









如果希望把每天出错的信息写入日志文件,每天新建一个文件。
package test.scala
import java.io.{File, FileWriter}
import java.text.SimpleDateFormat
import java.util.{Calendar, Date}
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
object LogWriter {
private val logDirectory = new File("D:\\data\\log")
private val dateFormat = new SimpleDateFormat("yyyy-MM-dd")
private val lock = new Object()
private def createLogFile(): File = {
val currentDate = dateFormat.format(new Date())
val logFileName = s"$currentDate.log"
val logFile = new File(logDirectory, logFileName)
if (!logDirectory.exists()) {
logDirectory.mkdirs()
}
if (!logFile.exists()) {
logFile.createNewFile()
}
logFile
}
def writeLog(content: String): Unit = {
lock.synchronized {
val logFile = createLogFile()
val currentTime = Calendar.getInstance().getTime
val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val formattedTime = dateFormat.format(currentTime)
//val logLine = s"$content\n"
val logLine = s"$formattedTime: $content\n"
val fileWriter = new FileWriter(logFile, true)
fileWriter.write(logLine)
fileWriter.close()
}
}
def main(args: Array[String]): Unit = {
LogWriter.writeLog("日志测试一")
LogWriter.writeLog("日志测试二")
LogWriter.writeLog("日志测试三")
}
}

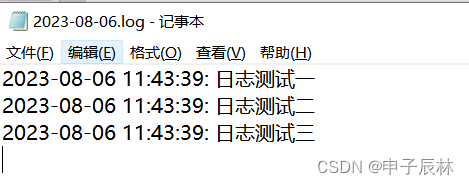
日志文件内容:















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









