







 本文记录了在基于Flink构建大数据实时数仓过程中遇到的各种问题,包括Slf4j配置问题、用户新老判断、Hbase启动、Redis缓存策略、Flink反压优化等,涉及数据处理、数据库操作、状态管理等多个方面,并提供了详细的解决办法和优化思路。
本文记录了在基于Flink构建大数据实时数仓过程中遇到的各种问题,包括Slf4j配置问题、用户新老判断、Hbase启动、Redis缓存策略、Flink反压优化等,涉及数据处理、数据库操作、状态管理等多个方面,并提供了详细的解决办法和优化思路。
这里写自定义目录标题
-
- 1. 关于Slf4j注解配置文件logback.xml不生效问题
- 2. 判断新老用户的时候,什么时候会出问题:
- 3. 为什么维度数据选择存储在Hbase中,而不是Redis,Mysql中
- 4. 启动phoenix卡住不动了
- 6. java找不到符号
- 7. 为什么实时数仓中没有DWT层?
- 8. 为什么实时数仓中有dwm层?
- 9. 如何给普通的泛型对象赋值?
- 10. 一秒钟来了1000个数据,只能处理800个数据就会产生反压,如何优化?
- 11. redis的安装
- 12. 在做redis旁路缓存的过程中,BaseDBAPP中,如果当前数据为更新操作,则先删除Redis中的数据,然后再执行插入操作,但是如果这两个操作中间,OrderWideAPP进行了一个查询该数据的操作,redis又有该数据了如何解决?
- 13.在使用异步查询优化的测试的时候,老是报Timeout错误,
- 14. DWS层的访客主题宽表中的聚合需要用什么函数?既需要增量也需要窗口信息
- 15. DWS中访客主题宽表,visitorStatsAPP输出的uj_ct始终为0,但是UserJumpDetail会有用户跳出的数据输出,为什么数据没进来?
- 16. 列式存储数据库的优点
- 17. OLAP和OLTP特点
- 18.clickhouse使用什么引擎?在DWS层中按什么分区?按什么排序?
- 19. HBASE随机写操作为什么这么快?
- 20 clickhouse 和hbase区别
- 21. hive中增加字段怎么操作?
- 22. 往Phoenix中写数据的用的是JdbcUtil为什么没有用JdbcSink?ClickHouse用哪个?
- 23. DWS层商品主题宽表计算的思路是什么?
- 24. 编写代码的问题
- 25. hadoop102挂掉了。
- 26. 恢复hadoop之后发现,clickhouse无法启动,
- 27. 断电后Kafka的Hadoop104始终启动不起来。
- 28. 如何做压测
- 29. 状态后端有什么存储位置?
- 30. 什么是FlinkCDC?
- 数据流和程序
- 层
- Sugar的使用
- 优化:
bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic dwd_order_refund_info
bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic
Linux非root用户是没有权限访问1024以下的端口的。
nginx的默认端口号是80
http的默认端口号是80,http://hadoop102:80可以不写80
用process可以把数据保留下来, 把脏数据 输出到测输出流中,用到测输出流只能用到process
动态分流来解决增加表的问题,通过外部文件来感知通知到程序,然后根据外部文件的配置变化来增加
跳出率和留存率都可以反映出用户粘性。
CEP可以使用事件时间,而且如果加了within就可以处理乱序数据,
env.setParallelism(1); // 生产环境,与Kafka分区数保持一致
1. 关于Slf4j注解配置文件logback.xml不生效问题
logback.xml的命名多打了一个空格,真的栓q
2. 判断新老用户的时候,什么时候会出问题:
卸载重装app的时候可能会将老用户标记为新用户。is_new为1时,老用户需要将1改为0,需要用到flink的状态编程(值状态)和相关知识点
3. 为什么维度数据选择存储在Hbase中,而不是Redis,Mysql中
因为维度数据中有个是用户维度信息,数据量非常的大,Hbase能够存储海量数据并且能够做到毫秒级查询
为什么不放在Mysql中,并发压力大,会加大业务数据库的压力。
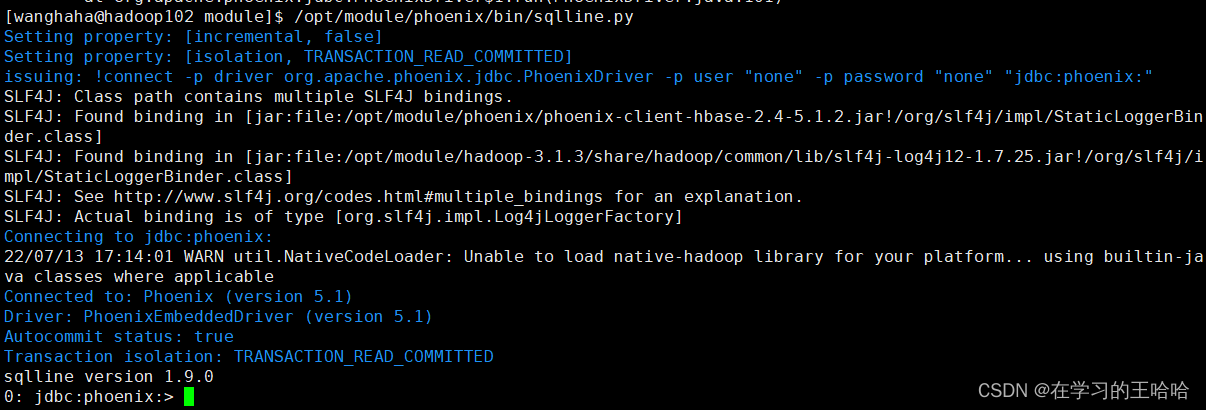
4. 启动phoenix卡住不动了
[wanghaha@hadoop102 module]$ /opt/module/phoenix/bin/sqlline.py hadoop102,hadoop103,hadoop104:2181
Setting property: [incremental, false]
Setting property: [isolation, TRANSACTION_READ_COMMITTED]
issuing: !connect -p driver org.apache.phoenix.jdbc.PhoenixDriver -p user "none" -p password "none" "jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181"
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/phoenix/phoenix-client-hbase-2.4-5.1.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-3.1.3/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
Connecting to jdbc:phoenix:hadoop102,hadoop103,hadoop104:2181
22/07/13 17:02:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:是hbase的meta信息不一致
将zk中hbase删除,然后重新启动hbase搞定
成功解决
6. java找不到符号

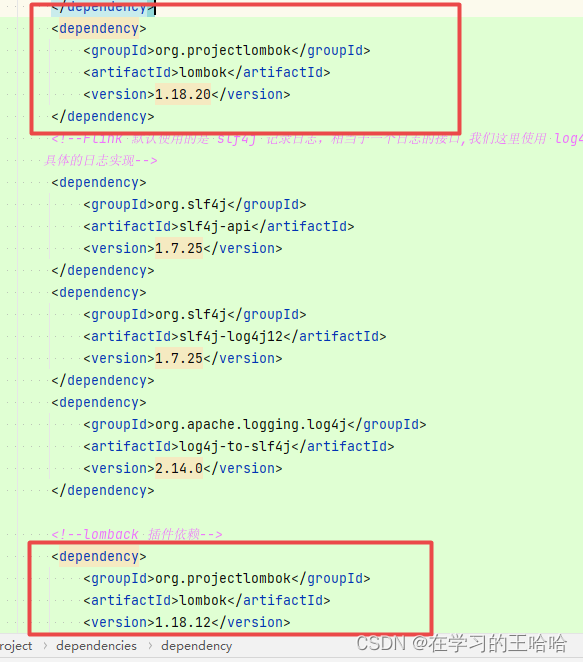
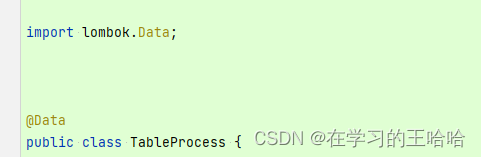
解决方法:我们用到了lombok的Data注解,而我们误引入了多个lombok依赖,删除版本低的,成功解决
7. 为什么实时数仓中没有DWT层?
DWT 数据主题层, 是历史数据的累计结果,实时数仓中不需要。
8. 为什么实时数仓中有dwm层?
9. 如何给普通的泛型对象赋值?
使用工具类,来实现。
<!--commons-beanutils 是 Apache 开源组织提供的用于操作 JAVA BEAN 的工具包。
使用 commons-beanutils,我们可以很方便的对 bean 对象的属性进行操作-->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
<!--Guava 工程包含了若干被 Google 的 Java 项目广泛依赖的核心库,方便开发-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>29.0-jre</version>
</dependency>
// 给泛型对象赋值
for (int i = 1; i < columnCount+1; i++) {
// 获取列名
String columnName = metaData.getColumnName(i);
// 判断是否需要转换为 驼峰命名
if(underScoreToCamel){
columnName = CaseFormat.LOWER_UNDERSCORE
.to(CaseFormat.LOWER_CAMEL,columnName.toLowerCase(Locale.ROOT));
}
// 获取 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









