







在写本篇博客之前,我也是查阅了许多资料,从官方文档到国内外多名网友的教程,但他们写的不是那么的具体,以至于在实际部署的时候遇到了好几个麻烦,浪费了很多时间,但这样一来二去也算是对Spark有了一个比较浅显的初步认识,因祸得福了吧。
废话不多说了,直接上干货。
本博文所使用的系统为Ubuntu 14.04 64位
安装
- 安装JDK,这一步我在这里就不再赘述了,想必稍微有点开发经验的朋友都早已配置好了
- 安装scala,scala采用的是函数式编程,上手难度较高,但他是官方推荐的编程语言,所以我在这里也先装上他,以备日后的学习之需。本文采用的开发语言为Python。
下载scala-2.11.8.tgz,解压到/opt/scala-2.11.8
下载地址:点我下载 - 安装Spark
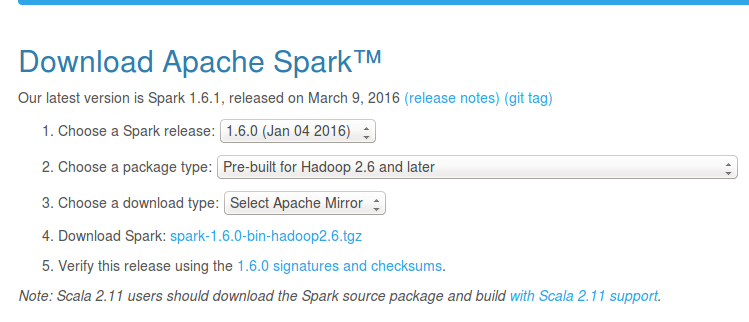
下载spark-1.6.0-bin-hadoop2.6.tgz,解压到/opt/spark-1.6.0-bin-hadoop2.6
下载地址:点我下载
这里附上图,需要选择一些选项:
环境变量配置
sudo gedit /etc/profile
在文件末尾加上如下配置语句:# for scala environment export SCALA_HOME=/opt/scala-2.11.8 export PATH=${SCALA_HOME}/bin:$PATH
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3379
3379











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









