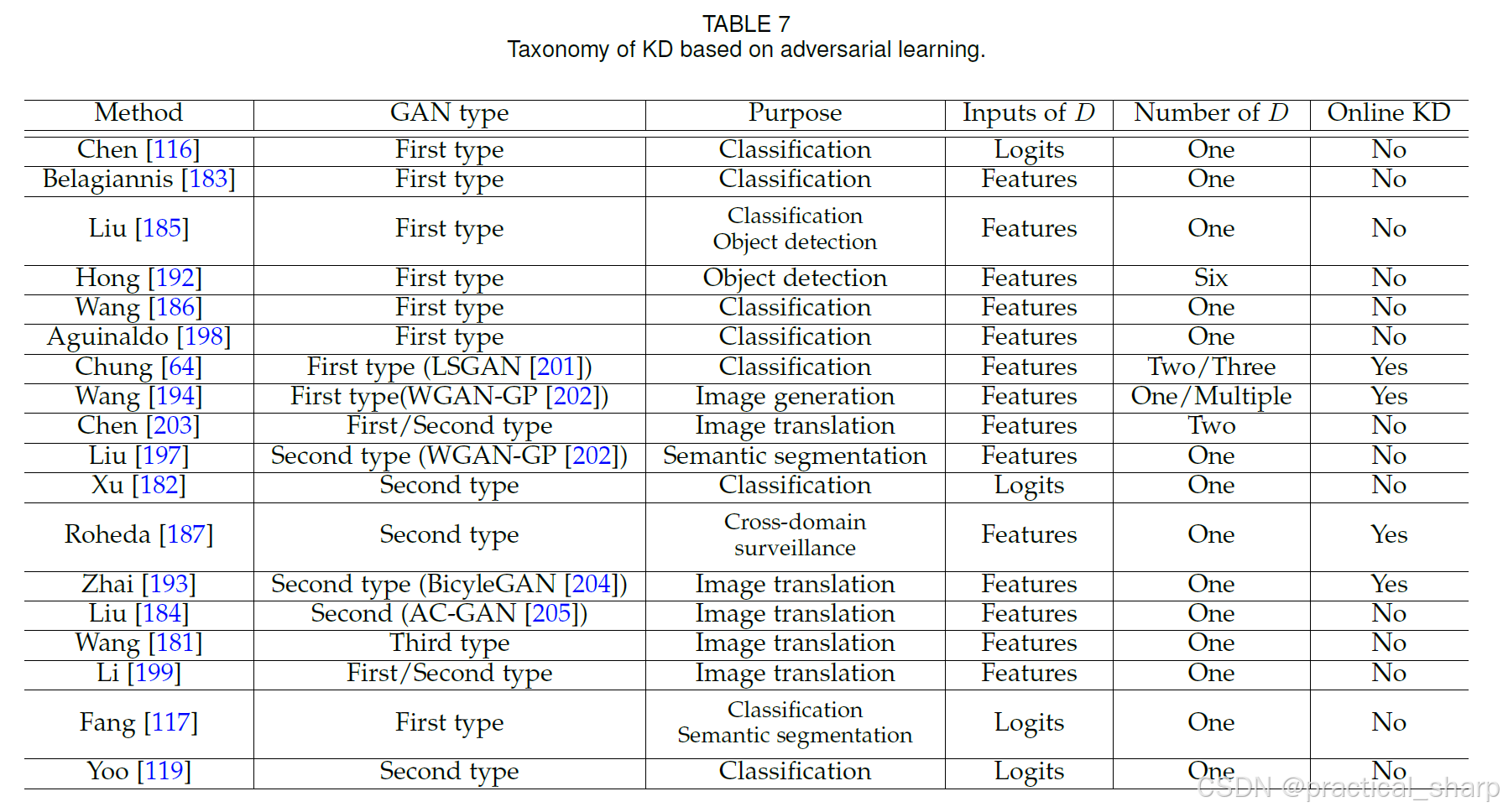
在表 7 中,我们针对实际应用、判别器D的输入特征、所用判别器的数量以及是否为单阶段(无需先对教师模型进行训练)等方面,对现有的基于生成对抗网络(GAN)的知识蒸馏方法进行了总结。总体而言,大多数方法聚焦于基于第一种生成对抗网络(常规生成对抗网络)[78] 的分类任务,并将特征作为判别器D的输入。此外,值得注意的是,大多数方法仅使用一个判别器来区分学生模型和教师模型。不过,诸如 [64]、[194] 和 [203] 等一些研究工作在其知识蒸馏框架中使用了多个判别器。可以看出,大多数方法遵循两阶段知识蒸馏范式,即先训练教师模型,然后再通过知识蒸馏损失将知识传递给学生模型。相比之下,[64, 187, 193, 194] 等研究也采用了在线(单阶段)知识蒸馏,无需预先训练好的教师网络。关于在线 / 两阶段蒸馏以及图像转换方面的知识蒸馏方法的更详细分析,分别在 6.1 节和 9.5 节中有所描述。
Open challenges:
基于生成对抗网络(GAN)的知识蒸馏(KD)面临的第一个挑战是训练的稳定性,特别是在教师模型和学生模型的容量差异较大时。其次,由于缺乏理论支持,仅使用逻辑值、仅使用特征或者两者都作为判别器的输入是否更好,这一点尚不明确。第三,使用多个判别器的优势不太清楚,而且在哪个位置的哪些特征适合用于训练生成对抗网络也有待进一步研究。
8.2 Distillation with graph representations
Overall insight: Graphs are the most typical locally connected structures that capture the features and hierarchical patterns for KD.
到目前为止,我们已经对使用逻辑值或特征信息的最常见的知识蒸馏(KD)方法进行了分类和分析。然而,知识蒸馏方面的一个关键问题在于数据。一般来说,训练深度神经网络(DNN)需要嵌入高维数据集以助力数据分析。因此,训练教师模型的最优目标不仅是将训练数据集转换到低维空间,还要分析数据内部的关系 [207, 208]。然而,大多数知识蒸馏方法都没有考虑这类关系。在此,我们基于 [209, 210] 介绍图嵌入和知识图谱基本概念的定义。我们会对现有的基于图的知识蒸馏方法进行分析,并讨论有关知识蒸馏的新视角。
8.2.1 Notation and definition


8.2.2 Graph-based distillation 与GNN密切相关,所涉及公式符号太多,建议读原文。
8.3 KD for semi-/self-supervised learning
Overall insight: KD with S-T learning aims to learn a rich representation by training a model with a large number of unlabeled datasets, and limited amount of labeled data.
半监督学习通常会处理因训练数据缺乏高质量标签而导致的过拟合问题。为此,大多数方法采用了师生(S-T)学习方式,这种方式假定模型兼具教师和学生的双重角色。学生模型旨在像以往一样学习给定的数据,而教师则从含噪数据中学习并生成预测目标,然后再通过一致性代价将这些预测目标传递给学生模型。在自监督学习中,学生模型自身会通过各种方法生成要学习的知识,然后再通过蒸馏损失将这些知识传递给自己。现在,我们对现有方法的技术细节进行详细分析。
8.3.1 Semi-supervised learning
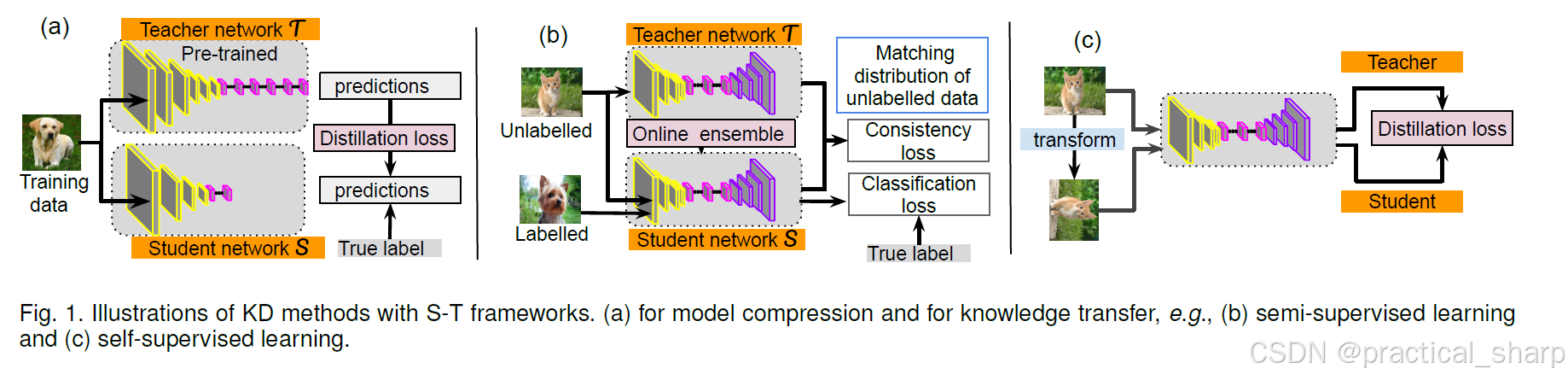
半监督学习的基准师生(S-T)框架由Laine等人 [226] 和Tarvainen等人 [2] 最初提出,如图 1(b)所示。学生模型和教师模型具有相同的结构,教师从噪声中学习,并通过一致性代价将知识传递给学生。有趣的是,在文献 [2] 中,教师的权重是利用学生权重的移动平均(EMA)来更新的。
受文献 [2] 的启发,Luo等人 [227]、Zhang等人 [228]、French等人 [229]、Choi等人 [230]、Cai等人 [231] 以及Xu等人 [232] 都采用了类似的框架,即教师的权重通过学生权重的指数移动平均(EMA)来更新。然而,Ke等人 [157] 提到,对于学生来说,使用耦合的指数移动平均(EMA)教师是不够的,因为随着训练的进行,耦合程度会增加。为了解决这个问题,教师被替换为另一个学生,并且在训练期间两个学生分别进行优化,同时为知识交换提供了一个稳定约束(类似于互学习 [34])。
Hailat等人 [233] 没有采用教师模型和学生模型之间相互独立的权重,而是运用了权重共享的方式,不过教师模型和学生模型的最后两个全连接层保持独立。教师模型扮演着教导学生、稳定整体模型以及尝试清理训练数据集中噪声标签的角色。
与之不同的是,Gong等人 [104] 和Xie等人 [21] 遵循了文献 [1] 所提出的常规蒸馏策略,即引入一个预训练的教师模型,利用无标签数据生成可供学习的知识,并将其作为特权知识,基于有标签数据来教导学生。然而,在学生学习过程中,Xie等人会向学生注入噪声(例如dropout),使其学得比教师更好。
Papernot等人 [38] 提议从多个教师(教师的集合)那里针对不相交的敏感数据子集(添加了噪声)进行知识蒸馏,并汇总教师们的知识以指导学生处理查询数据。
8.3.2 Self-supervised learning
针对自监督学习进行知识蒸馏的目的在于为学生模型自身保留已学习到的表征,如图 1(c)所示。使用伪标签是最常见的做法,[71, 234] 中就是如此操作的。具体来说,Lee等人 [71] 将自监督学习应用于知识蒸馏,这不仅确保了所传递的知识不会丢失,还能进一步提升性能。
与之不同的是,Noroozi等人 [234] 提议通过将(来自预训练教师模型的)已学习到的表征简化为无标签数据集上的伪标签(通过聚类的方式)来传递知识,然后利用这些伪标签去学习一个规模更小的学生网络。
另一种方法是基于数据增强(例如旋转、裁剪、颜色变换)[164, 166, 235],这在 6.2.3 节中已经提到过。与制造 “正”“负”(增强后的)样本不同,自监督学习方法 BYOL [178] 直接通过两个神经网络(分别称为在线网络和目标网络)引导表征,这两个网络相互作用、相互学习。这种思路在某种程度上与互学习 [34] 类似;不过,BYOL 训练其在线网络去预测目标网络对同一图像的另一个增强视图的表征。BYOL 的良好性能可能为通过表征引导而非使用负样本进行自监督学习的知识蒸馏指出了一个新方向。
8.3.3 Potentials and open challenges
基于对半监督学习和自监督学习中知识蒸馏(KD)方法的技术分析,可以明显看出在线蒸馏是主流方式。然而,这其中存在着几个挑战。
首先,正如 [157] 所指出的那样,使用指数移动平均(EMA)来更新教师模型的权重可能会导致知识学习达不到最优效果。其次,没有方法尝试去利用教师模型中丰富的特征知识。第三,与 6.2 节中所提出的方法相比,这些蒸馏方法中的数据增强方法效果欠佳,在 6.2 节中对抗学习的优势十分显著。第四,这些方法中知识的表征是有限的,且效果不佳。自监督学习方法 BYOL [178] 为表征引导开启了一扇大门,在未来的研究中,存在着进一步将这一思路与知识蒸馏相结合的潜力。此外,还有潜力去利用一种结构更优的数据表征方法,例如图神经网络(GNNs)中的相关方法。
鉴于这些挑战,半监督学习和自监督学习中知识蒸馏的未来发展方向可以从利用特征知识、采用更复杂的数据增强方法以及运用更稳健的表征方法中获取灵感。
8.4 Few-shot learning
Insight:Is it possible to learn an effective student model to classify unseen classes (query sets) by distilling knowledge from a teacher model with the support set?
与 5.2 节所讨论的侧重于用少量样本进行蒸馏以训练学生网络(且不学习对新类别进行泛化)的方法不同,本节着重分析利用知识蒸馏(KD)进行少样本学习的技术细节。少样本学习旨在对新数据进行分类,而这些新数据仅能从少量训练样本中获取相关信息。少样本学习本身是一个元学习问题,在给定一组训练任务的情况下,深度神经网络(DNN)要学习如何进行分类,并使用一组测试任务进行评估。在此设定中,目标是对每个类别有K个样本的N个类别进行区分(即所谓的N路K样本分类)。在这种情况下,这些训练样本被称为支持集。此外,还有同一类别中的其他样本,被称为查询集。少样本先验知识的学习方法通常基于三类:关于相似性的先验知识、关于学习过程的先验知识以及关于数据的先验知识。现在,我们来分析近期提出的用于少样本学习的知识蒸馏方法 [28, 46, 126, 236, 237]。
Prior knowledge about similarity:
Park等人 [28] 提出了基于距离和基于角度的知识蒸馏损失。其目的在于针对少样本学习,对教师模型和学生模型之间已学习表征的结构差异进行惩罚。
Prior knowledge about learning procedure:
[236, 237] 针对的是第二类先验知识,即学习过程方面的先验知识。具体而言,Flennerhag等人 [236] 专注于在学习过程中传递知识,即将先前任务中的信息进行蒸馏,以促进对新任务的学习。然而,Jin等人 [237] 致力于解决学习元学习器的问题,该元学习器能够自动学习应将哪些知识从源网络传递到目标网络的何处。
Prior knowledge about data:
Dvornik等人 [46] 和Liu等人 [126] 针对的是第三类先验知识,即数据方差。具体来说,在文献 [46] 中,详细阐述了由多个教师网络组成的集合,以利用分类器的方差,并鼓励它们相互协作,同时提升预测的多样性。然而,在文献 [126] 中,目标是通过为微调集中的训练样本生成伪标签,来保留教师模型在预训练阶段所学习到的知识(例如类内关系)。
8.4.1 What’s challenging?
基于我们的分析,现有技术实际上暴露出了一些关键挑战。首先,基于知识蒸馏(KD)的少样本学习的整体性能是令人信服的,但元学习的能力在某种程度上被削弱或忽视了。其次,从多源网络传递知识是一种潜在的途径,但识别要学习什么以及向何处传递在很大程度上依赖于元学习器,而且选择向哪个教师模型学习在计算方面较为复杂。第三,所有方法都侧重于特定任务的知识蒸馏,但随着领域的变化,性能会有所下降。因此,未来的工作可能会更侧重于解决这些问题。
8.5 Incremental Learning
Overall insight: KD for incremental learning mainly deals with two challenges: maintaining the performance on old classes, and balancing between old and new classes.
增量学习旨在持续学习新知识以更新模型的知识,同时保留已有知识 [238]。人们已经做了许多尝试 [102, 169, 193, 238, 239, 240, 241],利用知识蒸馏(KD)来应对保留旧知识这一挑战。根据用于蒸馏的教师网络的数量,这些方法可分为两类:从单一教师进行蒸馏以及从多个教师进行蒸馏。
8.5.1 Distillation from a single teacher
Shmelkov等人 [241]、Wu等人 [238]、Michieli等人 [239] 以及Hou等人 [169] 专注于通过从针对旧类别数据进行预训练的教师模型中蒸馏知识(逻辑值信息)来学习面向新类别的学生网络。尽管这些方法在任务和蒸馏过程方面有所不同,但它们都遵循类似的师生(S-T)结构。通常,预训练模型会被当作教师模型,并且会采用相同的网络或者不同的网络来适应新类别。Michieli等人利用了中间特征表示,并将其传递给学生模型。
8.5.2 Distillation from multiple teachers
Castro等人 [240]、Zhou等人 [102] 以及Ammar等人 [242] 专注于利用多个教师模型学习增量模型。具体而言,Castro等人在教师模型和学生模型之间共享相同的特征提取器。教师模型涵盖旧类别,其逻辑值(logits)用于蒸馏和分类。
有趣的是,Zhou等人提出了一种多模型、多层次的知识蒸馏(KD)策略,在该策略中,利用之前所有的模型快照来学习最后一个模型(即学生模型)。这种方法与 6.2 节中提到的 “born-again” 知识蒸馏方法类似,也就是利用之前所有步骤中汇总的知识来更新最后一步的学生模型。不过,汇总的知识同样依赖于中间特征表示。
Ammar等人开发了一个跨领域增量强化学习(RL)框架,在该框架中,可迁移的知识被共享,并被投射到特定任务的学生同类模型所处的不同任务领域中。
8.5.3 Open challenges
现有的方法依赖于多步训练(离线方式)。然而,如果能够利用在线(单步)蒸馏方法来提高学习效率和性能,那将会更有意义。而且,现有的方法需要访问之前的数据,以避免更新步骤之间出现混淆。不过,无数据蒸馏方法的可能性依然有待探索。此外,现有的方法仅仅处理同一数据域内新类别的增量学习问题,但如果能将跨领域蒸馏方法应用于这个方向,那将会很有成效。
8.6 Reinforcement learning
Overall insight: KD in reinforcement learning is to encourage polices (such as students) in the ensemble to learn from the best policies (such as teachers), thus enabling rapid improvement and continuous optimization. 强化学习中的知识蒸馏(KD)旨在鼓励集合中的策略(比如学生策略)向最佳策略(比如教师策略)学习,从而实现快速改进和持续优化。
强化学习(RL)是一个学习问题,它训练一个策略以与环境进行交互,从而获得最大奖励。为了使用最佳策略来引导其他策略,知识蒸馏(KD)已被应用于 [18, 107, 236, 243, 244, 245, 246, 247] 这些研究中。基于这些方法的特点,我们将它们分为三类,并进行详细分析。我们假定读者熟悉强化学习的基础知识,在此省略深度 Q 网络和异步优势 actor-critic(A3C)的定义。
8.6.1 Collaborative distillation
Xue等人 [246]、Hong等人 [245] 以及Lin等人 [247] 专注于协同蒸馏,这与互学习 [34] 类似。在Xue等人的研究中,智能体基于强化规则相互传授知识,且这种传授发生在智能体(学生智能体和教师智能体)的价值函数之间。需要注意的是,知识是由一组学生智能体定期提供的,并进行汇总以提高学习速度和稳定性,这一点与Hong等人 [245] 的做法相同。不过,Hong等人 [245] 会定期将表现最佳的策略蒸馏给集合中的其他智能体。Lin等人则着重强调异构学习智能体之间的协同学习,并将知识融入在线训练中。
8.6.2 Model compression with RL-based distillation
Ashok等人 [243] 通过强化学习来解决模型压缩的问题。该方法以一个规模较大的教师网络为基础,输出一个由此派生的压缩后的学生网络。具体而言,采用了两个循环策略网络,一个用于大刀阔斧地移除教师网络中的层,另一个用于谨慎地减小剩余各层的规模。通过一个奖励来评估所学习到的学生网络,该奖励是基于教师网络的准确率和压缩程度得出的一个分数。
8.6.3 Random network distillation
Burda等人 [244] 聚焦于一个不同的视角,即预测问题是随机生成的。该方法涉及两个网络:目标(学生)网络,它是固定的且随机初始化的;以及一个预测器(教师)网络,它基于智能体收集的数据进行训练。借助从预测器中蒸馏出的知识,目标网络往往会有更低的预测误差。
Rusu等人 [107] 同样对目标网络采用随机初始化的方式。不过,他们更侧重于在线学习动作策略,这些策略可以是单任务的,也可以是多任务的。
8.6.4 Potentials of RL-based KD
我们已经详细分析了现有的基于强化学习(RL)的知识蒸馏(KD)方法。尤其值得注意的是,通过基于强化学习的知识蒸馏来进行模型压缩颇具前景,这得益于它的诸多突出优势。
首先,基于强化学习的知识蒸馏能更好地解决网络模型的可扩展性问题。这一点与神经架构搜索(NAS)类似。此外,基于强化学习的知识蒸馏中的奖励函数能更好地平衡准确率与模型规模之间的权衡关系。而且,还有可能将知识从较小的模型传递到较大的模型,这相对于其他知识蒸馏方法来说是一个显著优势。
Section 9 Applications for Visual Intelligence
9.1 Semantic and motion segmentation
Insight: Semantic segmentation is a structured problem, and structure information (e.g., spatial context structures) needs to be taken into account when distilling knowledge for semantic segmentation networks. 语义分割是一个结构化问题,在对语义分割网络进行知识蒸馏时,需要考虑结构信息(例如空间上下文结构)。
语义分割是一种特殊的分类问题,它以逐像素的方式预测类别标签。由于诸如全卷积网络 [248] 这类现有的最先进(SOTA)方法存在模型规模大、计算成本高的问题,人们已经提出了一些方法 [117, 152, 159, 197, 239, 249, 250, 251, 252],旨在通过知识蒸馏(KD)来训练轻量化网络。
尽管这些方法在学习方式上有所不同,但它们大多共享相同的蒸馏框架。特别是,Xie等人 [252]、Shan等人 [249] 以及Michieli等人 [239] 侧重于逐像素、基于特征的蒸馏方法。此外,Liu等人 [197] 和He等人 [250] 都利用了基于亲和性且借助中间特征的蒸馏策略。Liu等人还通过对抗学习采用了逐像素和整体的知识蒸馏损失。
与之不同的是,Dou等人 [152] 侧重于非配对多模态分割,并通过互学习 [34] 提出了一种在线知识蒸馏方法。Chen等人 [251] 提出了一种目标引导的知识蒸馏方法,通过训练学生去模仿用真实图像训练的教师,来学习真实图像的风格。Mullapudi等人 [159] 通过在线蒸馏训练了一个紧凑的视频分割模型,在该模型中,教师的输出被用作学习目标,以调整学生模型并选择下一帧进行监督。
9.2 KD for visual detection and tracking
Insight: Challenges such as regression, region proposals, and less voluminous labels must be considered when distilling visual detectors.
视觉检测是计算机视觉中一项至关重要的高级任务。速度和精度是视觉检测器的两个关键因素。知识蒸馏(KD)是实现加速及轻量化网络模型的一个潜在选择。然而,将蒸馏方法应用于检测任务要比应用于分类任务更具挑战性。
首先,压缩后检测性能会严重下降。其次,检测类别并非同等重要,在进行蒸馏时必须予以特殊考虑。第三,对于经过蒸馏的检测器,必须考虑领域和数据的泛化问题。
为克服这些挑战,人们已经提出了一些令人印象深刻的知识蒸馏方法 [65, 175, 192, 237, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, 264],用于压缩视觉检测网络。我们会根据这些方法的特点(例如行人检测方面的特点)对它们进行分类。
9.2.1 Generic object detection
[65, 175, 192, 253, 254, 256, 258, 265, 266] 这些研究旨在利用知识蒸馏(KD)学习轻量化的目标检测器。在这些工作中,Chen等人 [254] 和Hao等人 [253] 着重强调遵循通用的知识蒸馏框架(基于预训练的教师模型)来学习一个类别增量式的学生检测器。不过,它们采用了新颖的目标检测损失作为学习新类别的强大推动力。这些损失涉及分类结果、定位结果、检测到的感兴趣区域以及所有中间区域提议。
此外,Chen等人 [175] 通过从教师模型的中间层、逻辑值以及回归器中蒸馏知识来学习学生检测器,这与 [65] 不同,在 [65] 中,仅基于细粒度的模仿掩码利用教师模型的中间层来识别信息量丰富的位置。Jin等人 [258]、Tang等人 [256] 以及Hong等人 [192] 利用多个中间层作为有用知识。Jin等人设计了一种考虑不确定性的蒸馏损失,以便从教师网络中学习多尺度特征。然而,Hong等人和Tang等人分别基于通过对抗学习的单阶段知识蒸馏(在线)以及半监督学习来开展相关工作。
与之不同的是,Liu等人 [266] 将单一的师生(S-T)学习和学生间的互学习相结合,用于学习轻量化的跟踪网络。
9.2.2 Pedestrian detection
虽然行人检测基于通用的目标检测,但在极端光照条件下行人的各种尺寸和宽高比是面临的挑战。为了学习一个有效的轻量化检测器,Chen等人 [255] 建议通过多重中间监督来使用统一的分层知识,在这种方式下,不仅特征金字塔(从低级特征到高级特征)和区域特征会被蒸馏,逻辑值信息也会被蒸馏。
Kruthiventi等人 [261] 通过从多模态教师网络中提取隐含知识(包括 RGB 特征以及类似热成像的提示特征),在具有挑战性的光照条件下学习了一个有效的学生检测器。
9.2.3 Face detection
Ge等人 [262] 和Karlekar等人 [267] 通过从初始用于识别高分辨率人脸的教师模型中进行选择性知识蒸馏(针对最后一个隐藏层),对人脸检测器进行压缩,使其能够识别低分辨率人脸。
与之不同的是,Jin等人 [237]、Luo等人 [263] 以及Feng等人 [264] 使用的是单一类型的图像。Jin等人专注于通过利用来自教师模型分类图和真实值回归图的监督信号来压缩人脸检测器。他们发现,学习较大模型的分类图要比学习较小模型的分类图效果更好。
Feng等人提出了一种三元组知识蒸馏方法,用于将知识从教师模型传递到学生模型,该方法使用了由锚图像、正样本图像和负样本图像组成的三元组样本。三元组损失的目的在于最小化锚图像与正样本图像之间的特征相似度,同时最大化锚图像与负样本图像之间的特征相似度。
Luo等人强调了教师模型较高隐藏层中神经元的重要性,并应用了一种神经元选择方法来挑选对教导学生至关重要的神经元。
Dong等人 [268] 专注于教师模型与学生模型之间的相互作用。两名学生学习生成伪人脸关键点标签,然后由教师对这些标签进行筛选并选择出合格的知识。
9.2.4 Vehicle detection and driving learning
Lee等人 [259]、Saputra等人 [257] 以及Xu等人 [182] 更侧重于自动驾驶的检测任务。
尤其值得一提的是,Lee等人专注于将基于级联卷积神经网络(教师模型)的汽车制造商分类系统压缩为单一的卷积神经网络结构(学生模型)。所提出的知识蒸馏方法将特征图用作传递媒介,并且教师模型和学生模型是并行训练的(在线蒸馏)。
尽管检测任务有所不同,Xu等人通过逐步将教师网络中从简单任务到困难任务的特征图切碎,构建了一个二值权重的 Yolo 车辆检测器。
Zhao等人 [269] 利用了一种师生(S-T)框架,以鼓励学生学习教师基于语义分割的充分且不变的表征知识,用于自动驾驶。
9.2.5 Pose detection
对人体姿态检测器进行知识蒸馏存在若干挑战。
首先,轻量化检测器必须能够处理任意的人物图像 / 视频,以确定关节位置,且要适应不受约束的人物外观。其次,检测器在视角条件和背景噪声环境下必须具备较强的鲁棒性。第三,检测器应当具备快速的推理速度,并且要节省内存。
为此,[145, 270, 271, 272, 273, 274, 275] 提出了各种各样的知识蒸馏方法。Zhang等人 [270] 通过从预训练的教师模型中蒸馏关节置信度图实现了有效的知识转移,而Huang等人 [272] 利用预训练教师的热图和位置图作为要蒸馏的知识。
此外,Xu等人 [273]、Thoker等人 [145] 以及Martinez等人 [271] 侧重于多人姿态估计。Thoker等人解决了跨模态蒸馏问题,在该问题中,初始化了一个基于由一名教师监督的两名学生互学习 [34] 的新颖框架。Xu等人 [273] 在标准的师生(S-T)框架下,通过一个判别器学习整体知识,即特征、逻辑值以及结构化信息。Martinez等人 [271] 训练学生去模仿预训练教师利用深度图像生成的置信度图、特征图以及中间阶段预测结果。Wang等人 [273] 通过仅使用二维地标标注,从基于运动的非刚性结构中蒸馏知识,训练了一个三维姿态估计网络。
与之不同的是,Nie等人 [275] 引入了一种在线知识蒸馏方法,该方法以一次性学习的方式,利用前一帧的时间线索对视频中的姿态核进行蒸馏。
9.3 Domain adaptation
Insight: Is it possible to distill knowledge of a teacher in one domain to a student in another domain?
领域自适应(DA)旨在解决借助不同但相关的源领域来学习目标领域的问题 [276]。自从Lopez等人 [277] 和Gupta等人 [143] 最初提出在来自不同模态的图像之间传递知识的技术(被称为广义蒸馏)以来,人们很自然地会问,这种新技术能否用于解决领域自适应的问题。
领域自适应的挑战通常在于将知识从带有标签的源模型转移到包含无标签数据的目标领域。为解决这一问题,最近已经提出了几种基于师生(S-T)框架的知识蒸馏(KD)方法 [230, 231, 232, 276, 278, 279, 280, 281, 282]。尽管这些方法侧重于不同的任务,但从技术层面来讲,它们可被分为两类:通过知识蒸馏实现的无监督领域自适应和半监督领域自适应。
9.3.1 Semi-supervised DA
French等人 [229]、Choi等人 [230]、Cai等人 [231]、Xu等人 [232] 以及Cho等人 [283] 针对语义分割和目标检测提出了类似的师生(S-T)框架。这些框架是 “均值教师”(Mean-Teacher)[2] 方法的改进版本,“均值教师” 方法基于学生网络的自集成(教师模型和学生模型具有相同的结构)。需要注意的是,在这些方法中,教师模型的权重是学生模型权重的指数移动平均值(EMAs)。
与之不同的是,Choi等人添加了一个目标引导生成器来生成增强图像,而非像 [229, 231, 232] 中那样进行随机增强。蔡(Cai)等人还利用了来自教师模型的特征知识,并应用了区域级和图内一致性损失来替代均方误差损失。
与之形成对比的是,Ao等人 [276] 提出了一种广义蒸馏领域自适应(DA)方法,该方法将广义蒸馏信息 [277] 应用于多个教师模型以生成软标签,然后利用这些软标签来监督学生模型(这个框架与 4.2 节中提到的来自多个教师的在线知识蒸馏类似)。Cho等人 [283] 提出了一个师生学习框架,在该框架中,基于从一个更大的立体匹配网络(教师)获得的辅助信息(多个深度预测的集合)的监督,对一个较小的深度预测网络进行训练。
9.3.2 Unsupervised DA
一些如 [278, 280] 中提到的方法,依据对抗学习 [78] 和图像转换 [123, 124, 200],将知识从源域蒸馏到目标域。从技术角度来讲,源域中的图像会被转换为目标域中的图像,以此作为数据增强的方式,并且采用跨域一致性损失来促使教师模型和学生模型做出一致的预测。
Tsai等人 [281] 以及Deng等人 [282] 着重于对齐教师模型和学生模型之间的特征相似度,而Meng等人 [279] 则侧重于对齐 Softmax 输出结果,二者有所不同。
9.4 Depth and scene flow estimation
Insight: The challenges for distilling depth and flow estimation tasks come with transferring the knowledge of data and labels.
深度估计和光流估计属于低级视觉任务,旨在对场景的三维结构和运动进行估计。这其中存在若干挑战。
首先,与其他任务(例如语义分割)不同的是,深度估计和光流估计并没有类别标签。因此,直接应用现有的知识蒸馏技术可能效果不佳。而且,学习一个轻量化的学生模型通常需要大量的标注数据,以实现强大的泛化能力。然而,获取这些数据的成本非常高。
为应对这些挑战,Guo等人 [176]、Pilzer等人 [284] 以及Tosi等人 [285] 提出了基于蒸馏的方法来学习单目深度估计。这些方法侧重于解决第二个挑战,即数据蒸馏问题。
具体而言,Pilzer等人 [284] 提出了一种无监督蒸馏方法,通过图像转换框架 [123, 200] 将左图像转换为右图像。左右图像之间的不一致性被用于改进深度估计,最终通过知识蒸馏来改进学生网络。与之不同的是,Guo等人和Tosi等人侧重于跨领域知识蒸馏,其目的是对从立体网络(教师网络)获得的代理标签进行蒸馏,以学习学生深度估计网络。Choi等人 [283] 通过数据集成策略,从立体教师网络中蒸馏深度预测知识,学习了一个用于单目深度推断的学生网络。
Liu等人 [286] 和Aleotti等人 [287] 提出了用于场景流估计的数据蒸馏方法。Liu等人从带有未标注数据的教师网络中蒸馏出可靠的预测结果,并将这些预测结果(针对非遮挡像素)作为标注来引导学生网络学习光流。他们提议利用专门用于立体视觉的教师网络所学习到的知识来蒸馏代理标注,这与 [176, 285] 中深度估计的知识蒸馏方法类似。Tosi等人 [288] 基于代理语义标签的蒸馏以及对光信息的语义感知自蒸馏,学习了一个紧凑的网络,用于预测包括深度、光流以及运动分割在内的整体场景理解任务。
9.5 Image translation
Insight: Distilling GAN frameworks for image translation has to consider three factors: large number of parameters of the generators, no ground truth labels for training data, and complex framework (both generator and discriminator).
在多项研究工作中,人们尝试利用知识蒸馏(KD)对用于图像转换的生成对抗网络(GANs)进行压缩。
Aguinaldo等人 [198] 聚焦于无条件生成对抗网络,提出通过使用均方误差(MSE)从规模更大的教师生成器所生成的图像中蒸馏知识,来学习一个规模更小的学生生成器。不过,该研究并未探究教师判别器中所包含的知识。
与之不同的是,Chen等人 [203] 和Li等人 [199] 侧重于条件生成对抗网络,并利用了来自教师判别器的知识。具体而言,Chen等人引入了一个学生判别器,用于测量真实图像以及学生生成器和教师生成器所生成图像之间的距离。然后,在教师生成对抗网络的监督下对学生生成对抗网络进行训练。尤其值得一提的是,Li等人 [199] 采用教师的判别器作为学生判别器,并通过使用神经架构搜索(NAS),对判别器以及压缩后的生成器(以显著更低的计算成本和更少的参数自动找到的生成器)一起进行微调。
与之形成对比的是,Wang等人 [289] 侧重于通过(编码器与其解码器之间的)协同蒸馏对基于编码器 - 解码器的神经风格迁移网络进行压缩,在这种情况下,限制学生去学习教师输出的线性嵌入。
9.6 KD for Video understanding
9.6.1 Video classification and recognition
Bhardwaj等人 [290] 和Wang等人 [291] 将通用的师生(S-T)学习框架应用于视频分类。学生网络在仅处理视频的少数几帧的情况下进行训练,并生成与教师网络相似的表征。
Gan等人 [292] 侧重于通过使用网络视频和图像进行动作识别及事件检测方面的视频概念学习。从教师网络(引导网络)中学习到的知识被用于过滤掉有噪声的图像,然后利用这些经过筛选的图像对教师网络进行微调,从而获得学生网络(超越网络)。
Gan等人 [293] 探索将几何知识作为一种新型实用的辅助知识,用于视频表征的自监督学习。
Fu等人 [294] 着重通过利用空间和时间知识来进行视频注意力预测。
Farhadi等人 [295] 将教师模型在所选视频帧上的时间知识蒸馏到学生模型中。
9.6.2 Video captioning
[296, 297] 挖掘了基于图的师生(S-T)学习在图像字幕方面的潜力。
具体来说,Zhang等人 [296] 借助时空图,利用对象级信息(教师端的信息)来学习场景特征表示(学生端的信息)。
Pan等人 [297] 强调了连接视频中所有对象的关系图的重要性,并通过教师推荐学习的方式,促使字幕模型学习丰富的语言表达。
Section 10 Discussions
10.1 Are bigger models better teachers?
知识蒸馏(KD)背后早期的假设和理念是,来自经过训练的教师模型的软标签(概率)相较于真实标签,能更多地反映数据的分布情况 [1]。如果这一假设成立,那么可以预期,随着教师模型变得更加鲁棒,教师所提供的知识(软标签)会更可靠,也能更好地捕捉类别分布。也就是说,一个更鲁棒的教师会为学生提供建设性的知识及监督。
因此,学习一个更准确的学生模型的直观方法就是采用一个规模更大且更鲁棒的教师模型。然而,依据 [16] 中的实验结果发现,规模更大且更鲁棒的模型并非总能成为更好的教师。随着教师模型能力的提升,学生模型的准确率会在一定程度上提高,随后便开始下降。基于 [16, 35],我们总结了知识蒸馏缺乏理论支持背后的两个关键原因。
原因1
学生能够追随教师,但却无法从教师那里吸收有用的知识。这表明知识蒸馏损失与准确率评估方法之间存在不匹配的情况。正如 [35] 中所指出的那样,所采用的优化方法可能会对蒸馏风险产生重大影响。因此,优化方法对于向学生进行有效的知识蒸馏而言可能至关重要。
原因2
另一个原因源于教师与学生之间模型容量差距较大,导致学生无法跟上教师的情况。[1, 53] 中指出,师生相似度与学生模仿教师的能力强弱高度相关。如果学生与教师相似,那么它就会产生与教师相似的输出结果。
中间特征表示也是可用于训练学生模型的有效知识 [52, 54]。基于特征进行知识蒸馏的常见做法是,将特征转换为一种学生模型易于学习的表示形式。在这种情况下,规模更大的模型就是更好的教师模型吗?正如 [52] 中所指出的,基于特征的知识蒸馏效果优于软标签的蒸馏,并且层次更深的学生模型性能要优于较浅的学生模型。此外,随着层数(特征表示的数量)增加,学生模型的性能也会提高 [54]。然而,当学生模型固定时,规模更大的教师模型并不总能教出更好的学生模型。当教师模型与学生模型的相似度相对较高时,学生模型往往能取得较好的结果。
10.2 Is a pretrained teacher important?
虽然大多数研究工作侧重于基于预训练的教师模型来学习一个规模更小的学生模型,但知识蒸馏并非总是高效且有效的。当教师模型与学生模型之间的模型容量差距较大时,学生模型很难跟上教师模型的节奏,从而导致优化难度增加。
那么,对于学习一个性能合理的紧凑型学生模型来说,预训练的教师模型是否重要呢?[34, 40] 提出从学生同伴那里进行学习,这些学生同伴各自具有相同的模型复杂度。这种蒸馏方法的最大优势在于效率,因为无需对高容量的教师模型进行预训练。学生同伴之间并非相互教导,而是学会彼此协作以获得最优的学习解决方案。令人惊讶的是,在没有教师模型的情况下进行学习甚至能够提升性能。
关于为何无教师模型的学习效果更好这一问题,已在 [2] 中有所研究。他们的研究结果表明,紧凑型学生模型出现过拟合的可能性更低。此外,[16] 指出,在 ImageNet [51] 上提前停止训练能够取得更好的性能。如 [34] 所述,学生模型的集合汇聚了它们的集体预测结果,从而有助于收敛到一个更稳健的最小值。
10.3 Is born-again self-distillation better?
重生网络(Born-again network)[30] 是最初的自蒸馏方法,在该方法中,学生模型按顺序依次训练,后一阶段由前一阶段进行监督。在整个过程结束时,将所有阶段的学生模型组合在一起以获得额外的收益。那么,这种多阶段的自蒸馏效果更好吗?[16] 发现网络架构在很大程度上决定了多阶段知识蒸馏的成功与否。尽管汇聚所有阶段的学生模型的集合性能优于从零开始训练的单个模型,但该集合的性能却不如同等数量从零开始训练的模型的集合性能。
相反,近期的一些研究工作 [163, 164, 168] 将关注点从顺序式自蒸馏(多阶段)转移到了单阶段(在线)方式。学生模型无需借助教师模型以及大量计算,便可自行进行知识蒸馏。这些方法展现出了更高的效率、更低的计算成本以及更高的准确率。[163, 168] 指出了产生这种更好性能的原因。他们发现,在线自蒸馏能够帮助学生模型收敛到平坦最小值。而且,自蒸馏可防止学生模型出现 “梯度消失” 问题。最后,自蒸馏有助于提取更具判别性的特征。总之,在线自蒸馏相较于顺序式蒸馏方法展现出了显著优势,并且更具通用性。
10.4 Single teacher vs multiple teachers
值得注意的是,近期的蒸馏方法开始挖掘向多位教师学习的潜力。向多位教师学习真的比向单一教师学习更好吗?为回答这一问题,[37] 凭直觉发现,学生能够融合来自多位教师的不同预测,从而建立起自身对知识的全面理解。其背后的原理在于,通过整合来自教师集合的知识,教师之间的相对相似关系得以维持。这为学生提供了更完整的隐含知识。**与互学习 [34, 40] 类似,教师集合将各位教师的个体预测(知识)汇聚到一起,进而收敛到更稳健的最小值。**最后,向多位教师学习能够缓解诸如梯度消失问题之类的训练困难。
10.5 Is data-free distillation effective enough?
在缺乏训练数据的情况下,已经有人提出了一些新颖的方法 [112, 116, 118, 119] 来获得合理的结果。但对于为何这些方法足以稳健地训练出一个轻便型学生模型,目前尚未有相应的理论解释。这些方法仅侧重于分类任务,而且它们的泛化能力仍然较低。大多数相关研究工作会利用生成器通过对抗学习 [123, 132] 从噪声中生成 “潜在” 图像,但这类方法相对较难训练,并且计算成本高昂。
10.6 Logits vs features
现有知识蒸馏(KD)方法中所定义的知识来自三个方面:logits、features(中间层)以及二者兼具。然而,目前仍不清楚这三者之中哪一个能更好地代表知识。
虽然诸如 [52, 53, 54, 55, 61] 等研究工作侧重于对特征表示进行更好的阐释,并声称特征可能包含更丰富的信息;但其他一些研究工作 [1, 15, 34, 115] 提到,软化标签(逻辑值)能够通过类别分布来表示每个样本,而且学生模型可以轻松学习类内的变化情况。
不过,值得注意的是,通过逻辑值进行知识蒸馏存在明显的缺陷。首先,其有效性受限于 Softmax 损失函数,并且依赖于类别数量(无法应用于低级视觉任务)。其次,当教师模型与学生模型之间的容量差距较大时,学生模型很难跟上教师模型的类别概率 [16]。
此外,正如 [61] 中所研究的那样,语义相似的输入往往会在教师网络中引发相似的激活模式,这表明来自中间特征的保持相似性的知识不仅体现了表示空间,还体现了对象类别的激活情况(类似于类别分布)。
因此,我们可以清楚地看到,特征相较于逻辑值能提供更丰富的知识,并且对于无类别标签的问题具有更好的泛化能力。
10.7 Interpretability of KD
在第 3 节中,我们基于信息最大化理论对知识蒸馏(KD)进行了理论分析。人们普遍认为,教师模型的隐含知识提供了关于类别相似性的特权信息,以促进学生模型的学习 [1, 4]。然而,知识蒸馏为何起作用也是一个重要问题。
有一些方法从标签平滑 [172]、视觉概念 [177]、类别相似性 [1] 等角度来探究知识蒸馏的原理。具体而言,[172] 发现知识蒸馏是一种习得的标签平滑正则化(LSR),并且标签平滑正则化是一种特定的知识蒸馏方式。即便教师模型训练不佳,也能提升学生模型的性能,而且较弱的学生模型也能对教师模型有所改善。不过,[172] 中的研究结果仅侧重于与分类相关的任务,这些有趣的结果并不适用于无标签的任务 [199, 203]。
与之相反,[177] 宣称知识蒸馏能使深度神经网络(DNN)学习更多与任务相关的视觉概念,并舍弃与任务无关的概念,从而学习到具有判别性的特征。从总体上看,[177] 中对视觉概念的量化为知识蒸馏的成功提供了一种更直观的解释。然而,在这个方向上迫切需要开展更深入的研究。
10.8 Network architecture vs effectiveness of KD.
已有研究表明,蒸馏位置对知识蒸馏(KD)的有效性有着重大影响 [16, 53]。大多数方法通过为教师模型和学生模型部署相同的网络来证明这一点。然而,许多方法在差异很大的教师模型和学生模型架构之间无法实现知识转移。
近期,[10] 发现 [11, 52, 57] 中的方法即便在教师模型和学生模型架构非常相似的情况下,效果也不佳。[172] 也报告了一个有趣的发现,即训练不佳的教师模型也能够提升学生模型的性能。因此,挖掘网络架构如何影响知识蒸馏的有效性以及当学生模型和教师模型的网络架构不同时知识蒸馏为何失效,是十分必要的。
Section 11 New Outlooks and Perspectives
在本节中,我们提出一些想法,并探讨知识蒸馏的未来发展方向。我们将最新的深度学习方法(例如,神经架构搜索(NAS)、图神经网络(GNN))、新颖的非欧几里得距离(例如,超球面hypersphere)、更优的特征表示方法以及潜在的视觉应用,如 360 度全景视觉 [298] 和基于事件的视觉 [158] 等纳入考虑范围。
11.1 Potential of NAS
近年来,神经架构搜索(NAS)已成为深度学习领域的热门话题。NAS 具备自动化设计神经网络的潜力,因此,它能够高效地搜索出更紧凑的学生模型。通过这种方式,NAS 可与知识蒸馏(KD)相结合用于模型压缩。近期,这一点在生成对抗网络(GAN)压缩方面已得到验证 [199, 299]。事实证明,它能有效地从教师模型中找到计算成本更低且参数更少的高效学生模型,结果显示 NAS 提高了压缩比并加快了知识蒸馏的进程。[243] 采取了类似的方法,基于强化学习(RL)学习去除教师网络的某些层。
因此,我们提出,结合强化学习的 NAS 可成为知识蒸馏用于模型压缩的一个良好发展方向。这或许能显著降低现有方法的复杂性,并提高其学习效率,因为在现有方法中,学生模型是基于教师模型手动设计的。
11.2 Potential of GNN
尽管图神经网络(GNN)在师生(S-T)框架下的知识蒸馏学习方面带来了进展,但仍存在一些挑战。这是因为大多数方法依赖于寻找可应用基于图的算法的结构化数据。[18] 将实例特征和实例关系视作实例图,[215] 为多任务知识蒸馏构建了输入图表示。然而,在知识蒸馏中,除了结构化知识(例如训练数据、逻辑值、中间特征以及教师的输出)之外,还存在非结构化知识,因此有必要构建一个灵活的知识图谱来应对非结构化蒸馏过程。
11.3 Non-Euclidean distillation measure
现有的知识蒸馏(KD)损失大多依赖于欧几里得损失(例如,L1 范数),并且都有各自的局限性。[300] 表明,使用欧几里得距离进行正则化的算法(例如均方误差损失)很容易被随机特征干扰。当教师模型与学生模型之间的模型容量差距较大时,就会出现这种困难。此外,L2 正则化对较小权重的惩罚力度不够。
受近期一项关于生成对抗网络(GAN)训练的研究 [301] 的启发,我们提出,利用非欧几里得空间(例如超球面)中数据的高阶统计信息是很有用的。这是因为非欧几里得距离所引发的几何约束可能会使训练更加稳定,从而提高知识蒸馏的效率。
11.4 Better feature representations
现有的侧重于多教师知识蒸馏(KD)的方法在处理跨领域问题或其他无真实标签的问题方面展现出了潜力。然而,特征表示的融合 [48, 64, 111] 在某些方面仍然具有挑战性。
一个关键挑战在于融合特征表示,并通过稳健的门控机制对它们进行平衡。手动为每个组件分配权重可能会损害各个特征表示的多样性和灵活性,从而削弱集成知识的有效性。
一种可能的解决方案是采用注意力门机制,正如一些检测任务 [302, 303] 中所展示的那样。这种方法的目的是突出重要的特征维度,并对特征响应进行修剪,只保留与特定任务相关的激活信息。
另一种方法的灵感来源于长短时记忆网络(LSTM)[304, 305] 中所使用的门控机制。也就是说,知识蒸馏中的这个门单元经过精心设计,能够记住不同图像区域的特征,并根据它们对任务(例如分类)的重要性权重,整体控制每个区域特征的传递。
11.5 A more constructive theoretical analysis
尽管知识蒸馏(KD)在许多任务中都展现出了令人瞩目的性能提升,但其背后的原理仍不明确。近期,[16] 利用线性模型对传统的知识蒸馏 [1] 进行了解释,[8, 9, 10] 则侧重于解释基于特征的知识蒸馏。Mobahi等人 [163] 为自蒸馏提供了理论分析。然而,无数据知识蒸馏以及多教师知识蒸馏背后的机制仍然未知。因此,应当进一步开展理论研究,对这些方法的原理进行阐释。
11.6 Potentials for special vision problems
虽然现有的知识蒸馏(KD)技术大多是基于视觉问题(例如分类)开发的,但它们很少利用一些特殊的视觉领域,如 360 度全景视觉 [298] 和基于事件的视觉 [124, 158, 306]。这两个视觉领域面临的最大挑战都是缺乏标注数据,而且在这些领域中进行学习需要对神经网络的输入进行特殊的改变。
因此,知识蒸馏(尤其是跨模态知识蒸馏)在这两个领域的应用潜力十分可观。通过将从利用 RGB 图像或帧训练的教师模型中蒸馏出的知识传递给专门用于学习预测 360 度图像或堆叠事件图像的学生网络,不仅可以解决数据缺乏的问题,还能在预测任务中取得理想的结果。
11.7 Integration of vision, speech and NLP.
作为一种潜在应用,将知识蒸馏(KD)应用于视觉、语音和自然语言处理(NLP)的融合学习问题颇具前景。尽管近期跨模态知识蒸馏的尝试 [142, 145, 146, 147] 侧重于在终端任务上把知识从一种模态(例如视频)转移到另一种模态(例如声音),但针对这三种模态融合的终端任务进行学习仍然颇具挑战性。
主要挑战可能源于收集三种模态的配对数据;不过,将生成对抗网络(GAN)或表征学习方法应用于无监督跨模态知识蒸馏,以便学习有效的终端任务,这是有可能实现的。
Section 12 Conclusion
本次对知识蒸馏(KD)和师生(S-T)学习的综述涵盖了视觉智能的主要技术细节及应用。我们给出了该问题的正式定义,并介绍了现有知识蒸馏方法的分类方式。通过梳理这些方法之间的关联,我们确定了一个新的活跃研究领域,该领域很可能催生出能够利用各范式优势的新方法。知识蒸馏方法的每一种分类都展现了其当前在优势和劣势方面的技术现状。基于明确的分析,我们接着探讨了克服挑战的方法,并通过利用新的深度学习方法、新的知识蒸馏损失以及新的视觉应用领域来突破瓶颈。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









