







在内存里维护一个序列,可能第一个想到的就是红黑树。但是,红黑树算法复杂,这还不是主要的,主要的问题是:红黑树的空间利用率低。
红黑树的空间利用率
一个红黑树的节点,包括父节点指针、两个子节点指针、一个红黑属性、一条数据。其中,数据若是一个机器字,一般为8字节,则空间利用率是1/5。
但是,采用malloc函数分配内存时,还有两个数的开销。整体算下来,利用率是1/7。
延迟序列的使用场景
内存够用的时候,当然是红黑树更好。但是,当内存不足时,传统的数据库会启用硬盘上的数据结构。在这两者之间,是延迟序列的应用场景。即,用红黑树报告内存不足,但实际上内存还有6倍余量,这时,应使用“延迟序列”。
延迟序列的数据结构
初步的版本,由四个序列组成。三个原始序列,长度分别是100、1万、100万个数据,一个删除序列,长度为100个数据。这四个序列均预先分配,用指针指出首尾,避免realloc函数的使用。这个函数有时会把整个内存块完整地复制一遍,这很慢,需避免。
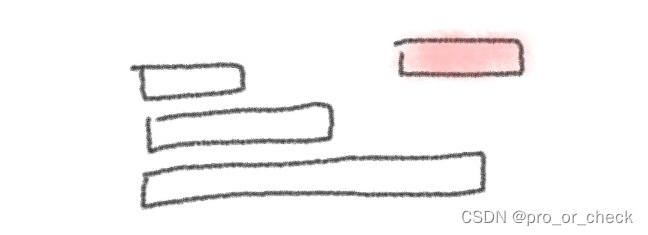
如图,红色长条表示删除序列,左侧的三个长条表示原始序列,它们的长度一个比一个长。
延迟序列的增删改查
这里没有用平衡二叉树存储序列,而是用数组。这导致在增加数据时,会产生批量的数据移动。例如,插入位置在数组的中间,则需要把后边的一半数据全都向后移动一格,再插入。
同理,若要删除一条数据,需要把后边的数据批量向前移动一格才可以。
当频繁插入、删除数据时,批量移动数据会显得很低效,不建议采用。所以,就有了延迟序列,它有“延迟插入、延迟删除”的特性。
当删除数据时,有一套方案是,暂时把数据改为0,表示删除了,过一会儿,或攒够了一定数量再整理。但是,0数据存在于序列中,会降低二分查找的效率,不推荐。所以,才有的一个单独的删除序列。
增加
在延迟序列里增加一条数据,先查看删除序列里有没有,如果有则删除它,就表示增加了数据。如果删除序列很长,甚至像原始序列那样有百万数据,则增加操作是缓慢的。所以,删除序列不宜过长,在初始的版本中,设计为100个数据。
若删除序列里没有,则在原始序列的第一层增加,使用插入排序,即接受小规模的批量移动数据。如果第一层满了,就引发归并排序,向第二层合并。如果第二层满了,就向第三层归并。
如果全满了,就报告内存不足。这时,应该像往常那样,启动硬盘上的数据结构,往硬盘里写。
删除
多数情况下,删除操作只是在不太长的删除序列里添加一项。当删除序列满了,就批量删除一次。由于删除序列也是有序的,所以应该叫归并删除?
查询
在延迟序列里查询一项,需要进行多个二分查找。先在原始序列的第一层查找,这里也是使用率最高的那些数据,根据数据的局部性原理,落在缓冲里的概率也较大。
若在第一层没找到,需要去第二层找。若还没找到,需要进第三层找。第三层里有百万数据,使用二分查找,需要找一阵子呢。最后,在删除序列里找,如果有则查找失败。
修改
大家熟悉的“增删改查”还有一个改,在序列中修改一个值,值的位置也会变化。所以“改”解释成先删除再增加,可否?
计算
据说,机械硬盘比内存慢百万倍,所以,原始序列里设计为100万个数据。即使执行插入操作,要把数据移动百万次,仍然比访问硬盘快。这只是个粗略的计算,固态硬盘的普及将改变这个数字,需要重新计算。
总结
在内存里维护一个序列,一般使用红黑树,但红黑树存在空间利用率低的缺点,所以,就有了“延迟序列”,它在红黑树内存满了以后、启动硬盘数据结构之前使用,能应付一阵子。
具体来说,要在红黑树内存即将满了,还没满的时候使用延迟序列。对红黑树进行中序遍历,把数据按顺序取出来,这也需要一部分内存。















 4291
4291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









