







先找个图像基础看一看,几分钟就行了,知道计算机下图像是什么样的。不然问我为什么要用数字,用矩阵...我真回答不上来
这里的代码实现的环境 python 版本3.6.3, opencv-python版本3.4.1.15
仅供参考
目录
1.引包
2.读取图像
3.显示图像
4.打印图像矩阵
5.保存图像
6.颜色通道B,R,G获取
7.边界填充
8.opencv视频读取与处理
9.ROI区域
10.数值计算
1.引包(如果没有,则代表你的anaconda环境里没有,请下载到anaconda环境,或者切换anaconda环境)
import cv2
import numpy as np
import matplotlib.pyplot as plt #这一条是用matplotlib,如果没有可不输入,matplotlib是图像处理的插件,还是比较好用的,推荐装到环境中2.读取图像(我的图像命名是girl1.jpg)
彩色图像的读取
# 读取图像(如果图片是在计算机内,而没有放在python项目中,path是你的电脑存储图像的路径)
path = 'C:/Users/13758/Pictures/test/'
img = cv2.imread(path + "girl1.jpg")
#读取图像(如果图像放在python下)
img = cv2.imread("girl1.jpg")灰度图像的读取
#读取灰度图
img = cv2.imread("girl1.jpg",cv2.IMREAD_GRAYSCALE)3.显示图像
# 下面两行是opencv 显示
cv2.imshow('girl1',img)
cv2.waitKey(1000) #cv2.waitkey()表示图片滞留时间,若括号内为0,则按任意键结束放映,若为1000,则1000毫秒后自动结束放映# 下面是三行matplotlib 显示
plt.imshow(img)
plt.axis('off')
plt.show()若运行上面三行则可以发现图像变蓝,OpenCV读取图片(cv2.imread())后,图像的颜色通道顺序是[B, G, R],和matplotlib读取图片(plt.imread())后,图像的颜色通道顺继续[R, G, B]恰好是相反的。这时,我们要想让图片正常显示,需要进行通道交换。
img = img[:,:,(2,1,0)] # 交换B和R通道 matplotlib显示图像
plt.imshow(img)
plt.axis('off')
plt.show()
4.打印图像矩阵
# 下面2行为读取图像数据矩阵
pixel_data = np.array(img)
print(pixel_data)
print(img.shape) #打印宽度,高度,通道数
print(img.size) #打印图像像素大小
print(img.dtype) #打印数据类型5.保存图像
saveFile = "C:/Users/13758/Pictures/test/girl2.jpg"
cv2.imwrite(saveFile,img)
使用函数cv2.imwrite(file,img,num)保存一个图像。第一个参数是要保存的文件名,第二个参数是要保存的图像。可选的第三个参数,它针对特定的格式:对于JPEG,其表示的是图像的质量,用0 - 100的整数表示,默认95;对于png ,第三个参数表示的是压缩级别。默认为3.
6.颜色通道B,R,G获取
#颜色通道提取
# 分离 b,r,g通道
b,r,g = cv2.split(img)
print(r) #打印r通道
print(r.shape)
# 整合 b,r,g通道
img = cv2.merge((b,g,r))
print(img.shape)
#只保留R
cur_img = img.copy()
cur_img[:,:,0] = 0
cur_img[:,:,1] = 0
cv2.imshow('R',cur_img)
cv2.waitKey(1000)
#只保留G
cur_img = img.copy()
cur_img[:,:,0] = 0
cur_img[:,:,2] = 0
cv2.imshow('G',cur_img)
cv2.waitKey(1000)
#只保留R
cur_img = img.copy()
cur_img[:,:,1] = 0
cur_img[:,:,2] = 0
cv2.imshow('B',cur_img)
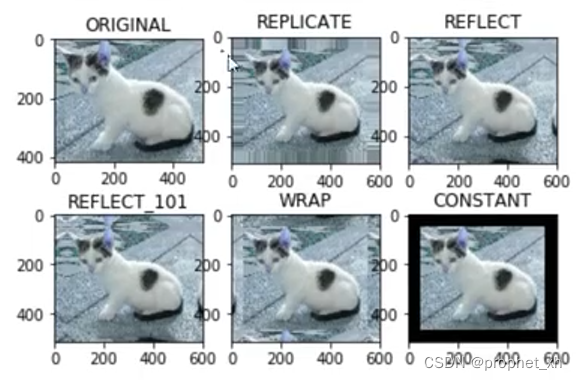
cv2.waitKey(1000)7.边界填充 (会在特征提取中用到)
简单理解就是把图像四周的扩大,那扩大后的区域拿什么来填充的问题
一般就是下面5种扩充的方式
#BORDER_REPLICATE:复制法,也就是复制最边缘像素。 #BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcba|abcdefgh|hgfedcb #BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba #BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg #BORDER_CONSTANT:常量法,常数值填充,需要在函数中填入常数参数。
复制法的代码实现
top_size, bottom_size, left_size, right_size = (50, 50, 50, 50)
replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
cv2.imshow('replicate',replicate)
cv2.waitKey(0)其它几种方法实现的代码差不多,下面附上,你也可以改成用opencv查看,这里用的是plt查看
# 填充的范围
#top_size, bottom_size, left_size, right_size = (50, 50, 50, 50)
# 填充
#replicate = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, borderType=cv2.BORDER_REPLICATE)
#reflect = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_REFLECT)
#reflect101 = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_REFLECT_101)
#wrap = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size, cv2.BORDER_WRAP)
#constant = cv2.copyMakeBorder(img, top_size, bottom_size, left_size, right_size,cv2.BORDER_CONSTANT, value=0)
# 展示填充效果
#plt.subplot(231), plt.imshow(img, 'gray'), plt.title('ORIGINAL')
#plt.subplot(232), plt.imshow(replicate, 'gray'), plt.title('REPLICATE')
#plt.subplot(233), plt.imshow(reflect, 'gray'), plt.title('REFLECT')
#plt.subplot(234), plt.imshow(reflect101, 'gray'), plt.title('REFLECT_101')
#plt.subplot(235), plt.imshow(wrap, 'gray'), plt.title('WRAP')
#plt.subplot(236), plt.imshow(constant, 'gray'), plt.title('CONSTANT')
#plt.show()各种效果图就像下面这样
8.opencv视频读取与处理(我的视频叫test1)
#vc = cv2.VideoCapture("C:/Users/13758/Pictures/test/test1.mp4") #(如果视频在计算机内,自己指定路径)
vc = cv2.VideoCapture('test1.mp4') #(如果视频在python中)
#检查是否打开正确
if vc.isOpened():
oepn, frame = vc.read() #oepn为返回值,读取第一帧 oepn的值为True或者False ,frame为当前图像
else:
open = False
while open: #只要能打开,遍历每一帧
ret, frame = vc.read() #读取
if frame is None:
break #如果图像为空,跳出来
if ret == True:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #这里我转为黑白图像查看(灰度图像)
cv2.imshow('result', gray) #展示结果
if cv2.waitKey(60) & 0xFF == 27: #waitkey() 类似于帧率 0xff == 27 表示退出快捷键退出
break
vc.release()
cv2.destroyWindow() #销毁窗口,如果不销毁,关闭的时候就会卡一下这里可能会有疑问?为什么图像的处理代码那么简单,视频这么麻烦?
可以看出这是个循环语句。因为视频是图像连起来形成的,所以处理视频的方式就是一帧一帧图像处理,所以处理完这一张继续处理下一张,这就形成了我们的视频处理,所以要循环,通俗易懂吧,好好揣摩一下。
9.ROI区域 region of intrest(截取图像特定区域)
就是截图!你感兴趣的区域截取出来。
img=cv2.imread("girl1.jpg")
girl=img[600:800,800:900]
cv2.imshow('girl1',girl)
cv2.waitKey(0)第二行意思就是你要截取第几个像素点到第几个像素点,长和宽各取一次。
10.数值计算
这里我的图片一张叫girl1,另一张叫cat1
打印下图片矩阵,观察下图像矩阵
arraycat = np.array(img_cat)
print(arraycat)
arraygirl = np.array(img_girl)
print(arraygirl)+法的运算(这里只打印前五行,查看下结果)
# +法
img_cat2 = arraycat + 10
print(img_cat2[:5,:,0]) #打印前5行
print(arraycat[:5,:,0])两张图片的+法
# +法(2) 超过256相当于% 256
img_cat3 = img_cat2 + arraycat
print(img_cat3[:5,:,0])add法的运算
# add法 超过255就是最大255
img_cat4 = cv2.add(img_cat2,arraycat)
print(img_cat4)add法与+法的区别就是如果图像的像素点值超过最大值255的处理,+法会取余数,而add法直接截至255(像素的值不会超过255)
图像融合(两张相同shape的图才能互相融合,记得改shape)
#图像融合
#shape值一样才能融合 用resize使得图像shape一样
img_cat = cv2.resize(img_cat,(2400,1600))
img_girl = cv2.resize(img_girl,(2400,1600))
res = cv2.addWeighted(img_cat,0.4,img_girl,0.6,0) #这里你可以看成加权操作
cv2.imshow('res',res)
cv2.waitKey(3000)图像融合起来就是这样的效果
如图,有点像重影的感觉

这章先这样,都是很基础的操作,
自己实现一下,很简单的,过一遍就会了。
后面会附上代码包。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









