







 MTGODE是Multivariate Time Series Forecasting的一种新方法,它结合动态图神经网络和常微分方程(ODE)。模型通过连续时间聚合和连续图传播机制,解决了离散神经结构的不连续性、高复杂性和对预定义图结构的依赖。相较于STGODE,MTGODE能更有效地捕捉时空动态,尤其在连续时间建模和图结构学习上有所创新。实验显示MTGODE在多个数据集上表现出优越性能。
MTGODE是Multivariate Time Series Forecasting的一种新方法,它结合动态图神经网络和常微分方程(ODE)。模型通过连续时间聚合和连续图传播机制,解决了离散神经结构的不连续性、高复杂性和对预定义图结构的依赖。相较于STGODE,MTGODE能更有效地捕捉时空动态,尤其在连续时间建模和图结构学习上有所创新。实验显示MTGODE在多个数据集上表现出优越性能。
MTGODE
Multivariate Time Series Forecasting with Dynamic Graph Neural ODEs
(ODE +学一个图 + 动态图迭代 )
笔记目录
一、背景与模型设计
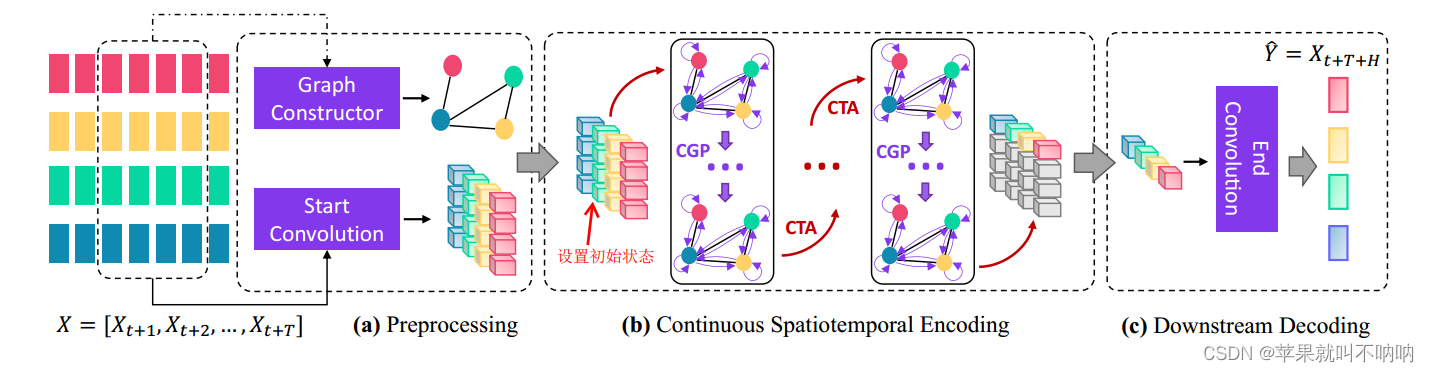
其中:
- Graph Constructor 和 MTGNN的Graph learning模块 一样
- Start Convolution 和MTGNN中的 1×1 conv模块一样
- CTA中间嵌套多次CGP,空洞卷积实现对时间的长距离依赖特征提取 以及 通过ODE细粒化(好几次的迭代的CGP过程)实现对于图的长距离关系捕捉
- CTA CGP都运用ODE
二、与STGODE的不同
STGODE只考虑了在预定义的静态图结构上的连续图传播,没有对连续的时间动态进行建模。
MTGODE在两个重要方面与它不同:
• 首先,提出了一种新的连续时间聚合机制,结合简化的连续图传播过程,以全连续的方式高效地学习更具表现力的潜在时空动态。
• 其次,MTGODE方法消除了对预定义图结构的依赖。
三、现阶段研究的问题与设计思路
(i).离散的神经结构:
将单独参数化的空间和时间块交错以编码丰富的潜在模式,会导致:不连续的潜在状态轨迹和更高的预测数值误差+过平滑影响远距离特征的提取。
(ii).高复杂性:
离散地叠加单独参数化的空间和时间模块,不仅会导致潜在状态轨迹不连续,而且会使参数化残差以及跳过连接的模型复杂化,训练参数冗余,导致计算和内存效率低下
(iii).依赖图先验:
依赖于预定义的静态图结构,限制了它们在现实世界应用中的有效性和实用性。
本文通过提出一个动态图神经常微分方程(MTGODE)预测多元时间序列的连续模型来解决上述所有限制。
• 为了补充和学习 节点(即变量)之间缺失的相互依赖关系,提出了一种连续图传播机制 + 图结构学习模式来部分解决(i),全部解决(iii),显著缓解了gnn中的过平滑问题,从而允许在动态自提取的图结构上进行更深层次的连续传播,以捕获时间序列之间的长期空间相关性。
• 为了编码丰富的时间信息并彻底解决(i),提出了一种连续的时间聚合机制来参数化潜在状态的导数而不是其本身,从而可以精确地提取和聚合细粒度的时间模式。值得注意的是,该机制还通过 消除冗余计算和解开离散公式中聚合深度和内存瓶颈之间的联系 巧妙地解决了(ii),因此可以提供比有限计算预算的离散方法更准确的潜在时间动力学建模。CTA和CGP都是用迭代的方式更新,从而减少参数量。
- 第一个通过两个耦合的ODE和更简洁的模型 设计统一时空信息传递 来学习任意多变量时间序列的工作。
- 提出了一种spatial ODE和一种图学习模式来学习时间序列之间的连续长期空间动态,从而减轻了对静态图先验的依赖和gnn中常见的过平滑问题。
- 提出了一个temporal neural ODE,通过推广规范时间卷积来学习时间序列的连续细粒度时间动态,从而得到一个强大而有效的空间ODE预测模型。
实验从不同角度证明了MTGODE在5个时间序列基准数据集上的优势。
四、几种方法的时间聚合形式对比
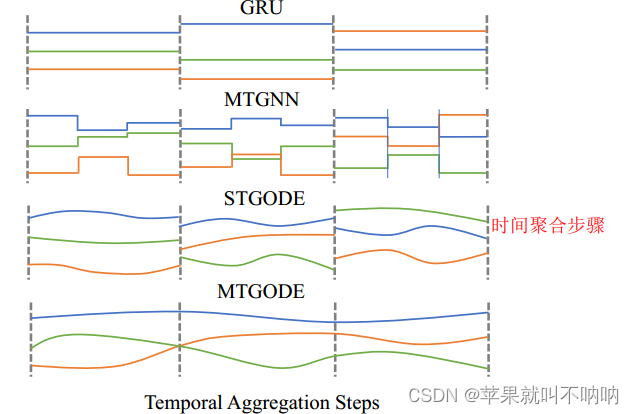
不同预测方法在对历史观测值进行编码时的潜在状态轨迹。垂直的虚线表示时间聚集步骤,三条彩色实线是不同变量的潜在状态轨迹。
在这些方法中:
- GRU在两个观测值之间具有不变的潜在状态。
- MTGNN在每个时间聚合步骤之后具有一系列转换(即图传播)。
- 虽然STGODE使用ODE生成离散图传播,但它的时间聚合仍然是离散的。
- 相比之下,MTGODE允许对完全连续的潜在时空动态进行建模。
五、CGP 连续图传播 Continuous Graph Propagation
5.1 公式推导
定义K-hop图传播的离散公式为:

其中:
A代表normalize后的邻接矩阵N × N;
HGk:代表中间状态,N节点数×D’特征数×Q序列长度;
HGout:代表输出状态,N节点数×D’特征数×Q序列长度;
φ:可训练的参数矩阵D’×D’
用上述方程中的爱因斯坦求和来定义特征传播中的张量乘法,以对特定维度上的元素积求和。
这是因为特征传播只对潜在状态的前两个维度进行操作,而没有沿着时间轴(序列长度为Q)聚合信息。
与GCN相比,方程4消除了冗余非线性,进一步解耦了特征传播和转换步骤,在保持相当精度的同时,模型更简单、更高效。
然而,这种离散公式容易出错,并且在进行深度计算时容易过度平滑。
| 将传播深度K分解为:积分时间Tcgp 与 步长∆Tcgp的组合,即K = Tcgp/∆Tcgp 从而实现离散k∈{0,···,k−1} 到连续 t∈R |
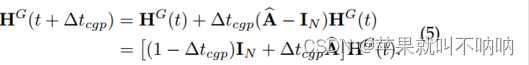
让传播深度K = Tcgp→∞,不仅会使离散传播中的图拉普拉斯特征值趋于零(见附录a),而且还会导致无限的数值误差(见附录B),从而使模型无法准确捕获远程空间依赖关系。
| 解开K与Tcgp之间的耦合,避免Tcgp→∞,从而可以捕获时间序列之间的细粒度和远程空间依赖关系 |
为了进一步减小数值误差,提出了下式(7)来代替式(4)中图传播的线性映射,不仅集成了最终状态,还集成了初始状态和选定的中间状态作为图传播的输出:
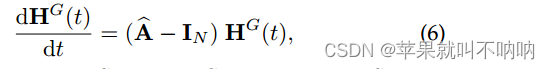
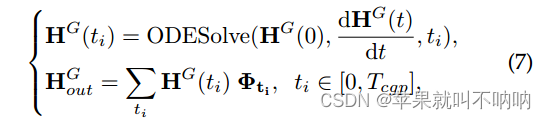
最终的图传播公式 ↑,空间ODE只允许在某个时间步捕获时间序列之间的空间依赖关系
ODESolve(·)ODE求解器,HG(ti)表示CGP过程的选定中间状态,
5.2 代码片段
step_size 决定了self.estimated_nfe 中间状态个数的大小
CGP的大框架如下:调用后面的CGPODEBLOCK
class CGP(nn.Module): # 连续图传播 本质上也是一个ODE
def __init__(self, cin, cout, alpha=2.0, method='rk4', time=1.0, step_size=1.0,
rtol=1e-4, atol=1e-3, adjoint=False, perturb=False):
super(CGP, self).__init__()
self.c_in = cin
self.c_out = cout
self.alpha = alpha
if method == 'euler':
self.integration_time = time
self.estimated_nfe = round(self.integration_time / step_size) # 时间除以时间步 ≈ 离散空间中的层数estimated_nfe(就是之前的离散的两层之间,用ODE的话计算几次,即ODEFunc循环计算几次)
elif method == 'rk4':
self.integration_time = time
self.estimated_nfe = round(self.integration_time / (step_size / 4.0))
else:
raise ValueError("Oops! The CGP solver is invaild.")
self.CGPODE = CGPODEBlock(CGPFunc(self.c_in, self.c_out, self.alpha),
method, step_size, rtol, atol, adjoint, perturb,
self.estimated_nfe)
def forward(self, x, adj):
self.CGPODE.set_x0(x)
self.CGPODE.set_adj(adj)
h = self.CGPODE(x, self.integration_time)
return h
CGPODEBlock:
构建任何一个ODE block都需要调用torchdiffeq.odeint_adjoint,需要参数odefunc,初始值x,时间数组,举例:
y4 = torchdiffeq.odeint(f2, torch.tensor(y0,dtype=torch.float32), torch.tensor(t1))
# 需要三个参数:一个是func,一个是初始值,一个是时间
# f2使用neural network替代显式表达式,y4最后呢就是一个记录所有时刻的数组,相当于是把所有状态都记录下来
torchdiffeq.odeint_adjoint和torchdiffeq.odeint是PyTorch中用于求解常微分方程(ODE)的两个函数
区别如下:
-
功能:torchdiffeq.odeint_adjoint函数用于求解带有梯度的ODE问题,而torchdiffeq.odeint函数用于求解不带梯度的ODE问题。
-
梯度传播:torchdiffeq.odeint_adjoint函数使用了反向传播的技术,可以高效地计算ODE的梯度。它通过在正向传播和反向传播之间共享中间结果来减少计算量,从而提高了计算效率。相比之下,torchdiffeq.odeint函数不会计算梯度。
-
内存消耗:由于使用了反向传播技术,torchdiffeq.odeint_adjoint函数在计算梯度时可能会占用更多的内存。相比之下,torchdiffeq.odeint函数通常在内存消耗方面更加高效。
因此,选择使用torchdiffeq.odeint_adjoint还是torchdiffeq.odeint取决于你的具体需求。如果你需要计算ODE的梯度,那么应该使用torchdiffeq.odeint_adjoint函数。如果你只需要求解不带梯度的ODE问题,那么torchdiffeq.odeint函数就足够了
# 两种模式的求解常微分方程(ODE)的两个函数
if self.adjoint:
out = torchdiffeq.odeint_adjoint(self.odefunc, x, self.integration_time, rtol=self.rtol, atol=self.atol,
method=self.method, options=dict(step_size=self.step_size_1, perturb=self.perturb))
else:
out = torchdiffeq.odeint(self.odefunc, x, self.integration_time, rtol=self.rtol, atol=self.atol,
method=self.method, options=dict(step_size=self.step_size_1, perturb=self.perturb))
CGPODEBlock整体代码如下:
class CGPODEBlock(nn.Module): # 任何一个ODE block都需要调用torchdiffeq.odeint_adjoint,需要参数odefunc,初始值x,时间数组
def __init__(self, cgpfunc, method, step_size, rtol, atol, adjoint, perturb, estimated_nfe):
super(CGPODEBlock, self).__init__()
self.odefunc = cgpfunc
self.method = method
self.step_size = step_size
self.adjoint = adjoint
self.perturb = perturb
self.atol = atol
self.rtol = rtol
self.mlp = linear((estimated_nfe + 1) * self.odefunc.c_in, self.odefunc.c_out)
def set_x0(self, x0):
self.odefunc.x0 = x0.clone().detach()
def set_adj(self, adj):
self.odefunc.adj = adj
def forward(self, x, t):
self.integration_time = torch.tensor([0, t]).float().type_as(x) # 时间数组
if self.adjoint:
out = torchdiffeq.odeint_adjoint(self.odefunc, x, self.integration_time, rtol=self.rtol, atol=self.atol,
method=self.method, options=dict(step_size=self.step_size, perturb=self.perturb))
else:
out = torchdiffeq.odeint(self.odefunc, x, self.integration_time, rtol=self.rtol, atol=self.atol,
method=self.method, options=dict(step_size=self.step_size,
perturb=self.perturb))
# 使用torchdiffeq库中的odeint_adjoint函数进行求解的ODE(常微分方程)问题
# odefunc(ODE的右侧函数)、x(初始条件)、integration_time(积分时间)、rtol(相对误差容限)、atol(绝对误差容限)、method(积分方法)和options(其他选项)
outs = self.odefunc.out
self.odefunc.out = []
outs.append(out[-1])
# out[-1] 取最后一个时刻的特征,相当于离散空间的最后一个layer的feature
h_out = torch.cat(outs, dim=1)
h_out = self.mlp(h_out)
return h_out
同时,这里给出设计的CGPfunc,CGPODEBlock需要调用这里的func作为常微分方程(ODE的右侧函数):
class CGPFunc(nn.Module): # CGP的func在此!
def __init__(self, c_in, c_out, init_alpha):
super(CGPFunc, self).__init__()
self.c_in = c_in
self.c_out = c_out
self.x0 = None
self.adj = None
self.nfe = 0
self.alpha = init_alpha
self.nconv = nconv()
self.out = []
def forward(self, t, x):
# 得到归一化后的邻接矩阵
adj = self.adj + torch.eye(self.adj.size(0)).to(x 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









