







一、数据类型(这应该记得住的吧?)
1.基本类型(不会有人不知道是8个吧?)
- boolean/1
- byte/8
- char/16
- short/16
- int/32
- float/32
- long/64
- double/64
2.包装类

[1] Integer
(1)new Integer(123) 与 Integer.valueOf(123) 的区别
- new Integer(123) 每次都会新建一个对象
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
Integer z = Integer.valueOf(123);
Integer k = Integer.valueOf(123);
System.out.println(z == k); // true在 Java 8 中, Integer 缓存池的大小默认为 -128~127。
拓展:节本类型对应的缓冲池
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
//在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。如果在缓冲池之外:
Integer m = 323;
Integer n = 323;
System.out.println(m == n); // false
(2)自动拆/装箱
装箱:基本类型-->包装类型,底层逻辑:valueOf()
Integer i = 127;
编译器会在缓冲池范围内的基本类型自动装箱过程调用 valueOf() 方法,因此多个 Integer 实例使用自动装箱来创建并且值相同,那么就会引用相同的对象。
拆箱:包装类型-->基本类型,底层逻辑:intValue()
int i = interger;
[2] String
(1)String 被声明为 final,因此它不可被继承。
(2)内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
(3)可以缓存hash值
(4)String Pool
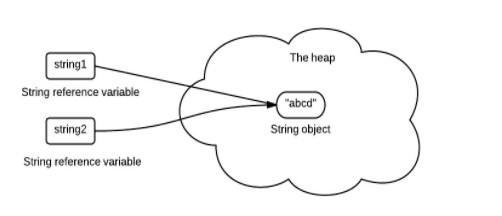
(5)String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
(6)String, StringBuffer and StringBuilder
① 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
② 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
(7)String.intern()
使用 String.intern() 可以保证相同内容的字符串变量引用同一的内存对象。
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
//如果是采用 "bbb" 这种使用双引号的形式创建字符串实例,会自动地将新建的对象放入 String Pool 中。
String s4 = "bbb";
String s5 = "bbb";
System.out.println(s4 == s5); // true
3.折磨的来了哦
(1)int和Integer有什么区别?
第一种:
Java是一个近乎纯洁的面向对象编程语言,但是为了编程的方便还是引入了基本数据类型,但是为了能够将这些基本数据类型当成对象操作,Java为每一个基本数据类型都引入了对应的包装类型(wrapper class),int的包装类就是Integer,从Java 5开始引入了自动装箱/拆箱机制,使得二者可以相互转换。
Java 为每个原始类型提供了包装类型:
- 原始类型: boolean,char,byte,short,int,long,float,double
- 包装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double如:
class AutoUnboxingTest {
public static void main(String[] args) {
Integer a = new Integer(3);
Integer b = 3; // 将3自动装箱成Integer类型
int c = 3;
System.out.println(a == b); // false 两个引用没有引用同一对象
System.out.println(a == c); // true a自动拆箱成int类型再和c比较
}
}
第二种:
Java 提供两种不同的类型:引用类型和原始类型(或内置类型)。Int是java的原始数据类型,Integer是java为int提供的封装类。
Java为每个原始类型提供了封装类。
原始类型封装类
boolean Boolean
char Character
byte Byte
short Short
int Integer
long Long
floa tFloat
double Double
引用类型和原始类型的行为完全不同,并且它们具有不同的语义。引用类型和原始类型具有不同的特征和用法,它们包括:大小和速度问题,这种类型以哪种类型的数据结构存储,当引用类型和原始类型用作某个类的实例数据时所指定的缺省值。
对象引用实例变量的缺省值为null,而原始类型实例变量的缺省值与它们的类型有关。
(2)请你说明String 和StringBuffer的区别?
JAVA 平台提供了两个类:String和StringBuffer,它们可以储存和操作字符串,即包含多个字符的字符数据。
这个String类提供了数值不可改变的字符串。
而这个StringBuffer类提供的字符串进行修改。当你知道字符数据要改变的时候你就可以使用StringBuffer。典型地,你可以使用StringBuffers来动态构造字符数据。
(3) 请说明String是最基本的数据类型吗?
基本数据类型包括byte、int、char、long、float、double、boolean和short。
java.lang.String类是final类型的,因此不可以继承这个类、不能修改这个类。为了提高效率节省空间,我们应该用StringBuffer类。
(4) 请你讲讲Java支持的数据类型有哪些?什么是自动拆装箱?
Java语言支持的8种基本数据类型是:
byte
short
int
long
float
double
boolean
char
自动装箱是Java编译器在基本数据类型和对应的对象包装类型之间做的一个转化。比如:把int转化成Integer,double转化成Double,等等。反之就是自动拆箱。
(5)请你说明符号“==”比较的是什么?
“==”对比两个对象基于内存引用,如果两个对象的引用完全相同(指向同一个对象)时,“==”操作将返回true,否则返回false。
“==”如果两边是基本类型,就是比较数值是否相等。
二、各种标识(见了面你总得认识吧?)
1.标识符
标识符可以简单的理解成一个名字。
规则:
(1)标识符可以由字母、数字、下划线(_)、美元符($)组成,但不能包含 @、%、空格等其它特殊字符
(2)不能以数字开头。如:123name 就是不合法
(3)标识符严格区分大小写。如: tmooc 和 tMooc 是两个不同的标识符
(4)标识符的命名最好能反映出其作用,做到见名知意。
(5)标识符不能是Java的关键字
2.关键字
在Java中,有一些单词被赋予了特定的意义,一共有50个关键字(另外加上true、false)。
这50个单词都是全小写,其中有两个保留字:const和goto。
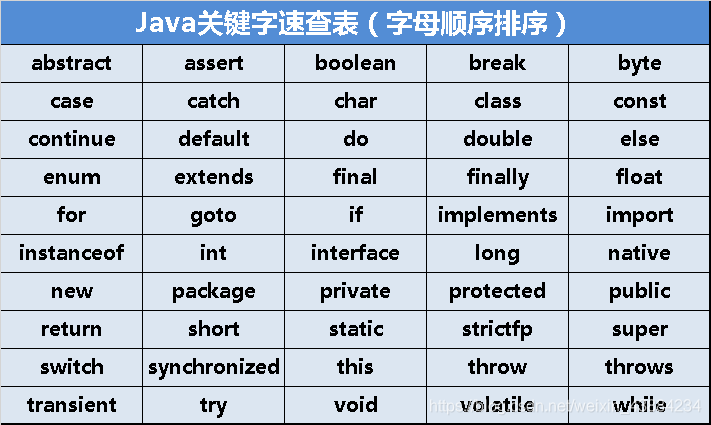
几个重要的关键字,要记得:
(1)final
- 声明数据为常量,可以是编译时常量,也可以是在运行时被初始化后不能被改变的常量。
- 声明方法不能被子类重写。
- 声明类不允许被继承。
(2)static
- 静态变量: 又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它;静态变量在内存中只存在一份。
- 静态方法在类加载的时候就存在了,它不依赖于任何实例。所以静态方法必须有实现,也就是说它不能是抽象方法(abstract)。
- 静态语句块在类初始化时运行一次。
- 非静态内部类依赖于外部类的实例,而静态内部类不需要;静态内部类不能访问外部类的非静态的变量和方法。
- 静态变量和静态语句块优先于实例变量和普通语句块,静态变量和静态语句块的初始化顺序取决于它们在代码中的顺序。
//在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
import static com.xxx.ClassName.*
实例变量: 每创建一个实例就会产生一个实例变量,它与该实例同生共死。
public class A {
private int x; // 实例变量
private static int y; // 静态变量
public static void main(String[] args) {
// int x = A.x; // Non-static field 'x' cannot be referenced from a static context
A a = new A();
int x = a.x;
int y = A.y;
}
}
3.泛型
泛型的本质是为了参数化类型(在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型)。
也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类、接口和方法中,分别被称为泛型类、泛型接口、泛型方法。
<?> 无限制通配符
<? extends E> extends 关键字声明了类型的上界,表示参数化的类型可能是所指定的类型,或者是此类型的子类
<? super E> super 关键字声明了类型的下界,表示参数化的类型可能是指定的类型,或者是此类型的父类
// 使用原则《Effictive Java》
// 为了获得最大限度的灵活性,要在表示 生产者或者消费者 的输入参数上使用通配符,使用的规则就是:生产者有上限、消费者有下限
1. 如果参数化类型表示一个 T 的生产者,使用 < ? extends T>;
2. 如果它表示一个 T 的消费者,就使用 < ? super T>;
3. 如果既是生产又是消费,那使用通配符就没什么意义了,因为你需要的是精确的参数类型。
public class GenericsDemo30{
public static void main(String args[]){
Integer i[] = fun1(1,2,3,4,5,6) ; // 返回泛型数组
fun2(i) ;
}
public static <T> T[] fun1(T...arg){ // 接收可变参数
return arg ; // 返回泛型数组
}
public static <T> void fun2(T param[]){ // 输出
System.out.print("接收泛型数组:") ;
for(T t:param){
System.out.print(t + "、") ;
}
}
}
- 定义泛型方法语法格式

- 调用泛型方法语法格式

4.注解
(1)作用
- 生成文档,通过代码里标识的元数据生成javadoc文档。
- 编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
- 编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
- 运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
(2)常见分类
- Java自带的标准注解,包括
@Override、@Deprecated和@SuppressWarnings,分别用于标明重写某个方法、标明某个类或方法过时、标明要忽略的警告,用这些注解标明后编译器就会进行检查。 - 元注解,元注解是用于定义注解的注解,包括
@Retention、@Target、@Inherited、@Documented,@Retention用于标明注解被保留的阶段,@Target用于标明注解使用的范围,@Inherited用于标明注解可继承,@Documented用于标明是否生成javadoc文档。 - 自定义注解,可以根据自己的需求定义注解,并可用元注解对自定义注解进行注解。
@Target
描述注解存在的位置:
ElementType.TYPE 应用于类的元素
ElementType.METHOD 应用于方法级
ElementType.FIELD 应用于字段或属性(成员变量)
ElementType.ANNOTATION_TYPE 应用于注解类型
ElementType.CONSTRUCTOR 应用于构造函数
ElementType.LOCAL_VARIABLE 应用于局部变量
ElementType.PACKAGE 应用于包声明
ElementType.PARAMETER 应用于方法的参数
@Retention
该注解定义了自定义注解被保留的时间长短,比如某些注解仅出现在源代码中,
而被编译器丢弃;而另一些却被编译在class文件中;
编译在class文件中的注解可能会被虚拟机忽略,而另一些在class被装载时将被读取。
SOURCE 在源文件中有效(即源文件保留)
CLASS 在class文件中有效(即class保留)
RUNTIME 在运行时有效(即运行时保留)
package cn.tedu.annotation;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
/*本类用于自定义注解入门*/
public class TestAnnotation { }
/*2.通过@Target注解表示此自定义注解可以使用的位置
* 注意:我们使用“ElementType.静态常量值”的方式来指定这个自定义注解可以使用的位置
* 这个位置可以写多个,格式:@Target({ElementType.XXX,ElementType.XXX})*/
//3.本行代码表示自定义注解可以加在类上 方法上 字段上
//@Target({ElementType.TYPE,ElementType.METHOD,ElementType.FIELD})
@Target(ElementType.METHOD)
/*3.通过@Retention注解表示此自定义注解的生命周期
* 注意:我们使用”RetentionPolicy.静态常量名“的方式来指定这个自定义注解可以活多久
* 也就是指定这个自定义注解存在哪个文件中:源文件中/字节码文件中/运行时有效
* 而且这三个值,只能3选1,不能同时写多个*/
//2.本行代码表示自定义注解只可以存在于源文件中
@Retention(RetentionPolicy.SOURCE)
/*0.首先注意:自定义注解的语法与java不同,不要套用java的格式*/
/*1.定义自定义注解,注解名Rice,并通过两个元注解表示这个自定义注解的作用位置和声明周期
* 注解定义的格式:"@interface 注解名"的方式来定义的*/
//1.定义自定义注解
@interface Rice{
//5.给注解进行功能的增强--添加属性
/*4.注意:int age();不是方法的定义,而是给自定义注解添加了一个age属性
* 如果为了使用注解时方便,还可以指定这个注解属性的默认值,这样就可以直接使用注解
* 不用给属性赋值了,格式:int age() default 0;
* */
//int age();//给自定义注解定义一个普通的int类型的属性age
int age() default 0;//给属性定义一个默认值0
/*5.注解中还可以添加特殊属性value
* 特殊属性的定义方式与别的属性相同,主要是使用方式不同
*注解使用时,这个特殊属性的赋值可以不用写成“@Rice(value="Apple")”
* 格式可以简化成"@Rice("Apple")"直接写值
* 自定义注解也可以赋予默认值,但是默认值的格式不能简写*/
//String value();//定义一个自定义注解中的特殊属性value,类型是String
String value() default "lemon";//定义一个自定义注解中的特殊属性并赋值
}
//4.创建一个类用来测试自定义注解
//@Rice
class TestAnno{
/*测试1:分别给TestAnno类/name属性/eat()都添加了Rice注解,只有方法上不报错
* 结论:自定义注解能够加在什么位置,取决于@Target注解的值
* 注意:如果@Target注解设置了多个值,自定义注解才能加在不同的位置
* 原因是因为Target注解底层的源码:ElementType[] values();*/
//@Rice
String name;
/*测试2:当我们给Rice注解添加了一个age属性以后,@Rice注解直接使用时报错
* 结论:当注解没有定义属性时,可以直接使用,如果有属性了,就必须给属性赋值
* 赋值的格式:"@Rice(age = 10)",注意不能直接写10,这个格式是错误的*/
//@Rice(age = 10)
/*测试3:给age属性赋予默认值后,可以使用注解时不给这个属性赋值,
这个时候使用的就是age的默认值,也就是说注解可以直接使用*/
//@Rice("Apple")
@Rice
public void eat(){
System.out.println("一会又要干饭啦~");
}
}
(3)内置注解
@Override:表示当前的方法定义将覆盖父类中的方法@Deprecated:表示代码被弃用,如果使用了被@Deprecated注解的代码则编译器将发出警告@SuppressWarnings:表示关闭编译器警告信息
class A{
public void test() {
}
}
class B extends A{
/**
* 重载父类的test方法
*/
@Override
public void test() {
}
/**
* 被弃用的方法
*/
@Deprecated
public void oldMethod() {
}
/**
* 忽略告警
*/
@SuppressWarnings("rawtypes")
public List processList() {
List list = new ArrayList();
return list;
}
}
5.折磨的来了哦
(1)请你讲讲Java里面的final关键字是怎么用的?
当用final修饰一个类时,表明这个类不能被继承。也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。
“使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。“
对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
(2)请你谈谈关于Synchronized和lock
synchronized是Java的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。JDK1.5以后引入了自旋锁、锁粗化、轻量级锁,偏向锁来有优化关键字的性能。
Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
(3) 请你介绍一下volatile?
volatile关键字是用来保证有序性和可见性的。这跟Java内存模型有关。比如我们所写的代码,不一定是按照我们自己书写的顺序来执行的,编译器会做重排序,CPU也会做重排序的,这样的重排序是为了减少流水线的阻塞的,引起流水阻塞,比如数据相关性,提高CPU的执行效率。需要有一定的顺序和规则来保证,不然程序员自己写的代码都不知带对不对了。
所以有happens-before规则,其中有条就是volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;有序性实现的是通过插入内存屏障来保证的。
可见性:首先Java内存模型分为,主内存,工作内存。比如线程A从主内存把变量从主内存读到了自己的工作内存中,做了加1的操作,但是此时没有将i的最新值刷新会主内存中,线程B此时读到的还是i的旧值。加了volatile关键字的代码生成的汇编代码发现,会多出一个lock前缀指令。
Lock指令对Intel平台的CPU,早期是锁总线,这样代价太高了,后面提出了缓存一致性协议,MESI,来保证了多核之间数据不一致性问题。
(4)请你介绍一下Syncronized锁,如果用这个关键字修饰一个静态方法,锁住了什么?如果修饰成员方法,锁住了什么?
synchronized修饰静态方法以及同步代码块的synchronized (类.class)用法锁的是类,线程想要执行对应同步代码,需要获得类锁。
synchronized修饰成员方法,线程获取的是当前调用该方法的对象实例的对象锁。
三、运算符(天天用,天天忘)

1.参数传递
Java 的参数是以值传递的形式传入方法中,而不是引用传递。
但是如果在方法中改变对象的字段值会改变原对象该字段值,因为改变的是同一个地址指向的内容。
2.类型转换
箭头开始的地方是小类型,箭头指向的地方是大类型
我们此处所指的"大"和"小",指的是对应类型的取值范围,不是字节数哦
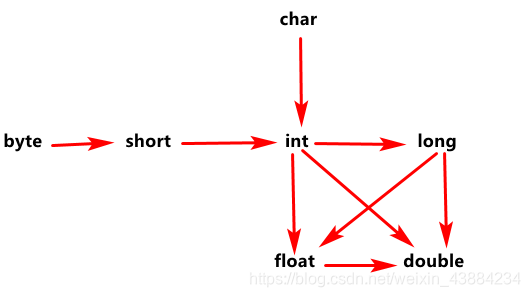
(1) 小到大(隐式转换)
byte m = 120;
int n = m;//小转大,右面的m是小类型,给左面的n大类型赋值,可以直接使用
float f = 3.2f; double d = f;// -->可以执行(2)大到小(显式转换)
①容量大的类型转换为容量小的类型时必须使用强制类型转换。
②转换过程中可能导致溢出或损失精度
例如:int i =128; byte b = (byte)i; //打印的结果是-128
③因为 byte 类型是 8 位,最大值为127,所以当 int 强制转换为 byte 类型时,值 128 时候就会导致溢出。
④浮点数到整数的转换是通过舍弃小数得到,而不是四舍五入
例如:float f = 32.7f; int a2 =(int) f; //打印的结果是32
⑤不能对boolean类型进行类型转换。
3.运算规则(5条)
(1)计算结果的数据类型,与最大数据类型一致
(2)byte,short,char三种比int小的整数,运算时会先自动转换成int
byte a = 1;
byte b = 2;
byte c = (byte)(a+b);
//a+b会自动提升成int类型,右面得运算结果就是int大类型
//给左面的byte小类型赋值,不可以,需要强转。(3)整数运算溢出
(4)浮点数运算不精确
(5)浮点数的特殊值
Infinity 无穷大 3.14/0
NaN not a number 0/0.0 或 0.0/0
4.算术运算符之自增自减运算符
a是操作数,++是自增运算符,–是自减运算符,自增和自减运算符即可以放在变量的前面,也可以放在变量的后面,例如:a++、++a、a–、--a等。
自增(++):将变量的值加1
分前缀式(如++a)和后缀式(如a++)。前缀式是先加1再使用;后缀式是先使用再加1。
自减(–):将变量的值减1
分前缀式(如–a)和后缀式(如a–)。前缀式是先减1再使用;后缀式是先使用再减1。
5.逻辑运算符
逻辑运算符连接两个关系表达式或布尔变量,用于解决多个关系表达式的组合判断问题
注意逻辑运算符返回的运算结果为布尔类型
通常,我们用0表示false,用1表示true
与:表示并且的关系
&单与: 1 & 2 ,结果想要是true,要求1和2都必须是true
&&双与(短路与):1 && 2 ,当1是false时,2会被短路,提高程序的效率
或:表示或者的关系
|单或: 1 | 2,结果想要是true,要求1和2只要有一个为true就可以
||双或(短路或):1 || 2,当1是true时,2会被短路,提高程序效率
6.正则表达式
正确的字符串格式规则。
常用来判断用户输入的内容是否符合格式的要求,注意是严格区分大小写的。
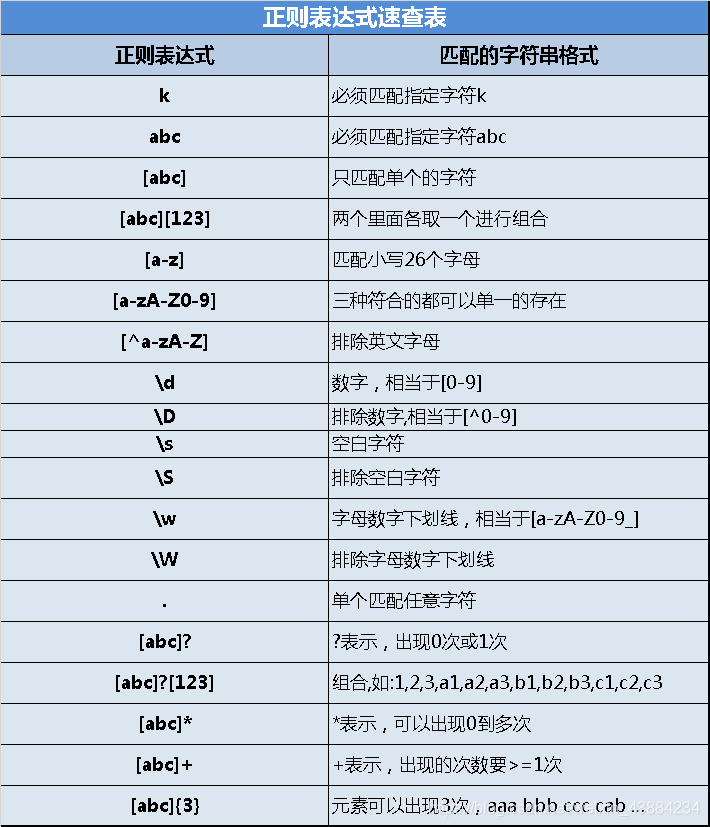
7.又见折磨
(1)请你谈谈Java中是如何支持正则表达式操作的?
Java中的String类提供了支持正则表达式操作的方法,包括:matches()、replaceAll()、replaceFirst()、split()。此外,Java中可以用Pattern类表示正则表达式对象,它提供了丰富的API进行各种正则表达式操作,如:
import java.util.regex.Matcher; import java.util.regex.Pattern; class RegExpTest { public static void main(String[] args) { String str = "成都市(成华区)(武侯区)(高新区)"; Pattern p = Pattern.compile(".*?(?=\\()"); Matcher m = p.matcher(str); if(m.find()) { System.out.println(m.group()); } } }
(2)请你简单描述一下正则表达式及其用途。
在编写处理字符串的程序时,经常会有查找符合某些复杂规则的字符串的需要。
正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
计算机处理的信息更多的时候不是数值而是字符串,正则表达式就是在进行字符串匹配和处理的时候最为强大的工具,绝大多数语言都提供了对正则表达式的支持。
(3)请你讲讲&和&&的区别?
&运算符有两种用法:
(1)按位与;(2)逻辑与。
&&运算符是短路与运算。逻辑与跟短路与的差别是非常巨大的,虽然二者都要求运算符左右两端的布尔值都是true整个表达式的值才是true。
&&之所以称为短路运算是因为,如果&&左边的表达式的值是false,右边的表达式会被直接短路掉,不会进行运算。
很多时候我们可能都需要用&&而不是&,例如在验证用户登录时判定用户名不是null而且不是空字符串,应当写为:username != null &&!username.equals(""),二者的顺序不能交换,更不能用&运算符,因为第一个条件如果不成立,根本不能进行字符串的equals比较,否则会产生NullPointerException异常。















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









